MemForest: An Efficient Agent Memory System with Hierarchical Temporal Indexing
Pith reviewed 2026-06-30 19:24 UTC · model grok-4.3
The pith
MemForest treats agent memory as a temporal indexing problem solved by parallel chunk extraction and localized tree-path updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
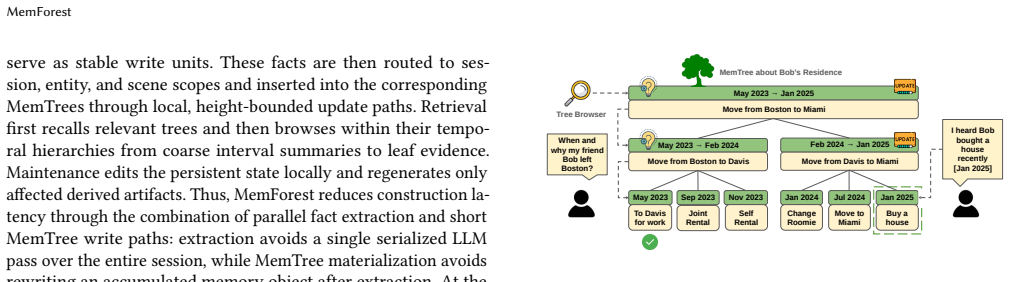
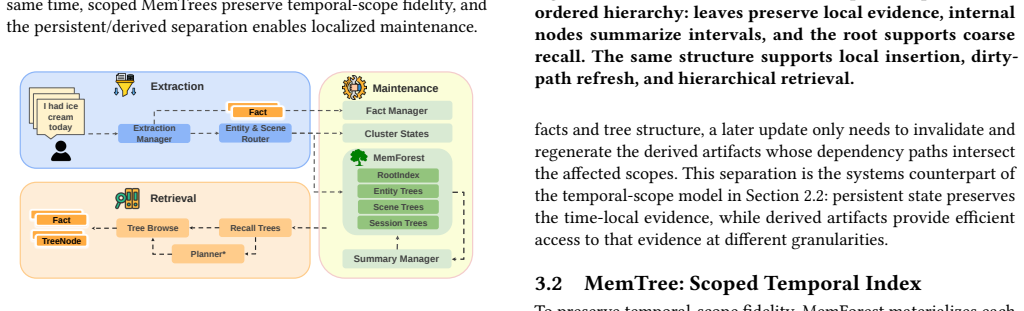
MemForest decouples memory construction into concurrent independent operations through parallel chunk extraction and replaces full-state rewrites with localized per-node updates on MemTree, a hierarchical temporal index that organizes memory as time-ordered trees, thereby reducing maintenance cost to the affected tree paths while naturally preserving temporally evolving states.
What carries the argument
MemTree, the hierarchical temporal index that organizes memory as time-ordered trees and supports localized per-node updates instead of full-state rewrites.
If this is right
- Memory maintenance cost is confined to affected tree paths rather than entire states.
- Construction throughput scales independently of sequential LLM inference bottlenecks.
- Temporally evolving states remain preserved without explicit full reconciliation.
- The system attains the highest overall accuracy among stateful baselines on the evaluated long-context benchmarks.
Where Pith is reading between the lines
- The same localized-update principle could apply to other persistent state stores that accumulate over long sessions.
- Further scaling of interaction length would likely show sub-linear growth in per-step latency.
- The parallel extraction layer might integrate with streaming data sources beyond agent logs.
Load-bearing premise
Localized per-node updates along the hierarchical temporal index are sufficient to preserve all necessary temporally evolving agent states without information loss or full-state reconciliation.
What would settle it
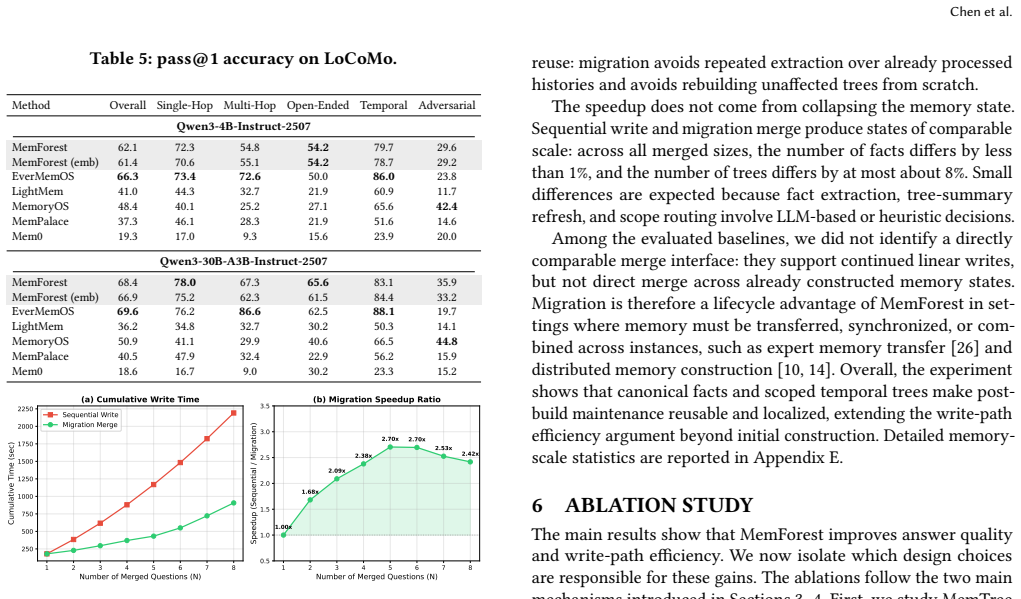
Running MemForest on LongMemEval-S and observing either pass@1 accuracy substantially below 79.8 percent or memory construction throughput not reaching approximately six times that of prior stateful baselines would falsify the central performance claims.
Figures


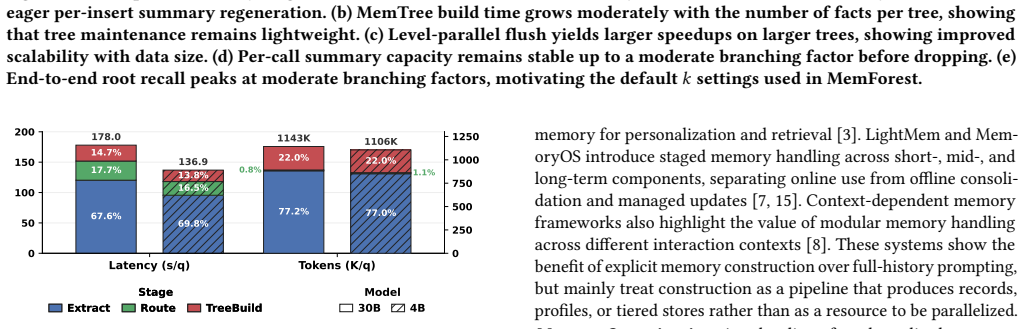
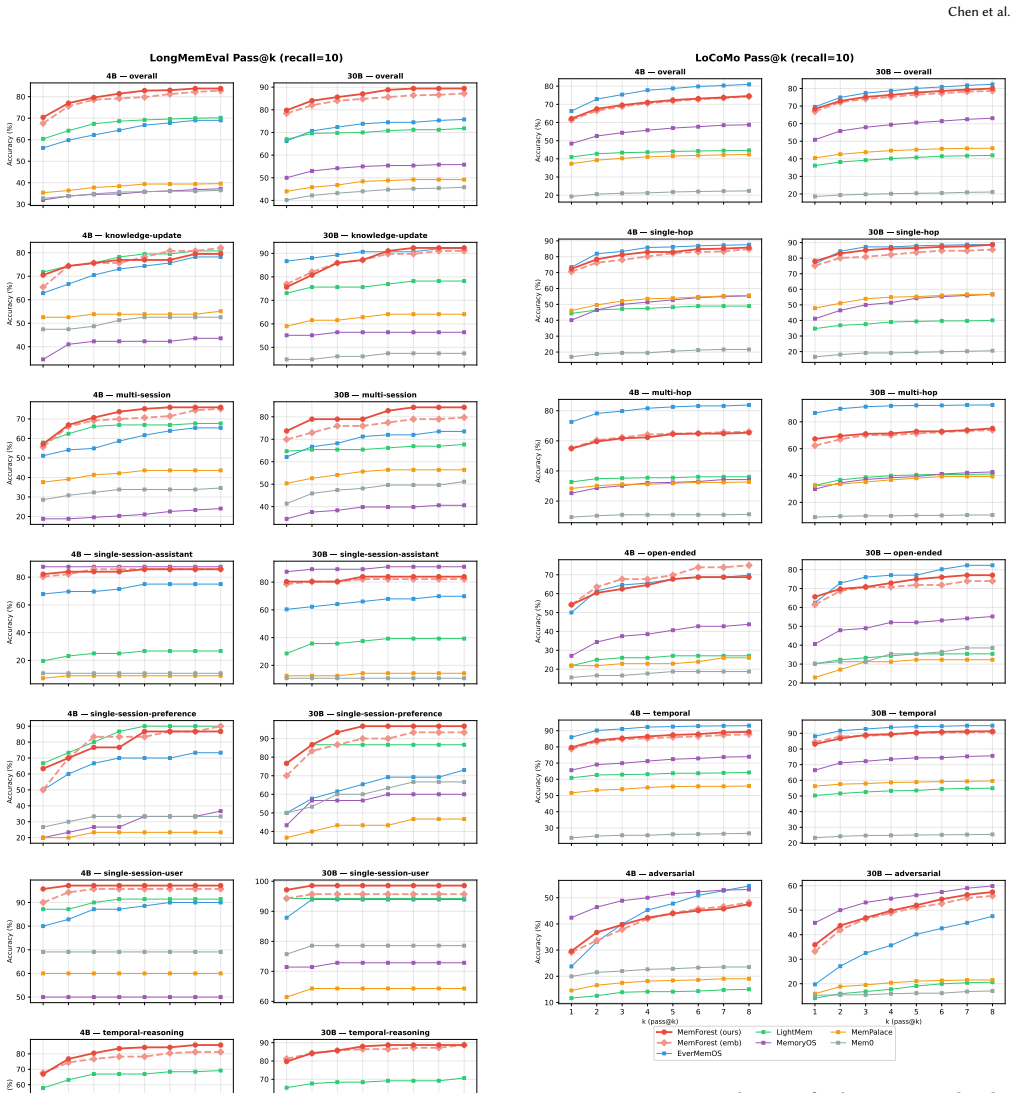
read the original abstract
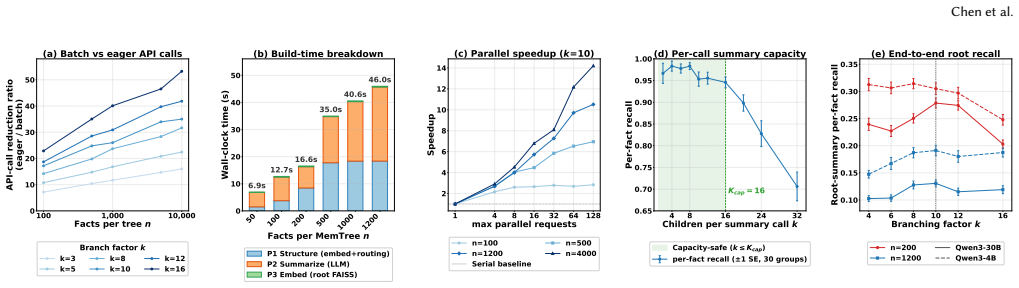
Memory is a fundamental component for enabling long-context LLM agents, supporting persistent state across interactions through a continuous serve-and-update lifecycle. Despite substantial prior work, existing systems suffer from significant maintenance overhead due to two key limitations: coarse-grained state management and inherently sequential update pipelines. In particular, updates are often tightly coupled with LLM inference and require full-state rewrites, leading to poor scalability and growing latency as memory accumulates. To address these challenges, we present MemForest, a memory framework that reformulates agent memory as a write-efficient temporal data management problem. MemForest breaks the sequential bottleneck via parallel chunk extraction, decoupling memory construction into concurrent, independent operations. To further eliminate coarse-grained maintenance, we introduce MemTree, a hierarchical temporal index that organizes memory as time-ordered trees rather than flat global summaries. This design replaces full-state rewrites with localized per-node updates, reducing maintenance cost to the affected tree paths while naturally preserving temporally evolving states. We evaluate MemForest on two long-context memory benchmarks, LongMemEval-S and LoCoMo. On LongMemEval-S, MemForest achieves the best overall performance among stateful baselines, reaching 79.8% pass@1 accuracy while sustaining a memory construction throughput approximately 6x higher than state-of-the-art approaches including EverMemOS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents MemForest, a memory framework for long-context LLM agents that reformulates agent memory as a write-efficient temporal data management problem. It decouples memory construction via parallel chunk extraction and introduces MemTree, a hierarchical temporal index organizing memory as time-ordered trees. This enables localized per-node updates rather than full-state rewrites. On LongMemEval-S, it reports 79.8% pass@1 accuracy (best among stateful baselines) and ~6x higher memory construction throughput than approaches including EverMemOS; similar claims are made for LoCoMo.
Significance. If the performance claims and design assumptions hold, the work could meaningfully advance scalable persistent memory for LLM agents by addressing coarse-grained maintenance and sequential update bottlenecks. The parallel extraction and tree-based localized updates represent a concrete engineering advance over flat global summaries.
major comments (2)
- [Evaluation] Evaluation section: The reported 79.8% pass@1 accuracy and 6x throughput gains are presented without baseline descriptions, statistical tests, error bars, data exclusion rules, or variance across runs. This directly undermines the central claim of best overall performance among stateful baselines, as the numbers cannot be assessed for significance or reproducibility.
- [MemTree design] MemTree design (hierarchical temporal index): The claim that localized per-node updates on time-ordered trees preserve all temporally evolving agent states without information loss rests on the unexamined assumption that cross-branch temporal dependencies do not exist or do not affect future queries. No formal argument, invariant, or targeted experiment (e.g., on LoCoMo cases with facts updated in one chunk affecting later unrelated chunks) is supplied to support this load-bearing assumption.
minor comments (1)
- [Abstract] The abstract states specific accuracy and throughput numbers but supplies no experimental details; this should be expanded in the abstract or a dedicated experimental-setup subsection for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important areas for improving the clarity and rigor of our evaluation and design justification. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The reported 79.8% pass@1 accuracy and 6x throughput gains are presented without baseline descriptions, statistical tests, error bars, data exclusion rules, or variance across runs. This directly undermines the central claim of best overall performance among stateful baselines, as the numbers cannot be assessed for significance or reproducibility.
Authors: We agree that the evaluation section requires additional details to support reproducibility and allow assessment of statistical significance. In the revised manuscript, we will expand this section to provide full descriptions of all baselines (including their configurations and implementation details), report standard deviations and confidence intervals across multiple runs (e.g., 5 independent runs), include error bars in figures, explicitly state data exclusion rules (none were applied beyond the standard protocols of LongMemEval-S and LoCoMo), and add variance metrics. These additions will directly address the concerns and strengthen the performance claims. revision: yes
-
Referee: [MemTree design] MemTree design (hierarchical temporal index): The claim that localized per-node updates on time-ordered trees preserve all temporally evolving agent states without information loss rests on the unexamined assumption that cross-branch temporal dependencies do not exist or do not affect future queries. No formal argument, invariant, or targeted experiment (e.g., on LoCoMo cases with facts updated in one chunk affecting later unrelated chunks) is supplied to support this load-bearing assumption.
Authors: The MemTree design structures memory as time-ordered hierarchical trees, with each node holding a temporal chunk; localized updates modify only the path to the affected node, and queries traverse from the root to collect relevant states while respecting temporal order within branches. This avoids full rewrites and preserves evolving states by design. We acknowledge that the manuscript does not provide an explicit formal invariant or targeted experiment addressing potential cross-branch dependencies. In revision, we will add a dedicated subsection formalizing the invariants (e.g., that all temporally relevant facts remain accessible via ancestor paths) and include a new experiment on LoCoMo subsets involving cross-chunk fact updates to empirically demonstrate preservation of information. revision: yes
Circularity Check
No circularity: empirical system evaluation on external benchmarks
full rationale
The paper introduces MemForest and MemTree as a new hierarchical temporal index for agent memory, motivated by limitations in prior systems (coarse-grained management, sequential updates, full-state rewrites). All performance claims (79.8% pass@1 on LongMemEval-S, 6x throughput vs. EverMemOS) are presented as results of implementation and benchmarking on named external datasets (LongMemEval-S, LoCoMo). No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or description. The design is justified by addressing stated problems rather than reducing to self-referential definitions or imported uniqueness theorems. This is a standard systems contribution whose validity rests on reproducible external benchmarks, not internal circular reduction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
MemTree
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shubham Agarwal, Sai Sundaresan, Subrata Mitra, Debabrata Mahapatra, Ar- chit Gupta, Rounak Sharma, Nirmal Joshua Kapu, Tong Yu, and Shiv Saini
-
[2]
Cache-Craft: Managing Chunk-Caches for Efficient Retrieval-Augmented Generation.Proc. ACM Manag. Data3, 3, Article 136 (June 2025), 28 pages. https://doi.org/10.1145/3725273
-
[3]
Bruno Becker, Stephan Gschwind, Thomas Ohler, Bernhard Seeger, and Peter Widmayer. 1996. An asymptotically optimal multiversion B-tree.The VLDB Journal5, 4 (1996), 264–275
1996
-
[4]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Ya- dav. 2025. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Tri Dao. 2024. FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. InInternational Conference on Learning Representations (ICLR)
2024
-
[6]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2024. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Ramez Elmasri, Gene TJ Wuu, and Yeong-Joon Kim. 1990. The time index: An access structure for temporal data. InProceedings of the 16th International Conference on Very Large Data Bases. 1–12
1990
-
[8]
Jizhan Fang, Xinle Deng, Haoming Xu, Ziyan Jiang, Yuqi Tang, Ziwen Xu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, Huajun Chen, and Ningyu Zhang
-
[9]
InThe Fourteenth International Conference on Learning Representations
LightMem: Lightweight and Efficient Memory-Augmented Generation. InThe Fourteenth International Conference on Learning Representations. https: //openreview.net/forum?id=dyJ0GWpjJB
-
[10]
Pengyu Gao, Jinming Zhao, Xinyue Chen, and Long Yilin. 2025. An efficient context-dependent memory framework for llm-centric agents. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 3: Industry Track). 1055–1069
2025
-
[11]
Yubin Ge, Salvatore Romeo, Jason Cai, Raphael Shu, Yassine Benajiba, Monica Sunkara, and Yi Zhang. 2025. Tremu: Towards neuro-symbolic temporal reason- ing for llm-agents with memory in multi-session dialogues. InFindings of the Association for Computational Linguistics: ACL 2025. 18974–18988
2025
- [12]
- [13]
-
[14]
Guoyu Hu, Shaofeng Cai, Tien Tuan Anh Dinh, Zhongle Xie, Cong Yue, Gang Chen, and Beng Chin Ooi. 2025. HAKES: Scalable Vector Database for Embedding Search Service.Proceedings of the VLDB Endowment18, 9 (2025), 3049–3062
2025
-
[15]
Mengkang Hu, Tianxing Chen, Qiguang Chen, Yao Mu, Wenqi Shao, and Ping Luo. 2025. Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large language model. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 32779–32798
2025
-
[16]
Paul Jackson and Jane Klobas. 2008. Transactive memory systems in organi- zations: Implications for knowledge directories.Decision support systems44, 2 (2008), 409–424
2008
-
[17]
Jiazheng Kang, Mingming Ji, Zhe Zhao, and Ting Bai. 2025. Memory os of ai agent. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 25972–25981
2025
-
[18]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al . 2025. Deepseek- v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [19]
-
[20]
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. 2024. Evaluating very long-term conversational memory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 13851–13870
2024
-
[21]
2026.MemPalace
milla-jovovich. 2026.MemPalace. https://github.com/milla-jovovich/mempalace
2026
-
[22]
Patrick O’Neil, Edward Cheng, Dieter Gawlick, and Elizabeth O’Neil. 1996. The log-structured merge-tree (LSM-tree).Acta informatica33, 4 (1996), 351–385
1996
-
[23]
Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonzalez. 2023. MemGPT: towards LLMs as operating systems. (2023)
2023
-
[24]
Vicky Zhao, Lili Qiu, and Jianfeng Gao
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Xufang Luo, Hao Cheng, Dongsheng Li, Yuqing Yang, Chin-Yew Lin, H. Vicky Zhao, Lili Qiu, and Jianfeng Gao. 2025. SeCom: On Memory Construction and Retrieval for Personalized Conversational Agents. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=xKDZAW0He3
2025
-
[25]
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Menglin Xia, Xufang Luo, Jue Zhang, Qingwei Lin, Victor Rühle, Yuqing Yang, Chin-Yew Lin, et al. 2024. Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression. In Findings of the Association for Computational Linguistics: ACL 2024. 963–981
2024
-
[26]
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology. 1–22
2023
-
[27]
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. 2025. Zep: a temporal knowledge graph architecture for agent memory. arXiv preprint arXiv:2501.13956(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Alireza Rezazadeh, Zichao Li, Ange Lou, Yuying Zhao, Wei Wei, and Yujia Bao
- [29]
-
[30]
Alireza Rezazadeh, Zichao Li, Wei Wei, and Yujia Bao. 2025. From Isolated Conversations to Hierarchical Schemas: Dynamic Tree Memory Representation for LLMs. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=moXtEmCleY
2025
-
[31]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D Manning. 2024. Raptor: Recursive abstractive processing for tree-organized retrieval. InThe Twelfth International Conference on Learning Representations
2024
-
[32]
Ji Sun, Guoliang Li, James Pan, Jiang Wang, Yongqing Xie, Ruicheng Liu, and Wen Nie. 2025. GaussDB-Vector: A Large-Scale Persistent Real-Time Vector Database for LLM Applications.Proceedings of the VLDB Endowment18, 12 (2025), 4951–4963
2025
-
[33]
Zhen Tan, Jun Yan, I-Hung Hsu, Rujun Han, Zifeng Wang, Long Le, Yiwen Song, Yanfei Chen, Hamid Palangi, George Lee, et al. 2025. In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 8416–8439
2025
-
[34]
Zhenheng Tang, Xin He, Tiancheng Zhao, Fanjunduo Wei, Xiang Liu, Peijie Dong, Qian Wang, Qi Li, Huacan Wang, Ronghao Chen, et al. 2026. LLM Agent Memory: A Survey from a Unified Representation–Management Perspective. (2026)
2026
-
[35]
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu
-
[36]
InThe Thirteenth International Conference on Learning Representations
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=pZiyCaVuti
-
[37]
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang
-
[38]
InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
A-Mem: Agentic Memory for LLM Agents. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/ forum?id=FiM0M8gcct
-
[39]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical Chen et al. report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Zihe Ye, Jingyuan Huang, Weixin Chen, and Yongfeng Zhang. 2026. H-Mem: Hybrid Multi-Dimensional Memory Management for Long-Context Conversa- tional Agents. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 7756–7775
2026
-
[41]
Runjie Yu, Weizhou Huang, Shuhan Bai, Jian Zhou, and Fei Wu. 2025. AquaPipe: A Quality-Aware Pipeline for Knowledge Retrieval and Large Language Models. Proc. ACM Manag. Data3, 1, Article 11 (Feb. 2025), 26 pages. https://doi.org/10. 1145/3709661
2025
- [42]
-
[43]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. 2025. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Zeyu Zhang, Quanyu Dai, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. 2025. A survey on the memory mechanism of large language model-based agents.ACM Transactions on Information Systems 43, 6 (2025), 1–47
2025
-
[45]
label":
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. 2024. Memo- rybank: Enhancing large language models with long-term memory. InProceedings of the AAAI conference on artificial intelligence, Vol. 38. 19724–19731. MemForest A PROMPTS A.1 LLM-as-Judge Prompts LongMemEval Judge Prompt Your task is to label an answer to a LongMemEval question as C...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.