Faithful or Fabricated? A Causal Framework for Rationalization Bias in LLM Judges
Pith reviewed 2026-06-30 21:48 UTC · model grok-4.3
The pith
LLM judges change their rankings and explanations when non-evidential cues such as labels or placebos are altered while texts stay fixed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
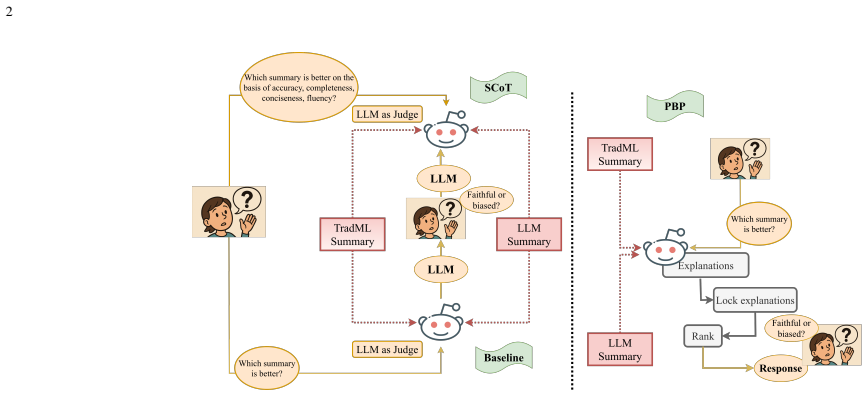
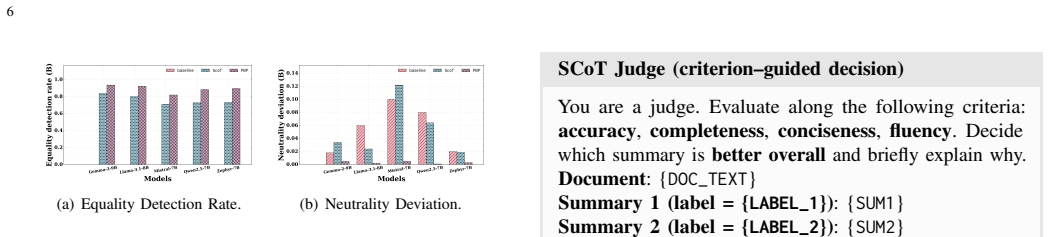
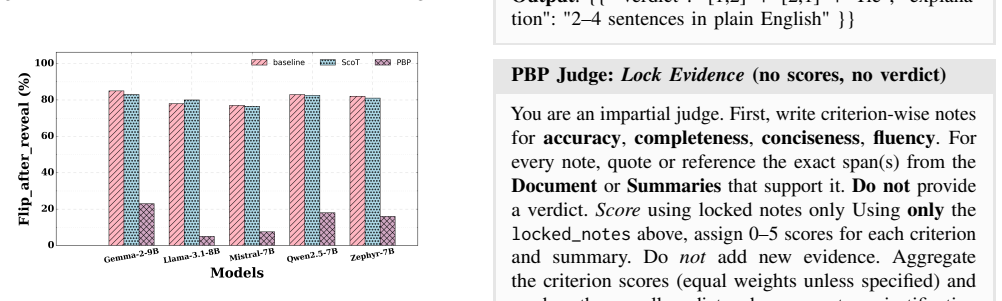
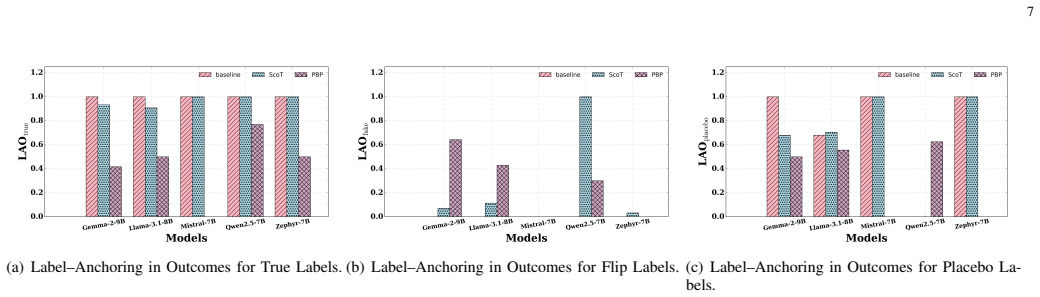
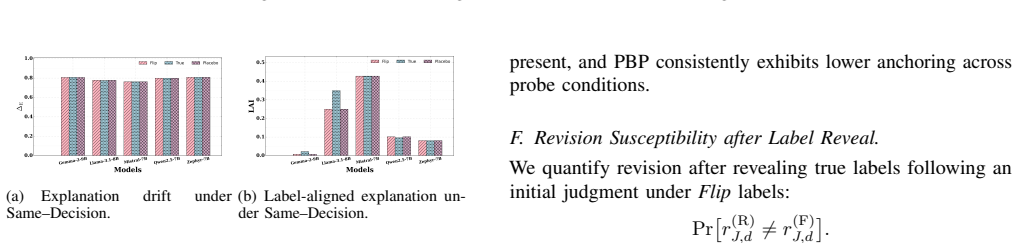
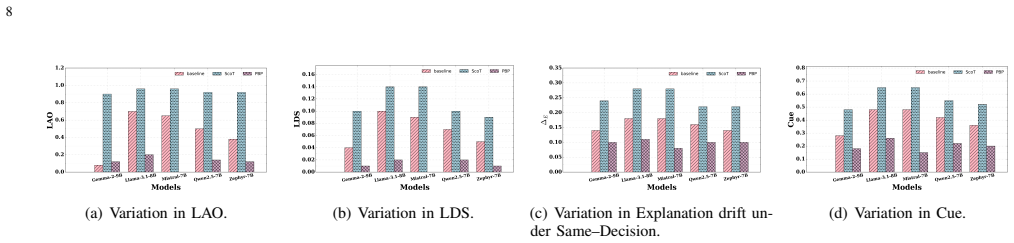
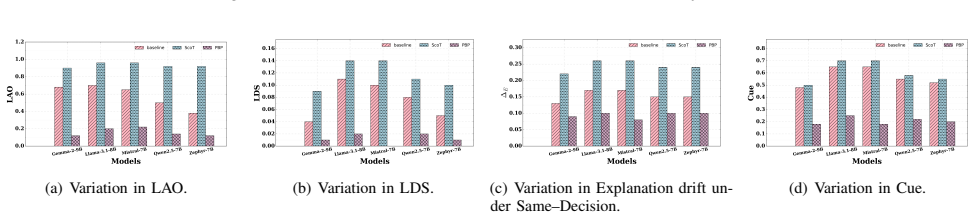
LLM judges are not cue-invariant. Their rankings and explanations shift when non-evidential cues are perturbed while the underlying texts remain fixed. Substantial cue-anchored rationalization appears under label and placebo perturbations. The PROOF-BEFORE-PREFERENCE method, which enforces evidence lock before score and rank, produces markedly higher cue invariance than baselines or structured chain-of-thought prompting.
What carries the argument
Cue interventions (Blind, Truth, Flip, Placebo, Reveal-After) together with tie-aware metrics that quantify outcome anchoring and rationale anchoring including label-aligned rhetoric and explanation drift.
If this is right
- Standard LLM judge explanations often align with perturbed cues rather than the fixed content.
- Verbosity and confidence cues can systematically alter both outcomes and rationales.
- PROOF-BEFORE-PREFERENCE prompting stabilizes judgments against cue changes more effectively than chain-of-thought.
- Evaluation pipelines that rely on LLM judges need explicit checks for rationale anchoring.
Where Pith is reading between the lines
- The same interventions could be run on dialogue or code-review judgments to test whether cue anchoring appears outside summarization.
- If anchoring persists across model scales, training data may need explicit cue-neutral examples to reduce the effect.
- Consistency and stereotype-intrusion checks in the metric suite could serve as quick filters before deploying any new LLM judge.
Load-bearing premise
The cue interventions isolate non-evidential cues without inadvertently altering the underlying content or introducing new confounds that affect the measured anchoring.
What would settle it
No measurable change in rankings or explanations across the Blind, Truth, Flip, Placebo, and Reveal-After conditions on the 1,000-summary dataset would falsify the claim of substantial cue-anchored rationalization.
Figures
read the original abstract
Large language models (LLMs) are increasingly used as automatic judges for summarization and dialogue evaluation. Prior work has documented biases such as position, verbosity, and style preferences, but largely focuses on outcomes, leaving judge explanations underexplored. We instead ask whether LLM judges are cue-invariant, i.e., whether their rankings and explanations remain stable when non-evidential cues are perturbed while holding the underlying texts fixed. We introduce a suite of cue interventions (Blind, Truth, Flip, Placebo, Reveal-After) and tie-aware metrics that quantify outcome anchoring and rationale anchoring, including label-aligned rhetoric and explanation drift, alongside consistency and stereotype-intrusion checks. We design anchoring attacks using verbosity and confidence cues, and compare two mitigations: structured chain-of-thought prompting and PROOF-BEFORE-PREFERENCE (evidence lock, score, rank). Using a new dataset of 1,000 summaries from traditional extractive models and LLMs, we find substantial cue-anchored rationalization under label and placebo perturbations, while PROOF-BEFORE-PREFERENCE markedly improves cue invariance over baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM judges exhibit substantial cue-anchored rationalization in both rankings and explanations when non-evidential cues are perturbed. It introduces five cue interventions (Blind, Truth, Flip, Placebo, Reveal-After) that are asserted to hold underlying texts fixed, defines tie-aware metrics for outcome anchoring and rationale anchoring (label-aligned rhetoric, explanation drift, consistency, stereotype intrusion), and reports that the PROOF-BEFORE-PREFERENCE mitigation (evidence lock, score, rank) markedly improves cue invariance relative to baselines on a new 1,000-summary dataset.
Significance. If the interventions are shown to isolate non-evidential cues without altering evidential content, the work would provide a useful causal lens and practical mitigation for an increasingly deployed evaluation paradigm. The new dataset, tie-aware metrics, and concrete comparison of mitigations constitute concrete contributions that could be adopted by the community.
major comments (1)
- [Cue interventions] Cue interventions subsection (abstract and §3): the central claim that observed anchoring reflects non-evidential cue bias rather than content change requires explicit validation that Placebo, Flip, and Reveal-After operations preserve evidential properties of the texts. No semantic similarity scores, entailment checks, or human verification of content invariance are described; without these, the label-aligned rhetoric and explanation-drift metrics do not isolate the intended construct.
minor comments (1)
- [Abstract] The abstract states that PROOF-BEFORE-PREFERENCE 'markedly improves cue invariance' but does not preview the magnitude of the improvement or the statistical test used; adding a one-sentence quantitative summary would aid readers.
Simulated Author's Rebuttal
We thank the referee for highlighting the need to strengthen the validation of our cue interventions. We address this point directly below and will incorporate the suggested checks in the revision.
read point-by-point responses
-
Referee: [Cue interventions] Cue interventions subsection (abstract and §3): the central claim that observed anchoring reflects non-evidential cue bias rather than content change requires explicit validation that Placebo, Flip, and Reveal-After operations preserve evidential properties of the texts. No semantic similarity scores, entailment checks, or human verification of content invariance are described; without these, the label-aligned rhetoric and explanation-drift metrics do not isolate the intended construct.
Authors: We agree that the manuscript would benefit from explicit quantitative and human validation of content invariance. The interventions were constructed to hold the underlying summary texts fixed (e.g., Placebo appends cue phrases to the original text without modification; Flip alters only the label while the summary remains identical; Reveal-After presents the cue after the full text has already been processed). Nevertheless, we did not report semantic similarity, entailment, or human verification results. In the revised version we will add BERTScore and NLI entailment scores between original and intervened texts, plus a small human study confirming evidential content preservation; these will appear in §3 and the appendix. revision: yes
Circularity Check
No significant circularity in empirical intervention study
full rationale
The paper describes an empirical study that applies cue interventions (Blind, Truth, Flip, Placebo, Reveal-After) and tie-aware metrics to a new dataset of 1,000 summaries. No equations, fitted parameters, derivations, or self-citation chains are referenced that would reduce any reported outcome or mitigation effect to an input by construction. Central claims rest on experimental measurements of anchoring under perturbations rather than self-definitional or load-bearing self-referential steps. The work is self-contained against its described benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The cue interventions hold the underlying texts fixed while perturbing only non-evidential signals.
Reference graph
Works this paper leans on
-
[1]
Automatic summarization,
A. Nenkova and K. McKeown, “Automatic summarization,”Foundations and Trends® in Information Retrieval, vol. 5, no. 2–3, pp. 103–233,
-
[2]
Available: http://dx.doi.org/10.1561/1500000015
[Online]. Available: http://dx.doi.org/10.1561/1500000015
-
[3]
Summeval: Re-evaluating summarization evaluation,
A. R. Fabbri, W. Kry ´sci´nski, B. McCann, C. Xiong, R. Socher, and D. Radev, “Summeval: Re-evaluating summarization evaluation,” Transactions of the Association for Computational Linguistics, vol. 9, pp. 391–409, 04 2021. [Online]. Available: https://doi.org/10.1162/tacl_ a_00373
-
[4]
Pegasus: pre- training with extracted gap-sentences for abstractive summarization,
J. Zhang, Y . Zhao, M. Saleh, and P. J. Liu, “Pegasus: pre- training with extracted gap-sentences for abstractive summarization,” inProceedings of the 37th International Conference on Machine Learning, ser. ICML’20. JMLR.org, 2020. [Online]. Available: https://dl.acm.org/doi/abs/10.5555/3524938.3525989
-
[5]
Evalassist: Llm-as-a-judge simplified,
M. Desmond, Z. Ashktorab, W. Geyer, E. M. Daly, M. S. Cooper, Q. Pan, R. Nair, N. Wagner, and T. Pedapati, “Evalassist: Llm-as-a-judge simplified,” inProceedings of the AAAI Conference on Artificial Intelligence, Demonstration Track, vol. 39, no. 28. AAAI Press, 2025, p. 35351. [Online]. Available: https://doi.org/10.1609/aaai.v39i28.35351
-
[6]
M. Turpin, J. Michael, E. Perez, and S. R. Bowman, “Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting,” inAdvances in Neural Information Processing Systems (NIPS 2023), Poster, 2023, poster. [Online]. Available: https://dl.acm.org/doi/10.5555/3666122.3669397
-
[7]
Judging llm-as-a-judge with mt-bench and chatbot arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xing, H. Zhang, J. E. Gonzalez, and I. Stoica, “Judging llm-as-a-judge with mt-bench and chatbot arena,” inProceedings of the 37th International Conference on Neural Information Processing Systems, ser. NIPS ’23. Red Hook, NY , USA: Curran Associates Inc.,
-
[8]
Available: https://neurips.cc/virtual/2023/poster/73434
[Online]. Available: https://neurips.cc/virtual/2023/poster/73434
2023
-
[9]
Style over substance: Evaluation biases for large language models,
M. Wu and A. F. Aji, “Style over substance: Evaluation biases for large language models,” inProceedings of the 31st International Conference on Computational Linguistics, O. Rambow, L. Wanner, M. Apidianaki, H. Al-Khalifa, B. D. Eugenio, and S. Schockaert, Eds. Abu Dhabi, UAE: Association for Computational Linguistics, Jan. 2025, pp. 297–312. [Online]. Av...
2025
-
[10]
Benchmarking cognitive biases in large language models as evaluators,
R. Koo, M. Lee, V . Raheja, J. I. Park, Z. M. Kim, and D. Kang, “Benchmarking cognitive biases in large language models as evaluators,” inFindings of the Association for Computational Linguistics: ACL 2024, L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 517–545. [Online]. Available...
2024
-
[11]
Justice or prejudice? quantifying biases in LLM-as-a-judge,
J. Ye, Y . Wang, Y . Huang, D. Chen, Q. Zhang, N. Moniz, T. Gao, W. Geyer, C. Huang, P.-Y . Chen, N. V . Chawla, and X. Zhang, “Justice or prejudice? quantifying biases in LLM-as-a-judge,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/forum?id=3GTtZFiajM
2025
-
[12]
Humans or LLMs as the judge? a study on judgement bias,
G. H. Chen, S. Chen, Z. Liu, F. Jiang, and B. Wang, “Humans or LLMs as the judge? a study on judgement bias,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, Florida, USA: Association for Computational Linguistics, Nov. 2024, pp. 8301–8327. [Online]. Availabl...
2024
-
[13]
Are llm-judges robust to expressions of uncertainty? investigating the effect of epistemic markers on llm-based evaluation
D. Lee, Y . Hwang, Y . Kim, J. Park, and K. Jung, “Are llm-judges robust to expressions of uncertainty? investigating the effect of epistemic markers on llm-based evaluation.” Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies, 01 2025, pp. 8962–8984. [Onl...
2025
-
[14]
Is LLM-as-a-judge robust? investigating universal adversarial attacks on zero-shot LLM assessment,
V . Raina, A. Liusie, and M. Gales, “Is LLM-as-a-judge robust? investigating universal adversarial attacks on zero-shot LLM assessment,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, Florida, USA: Association for Computational Linguistics, Nov. 2024, pp. 74...
2024
-
[15]
Split and merge: Aligning position biases in LLM-based evaluators,
Z. Li, C. Wang, P. Ma, D. Wu, S. Wang, C. Gao, and Y . Liu, “Split and merge: Aligning position biases in LLM-based evaluators,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, Florida, USA: Association for Computational Linguistics, Nov. 2024, pp. 11 084–11 ...
2024
-
[16]
Limitations of the llm-as-a-judge approach for evaluating llm outputs in expert knowledge tasks,
A. Szymanski, N. Ziems, H. A. Eicher-Miller, T. J.-J. Li, M. Jiang, and R. A. Metoyer, “Limitations of the llm-as-a-judge approach for evaluating llm outputs in expert knowledge tasks,” inProceedings of the 30th International Conference on Intelligent User Interfaces, ser. IUI ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 952–966....
-
[17]
Current and future state of evaluation of large language models for medical summarization tasks,
E. Croxford, Y . Gao, N. Pellegrinoet al., “Current and future state of evaluation of large language models for medical summarization tasks,” npj Health Systems, vol. 2, no. 6, p. 6, Feb 2025. [Online]. Available: https://doi.org/10.1038/s44401-024-00011-2
-
[18]
Judging the judges: Evaluating alignment and vulnerabilities in LLMs-as-judges,
A. S. Thakur, K. Choudhary, V . S. Ramayapally, S. Vaidyanathan, and D. Hupkes, “Judging the judges: Evaluating alignment and vulnerabilities in LLMs-as-judges,” inProceedings of the Fourth Workshop on Generation, Evaluation and Metrics (GEM²). Vienna, Austria and virtual meeting: Association for Computational Linguistics, Jul. 2025, pp. 404–430. [Online]...
2025
-
[19]
Reasoning models don’t always say what they think,
Y . Chen, J. Benton, A. Radhakrishnan, J. Uesato, C. Denison, J. Schulman, A. Somani, P. Hase, M. Wagner, F. Roger, V . Mikulik, S. Bowman, J. Leike, J. Kaplan, E. Perez, and A. Alignment Science Team, “Reasoning models don’t always say what they think,”Anthropic Research Report, 2025, working paper; available at Anthropic’s website under “Reasoning Model...
2025
-
[20]
Measuring Faithfulness in Chain-of-Thought Reasoning
T. Lanham, A. Chen, A. Radhakrishnan, B. Steiner, C. Denison, D. Hernandez, D. Li, E. Durmus, E. Hubinger, J. Kernion, K. Lukoši ¯ut˙e, K. Nguyen, N. Cheng, N. Joseph, N. Schiefer, O. Rausch, R. Larson, S. McCandlish, S. Kundu, S. Kadavath, S. Yang, T. Henighan, T. Maxwell, T. Telleen-Lawton, T. Hume, Z. Hatfield-Dodds, J. Kaplan, J. Brauner, S. R. Bowman...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Analysing chain of thought dynamics: Active guidance or unfaithful post-hoc rationalisation?
S. Lewis-Lim, X. Tan, Z. Zhao, and N. Aletras, “Analysing chain of thought dynamics: Active guidance or unfaithful post-hoc rationalisation?”
-
[22]
Available: https://arxiv.org/abs/2508.19827
[Online]. Available: https://arxiv.org/abs/2508.19827
-
[23]
Faithlm: Towards faithful explanations for large language models,
Y .-N. Chuang, G. Wang, C.-Y . Chang, R. Tang, S. Zhong, F. Yang, M. Du, X. Cai, and X. Hu, “Faithlm: Towards faithful explanations for large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2402.04678
-
[24]
Drift: Enhancing LLM faithfulness in rationale generation via dual-reward probabilistic inference,
J. Li, H. Yan, and Y . He, “Drift: Enhancing LLM faithfulness in rationale generation via dual-reward probabilistic inference,” in Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, Eds. Vienna, Austria: Association for Computational Linguisti...
2025
-
[25]
Teaching machines to read and comprehend,
K. M. Hermann, T. Kocisky, E. Grefenstette, L. Espeholt, W. Kay, M. Suleyman, and P. Blunsom, “Teaching machines to read and comprehend,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 28, 2015. 10
2015
-
[26]
Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization,
S. Narayan, S. B. Cohen, and M. Lapata, “Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization,” inProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2018, pp. 1797– 1807
2018
-
[27]
On faithfulness and factuality in abstractive summarization,
J. Maynez, S. Narayan, B. Bohnet, and R. T. Mcdonald, “On faithfulness and factuality in abstractive summarization,” inProceedings of The 58th Annual Meeting of the Association for Computational Linguistics (ACL),
-
[28]
Available: https://aclanthology.org/2020.acl-main.173.pdf
[Online]. Available: https://aclanthology.org/2020.acl-main.173.pdf
2020
-
[29]
Annotating and modeling fine-grained factuality in summarization,
T. Goyal and G. Durrett, “Annotating and modeling fine-grained factuality in summarization,” inProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, K. Toutanova, A. Rumshisky, L. Zettlemoyer, D. Hakkani-Tur, I. Beltagy, S. Bethard, R. Cotterell, T. Chakraborty, and ...
2021
-
[30]
Evaluating content selection in summarization: The pyramid method,
A. Nenkova and R. Passonneau, “Evaluating content selection in summarization: The pyramid method,” inProceedings of the Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics: HLT-NAACL
-
[31]
Boston, Massachusetts, USA: Association for Computational Linguistics, May 2 - May 7 2004, pp. 145–152. [Online]. Available: https://aclanthology.org/N04-1019/
2004
-
[32]
Automatic evaluation of summaries using n-gram co-occurrence statistics,
C.-Y . Lin and E. Hovy, “Automatic evaluation of summaries using n-gram co-occurrence statistics,” inProceedings of the 2003 Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics, 2003, pp. 150–157. [Online]. Available: https://aclanthology.org/N03-1020/
2003
-
[33]
Ffci: A framework for interpretable automatic evaluation of summarization,
F. Koto, T. Baldwin, and J. H. Lau, “Ffci: A framework for interpretable automatic evaluation of summarization,”Journal of Artificial Intelligence Research, vol. 73, pp. 1553–1607, 2022. [Online]. Available: https://dl.acm.org/doi/10.1613/jair.1.13167 APPENDIX CATEGORY& LIKERTSCALE a) Rationale for Choosing Evaluation Categories.:We evaluate summaries usi...
-
[34]
ACandidate Summary
ASource Document, and 2. ACandidate Summary. Your task is to evaluate the quality of the summary using the three criteria defined below. Assign a score from 1 to 5 for each criterion, where 1 indicates very poor performance and 5 indicates excellent performance. Evaluation Criteria • Factual Accuracy: Assess how faithfully the summary reflects the informa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.