S³GNN: Efficient Global Mixing and Local Message Passing for Long-Range Graph Learning
Pith reviewed 2026-05-25 05:25 UTC · model grok-4.3
The pith
S³GNN mitigates oversquashing in graph networks by lightweight reintroduction of omitted components without strong theoretical assumptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
S³GNN mitigates OSQ without such restrictive assumptions by lightweightly reintroducing omitted components with substantially lower computational complexity, while standard stability constraints on feature transformations remain effective under our new dynamics.
What carries the argument
The revised propagation dynamics obtained by lightweight reintroduction of omitted components during spectral global mixing.
If this is right
- Standard stability constraints on feature transformations suffice for effective OSQ mitigation under the new dynamics.
- Computational complexity stays substantially lower than that of earlier spectral approaches.
- Error reductions of up to an order of magnitude appear on long-range benchmarks, KGQA, and mesh-based fluid dynamics.
- Up to 50 percent fewer parameters are needed while preserving or improving accuracy.
Where Pith is reading between the lines
- The same lightweight reintroduction tactic could be tested on other architectures that suffer from information bottlenecks.
- Deeper message-passing networks might become viable on long-range problems without additional rewiring.
- The approach might complement spatial connectivity enrichment methods rather than replace them.
Load-bearing premise
The revised dynamics introduced by lightweight reintroduction of omitted components allow standard stability constraints on feature transformations to remain effective without requiring the strong theoretical assumptions needed by prior spectral approaches.
What would settle it
If experiments on the long-range benchmarks, KGQA tasks, or mesh fluid dynamics show no order-of-magnitude error reduction or no parameter savings relative to baselines, the claimed practical benefit would be falsified.
Figures







read the original abstract
Message-passing neural networks (MPNNs) often suffer from an information bottleneck when capturing long-range dependencies, leading to the oversquashing (OSQ) phenomenon. Alongside spatial connectivity enrichment (e.g., rewiring), recent studies have shown that spectral filtering can yield strong long-range learning outcomes, as spectral operators enable global information mixing that alleviates OSQ. These approaches achieve this either by stabilizing the Jacobian energies in deep propagation or by guaranteeing OSQ mitigation under strong theoretical assumptions. We revisit these conclusions and show that the associated Jacobian sensitivity lower bound is generally difficult to achieve in practice. We then propose S$^3$GNN, which mitigates OSQ without such restrictive assumptions by lightweightly reintroducing omitted components with substantially lower computational complexity, while standard stability constraints on feature transformations remain effective under our new dynamics. Extensive experiments across diverse domains (e.g., long-range benchmarks, KGQA, and mesh-based fluid dynamics) demonstrate that S$^3$GNN achieves up to an order-of-magnitude error reduction with up to 50\% fewer parameters. Our code can be found in https://github.com/EEthanShi/S3-GNN.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes S³GNN, a graph neural network that combines spectral global mixing with local message passing to mitigate oversquashing (OSQ) in MPNNs for long-range dependencies. It argues that prior spectral methods require hard-to-achieve Jacobian lower bounds or strong assumptions, and instead introduces a lightweight reintroduction of omitted components under standard stability constraints on feature transformations, yielding lower complexity. Empirical results are reported on long-range benchmarks, KGQA, and mesh-based fluid dynamics, claiming up to 10× error reduction with up to 50% fewer parameters, with code released.
Significance. If the central claims hold, the work provides a practical route to long-range graph learning that avoids restrictive Jacobian bounds while retaining stability guarantees under milder conditions. The combination of global spectral operators with local MPNN dynamics, together with the released code, would strengthen reproducibility and applicability in domains requiring efficient long-range propagation.
minor comments (3)
- [Abstract] Abstract states that the Jacobian sensitivity lower bound is 'generally difficult to achieve in practice' but does not cite the specific section or theorem where this is shown; add a forward reference to the relevant derivation or empirical evidence.
- [Abstract / §4] The claim of 'substantially lower computational complexity' relative to prior spectral methods is stated without an explicit complexity comparison (e.g., big-O or measured FLOPs) in the provided abstract; ensure §4 or the experimental section includes a direct table or equation.
- [§3] Notation for the 'new dynamics' and the 'lightweight reintroduction of omitted components' is introduced at a high level; define the precise update rule (likely an equation in §3) with all symbols before the stability argument.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of S³GNN and the recommendation for minor revision. The assessment correctly identifies the core contribution as a lightweight spectral-global plus local-MPNN approach that avoids restrictive Jacobian bounds while retaining stability under milder conditions.
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description contain no equations, fitted parameters, or derivation steps that reduce by construction to self-defined quantities, renamed predictions, or load-bearing self-citations. Claims about Jacobian bounds being difficult to achieve and the new S³GNN dynamics allowing standard stability constraints are presented as external observations leading to a proposed architecture; no internal reduction to inputs is exhibited. The argument is self-contained with references to prior spectral work treated as independent.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Arnaiz-Rodriguez, A. and Errica, F. Oversmoothing,” oversquashing”, heterophily, long-range, and more: De- mystifying common beliefs in graph machine learning. arXiv:2505.15547,
-
[2]
Specformer: Spectral graph neural networks meet transformers.arXiv preprint arXiv:2303.01028,
Bo, D., Shi, C., Wang, L., and Liao, R. Specformer: Spectral graph neural networks meet transformers.arXiv preprint arXiv:2303.01028,
-
[3]
Beltrami flow and neural diffusion on graphs
Chamberlain, B., Rowbottom, J., Eynard, D., Di Gio- vanni, F., Dong, X., and Bronstein, M. Beltrami flow and neural diffusion on graphs. InAdvances in Neural Information Processing Systems, vol- ume 34, pp. 1594–1609. Curran Associates, Inc., 2021a. URL https://proceedings.neurips. cc/paper_files/paper/2021/file/ 0cbed40c0d920b94126eaf5e707be1f5-Paper. pd...
- [4]
-
[5]
Giraldo, J. H., Malliaros, F. D., and Bouwmans, T. Understanding the relationship between over- smoothing and over-squashing in graph neural networks. arXiv:2212.02374,
-
[6]
Anti-symmetric dgn: a stable architecture for deep graph networks.arXiv preprint arXiv:2210.09789,
Gravina, A., Bacciu, D., and Gallicchio, C. Anti-symmetric dgn: a stable architecture for deep graph networks.arXiv preprint arXiv:2210.09789,
-
[7]
Hariri, A., Arroyo, ´A., Gravina, A., Eliasof, M., Sch¨onlieb, C.-B., Bacciu, D., Azizzadenesheli, K., Dong, X., and Vandergheynst, P. Return of chebnet: Understanding and improving an overlooked gnn on long range tasks.arXiv preprint arXiv:2506.07624,
-
[8]
Kipf, T. N. and Welling, M. Semi-supervised classification with graph convolutional networks.arXiv:1609.02907,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Mavromatis, C. and Karypis, G. Rearev: Adaptive reasoning for question answering over knowledge graphs.arXiv preprint arXiv:2210.13650,
-
[10]
Mavromatis, C. and Karypis, G. Gnn-rag: Graph neural re- trieval for large language model reasoning.arXiv preprint arXiv:2405.20139,
-
[11]
Mishra, S. mhc-gnn: Manifold-constrained hyper- connections for graph neural networks.arXiv preprint arXiv:2601.02451,
-
[12]
Rusch, T. K., Bronstein, M. M., and Mishra, S. A survey on oversmoothing in graph neural networks. arXiv:2303.10993,
-
[13]
A survey on the expressive power of graph neural networks.arXiv:2003.04078,
Sato, R. A survey on the expressive power of graph neural networks.arXiv:2003.04078,
-
[14]
Shi, D., Han, A., Lin, L., Guo, Y ., and Gao, J. Ex- position on over-squashing problem on gnns: Current methods, benchmarks and challenges.arXiv preprint arXiv:2311.07073,
-
[15]
Wang, C., Tsepa, O., Ma, J., and Wang, B. Graph-mamba: Towards long-range graph sequence modeling with se- lective state spaces.arXiv preprint arXiv:2402.00789,
-
[16]
Difformer: Scalable (graph) transformers induced by energy constrained diffusion
Wu, Q., Yang, C., Zhao, W., He, Y ., Wipf, D., and Yan, J. Difformer: Scalable (graph) transformers induced by energy constrained diffusion. InInternational Conference on Learning Representations, 2023a. Wu, Q., Yang, C., Zhao, W., He, Y ., Wipf, D., and Yan, J. Difformer: Scalable (graph) transformers induced by energy constrained diffusion.arXiv:2301.09...
-
[17]
mHC: Manifold-Constrained Hyper-Connections
Xie, Z., Wei, Y ., Cao, H., Zhao, C., Deng, C., Li, J., Dai, D., Gao, H., Chang, J., Zhao, L., et al. mhc: Manifold-constrained hyper-connections.arXiv preprint arXiv:2512.24880,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
11 S3GNN: Efficient Global Mixing and Local Message Passing for Long-Range Graph Learning A. Related Works OSQ Mitigation MethodsOversquashing arises when information from exponentially many distant nodes is compressed into fixed-dimensional node representations, and has been recognized as a fundamental limitation of message-passing GNNs (Topping et al., ...
work page 2021
-
[19]
The proof follows the similar strategy in (Hariri et al., 2025). The core is the outer product between one antisymmetric matrix and a symmetric matrix is still antisymmetric, i.e,P θ ⊗cWandA⊗ cW. Leth(ℓ) = vec(H(ℓ))∈R N d. Using the standard identity vec(S H W) = (W⊤ ⊗S) vec(H), the dynamics in Eq. (11) implies h(ℓ+
work page 2025
-
[20]
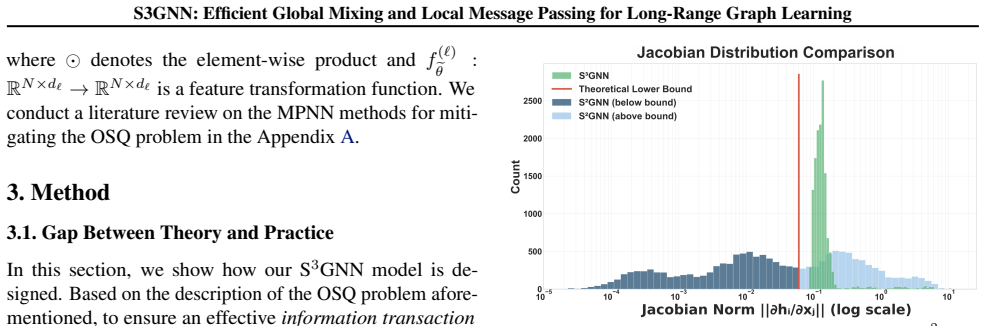
We found that in all plots, S2GNN’s norm distributions are mixedbelow-bound valuesandabove-bound values, whereas S 3GNNs are all above the theoretical lower bounds, except in the graph #356, where we observed around 5.7% of the norms are below the lower bound. These evidence further suggests the violation between the real-implementation and theoretical co...
work page 2016
-
[21]
and DRew-GCN (Gutteridge et al., 2023); state-space models including Graph Mamba (Wang et al.,
work page 2023
-
[22]
and GMN (Behrouz & Hashemi, 2024). C.3. Hyperparameter Searching Space In this section, we provide hyperparameter searching spaces for each of the experiments. Table 8 to 7 summarize the search spaces and the reference hyperparameters. We note that for the experiment in KGQA, topological interpolation, and the fulid dynamic prediction, the hyperparameters...
work page 2024
-
[23]
for more implementation details. 14 S3GNN: Efficient Global Mixing and Local Message Passing for Long-Range Graph Learning Table 7.Hyperparameters for LRGB Experiments Hyperparameter Peptides-struct Peptides-func Search Space Hidden dimension 256 128 128, 256, 512 Number of Layers 5 7 3, 5, 7 MLP Layers 2 2 1, 2, 3 Batch Size 64 32 32, 64, 128 Learning Ra...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.