MileStone: A Multi-Objective Compiler Phase Ordering Framework for Graph-based IR-Level Optimization
Pith reviewed 2026-05-25 02:39 UTC · model grok-4.3
The pith
MileStone models compiler phase ordering as multi-objective search over graph representations, using a neural predictor and reinforcement learning to locate Pareto-optimal pass sequences that respect energy budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MileStone represents programs as graphs, predicts performance metrics with a graph neural network, and explores pass sequences with a reinforcement-learning agent that follows user constraints. The framework builds a self-evolving database that collects compiler transformations and improves prediction quality. On standard benchmarks it finds strong Pareto-optimal solutions, meets energy limits more accurately than LLVM optimization levels and other techniques, and reduces execution time by up to 45 percent under the same energy budget.
What carries the argument
Graph neural network predictor combined with a reinforcement-learning search agent that navigates the space of pass sequences under explicit user constraints, backed by a self-evolving database of observed transformations.
If this is right
- Compiler phase ordering becomes solvable as a constrained multi-objective search rather than a single fixed level.
- Graph representations of intermediate code enable metric prediction without executing every possible sequence.
- User-specified energy or size limits can be satisfied more closely than with existing heuristic levels.
- A self-updating database of transformations steadily raises the quality of future predictions.
- Execution time can be lowered by up to 45 percent without increasing energy consumption on the tested benchmarks.
Where Pith is reading between the lines
- The same graph-plus-RL structure could be applied to other compiler tasks such as register allocation or loop scheduling that also face large discrete search spaces.
- Integration into LLVM would allow the framework to replace or augment the current static optimization levels for energy-aware compilation.
- The database mechanism suggests the system could adapt online to new hardware or new program domains without full retraining.
- Extending the objectives to include metrics such as worst-case execution time or binary security properties would test whether the approach generalizes beyond the three goals studied.
Load-bearing premise
That a graph neural network can reliably predict the actual runtime, size, and energy outcomes of arbitrary pass sequences and that the reinforcement-learning agent can locate good trade-off points inside the enormous search space.
What would settle it
Running the trained predictor on a fresh set of programs and pass sequences and finding that its forecasts differ from measured hardware values by more than the margin reported in the experiments, or showing that the agent returns no better solutions than LLVM -O3 when energy is strictly capped.
Figures








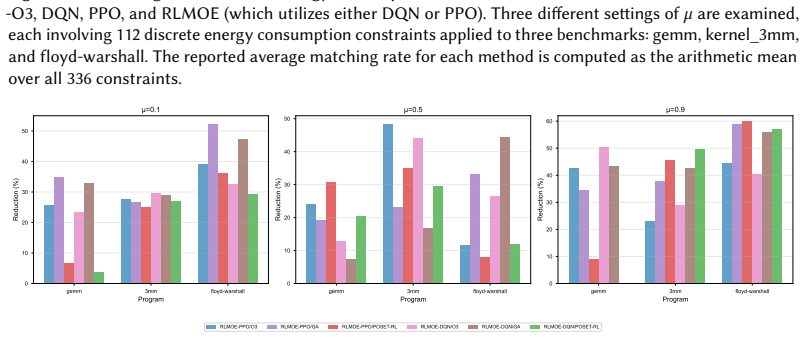
read the original abstract
Compiler phase ordering has a strong effect on program performance. Finding an effective sequence of passes is still a difficult task because the search space is large and execution time, code size and energy consumption often conflict. Existing methods usually depend on fixed optimization levels or limited heuristics and they rarely handle multiple objectives at the same time. This paper presents MileStone, a modular framework that models compiler phase ordering as a multi-objective optimization problem. MileStone represents programs as graphs, predicts performance metrics with a graph neural network and explores pass sequences with a reinforcement-learning agent that follows user constraints. The framework also builds a self-evolving database that collects compiler transformations and improves prediction quality. Experiments on standard benchmarks show that MileStone finds strong Pareto-optimal solutions, meets energy limits more accurately than LLVM optimization levels and other related techniques. MileStone reduces execution time by up to 45 percent under the same energy budget using a multi-objective approach. The results show that MileStone provides an effective and scalable solution for multi-objective compiler phase ordering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MileStone, a modular framework for multi-objective compiler phase ordering on graph-based IR. It represents programs as graphs, uses a graph neural network to predict execution time, code size, and energy metrics, and employs a reinforcement-learning agent to search pass sequences while respecting user-specified constraints such as energy budgets. A self-evolving database collects transformations to improve predictions over time. Experiments on standard benchmarks are reported to yield Pareto-optimal solutions that meet energy limits more accurately than LLVM -O levels and related techniques, with up to 45% execution-time reduction under a fixed energy budget.
Significance. If the GNN surrogate and RL search are shown to be accurate on held-out sequences, the work would be significant for practical compiler optimization: it directly tackles the conflicting objectives of time, size, and energy that fixed LLVM levels ignore, and the self-evolving database offers a path to continual improvement. The multi-objective framing and constraint-following RL agent address a real gap in existing phase-ordering literature.
major comments (2)
- [§4 (Evaluation)] §4 (Evaluation) and abstract: the central claims of 45% time reduction and superior energy compliance rest on the GNN surrogate being sufficiently accurate for the sequences discovered by the RL agent. No training-set size, held-out MAE/RMSE, or generalization results on long or out-of-distribution pass sequences are reported; without these, the reported speedups and energy adherence may reflect surrogate artifacts rather than ground-truth improvements.
- [§3.2 (RL Agent)] §3.2 (RL Agent) and §3.1 (GNN Predictor): the paper states that the RL agent follows user constraints, yet provides no description of how constraint violation is penalized or how the multi-objective reward is shaped. This makes it impossible to assess whether the reported Pareto fronts are produced by genuine trade-off optimization or by an implicit single-objective bias.
minor comments (2)
- [§2] The abstract and introduction use “graph-based IR-Level Optimization” without defining the precise IR representation or the node/edge features fed to the GNN; a short table or paragraph in §2 would clarify this for readers.
- [§4] No error bars, number of runs, or statistical significance tests accompany the 45% figure or the comparison tables; adding these would strengthen the experimental presentation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation and RL agent sections. The comments identify gaps in reported metrics and implementation details that we will address in revision.
read point-by-point responses
-
Referee: [§4 (Evaluation)] §4 (Evaluation) and abstract: the central claims of 45% time reduction and superior energy compliance rest on the GNN surrogate being sufficiently accurate for the sequences discovered by the RL agent. No training-set size, held-out MAE/RMSE, or generalization results on long or out-of-distribution pass sequences are reported; without these, the reported speedups and energy adherence may reflect surrogate artifacts rather than ground-truth improvements.
Authors: We agree that the manuscript does not report training-set size, held-out MAE/RMSE, or generalization results on long or out-of-distribution pass sequences. This information is necessary to validate the surrogate. In the revised version we will add the training dataset sizes, held-out MAE and RMSE values for execution time, code size, and energy, plus an analysis of performance on sequences of varying lengths and out-of-distribution cases. These additions will confirm that the reported improvements rest on accurate predictions rather than artifacts. revision: yes
-
Referee: [§3.2 (RL Agent)] §3.2 (RL Agent) and §3.1 (GNN Predictor): the paper states that the RL agent follows user constraints, yet provides no description of how constraint violation is penalized or how the multi-objective reward is shaped. This makes it impossible to assess whether the reported Pareto fronts are produced by genuine trade-off optimization or by an implicit single-objective bias.
Authors: We acknowledge that Sections 3.1 and 3.2 lack explicit descriptions of constraint penalization and multi-objective reward shaping. The current text states that the agent respects constraints but does not detail the implementation. We will expand these sections to describe the penalty function applied on violation (e.g., energy budget exceedance) and the exact reward formulation used to produce the Pareto fronts, thereby clarifying that the fronts arise from explicit multi-objective optimization. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a modular framework that models phase ordering as multi-objective optimization, using a GNN to predict metrics from graph representations of programs and an RL agent to explore sequences under constraints, with a self-evolving database for data collection. All central claims (Pareto-optimal solutions, energy compliance, up to 45% execution-time reduction) are presented as experimental outcomes on standard benchmarks rather than derived by construction from fitted parameters or self-citations. No self-definitional steps, fitted-input-as-prediction patterns, or load-bearing self-citation chains appear in the abstract or described approach; the method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Miltiadis Allamanis, Marc Brockschmidt, and Mahmoud Khademi. 2017. Learning to Represent Programs with Graphs. CoRRabs/1711.00740 (2017). arXiv:1711.00740 http://arxiv.org/abs/1711.00740
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Uri Alon, Meital Zilberstein, Omer Levy, and Eran Yahav. 2018. A general path-based representation for predicting program properties.SIGPLAN Not.53, 4 (June 2018), 404–419. doi:10.1145/3296979.3192412
-
[3]
Uri Alon, Meital Zilberstein, Omer Levy, and Eran Yahav. 2019. code2vec: learning distributed representations of code. Proc. ACM Program. Lang.3, POPL, Article 40 (Jan. 2019), 29 pages. doi:10.1145/3290353
-
[4]
Ashouri, Andrea Bignoli, Gianluca Palermo, Cristina Silvano, Sameer Kulkarni, and John Cavazos
Amir H. Ashouri, Andrea Bignoli, Gianluca Palermo, Cristina Silvano, Sameer Kulkarni, and John Cavazos. 2017. MiCOMP: Mitigating the Compiler Phase-Ordering Problem Using Optimization Sub-Sequences and Machine Learning. ACM Trans. Archit. Code Optim.14, 3, Article 29 (Sept. 2017), 28 pages. doi:10.1145/3124452
-
[5]
Ashouri, William Killian, John Cavazos, Gianluca Palermo, and Cristina Silvano
Amir H. Ashouri, William Killian, John Cavazos, Gianluca Palermo, and Cristina Silvano. 2018. A Survey on Compiler Autotuning using Machine Learning.ACM Comput. Surv.51, 5, Article 96 (Sept. 2018), 42 pages. doi:10.1145/3197978
-
[6]
Amir Hossein Ashouri, Giovanni Mariani, Gianluca Palermo, Eunjung Park, John Cavazos, and Cristina Silvano. 2016. COBAYN: Compiler Autotuning Framework Using Bayesian Networks.ACM Trans. Archit. Code Optim.13, 2, Article 21 (June 2016), 25 pages. doi:10.1145/2928270
-
[7]
Kunal Banerjee and Chandan Karfa. 2018. Compiler-agnostic Translation Validation. InProceedings of the 11th Innovations in Software Engineering Conference(Hyderabad, India)(ISEC ’18). Association for Computing Machinery, New York, NY, USA, Article 22, 1 pages. doi:10.1145/3172871.3180078
-
[8]
JooHyoung Cha, Munyoung Lee, Jinse Kwon, Jemin Lee, and Yongin Kwon. 2025. Multi-level Machine Learning- Guided Autotuning for Efficient Code Generation on a Deep Learning Accelerator. InProceedings of the 26th ACM SIGPLAN/SIGBED International Conference on Languages, Compilers, and Tools for Embedded Systems(Seoul, Republic of Korea)(LCTES ’25). Associat...
-
[9]
Yihan Chen, Huanhuan Chen, Yuan Yao, Ping Yu, Feng Xu, and Xiaoxing Ma. 2025. Exploiting Booster Pass Chain for Compiler Phase Ordering. InProceedings of the 16th International Conference on Internetware (Internetware ’25). Association for Computing Machinery, New York, NY, USA, 175–185. doi:10.1145/3755881.3755899
-
[10]
Tianming Cui, Pen-Chung Yew, Stephen McCamant, and Antonia Zhai. 2025. DeCOS: Data-Efficient Reinforcement Learning for Compiler Optimization Selection Ignited by LLM. InProceedings of the 39th ACM International Conference on Supercomputing (ICS ’25). Association for Computing Machinery, New York, NY, USA, 943–958. doi:10.1145/3721145. 3725765
-
[11]
Fisches, Tal Ben-Nun, Torsten Hoefler, Michael F P O’Boyle, and Hugh Leather
Chris Cummins, Zacharias V. Fisches, Tal Ben-Nun, Torsten Hoefler, Michael F P O’Boyle, and Hugh Leather. 2021. ProGraML: A Graph-based Program Representation for Data Flow Analysis and Compiler Optimizations. InProceedings of the 38th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 139), Marina Meila and Tong ...
2021
-
[12]
Jack W. Davidson, Gary S. Tyson, David B. Whalley, and Prasad A. Kulkarni. 2007. Evaluating Heuristic Optimization Phase Order Search Algorithms. InInternational Symposium on Code Generation and Optimization (CGO’07). 157–169. doi:10.1109/CGO.2007.9
-
[13]
Haoran Geng, Xiaoyang Lu, Yuezhi Che, Ziang Tian, Dazhao Cheng, Xian-He Sun, Michael Niemier, and X. Sharon Hu. 2025. COSMOS: RL-Enhanced Locality-Aware Counter Cache Optimization for Secure Memory. InProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture (MICRO ’25). Association for Computing Machinery, New York, NY, USA, 1073–1086...
-
[14]
Yacine Hakimi, Riyadh Baghdadi, and Yacine Challal. 2025. Supporting Dynamic Program Sizes in Deep Learning- Based Cost Models for Code Optimization.ACM Trans. Archit. Code Optim.22, 2, Article 67 (July 2025), 25 pages. doi:10.1145/3727638
-
[15]
Ruobing Han and Hyesoon Kim. 2024. Exponentially Expanding the Phase-Ordering Search Space via Dormant Information. InProceedings of the 33rd ACM SIGPLAN International Conference on Compiler Construction(Edinburgh, United Kingdom)(CC 2024). Association for Computing Machinery, New York, NY, USA, 250–261. doi:10.1145/3640537. 3641582
-
[16]
Afshin Hasani, Mehran Alidoost Nia, and Reza Ebrahimi Atani. 2024. Balancing Safety and Security in Autonomous Driving Systems: A Machine Learning Approach with Safety-First Prioritization. In2024 Annual Computer Security Applications Conference Workshops (ACSAC Workshops). 30–41. doi:10.1109/ACSACW65225.2024.00012
-
[17]
Erik Orm Hellsten, Artur Souza, Johannes Lenfers, Rubens Lacouture, Olivia Hsu, Adel Ejjeh, Fredrik Kjolstad, Michel Steuwer, Kunle Olukotun, and Luigi Nardi. 2024. BaCO: A Fast and Portable Bayesian Compiler Optimization Framework. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Syst...
-
[18]
Celeste Hollenbeck and Michael F. P. O’Boyle. 2024. Hot Call-Chain Inlining for the Glasgow Haskell Compiler. In Proceedings of the 23rd ACM SIGPLAN International Conference on Generative Programming: Concepts and Experiences 22 A. Sadr and M. Alidoost Nia (Pasadena, CA, USA)(GPCE ’24). Association for Computing Machinery, New York, NY, USA, 66–79. doi:10...
-
[19]
Qijing Huang, Ameer Haj-Ali, William Moses, John Xiang, Ion Stoica, Krste Asanovic, and John Wawrzynek. 2019. Au- toPhase: Compiler Phase-Ordering for HLS with Deep Reinforcement Learning. In2019 IEEE 27th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM). 308–308. doi:10.1109/FCCM.2019.00049
-
[21]
Hisao Ishibuchi, Lie Meng Pang, and Cheng Gong. 2025. Search Behavior Analysis of NSGA-III: Dominance-based and Decomposition-based Multi-objective Evolutionary Algorithm. InProceedings of the Genetic and Evolutionary Computation Conference(NH Malaga Hotel, Malaga, Spain)(GECCO ’25). Association for Computing Machinery, New York, NY, USA, 581–589. doi:10....
-
[22]
Shashank Jadhav and Heiko Falk. 2019. Multi-Objective Optimization for the Compiler of Real-Time Systems based on Flower Pollination Algorithm. InProceedings of the 22nd International Workshop on Software and Compilers for Embedded Systems(Sankt Goar, Germany)(SCOPES ’19). Association for Computing Machinery, New York, NY, USA, 45–48. doi:10.1145/3323439.3323977
-
[23]
VenkataKeerthy, and Ramakrishna Upadrasta
Shalini Jain, Yashas Andaluri, S. VenkataKeerthy, and Ramakrishna Upadrasta. 2022. POSET-RL: Phase ordering for Optimizing Size and Execution Time using Reinforcement Learning . In2022 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). IEEE Computer Society, Los Alamitos, CA, USA, 121–131. doi:10.1109/ISPASS55109.2022.00012
-
[24]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Optimization. In3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, Yoshua Bengio and Yann LeCun (Eds.). http://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[25]
David Klopp, Sebastian Erdweg, and André Pacak. 2024. A Typed Multi-level Datalog IR and Its Compiler Framework. Proc. ACM Program. Lang.8, OOPSLA2, Article 327 (Oct. 2024), 29 pages. doi:10.1145/3689767
-
[26]
Yogesh Kumar, Prakhar Gupta, Karuna Panwar, and Kusum Deep. 2025. Efficient Waste Collection Routing Using F- CVRP and Dynamic Parameter Optimization via Q-Learning. InProceedings of the Genetic and Evolutionary Computation Conference Companion(NH Malaga Hotel, Malaga, Spain)(GECCO ’25 Companion). Association for Computing Machinery, New York, NY, USA, 25...
-
[27]
C. Lattner and V. Adve. 2004. LLVM: a compilation framework for lifelong program analysis & transformation. In International Symposium on Code Generation and Optimization, 2004. CGO 2004.75–86. doi:10.1109/CGO.2004.1281665
-
[28]
Qimai Li, Zhichao Han, and Xiao-Ming Wu. 2018. Deeper insights into graph convolutional networks for semi- supervised learning. InProceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligenc...
2018
-
[30]
Zujie Li, Huabiao Qin, and Yixiang Xie. 2025. Applying Knowledge-Guided Deep Reinforcement Learning with Graph Neural Networks for Compiler Optimization. InProceedings of the 4th International Conference on Computer, Artificial Intelligence and Control Engineering (CAICE ’25). Association for Computing Machinery, New York, NY, USA, 193–198. doi:10.1145/37...
-
[31]
Lili Liu, Jinyang Yao, Wenbo Liu, Chaowei Zhao, Yingying Li, Jinlong Xu, Ping Zhang, and Bo Zhao. 2025. Loop Vectorization Optimization Technique for System Calls. InProceedings of the 2025 5th International Conference on Computer Network Security and Software Engineering (CNSSE ’25). Association for Computing Machinery, New York, NY, USA, 308–315. doi:10...
-
[32]
Rahim Mammadli, Ali Jannesari, and Felix Wolf. 2020. Static Neural Compiler Optimization via Deep Reinforcement Learning. In2020 IEEE/ACM 6th Workshop on the LLVM Compiler Infrastructure in HPC (LLVM-HPC) and Workshop on Hierarchical Parallelism for Exascale Computing (HiPar). 1–11. doi:10.1109/LLVMHPCHiPar51896.2020.00006
-
[33]
Human-level control through deep reinforcement learning
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Mar- tin A. Riedmiller, Andreas Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. 2015. Human-level control through deep reinfor...
-
[34]
Paschalis Mpeis, Pavlos Petoumenos, Kim Hazelwood, and Hugh Leather. 2021. Developer and user-transparent compiler optimization for interactive applications. InProceedings of the 42nd ACM SIGPLAN International Conference MileStone: A Multi-Objective Compiler Phase Ordering Framework for Graph-based IR-Level Optimization 23 on Programming Language Design a...
-
[35]
Pei Mu, Nikolaos Mavrogeorgis, Christos Vasiladiotis, Vasileios Tsoutsouras, Orestis Kaparounakis, Phillip Stanley- Marbell, and Antonio Barbalace. 2024. CoSense: Compiler Optimizations using Sensor Technical Specifications. In Proceedings of the 33rd ACM SIGPLAN International Conference on Compiler Construction(Edinburgh, United Kingdom) (CC 2024). Assoc...
-
[36]
Alnis Murtovi, Giorgis Georgakoudis, Konstantinos Parasyris, Chunhua Liao, Ignacio Laguna, and Bernhard Steffen
-
[37]
Enhancing Performance through Control-Flow Unmerging and Loop Unrolling on GPUs. InProceedings of the 2024 IEEE/ACM International Symposium on Code Generation and Optimization(Edinburgh, United Kingdom)(CGO ’24). IEEE Press, 106–118. doi:10.1109/CGO57630.2024.10444819
-
[38]
R Nobre, L Reis, and JMP Cardoso. 2018. Compiler Phase Ordering as an Orthogonal Approach for Reducing Energy Consumption. Indexing/Citations: dblp
2018
-
[39]
Nuno Paulino, João Canas Ferreira, and João M. P. Cardoso. 2020. Improving Performance and Energy Consumption in Embedded Systems via Binary Acceleration: A Survey.ACM Comput. Surv.53, 1, Article 6 (Feb. 2020), 36 pages. doi:10.1145/3369764
-
[40]
Hannah Peeler, Shuyue Stella Li, Andrew N. Sloss, Kenneth N. Reid, Yuan Yuan, and Wolfgang Banzhaf. 2022. Optimizing LLVM pass sequences with shackleton: a linear genetic programming framework. InProceedings of the Genetic and Evolutionary Computation Conference Companion(Boston, Massachusetts)(GECCO ’22). Association for Computing Machinery, New York, NY...
-
[41]
Xiaolei Ren, Mengfei Ren, Yu Lei, and Jiang Ming. 2025. Revisiting Optimization-Resilience Claims in Binary Diffing Tools: Insights from LLVM Peephole Optimization Analysis.Proc. ACM Softw. Eng.2, FSE, Article FSE119 (June 2025), 23 pages. doi:10.1145/3729389
-
[42]
2025.IRFuzzer: Specialized Fuzzing for LLVM Backend Code Generation
Yuyang Rong, Zhanghan Yu, Zhenkai Weng, Stephen Neuendorffer, and Hao Chen. 2025.IRFuzzer: Specialized Fuzzing for LLVM Backend Code Generation. IEEE Press, 1986–1998. https://doi.org/10.1109/ICSE55347.2025.00130
-
[43]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael I. Jordan, and Pieter Abbeel. 2016. High-Dimensional Continu- ous Control Using Generalized Advantage Estimation. In4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings, Yoshua Bengio and Yann LeCun (Eds.). http://arxiv....
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[44]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal Policy Optimization Algorithms.CoRRabs/1707.06347 (2017). arXiv:1707.06347 http://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[45]
Volker Seeker, Chris Cummins, Murray Cole, Björn Franke, Kim Hazelwood, and Hugh Leather. 2024. Revealing Compiler Heuristics through Automated Discovery and Optimization. InProceedings of the 2024 IEEE/ACM International Symposium on Code Generation and Optimization(Edinburgh, United Kingdom)(CGO ’24). IEEE Press, 55–66. doi:10. 1109/CGO57630.2024.10444847
-
[46]
Xipeng Shen. 2018. Rethinking compilers in the rise of machine learning and AI (keynote). InProceedings of the 27th International Conference on Compiler Construction(Vienna, Austria)(CC ’18). Association for Computing Machinery, New York, NY, USA, 1. doi:10.1145/3178372.3183634
-
[47]
Langchun Si, Xingyi Zhang, Yajie Zhang, Ye Tian, and Shangshang Yang. 2025. Reinforcement Learning-Assisted Multi-Stage Evolutionary Constrained Multi-Objective optimization.ACM Trans. Evol. Learn. Optim.(Sept. 2025). doi:10.1145/3764597 Just Accepted
-
[48]
Arnab Kanti Tarafder, Yidong Gong, and Pradeep Kumar. 2025. Optimization of GNN Training Through Half-precision. InProceedings of the 34th International Symposium on High-Performance Parallel and Distributed Computing(University of Notre Dame Conference Facilities, Notre Dame, IN, USA)(HPDC ’25). Association for Computing Machinery, New York, NY, USA, Art...
-
[49]
S. VenkataKeerthy, Rohit Aggarwal, Shalini Jain, Maunendra Sankar Desarkar, Ramakrishna Upadrasta, and Y. N. Srikant. 2020. IR2VEC: LLVM IR Based Scalable Program Embeddings.ACM Trans. Archit. Code Optim.17, 4, Article 32 (Dec. 2020), 27 pages. doi:10.1145/3418463
-
[50]
S. VenkataKeerthy, Siddharth Jain, Umesh Kalvakuntla, Pranav Sai Gorantla, Rajiv Shailesh Chitale, Eugene Brevdo, Albert Cohen, Mircea Trofin, and Ramakrishna Upadrasta. 2024. The Next 700 ML-Enabled Compiler Optimizations. In Proceedings of the 33rd ACM SIGPLAN International Conference on Compiler Construction(Edinburgh, United Kingdom) (CC 2024). Associ...
-
[51]
Ke Wang, Yingnan Zhao, and Ahmed Louri. 2025. FORT-GCN: A Fault-Tolerant and Adaptive Accelerator Design for Efficient Graph Convolutional Network Inference.ACM Trans. Embed. Comput. Syst.24, 5s, Article 122 (Sept. 2025), 26 pages. doi:10.1145/3758094
-
[52]
2025.Compiler Optimization Testing Based on Optimization-Guided Equivalence Transformations
Jingwen Wu, Jiajing Zheng, Zhenyu Yang, and Zhongxing Yu. 2025.Compiler Optimization Testing Based on Optimization-Guided Equivalence Transformations. Association for Computing Machinery, New York, NY, USA, 706–710. https://doi.org/10.1145/3696630.3728528 24 A. Sadr and M. Alidoost Nia
-
[53]
Tomofumi Yuki. 2014. Understanding polybench/c 3.2 kernels. InInternational workshop on polyhedral compilation techniques (IMPACT). 1–5
2014
-
[54]
André Felipe Zanella, Anderson Faustino da Silva, and Fernando Magno Quintão. 2020. YACOS: a Complete Infrastruc- ture to the Design and Exploration of Code Optimization Sequences. InProceedings of the 24th Brazilian Symposium on Context-Oriented Programming and Advanced Modularity(Natal, Brazil)(SBLP ’20). Association for Computing Machinery, New York, N...
-
[55]
Kechi Zhang, Wenhan Wang, Huangzhao Zhang, Ge Li, and Zhi Jin. 2022. Learning to represent programs with heterogeneous graphs. InProceedings of the 30th IEEE/ACM International Conference on Program Comprehension(Virtual Event)(ICPC ’22). Association for Computing Machinery, New York, NY, USA, 378–389. doi:10.1145/3524610.3527905
-
[56]
Ming Zhong, Fang Lv, Lulin Wang, Lei Qiu, Yingying Wang, Ying Liu, Huimin Cui, Xiaobing Feng, and Jingling Xue
-
[57]
VEGA: Automatically Generating Compiler Backends using a Pre-trained Transformer Model. InProceedings of the 23rd ACM/IEEE International Symposium on Code Generation and Optimization(Las Vegas, NV, USA)(CGO ’25). Association for Computing Machinery, New York, NY, USA, 90–106. doi:10.1145/3696443.3708931
-
[58]
Mingxuan Zhu, Dan Hao, and Junjie Chen. 2024. Compiler Autotuning through Multiple-phase Learning.ACM Trans. Softw. Eng. Methodol.33, 4, Article 100 (April 2024), 38 pages. doi:10.1145/3640330
-
[59]
Mingcheng Zuo, Dunwei Gong, Tianyang Xue, Chunliang Zhao, and Yongde Guo. 2025. Constrained Multi-objective Optimization with Search Direction Learning. InProceedings of the Genetic and Evolutionary Computation Conference (NH Malaga Hotel, Malaga, Spain)(GECCO ’25). Association for Computing Machinery, New York, NY, USA, 683–691. doi:10.1145/3712256.37264...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.