Mitigating Hallucinations in Large Vision-Language Models via Causal Route Gating
Pith reviewed 2026-06-30 17:17 UTC · model grok-4.3
The pith
Large vision-language models reduce hallucinations by selectively suppressing text routes that dominate attention heads over visual evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
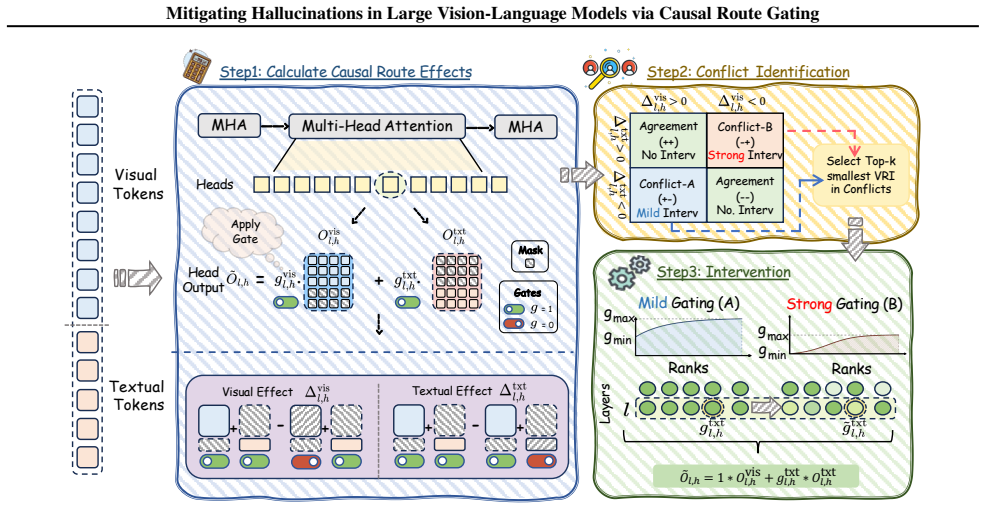
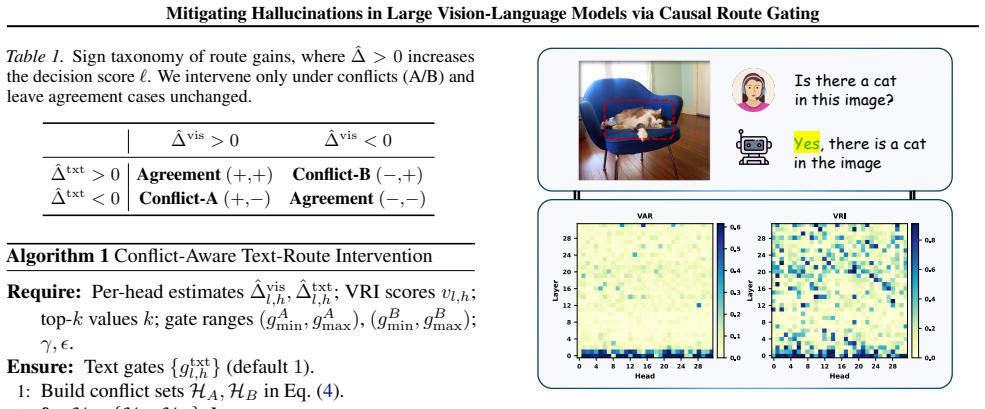
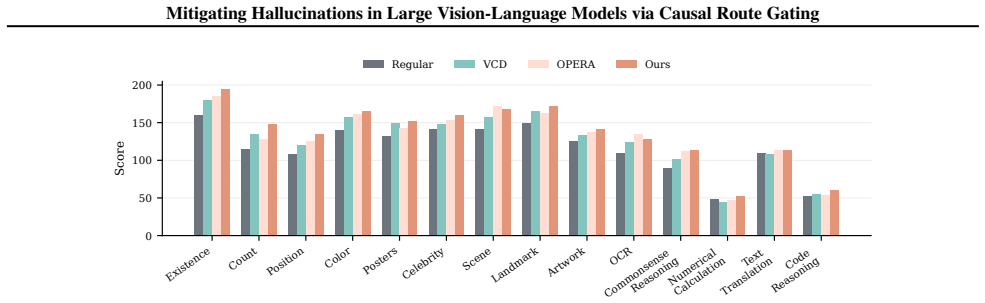
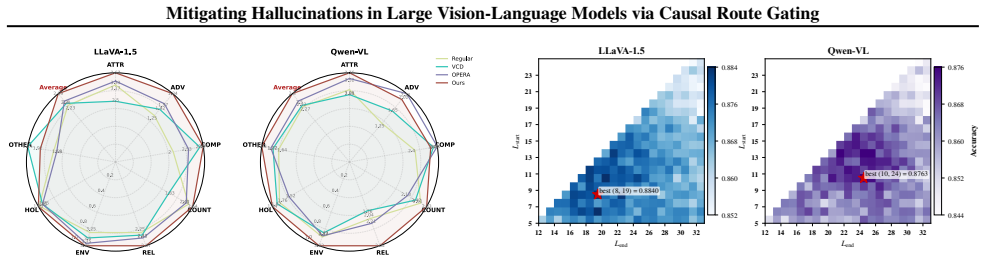
Hallucinations arise because even when visual tokens receive attention, the final decision in many heads is still controlled by the textual pathway that follows linguistic priors. Causal route gating decomposes every attention head into an explicit visual route and text route, approximates their token-level causal effects via a one-forward/one-gradient procedure, locates prior-dominant heads, and suppresses only the text route while preserving the visual route intact. This intervention lowers hallucination-related errors on five benchmarks spanning discriminative and generative tasks across multiple models while keeping overall multimodal performance largely unchanged and adding only modest
What carries the argument
Causal route gating: a training-free decomposition of each attention head into separate visual and text routes whose token-level effects are estimated by one-forward/one-gradient approximation, followed by selective suppression of the text route in prior-dominant heads.
If this is right
- Hallucination-related errors drop consistently on five benchmarks that cover both discriminative and generative settings.
- The intervention works across multiple LVLMs while leaving overall multimodal performance largely intact.
- Only the text route is suppressed in selected heads, leaving visual routes and non-conflicting heads unchanged.
- The method adds only modest inference-time overhead because it requires no retraining.
Where Pith is reading between the lines
- The same route-decomposition idea could be tested on other multimodal architectures where one modality's priors override another at decision time.
- Because the method is training-free, it could be applied as a post-hoc patch to already-deployed models without retraining costs.
- Dynamic versions of the gating that adjust suppression strength per input might further reduce side effects on edge cases the current fixed suppression leaves unaddressed.
Load-bearing premise
The one-forward/one-gradient approximation supplies accurate enough estimates of each route's effect on token choice to let suppression of the text route reduce hallucinations without creating new errors.
What would settle it
If manually ablating the text route in the heads flagged by the approximation produces no reduction in hallucination rates or instead increases errors on the same benchmarks, the approximation would be shown to be unreliable for this purpose.
Figures


read the original abstract
Large vision-language models (LVLMs) often hallucinate content that is fluent yet unsupported by the image, limiting their reliability in real-world deployment. We show that a key failure mode arises from route competition: even when visual tokens receive attention, the final token decision can be dominated by the textual pathway, causing the decoder to follow linguistic priors over visual evidence. To mitigate this, we propose a training-free, decision-aligned intervention that decomposes each attention head into a visual route and a text route, and estimates their token-level effects using an efficient one-forward/one-gradient approximation. These estimates reveal route conflict within heads and identify prior-dominant ones, enabling selective suppression of only the text route while keeping the visual route intact. Across five benchmarks spanning discriminative and generative settings, our method consistently reduces hallucination-related errors across models with limited impact on overall multimodal performance, while incurring a modest inference-time overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that hallucinations in LVLMs arise from route competition in attention heads where textual pathways dominate over visual evidence. It proposes a training-free Causal Route Gating intervention that decomposes heads into visual and text routes, estimates token-level effects via a one-forward/one-gradient approximation, identifies prior-dominant heads, and selectively suppresses only the text route. Experiments across five benchmarks (discriminative and generative) report consistent reductions in hallucination errors with limited impact on overall performance and modest inference overhead.
Significance. If the approximation accurately captures causal route effects and the selective suppression works as described, the method offers a practical, training-free way to improve LVLM reliability by aligning decisions with visual evidence. The training-free and decision-aligned nature is a strength, as is the explicit decomposition of routes within heads. However, the significance is tempered by the absence of validation for the core approximation.
major comments (2)
- [Abstract / §3] Abstract and method description (likely §3): The central claim relies on the one-forward/one-gradient approximation providing accurate token-level route effect estimates, yet no derivation, error bounds, comparison to exact intervention, or analysis of higher-order effects from softmax/residuals is supplied. This directly affects whether prior-dominant heads are correctly identified without introducing new errors.
- [§4 / Tables] Experimental results (likely §4, Tables 1-5): Consistent gains are reported across benchmarks, but no ablations validate the approximation's fidelity (e.g., correlation with full causal effects) or test cases where suppression alters downstream routing. Without this, the claim of 'limited impact on overall multimodal performance' cannot be evaluated as load-bearing evidence.
minor comments (2)
- [§3] Notation for 'visual route' and 'text route' within heads should be formalized with equations early in the method section for clarity.
- [Abstract] The five benchmarks should be explicitly listed with references in the abstract or introduction.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas where additional rigor would strengthen the paper. We agree that explicit validation of the one-forward/one-gradient approximation is currently missing and will address both major comments through targeted additions in the revision. Below we respond point by point.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and method description (likely §3): The central claim relies on the one-forward/one-gradient approximation providing accurate token-level route effect estimates, yet no derivation, error bounds, comparison to exact intervention, or analysis of higher-order effects from softmax/residuals is supplied. This directly affects whether prior-dominant heads are correctly identified without introducing new errors.
Authors: We agree that the manuscript lacks a formal derivation and error analysis for the approximation. In the revision we will add a dedicated subsection deriving the one-forward/one-gradient estimator from a first-order Taylor expansion of the attention output (including the softmax and residual stream), explicitly stating the assumptions and discussing potential higher-order interactions. We will also include a limited comparison against exact route interventions on a small subset of heads and tokens to quantify approximation error. These changes directly respond to the concern about reliable identification of prior-dominant heads. revision: yes
-
Referee: [§4 / Tables] Experimental results (likely §4, Tables 1-5): Consistent gains are reported across benchmarks, but no ablations validate the approximation's fidelity (e.g., correlation with full causal effects) or test cases where suppression alters downstream routing. Without this, the claim of 'limited impact on overall multimodal performance' cannot be evaluated as load-bearing evidence.
Authors: We concur that ablations validating the approximation's fidelity are needed. The revised version will add (i) correlation plots between approximated route effects and those measured by full causal interventions on a held-out subset of examples, and (ii) an analysis of downstream routing changes after selective suppression, reporting any resulting shifts in standard multimodal metrics. These experiments will be presented alongside the existing benchmark tables to substantiate the claim of limited performance impact. revision: yes
Circularity Check
No circularity; derivation is self-contained and training-free
full rationale
The paper's central intervention decomposes attention heads into visual/text routes and applies a one-forward/one-gradient approximation to estimate per-token effects before selective suppression. No load-bearing step reduces to a self-definition, a fitted parameter renamed as prediction, or a self-citation chain; the method is explicitly training-free and the reported gains are measured on external benchmarks rather than by construction from the inputs. The approximation is presented as an engineering choice whose validity is evaluated empirically, not assumed tautologically.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://lmsys.org/blog/2023-0 3-30-vicuna/. Deng, J. and Yang, Y . MaskCD: Mitigating LVLM hal- lucinations by image head masked contrastive decod- ing. InFindings of the Association for Computational Linguistics: EMNLP 2025, pp. 18854–18866. Associ- ation for Computational Linguistics, November 2025. doi: 10.18653/v1/2025.findings-emnlp.1025. URL htt...
-
[2]
URL https://transformer-circuits. pub/2021/framework/index.html. Favero, A., Zancato, L., Trager, M., Choudhary, S., Per- era, P., Achille, A., Swaminathan, A., and Soatto, S. Multi-modal hallucination control by visual information grounding. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, p...
-
[3]
URL https://deepmind.google/mo dels/model-cards/gemini-3-pro-image/ . Accessed: 2025-12-30. Gunjal, A., Yin, J., and Bas, E. Detecting and prevent- ing hallucinations in large vision language models. In Proceedings of the AAAI Conference on Artificial Intelli- gence, volume 38, pp. 18135–18143, 2024. doi: 10.1609/ aaai.v38i16.29771. URL https://ojs.aaai.o...
work page doi:10.1109/cv 2025
-
[4]
URL https://doi.org/10.5281/zeno do.5143773. Version 0.1. Jain, S. and Wallace, B. C. Attention is not explana- tion. InProceedings of the 2019 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), pp....
-
[5]
Qian, J., Zheng, G., Zhu, Y ., and Yang, S
URL https://papers.nips.cc/paper _files/paper/2025/hash/a7f530e11fa19 e9551b7a51dbd0f336f-Abstract-Confere nce.html. Qian, J., Zheng, G., Zhu, Y ., and Yang, S. Intervene-All- Paths: Unified mitigation of LVLM hallucinations across alignment formats. InThe Thirty-ninth Annual Confer- ence on Neural Information Processing Systems, 2025. URL https://openrev...
2025
-
[6]
Radford, A., Kim, J
URL https://papers.nips.cc/paper _files/paper/2025/hash/904e89bb4e632 e75fb47f093b620b257-Abstract-Confere nce.html. Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., and Sutskever, I. Learning transfer- able visual models from natural language supervision. InProceedings of...
2025
-
[7]
URL https: //doi.org/10.18653/v1/d18-1437
doi: 10.18653/V1/D18-1437. URL https: //doi.org/10.18653/v1/d18-1437. Sarkar, S., Che, Y ., Gavin, A., Beerel, P. A., and Kundu, S. Mitigating hallucinations in vision-language models through image-guided head suppression. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 12481–12500, Suzhou, China, November 202...
-
[8]
URL https: //doi.org/10.18653/v1/p19-1282
doi: 10.18653/V1/P19-1282. URL https: //doi.org/10.18653/v1/p19-1282. Sharkey, L., Chughtai, B., Batson, J., Lindsey, J., Wu, J., Bushnaq, L., Goldowsky-Dill, N., Heimersheim, S., Or- tega, A., Bloom, J. I., Biderman, S., Garriga-Alonso, A., Conmy, A., Nanda, N., Rumbelow, J. M., Watten- berg, M., Schoots, N., Miller, J., Saunders, W., Michaud, E. J., Cas...
-
[9]
PMLR, 2017. URL http://proceedings. mlr.press/v70/sundararajan17a.html. Tang, F., Liu, C., Xu, Z., Hu, M., Huang, Z., Xue, H., Chen, Z., Peng, Z., Yang, Z., Zhou, S., Li, W., Li, Y ., Song, W., Su, S., Feng, W., Su, J., Lin, M., Peng, Y ., Cheng, X., Razzak, I., and Ge, Z. Seeing far and clearly: Mitigating hallucinations in MLLMs with attention causal de...
-
[10]
URL https://doi.org/10.48550/arXiv .2502.12359. Yang, T., Li, Z., Cao, J., and Xu, C. Understanding and mit- igating hallucination in large vision-language models via modular attribution and intervention. InThe Thirteenth International Conference on Learning Representations,
work page internal anchor Pith review doi:10.48550/arxiv
-
[11]
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
URL https://openreview.net/forum ?id=Bjq4W7P2Us. Ye, Q., Xu, H., Xu, G., Ye, J., Yan, M., Zhou, Y ., Wang, J., Hu, A., Shi, P., Shi, Y ., Li, C., Xu, Y ., Chen, H., Tian, J., Qi, Q., Zhang, J., Huang, F., and Zhou, J. mPLUG- Owl: Modularization empowers large language models with multimodality.CoRR, abs/2304.14178, 2023. doi: 10.48550/arXiv.2304.14178. UR...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.14178 2023
-
[12]
URL https://ojs.aaai.org/index.php/AAAI/ article/view/40918
doi: 10.1609/aaai.v40i42.40918. URL https://ojs.aaai.org/index.php/AAAI/ article/view/40918. Y¨uksekg¨on¨ul, M., Chandrasekaran, V ., Jones, E., Gunasekar, S., Naik, R., Palangi, H., Kamar, E., and Nushi, B. At- tention satisfies: A constraint-satisfaction lens on factual errors of language models. InThe Twelfth International Conference on Learning Repres...
-
[13]
Then the first-order visual- route effect satisfies b∆vis l,h(i) ≤VAR l,h(i)·s l,h(i)≤VAR l,h(i)·m l,h(i), wherem l,h(i) := maxj∈Ivis |aj|as in Lemma A.1
Define the (attention-weighted) second-moment factor sl,h(i) := P j∈Ivis ˜α(l,h) ij a2 j 1/2 . Then the first-order visual- route effect satisfies b∆vis l,h(i) ≤VAR l,h(i)·s l,h(i)≤VAR l,h(i)·m l,h(i), wherem l,h(i) := maxj∈Ivis |aj|as in Lemma A.1. Proof.Starting from the definition of the first-order effect, b∆vis l,h(i) = X j∈Ivis α(l,h) ij aj = VAR l,...
-
[14]
highly visual
Orthogonality (large V AR, zero effect).Assume VARl,h(i) = 1, i.e., all attention mass is assigned to visual tokens, but ⟨Gl,h(i), v(l,h) j ⟩= 0 for every j∈I vis. Then b∆vis l,h(i) =P j∈Ivis α(l,h) ij ·0 = 0 . Thus, a head may appear “highly visual” under V AR while contributing no visual evidence to the current decision
-
[15]
Let ⟨Gl,h(i), v(l,h) j1 ⟩= +1 and ⟨Gl,h(i), v(l,h) j2 ⟩=−1
Cancellation (large V AR, small effect by sign mixing).Consider two visual tokens j1, j2 ∈I vis with α(l,h) ij1 = α(l,h) ij2 = 1/2, so VARl,h(i) = 1 . Let ⟨Gl,h(i), v(l,h) j1 ⟩= +1 and ⟨Gl,h(i), v(l,h) j2 ⟩=−1 . Then b∆vis l,h(i) = 1 2(+1) + 1 2(−1) = 0. Hence, even when V AR is maximal, the net decision-aligned effect can vanish due to signed cancellations
-
[16]
Harmful visual content (large V AR, negative effect).V AR is nonnegative by construction and cannot encode whether the attended visual content supports or contradicts the target token. SupposeVARl,h(i) is large, but⟨Gl,h(i), v(l,h) j ⟩<0 for the dominant attended visual keys j. Then b∆vis l,h(i) becomes negative, meaning the visual routereducesthe score ℓ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.