A Tabular Schedule Abstraction for Communication-Aware Evaluation of Pipeline-Parallel LLM Training
Pith reviewed 2026-06-30 18:12 UTC · model grok-4.3
The pith
Communication costs can reverse which pipeline schedule ranks highest for large language model training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
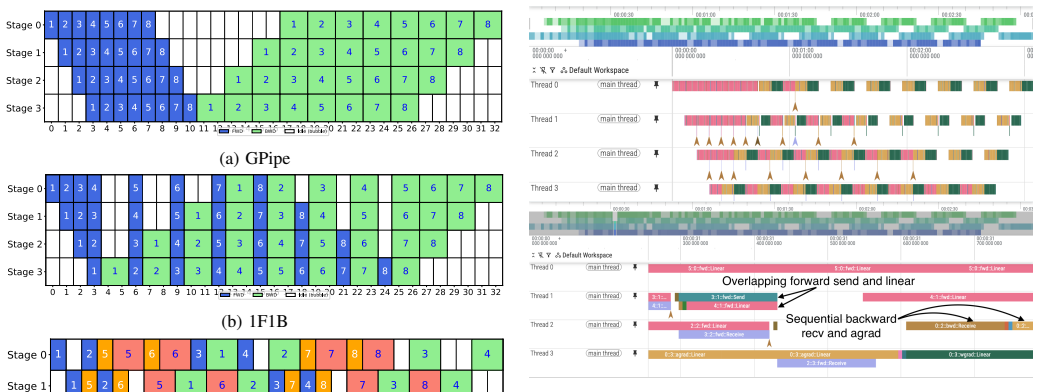
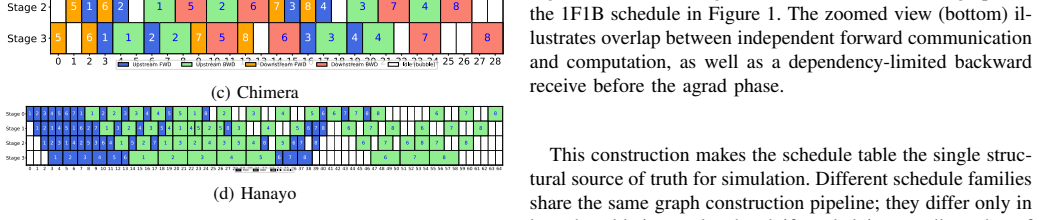
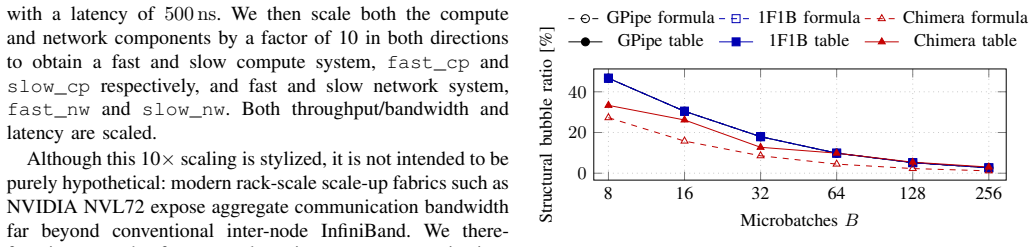
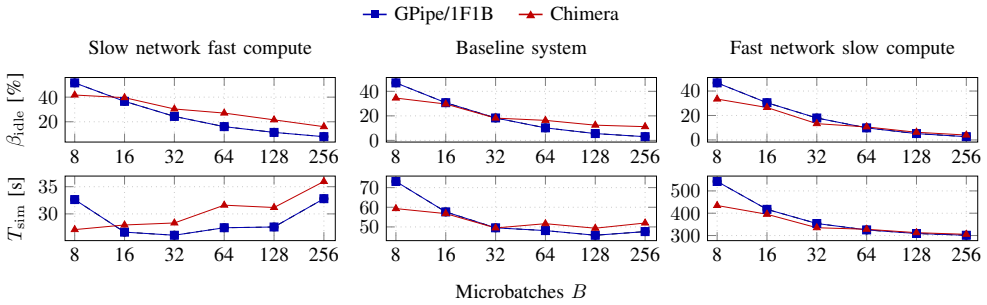
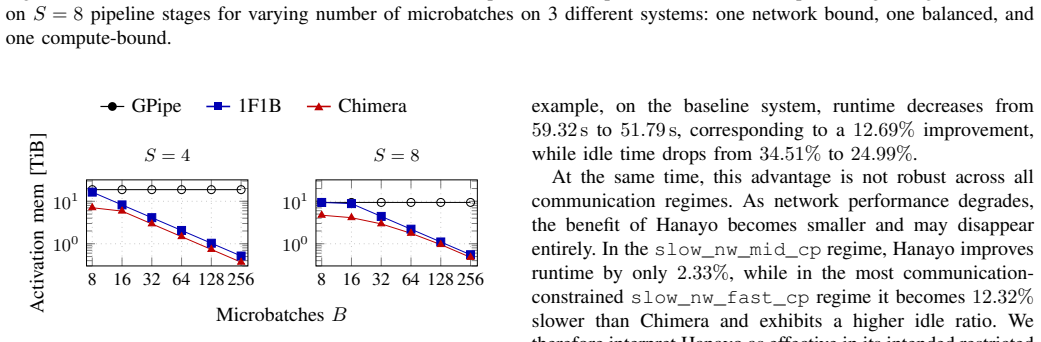
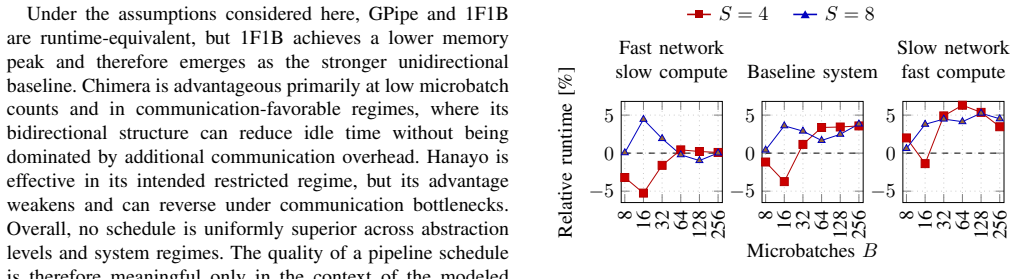
A tabular schedule abstraction unifies formula reasoning, idealized tables, and execution simulation, demonstrating that schedule rankings are not abstraction-invariant. Communication can negate structural advantages visible in bubble analysis alone. Under the assumptions considered, GPipe and 1F1B are runtime-equivalent while 1F1B achieves a lower activation-memory peak; Chimera is advantageous mainly at low microbatch counts in communication-favorable regimes; Hanayo works in its intended restricted operating point but remains sensitive to network bottlenecks.
What carries the argument
The tabular schedule abstraction, which represents pipeline execution at multiple fidelity levels to incorporate communication effects into comparisons of GPipe, 1F1B, Chimera, and Hanayo.
If this is right
- Schedule quality is meaningful only inside a modeled execution environment that includes communication.
- GPipe and 1F1B deliver identical runtimes, so 1F1B can be selected for its lower memory peak without runtime penalty.
- Chimera's advantage appears mainly at low microbatch counts and in low-latency communication settings.
- Hanayo remains effective only inside its restricted operating regime and degrades under network pressure.
- Asymmetric Chimera-style placements do not lower global peak memory and yield only limited runtime gains in shallow pipelines.
Where Pith is reading between the lines
- Designers of distributed training systems may need to re-evaluate schedule choice whenever network parameters change.
- The abstraction could be applied to additional schedules or deeper pipelines to check whether the same ranking shifts occur.
- Without communication modeling, structural metrics alone may recommend schedules that underperform once deployed.
Load-bearing premise
The modeled system configurations and the restricted operating regime for Hanayo are representative enough that the observed ranking changes will hold on real hardware.
What would settle it
Executing the compared schedules on physical GPU clusters using the modeled configurations and network parameters, then measuring whether the runtime and memory ordering matches the abstraction predictions.
Figures
read the original abstract
Pipeline parallelism is a key technique for distributed training of large language models because it reduces per-device parameter and activation memory. However, comparing pipeline schedules is difficult: analytical models expose structural quantities such as bubble ratios, while end-to-end hardware experiments are costly and system-specific. In this work, we introduce a tabular schedule abstraction and a unified multi-abstraction methodology that connects formula-based reasoning, idealized schedule tables, and communication-aware execution simulation. Using this framework, we compare GPipe, 1F1B, Chimera, and Hanayo in its restricted regime across multiple modeled system configurations. Our results show that schedule rankings are not abstraction-invariant: communication can negate structural advantages suggested by bubble analysis alone. Under the assumptions considered here, GPipe and 1F1B are runtime-equivalent, but 1F1B achieves a lower activation-memory peak. Chimera is advantageous mainly at low microbatch counts and in communication-favorable regimes, while Hanayo is effective in its intended restricted operating point but remains sensitive to network bottlenecks. We further study an asymmetric Chimera-style placement, which does not reduce the global peak memory requirement but reveals limited runtime gains in shallow pipelines. Overall, pipeline schedule quality is meaningful only in the context of the modeled execution environment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a tabular schedule abstraction together with a unified multi-abstraction methodology that links formula-based bubble analysis, idealized schedule tables, and communication-aware execution simulation. Using this framework the authors compare GPipe, 1F1B, Chimera, and Hanayo (restricted regime) across several modeled system configurations and conclude that schedule rankings are not abstraction-invariant: communication can negate structural advantages visible from bubble ratios alone. Under the modeled assumptions GPipe and 1F1B are reported runtime-equivalent while 1F1B exhibits a lower activation-memory peak; Chimera is advantageous mainly at low micro-batch counts and in communication-favorable regimes, and Hanayo is effective only inside its intended operating point but sensitive to network bottlenecks.
Significance. If the simulation results prove representative, the work supplies a practical, low-cost methodology for communication-aware schedule evaluation that sits between purely analytical bubble ratios and expensive end-to-end hardware campaigns. The explicit demonstration that rankings shift once communication is modeled is a useful cautionary result for the pipeline-parallelism literature. The tabular abstraction itself appears reusable and the connection of three abstraction levels is a methodological contribution.
major comments (2)
- [§5] §5 (Evaluation) and the abstract: the central claims—runtime equivalence of GPipe and 1F1B, lower activation peak for 1F1B, and the reported ranking reversals—are obtained exclusively from the tabular abstraction and the communication-aware simulator run on a set of modeled system configurations. No direct comparison of simulated versus measured hardware behavior (same schedules, same collectives, same NIC) is presented, so the representativeness of those configurations remains an untested load-bearing assumption.
- [§4] §4 (Methodology) and §5: the paper states that “under the assumptions considered here” the equivalences hold, yet the free parameters (modeled system configurations) are not accompanied by a sensitivity study or bounds showing how far the reported ranking changes survive perturbations in bandwidth, latency, or collective implementation overhead.
minor comments (1)
- Figure captions and axis labels in the results section should explicitly state the exact micro-batch counts, pipeline depths, and network parameters used for each plotted point so that readers can reproduce the modeled configurations without consulting the text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the methodological contribution of the tabular abstraction. We address each major comment below, clarifying scope and indicating revisions where appropriate.
read point-by-point responses
-
Referee: [§5] §5 (Evaluation) and the abstract: the central claims—runtime equivalence of GPipe and 1F1B, lower activation peak for 1F1B, and the reported ranking reversals—are obtained exclusively from the tabular abstraction and the communication-aware simulator run on a set of modeled system configurations. No direct comparison of simulated versus measured hardware behavior (same schedules, same collectives, same NIC) is presented, so the representativeness of those configurations remains an untested load-bearing assumption.
Authors: We agree that the absence of hardware measurements leaves the representativeness of the modeled configurations as an assumption rather than an empirically validated claim. The manuscript's contribution is the multi-abstraction methodology itself; all quantitative statements are already qualified with the phrase 'under the assumptions considered here.' In revision we have added a dedicated limitations paragraph in §5 that explicitly discusses the gap between simulation and hardware, the modeled NIC and collective assumptions, and the desirability of future end-to-end validation. This scopes the claims without altering the core results. revision: partial
-
Referee: [§4] §4 (Methodology) and §5: the paper states that “under the assumptions considered here” the equivalences hold, yet the free parameters (modeled system configurations) are not accompanied by a sensitivity study or bounds showing how far the reported ranking changes survive perturbations in bandwidth, latency, or collective implementation overhead.
Authors: We have performed the requested sensitivity study. In the revised manuscript we added a new subsection to §5 that re-executes the simulator while scaling modeled bandwidth and latency by factors of 0.5×–2× and varying collective overhead by ±30 %. The runtime equivalence of GPipe and 1F1B, the memory advantage of 1F1B, and the ranking reversal relative to pure bubble analysis remain stable inside this range; Chimera's advantage at low micro-batch counts is more sensitive to communication parameters, which we now quantify with an additional plot. The new material is presented as a bounded sensitivity result rather than an exhaustive exploration. revision: yes
Circularity Check
No circularity: results derived from independent simulation on modeled configurations
full rationale
The paper defines a tabular schedule abstraction and applies it within a multi-abstraction methodology to simulate GPipe, 1F1B, Chimera, and Hanayo across chosen system parameters. Reported outcomes such as runtime equivalence between GPipe and 1F1B, lower activation-memory peak for 1F1B, and ranking shifts due to communication are direct outputs of that simulation under explicit assumptions; they do not reduce by construction to fitted parameters, self-definitions, or self-citations. The derivation chain remains self-contained against external benchmarks because the modeled configurations and restricted regimes are stated inputs, not outputs renamed as predictions.
Axiom & Free-Parameter Ledger
free parameters (1)
- modeled system configurations
axioms (1)
- domain assumption The restricted regime for Hanayo is the appropriate operating point for its evaluation.
Reference graph
Works this paper leans on
-
[1]
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amo...
-
[2]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,”CoRR/2001.08361, 2020. [Online]. Available: https://arxiv.org/abs/2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[3]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro, “Megatron-lm: Training multi-billion parameter language models using model parallelism,”CoRR/1909.08053, 2020. [Online]. Available: https://arxiv.org/abs/1909.08053
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[4]
Efficient large-scale language model training on gpu clusters using megatron-lm,
D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, V . Korthikanti, D. Vainbrand, P. Kashinkunti, J. Bernauer, B. Catanzaro, A. Phanishayee, and M. Zaharia, “Efficient large-scale language model training on gpu clusters using megatron-lm,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Ana...
-
[5]
Zero: memory optimizations toward training trillion parameter models,
S. Rajbhandari, J. Rasley, O. Ruwase, and Y . He, “Zero: memory optimizations toward training trillion parameter models,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’20. IEEE Press, 2020. [Online]. Available: https://doi.org/10.5555/3433701.3433727
-
[6]
Gpipe: efficient training of giant neural networks using pipeline parallelism,
Y . Huang, Y . Cheng, A. Bapna, O. Firat, M. X. Chen, D. Chen, H. Lee, J. Ngiam, Q. V . Le, Y . Wu, and Z. Chen, “Gpipe: efficient training of giant neural networks using pipeline parallelism,” inProceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook, NY , USA: Curran Associates Inc., 2019. [Online]. Available:...
-
[7]
Pipedream: generalized pipeline parallelism for dnn training,
D. Narayanan, A. Harlap, A. Phanishayee, V . Seshadri, N. R. Devanur, G. R. Ganger, P. B. Gibbons, and M. Zaharia, “Pipedream: generalized pipeline parallelism for dnn training,” inProceedings of the 27th ACM Symposium on Operating Systems Principles, ser. SOSP ’19. New York, NY , USA: Association for Computing Machinery, 2019, p. 1–15. [Online]. Availabl...
-
[8]
Memory-efficient pipeline-parallel dnn training,
D. Narayanan, A. Phanishayee, K. Shi, X. Chen, and M. Zaharia, “Memory-efficient pipeline-parallel dnn training,” inProceedings of the 38th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, M. Meila and T. Zhang, Eds., vol
-
[9]
7937–7947
PMLR, 18–24 Jul 2021, pp. 7937–7947. [Online]. Available: https://proceedings.mlr.press/v139/narayanan21a.html
2021
-
[10]
Chimera: efficiently training large-scale neural networks with bidirectional pipelines,
S. Li and T. Hoefler, “Chimera: efficiently training large-scale neural networks with bidirectional pipelines,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’21. New York, NY , USA: Association for Computing Machinery, 2021. [Online]. Available: https://doi.org/10.1145/3458817.3476145
-
[11]
Hanayo: Harnessing wave-like pipeline parallelism for enhanced large model training efficiency,
Z. Liu, S. Cheng, H. Zhou, and Y . You, “Hanayo: Harnessing wave-like pipeline parallelism for enhanced large model training efficiency,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’23. New York, NY , USA: Association for Computing Machinery, 2023. [Online]. Available: https://d...
-
[12]
Beyond data and model parallelism for deep neural networks
Z. Jia, M. Zaharia, and A. Aiken, “Beyond data and model parallelism for deep neural networks.” inProceedings of Machine Learning and Systems, A. Talwalkar, V . Smith, and M. Zaharia, Eds., vol. 1, 2019, pp. 1–13. [Online]. Available: https://cs.stanford.edu/ ∼zhihao/papers/ sysml19a.pdf
2019
-
[13]
Astra-sim2.0: Modeling hierarchical networks and disaggregated systems for large-model training at scale,
W. Won, T. Heo, S. Rashidi, S. Sridharan, S. Srinivasan, and T. Kr- ishna, “Astra-sim2.0: Modeling hierarchical networks and disaggregated systems for large-model training at scale,” in2023 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 2023, pp. 283–294
2023
-
[14]
Calculon: a methodology and tool for high-level co-design of systems and large language models,
M. Isaev, N. Mcdonald, L. Dennison, and R. Vuduc, “Calculon: a methodology and tool for high-level co-design of systems and large language models,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’23. New York, NY , USA: Association for Computing Machinery,
-
[15]
Available: https://doi.org/10.1145/3581784.3607102
[Online]. Available: https://doi.org/10.1145/3581784.3607102
-
[16]
Gaussian Error Linear Units (GELUs)
D. Hendrycks and K. Gimpel, “Gaussian error linear units (gelus),” CoRR/1606.08415, 2016. [Online]. Available: https://arxiv.org/abs/1606. 08415
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[17]
L. Braun, S. Nikas, C. Song, V . Heuveline, and H. Fr ¨oning, “A simple model for portable and fast prediction of execution time and power consumption of GPU kernels,”ACM Trans. Archit. Code Optim., vol. 18, no. 1, pp. 7:1–7:25, 2021. [Online]. Available: https://doi.org/10.1145/3431731
-
[18]
On link width scaling for energy-proportional direct interconnection networks,
F. Zahn, S. Lammel, and H. Fr ¨oning, “On link width scaling for energy-proportional direct interconnection networks,”Concurr. Comput. Pract. Exp., vol. 31, no. 2, 2019. [Online]. Available: https://doi.org/10.1002/cpe.4439
-
[19]
J. Tarraga-Moreno, D. Barley, F. J. A. Munoz, J. Escudero-Sahuquillo, H. Froning, P. J. Garcia, F. J. Quiles, and J. Duato, “Scalable and efficient intra- and inter-node interconnection networks for post-exascale supercomputers and data centers,”CoRR, vol. abs/2511.04677, 2025. [Online]. Available: https://arxiv.org/abs/2511.04677
-
[20]
Cudasap: Statically-determined execution statistics as alternative to execution-based profiling,
Y . Emonds, L. Braun, and H. Fr ¨oning, “Cudasap: Statically-determined execution statistics as alternative to execution-based profiling,” in 23rd IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing, ser. CCGRID, Y . Simmhan, I. Altintas, A. L. Varbanescu, P. Balaji, A. S. Prasad, and L. Carnevale, Eds. Bangalore, India: IEEE, 2023, ...
-
[21]
Zero bubble (almost) pipeline parallelism,
P. Qi, X. Wan, G. Huang, and M. Lin, “Zero bubble (almost) pipeline parallelism,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/ forum?id=tuzTN0eIO5
2024
-
[22]
Compressing the backward pass of large- scale neural architectures by structured activation pruning,
D. Barley and H. Fr ¨oning, “Compressing the backward pass of large- scale neural architectures by structured activation pruning,”CoRR, vol. abs/2311.16883, 2023. [Online]. Available: https://arxiv.org/abs/2311. 16883
-
[24]
Available: https://arxiv.org/abs/2409.11902
[Online]. Available: https://arxiv.org/abs/2409.11902
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.