Human Decision-Making with Persuasive and Narrative LLM Explanations
Pith reviewed 2026-05-25 03:04 UTC · model grok-4.3
The pith
LLM narrative explanations of varying persuasiveness do not improve human decision accuracy beyond a simple AI prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
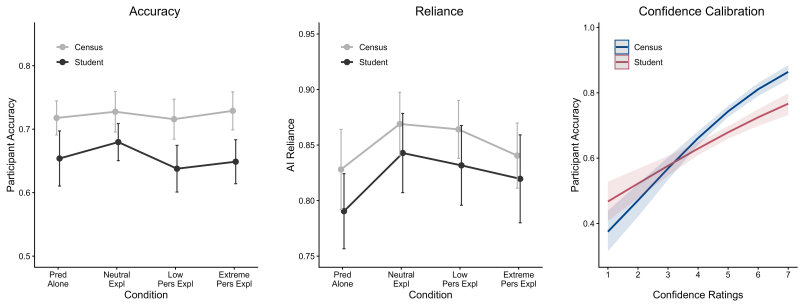
In a large-scale human behavioral experiment evaluating decision-making performance with LLM-generated narrative explanations of varying persuasiveness, the degree of persuasiveness did not meaningfully impact decision accuracy over a simple AI prediction alone. Narratives increased reliance on AI both when predictions were correct and incorrect. More persuasive narratives may have had a detrimental effect on decision response times and the ability to discriminate between a correct and incorrect AI prediction.
What carries the argument
Experimental manipulation of persuasiveness in LLM-generated narrative explanations and its measured effects on human accuracy, reliance, response time, and discrimination in classification tasks.
If this is right
- Narrative explanations increase human reliance on AI predictions even when those predictions are incorrect.
- More persuasive narratives can lengthen decision response times.
- Persuasive narratives can reduce people's ability to distinguish correct from incorrect AI predictions.
- Including narrative explanations with AI predictions involves tradeoffs for objective decision-making performance.
Where Pith is reading between the lines
- AI system designers may need to test whether adding any explanation is worth the risk of increased over-reliance in a given domain.
- High-stakes settings such as medical diagnosis could benefit from withholding narrative text and showing only the raw prediction.
- Future experiments could measure whether calibration techniques, such as showing confidence scores alongside narratives, restore discrimination ability.
Load-bearing premise
The experimental manipulation successfully varied the persuasiveness of the LLM explanations independently of other factors such as explanation length or content accuracy.
What would settle it
A direct replication in which participants achieve reliably higher decision accuracy with high-persuasiveness narratives than with low-persuasiveness ones or with AI predictions alone would falsify the central result.
Figures












read the original abstract
Large language models (LLMs) have the potential to aid and improve human decision-making in classification tasks, not only by providing fairly accurate predictions, but also in their ability to generate cogent narrative explanations of those predictions. Prior work has demonstrated that people generally find AI narrative explanations to be understandable, trustworthy, and convincing for changing beliefs and opinions; however, less is known about the impact of narrative explanations on objective human decision-making performance. Here we conduct a large-scale human behavioral experiment to evaluate decision-making performance with LLM-generated narrative explanations of varying persuasiveness. We found the degree of persuasiveness, or lack thereof, for LLM-based explanations did not meaningfully impact decision accuracy over a simple AI prediction alone, in agreement with typical results with explainable AI based on feature importance. We found evidence that narratives increased reliance on AI, but both when the AI prediction was correct and incorrect. Exploratory analyses also indicated that the more persuasive narratives may have had a detrimental effect on decision response times and the ability to discriminate between a correct and incorrect AI prediction. Overall, this work indicates that including narrative explanations with AI predictions may involve tradeoffs for decision-making performance, and more work is needed to determine how and when narrative explanations impact human decision-making.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports results from a large-scale human behavioral experiment on the effects of LLM-generated narrative explanations with varying persuasiveness on human decision accuracy and AI reliance in classification tasks. The main claims are that persuasiveness levels did not meaningfully affect decision accuracy compared to AI predictions alone, that narratives increased reliance on AI predictions whether correct or incorrect, and that more persuasive narratives may have negatively affected response times and discrimination between correct and incorrect AI predictions.
Significance. If these results hold, the work indicates potential tradeoffs in using narrative LLM explanations for decision support, as they may increase over-reliance without improving accuracy. This aligns with prior findings on explainable AI and provides empirical data on narrative forms specifically. The large-scale nature of the experiment strengthens the evidence base for understanding human-AI interaction in decision-making.
major comments (2)
- [Methods] Methods section: The description of the persuasiveness manipulation (including any pre-tests, validation of independence from length/accuracy, and how persuasiveness was quantified) is load-bearing for interpreting the null result on decision accuracy; without explicit evidence that the manipulation succeeded independently, the claim that persuasiveness does not impact accuracy cannot be fully evaluated.
- [Results] Results section: The central null finding on accuracy requires reporting of effect sizes, confidence intervals, and a power analysis or equivalence test; absence of these weakens the conclusion that persuasiveness 'did not meaningfully impact' performance.
minor comments (1)
- [Abstract] Abstract: Specify the participant count, number of trials, and key statistical methods to allow readers to assess the claims without needing the full text.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important areas for strengthening the interpretation of our null results. We address each major comment below.
read point-by-point responses
-
Referee: [Methods] Methods section: The description of the persuasiveness manipulation (including any pre-tests, validation of independence from length/accuracy, and how persuasiveness was quantified) is load-bearing for interpreting the null result on decision accuracy; without explicit evidence that the manipulation succeeded independently, the claim that persuasiveness does not impact accuracy cannot be fully evaluated.
Authors: We agree that the Methods section requires expanded detail on the persuasiveness manipulation to support interpretation of the accuracy null result. The manuscript describes generation of narrative explanations at different persuasiveness levels, but we will revise to include any pre-tests performed, explicit checks confirming independence from explanation length and prediction accuracy, and the precise quantification approach (e.g., rating scales or validation metrics). This will provide the necessary evidence that the manipulation operated as intended. revision: yes
-
Referee: [Results] Results section: The central null finding on accuracy requires reporting of effect sizes, confidence intervals, and a power analysis or equivalence test; absence of these weakens the conclusion that persuasiveness 'did not meaningfully impact' performance.
Authors: We concur that null findings on accuracy benefit from effect sizes, confidence intervals, and equivalence testing or power analysis to substantiate claims of no meaningful impact. We will update the Results section to report appropriate effect sizes (e.g., Cohen's d) with 95% confidence intervals for accuracy comparisons across conditions, along with an equivalence test or post-hoc power analysis to strengthen the conclusion that persuasiveness levels did not meaningfully affect decision accuracy. revision: yes
Circularity Check
Empirical study with no derivation chain
full rationale
This is an empirical behavioral study reporting outcomes from a human-subjects experiment on decision accuracy and AI reliance. No mathematical derivations, equations, fitted parameters, or theoretical chains are present that could reduce any result to prior inputs by construction. All claims rest on direct experimental data collection and statistical reporting, which are self-contained against external benchmarks and do not invoke self-citation load-bearing premises or ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard statistical assumptions for analyzing human decision data (e.g., independence of trials, appropriate error models) hold.
Reference graph
Works this paper leans on
-
[1]
Akgul, Omer and Roberts, Richard and Namara, Moses and Levin, Dave and Mazurek, Michelle L. , booktitle=. Investigating Influencer. 2022 , volume=
work page 2022
-
[2]
Douglas Alan Amyx and James R. Lumpkin , title =. Journal of Promotion Management , volume =. 2016 , publisher =. doi:10.1080/10496491.2016.1154920 , URL =
-
[3]
International Journal of Human--Computer Interaction , volume=
Explainable artificial intelligence improves human decision-making: results from a mushroom picking experiment at a public art festival , author=. International Journal of Human--Computer Interaction , volume=. 2024 , doi =
work page 2024
-
[4]
A meta-analysis of the utility of explainable artificial intelligence in human-
Schemmer, Max and Hemmer, Patrick and Nitsche, Maximilian and K. A meta-analysis of the utility of explainable artificial intelligence in human-. Proceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society , pages=
work page 2022
-
[5]
Ironies of automation , author=. Automatica , volume=. 1983 , publisher=
work page 1983
-
[6]
Annual Review Economics , volume=
Persuasion: empirical evidence , author=. Annual Review Economics , volume=. 2010 , doi=
work page 2010
-
[7]
Persuasion: Theory and research, 3rd edition , author=. 2015 , publisher=
work page 2015
-
[8]
A meta-analysis of the persuasive power of large language models , author=. Scientific Reports , year=
-
[9]
Influence, New and Expanded The Psychology of Persuasion , author=. 2019 , isbn=
work page 2019
-
[10]
Cokely, Edward T and Galesic, Mirta and Schulz, Eric and Ghazal, Saima and Garcia-Retamero, Rocio , journal=. Measuring risk literacy: The. 2012 , publisher=
work page 2012
- [11]
-
[12]
Gass, R. and Seiter, John , editor=. Embracing Divergence: A Definitional Analysis of Pure and Borderline Cases of Persuasion , booktitle=. 2004 , month=jan, pages=
work page 2004
-
[13]
Petty, Richard E. and Cacioppo, John T. , editor=. Advances in Experimental Social Psychology , title=. 1986 , pages=. doi:https://doi.org/10.1016/S0065-2601(08)60214-2 , publisher=
-
[14]
Kruglanski, Arie W. and Thompson, Erik P. , year=. Persuasion by a Single Route: A View From the Unimodel , volume=. Psychological Inquiry , publisher=. doi:10.1207/S15327965PL100201 , number=
-
[15]
The heuristic model of persuasion , ISBN=
Chaiken, Shelly , year=. The heuristic model of persuasion , ISBN=. Social influence: The Ontario symposium, Vol. 5. , publisher=
-
[16]
Gass, Robert H. and Seiter, John S. , year=. Persuasion: Social Influence and Compliance Gaining , ISBN=. doi:10.4324/9781003081388 , publisher=
-
[17]
The effects of message features: Content, structure, and style , ISBN=
Shen, Lijiang and Bigsby, Elisabeth , year=. The effects of message features: Content, structure, and style , ISBN=. The
-
[18]
Lange, Kristian and Kühn, Simone and Filevich, Elisa , year=. ". PLOS ONE , publisher=. doi:10.1371/journal.pone.0130834 , number=
-
[19]
Data analysis using regression and multilevel/hierarchical models , author=. 2006 , publisher=
work page 2006
-
[20]
Marusich, Laura R. and Bakdash, Jonathan Z. and Zhou, Yan and Kantarcioglu, Murat , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
work page 2024
-
[21]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Does Explainable Artificial Intelligence Improve Human Decision-Making? , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2021 , month=. doi:10.1609/aaai.v35i8.16819 , number=
-
[22]
UCI Machine Learning Repository
Dua, Dheeru and Graff, Casey. UCI Machine Learning Repository. 2017
work page 2017
-
[23]
David Martens and James Hinns and Camille Dams and Mark Vergouwen and Theodoros Evgeniou , keywords =. Tell me a story!. Decision Support Systems , volume =. 2025 , issn =. doi:https://doi.org/10.1016/j.dss.2025.114402 , url =
-
[24]
arXiv preprint arXiv:2404.09329 , year=
Large language models are as persuasive as humans, but how? About the cognitive effort and moral-emotional language of LLM arguments , author=. arXiv preprint arXiv:2404.09329 , year=
-
[25]
Persuasion with large language models: a survey , author=
-
[26]
arXiv preprint arXiv:2505.09662 , year=
Large Language Models Are More Persuasive Than Incentivized Human Persuaders , author=. arXiv preprint arXiv:2505.09662 , year=
-
[27]
Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , pages=
Deceptive explanations by large language models lead people to change their beliefs about misinformation more often than honest explanations , author=. Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , pages=
work page 2025
-
[28]
Nature Machine Intelligence , volume=
What large language models know and what people think they know , author=. Nature Machine Intelligence , volume=. 2025 , publisher=
work page 2025
-
[29]
Rogiers, Alexander and Noels, Sander and Buyl, Maarten and Bie, Tijl De , year=. Persuasion with Large Language Models: a Survey , url=. doi:10.48550/arXiv.2411.06837 , note=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.06837
-
[30]
Information delivered by a chatbot has a positive impact on
Altay, Sacha and Hacquin, Anne-Sophie and Chevallier, Coralie and Mercier, Hugo , journal=. Information delivered by a chatbot has a positive impact on. 2023 , publisher=
work page 2023
-
[31]
Durably reducing conspiracy beliefs through dialogues with
Costello, Thomas H and Pennycook, Gordon and Rand, David G , journal=. Durably reducing conspiracy beliefs through dialogues with. 2024 , publisher=
work page 2024
-
[32]
Esin Durmus and Liane Lovitt and Alex Tamkin and Stuart Ritchie and Jack Clark and Deep Ganguli , title =. 2024 , url =
work page 2024
-
[33]
Proceedings of the International AAAI Conference on Web and Social Media , volume=
The persuasive power of large language models , author=. Proceedings of the International AAAI Conference on Web and Social Media , volume=
-
[34]
Meguellati, Elyas and Han, Lei and Bernstein, Abraham and Sadiq, Shazia and Demartini, Gianluca , booktitle=. How good are
-
[35]
Matz, Sandra C and Teeny, Jacob D and Vaid, Sumer S and Peters, Heinrich and Harari, Gabriella M and Cerf, Moran , journal=. The potential of generative. 2024 , publisher=
work page 2024
-
[36]
The persuasive effects of political microtargeting in the age of generative artificial intelligence , author=. PNAS nexus , volume=. 2024 , publisher=
work page 2024
-
[37]
B. People devalue generative. Communications Psychology , volume=. 2023 , publisher=
work page 2023
-
[38]
Karinshak, Elise and Liu, Sunny Xun and Park, Joon Sung and Hancock, Jeffrey T , journal=. Working with. 2023 , publisher=
work page 2023
-
[39]
arXiv preprint arXiv:2505.07775 , year=
Must Read: A Systematic Survey of Computational Persuasion , author=. arXiv preprint arXiv:2505.07775 , year=
-
[40]
Martens, David and Hinns, James and Dams, Camille and Vergouwen, Mark and Evgeniou, Theodoros , journal=. Tell me a story!. 2025 , publisher=
work page 2025
-
[41]
Zytek, Alexandra and Pido, Sara and Alnegheimish, Sarah and Berti-Equille, Laure and Veeramachaneni, Kalyan , booktitle=. Explingo: Explaining. 2024 , organization=
work page 2024
-
[42]
Hartmann, Mareike and Du, Han and Feldhus, Nils and Kruijff-Korbayov. KI-K. 2022 , publisher=
work page 2022
-
[43]
XAI meets LLMs: A Survey of the Relation between Explainable AI and Large Language Models , author=. 2024 , eprint=
work page 2024
-
[44]
On the conversational per- suasiveness of GPT-4
On the conversational persuasiveness of. Nature Human Behaviour , author =. 2025 , keywords =. doi:10.1038/s41562-025-02194-6 , language =
-
[45]
Proceedings of the National Academy of Sciences , volume=
Evaluating the persuasive influence of political microtargeting with large language models , author=. Proceedings of the National Academy of Sciences , volume=. 2024 , publisher=
work page 2024
-
[46]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Zero-shot persuasive chatbots with LLM-generated strategies and information retrieval , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
work page 2024
-
[47]
Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
Escalation risks from language models in military and diplomatic decision-making , author=. Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
work page 2024
-
[48]
Proceedings of the 56th Annual ACM Symposium on Theory of Computing , pages=
Calibrated language models must hallucinate , author=. Proceedings of the 56th Annual ACM Symposium on Theory of Computing , pages=
-
[49]
Bo, Jessica Y and Wan, Sophia and Anderson, Ashton , booktitle=. To rely or not to rely?
-
[50]
Bai, Hui and Voelkel, Jan G and Muldowney, Shane and Eichstaedt, Johannes C and Willer, Robb , journal=. 2025 , publisher=
work page 2025
-
[51]
Steven Loria , year=
-
[52]
textstat 0.7.12 , howpublished =
Shivam Bansal, Chaitanya Aggarwal , year=. textstat 0.7.12 , howpublished =
-
[53]
Computational intelligence , volume=
Crowdsourcing a word--emotion association lexicon , author=. Computational intelligence , volume=. 2013 , publisher=
work page 2013
-
[54]
Measuring and Benchmarking Large Language Models' Capabilities to Generate Persuasive Language , author=. 2024 , eprint=
work page 2024
-
[55]
https://aclanthology.org/2025.naacl-long.506/
Measuring and benchmarking large language models’ capabilities to generate persuasive language , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , url = "https://aclanthology.org/2025.naacl-long.506/", pages=
work page 2025
-
[56]
Natural Language Processing with Python , author=. 2009 , publisher=
work page 2009
-
[57]
Hutto, Clayton and Gilbert, Eric , booktitle=
-
[58]
Potter, Yujin and Lai, Shiyang and Kim, Junsol and Evans, James and Song, Dawn , booktitle=. Hidden persuaders:
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.