Optimal Non-Asymptotic Edgeworth Expansions for Multivariate Neural Network Outputs
Pith reviewed 2026-06-30 15:14 UTC · model grok-4.3
The pith
Finite-width neural networks are approximated by Edgeworth expansions with total variation error of order n to the minus m.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Assuming that the corresponding Gaussian limit has an invertible covariance matrix and that the activation function is polynomially bounded, we establish a bound of order n^{-m} on the total variation distance between the law of the true network output and its Edgeworth approximation, with matching lower bounds.
What carries the argument
Multidimensional Edgeworth expansion of order 4m-1 applied to the finite collection of network outputs at fixed inputs.
If this is right
- The approximation error between the network output distribution and its Edgeworth series is of order n to the minus m in total variation.
- Matching lower bounds establish that no faster rate is possible in general under the stated conditions.
- Replacing the network prior by its Edgeworth expansion produces a Bayesian posterior whose error is controlled at the same rate.
- The same non-asymptotic bounds hold for any sequence of conditionally Gaussian random vectors that converge to a Gaussian with invertible covariance.
Where Pith is reading between the lines
- The result suggests that higher-order Edgeworth corrections could improve posterior calibration in Bayesian neural networks at modest extra cost when the limiting covariance is well-conditioned.
- If the conditional-Gaussian property can be verified for other architectures, similar expansion rates may apply beyond fully connected layers.
- The invertibility requirement implies that the finite set of evaluation points must span a space in which the limiting covariance is full rank, which may fail for highly correlated or low-dimensional inputs.
- For concrete networks one could test whether increasing m yields the predicted improvement until cumulant estimation becomes the dominant error source.
Load-bearing premise
The Gaussian limit has an invertible covariance matrix.
What would settle it
Direct numerical computation of the total variation distance for a small fixed m, a concrete activation such as ReLU, and increasing network widths, checking whether the observed rate matches the stated upper and lower bounds of order n to the minus m.
Figures
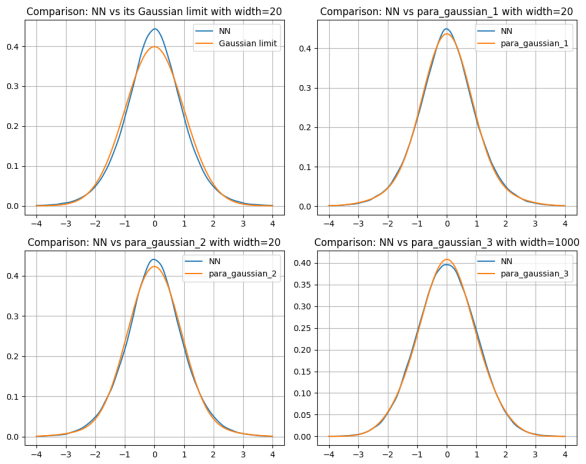
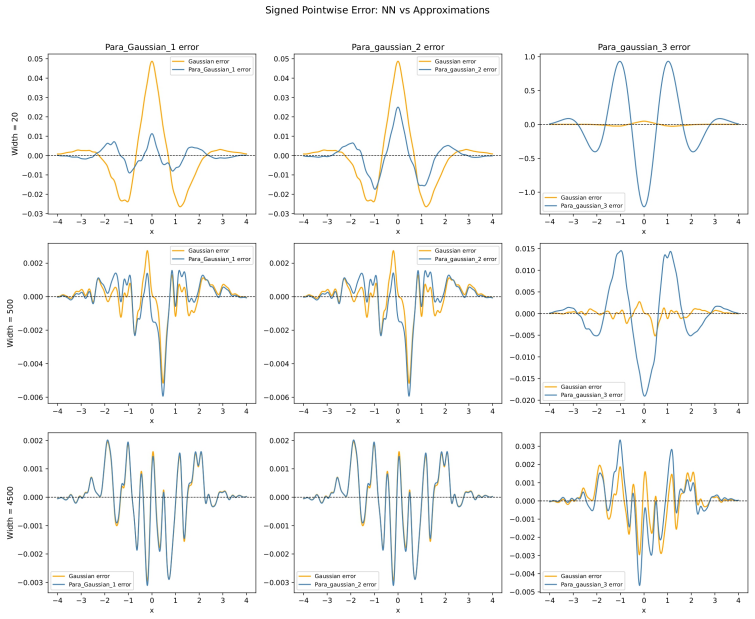
read the original abstract
Finite-width fully connected neural networks with Gaussian-initialized weights deviate from their infinite-width Gaussian limit, exhibiting non-vanishing higher-order cumulants. We approximate these deviations, for a neural network evaluated in a finite number of inputs, using multidimensional Edgeworth expansions of arbitrary order $4m-1$, with $m\in\mathbb{N}$. Assuming that the corresponding Gaussian limit has an invertible covariance matrix and that the activation function is polynomially bounded, we establish a bound of order $n^{-m}$ on the total variation distance between the law of the true network output and its Edgeworth approximation, with matching lower bounds. As an application, we quantify the error in Bayesian posterior distributions when the prior is replaced by its Edgeworth expansion. Our results are more general and also apply to sequences of conditionally Gaussian vectors converging to a Gaussian vector with invertible covariance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper establishes non-asymptotic bounds on the total variation distance between the distribution of outputs from finite-width fully connected neural networks (with Gaussian-initialized weights) and their multidimensional Edgeworth approximations of order 4m-1. Under the assumptions that the limiting Gaussian has invertible covariance and the activation is polynomially bounded, it proves an O(n^{-m}) upper bound with matching lower bounds. The results extend to conditionally Gaussian sequences converging to a Gaussian with invertible covariance and include an application quantifying the error when replacing a prior with its Edgeworth expansion in Bayesian posterior computations.
Significance. If the technical results hold, the work supplies the first optimal non-asymptotic Edgeworth rates tailored to neural-network outputs, together with matching lower bounds that establish sharpness. The explicit assumptions (invertible limiting covariance, polynomial activation bound) are stated clearly in the abstract, and the generalization to conditionally Gaussian vectors plus the Bayesian-posterior application add concrete utility. These elements strengthen the contribution beyond standard Edgeworth theory.
minor comments (3)
- The abstract states the order 4m-1 and the n^{-m} rate but does not indicate where in the manuscript the precise statement of the main theorem (including the dependence on m) appears; adding an explicit theorem label in the abstract would improve readability.
- The extension to conditionally Gaussian sequences is mentioned only briefly; a short dedicated subsection or remark clarifying how the NN case is recovered as a special instance would help readers trace the argument.
- Notation for the total-variation distance and the Edgeworth polynomial is introduced without an early reference to the precise definition used in the proofs; a short notational table or paragraph at the end of the introduction would reduce ambiguity.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation of minor revision. The provided summary accurately reflects the paper's contributions on non-asymptotic Edgeworth expansions for finite neural network outputs, including the O(n^{-m}) bounds with matching lower bounds under the stated assumptions, the extension to conditionally Gaussian sequences, and the Bayesian application.
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper derives an O(n^{-m}) TV bound for Edgeworth approximations of order 4m-1 applied to finite-width NN outputs (and conditionally Gaussian sequences) under the explicit assumptions of invertible limiting covariance and polynomially bounded activations. The central result rests on standard Edgeworth expansion techniques plus these assumptions, with matching lower bounds stated directly; no step reduces by construction to a fitted input, self-definition, or load-bearing self-citation chain. The abstract and claim structure are independent of any internal renaming or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The Gaussian limit has an invertible covariance matrix
- domain assumption The activation function is polynomially bounded
Reference graph
Works this paper leans on
-
[1]
Abramowitz and I.A
M. Abramowitz and I.A. Stegun.Handbook of Mathematical Functions: With Formulas, Graphs, and Mathematical Tables. Applied mathematics series. Dover Publications, 1965. URL:https://books.google.lu/books?id=MtU8uP7XMvoC
1965
-
[2]
Why bigger is not always better: on finite and infinite neural networks
Laurence Aitchison. Why bigger is not always better: on finite and infinite neural networks. In Hal Daum´ e III and Aarti Singh, editors,Proceedings of the 37th International Con- ference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 156–164. PMLR, 13–18 Jul 2020. URL:https://proceedings.mlr.press/v119/ aitchison20a.html
2020
- [3]
-
[4]
Normal approximation of random gaussian neural networks.Stochastic Systems, 15(1):88–110, 2025
Nicola Apollonio, Daniela De Canditiis, Giovanni Franzina, Paola Stolfi, and Giovanni Luca Torrisi. Normal approximation of random gaussian neural networks.Stochastic Systems, 15(1):88–110, 2025
2025
-
[5]
T. M. Apostol.Calculus, Volume 1: One-Variable Calculus, with an Introduction to Linear Algebra. John Wiley & Sons, 1967
1967
-
[6]
K. Balasubramanian and N. Ross. Finite-dimensional gaussian approximation for deep neural networks: Universality in random weights, 2025. URL:https://arxiv.org/abs/ 2507.12686,arXiv:2507.12686
-
[7]
Basteri and D
A. Basteri and D. Trevisan. Quantitative gaussian approximation of randomly initialized deep neural networks.Mach. Learn., 113:6373–6393, 2024
2024
-
[8]
Bhattacharya and R.R
R.N. Bhattacharya and R.R. Rao.Normal Approximation and Asymptotic Expansions. Classics in Applied Mathematics. Society for Industrial and Applied Mathematics, 1986. URL:https://books.google.lu/books?id=H1lOIVHcRDEC
1986
-
[9]
Bordino, S
A. Bordino, S. Favaro, and S. Fortini. Non-asymptotic approximations of gaussian neu- ral networks via second-order poincar´ e inequalities. InProceedings of Machine Learning Research (AABI24), 2024. 31
2024
-
[10]
C. K. I. Williams C. E. Rasmussen.Gaussian Processes for Machine Learning. MIT Press, ISBN 026218253X, 2006
2006
-
[11]
Carvalho, J
L. Carvalho, J. L. Costa, J. Mour˜ ao, and G. Oliveira. The positivity of the neural tangent kernel.SIAM Journal on Mathematics of Data Science, 7(2):495–515, 2025.doi:10.1137/ 24M1659534
2025
-
[12]
L. Celli. Edgworth expansion for fcnns (simulations), 2026.doi:10.5281/zenodo. 19737987
- [13]
-
[14]
L. Celli and G. Peccati. Entropic bounds for conditionally gaussian vectors and applications to neural networks, 2025. URL:https://arxiv.org/abs/2504.08335,arXiv:2504.08335
-
[15]
G. Cybenko. Approximation by superpositions of a sigmoidal function.Math. Control Signals Syst., 2(4):303–314, 1989.doi:10.1007/BF02551274
-
[16]
Favaro, B
S. Favaro, B. Hanin, D. Marinucci, I. Nourdin, and G. Peccati. Quantitative clts in deep neural networks.Probability Theory and Related Fields, 191(3):933–977, 2025
2025
-
[17]
V. Fortuin. Priors in bayesian deep learning: A review.International Statistical Re- view, 90(3):563–591, 2022. URL:https://onlinelibrary.wiley.com/doi/full/10. 1111/insr.12502
2022
-
[18]
Hall.The Bootstrap and Edgeworth Expansion
P. Hall.The Bootstrap and Edgeworth Expansion. Springer, New York, 1992
1992
-
[19]
B. Hanin. Random neural networks in the infinite width limit as gaussian processes.Ann. Appl. Probab., 33(6A):4798–4819, 2023
2023
-
[20]
B. Hanin. Random fully connected neural networks as perturbatively solvable hierarchies. Journal of Machine Learning Research, 2024
2024
- [21]
-
[22]
Klukowski
A. Klukowski. Rate of convergence of polynomial networks to gaussian processes. InCon- ference on Learning Theory, Proceedings of Machine Learning Research, pages 701–722, 2022
2022
-
[23]
Kolassa.Series Approximation Methods in Statistics
J.E. Kolassa.Series Approximation Methods in Statistics. Lecture Notes in Statistics. Springer New York, 2006. URL:https://books.google.lu/books?id=aLVY_gVEomgC
2006
-
[24]
J. Lee, Y. Bahri, R. Novak, S. Schoenholz, J. Pennington, and J. Sohl-Dickstein. Deep neural networks as gaussian processes. InInternational Conference on Learning Representation, 2018
2018
-
[25]
C.-K. Lu. Bayesian inference with finitely wide neural networks.Phys. Rev. E, 108:014311, Jul 2023. URL:https://link.aps.org/doi/10.1103/PhysRevE.108.014311,doi:10. 1103/PhysRevE.108.014311. 32
-
[26]
P. Mansanarez, G. Poly, and Y. Swan. Edgeworth expansion on wiener chaos, 2025. URL: https://arxiv.org/abs/2510.14002,arXiv:2510.14002
-
[27]
Matthews, J
A. Matthews, J. Hron, M. Rowland, R. Turner, and Z. Ghahramani. Gaussian process behaviour in wide deep neural networks. InInternational Conference on Learning Repre- sentation, 2018
2018
-
[28]
McCullagh.Tensor Methods in Statistics
P. McCullagh.Tensor Methods in Statistics. Monographs on Statistics and Applied Proba- bility. Chapman and Hall/CRC, 1987.doi:10.1201/9781351077118
-
[29]
Naveh, O
G. Naveh, O. B. David, H. Sompolinsky, and Z. Ringel. Predicting the outputs of finite deep neural networks trained with noisy gradients.Physical review. E, 104 6-1:064301,
-
[30]
URL:https://api.semanticscholar.org/CorpusID:238226559
-
[31]
Neal.Bayesian learning for neural networks, volume 118
R. Neal.Bayesian learning for neural networks, volume 118. Springer, 1996
1996
-
[32]
Nica and J
M. Nica and J. Ortmann. Improving the gaussian approximation in neural networks: Para- gaussians and edgeworth expansions. InNeurIPS 2024 Workshop on Mathematics of Modern Machine Learning, 2024. URL:https://openreview.net/forum?id=92q7WV4od7
2024
-
[33]
Cambridge Tracts in Mathematics
Ivan Nourdin and Giovanni Peccati.Normal Approximations with Malliavin Calculus: From Stein’s Method to Universality. Cambridge Tracts in Mathematics. Cambridge University Press, 2012
2012
-
[34]
Pacelli, S
R. Pacelli, S. Ariosto, M. Pastore, F. Ginelli, M. Gherardi, and P. Rotondo. A statistical mechanics framework for bayesian deep neural networks beyond the infinite-width limit. Nature Machine Intelligence, 5(12):1497–1507, 2023
2023
-
[35]
Peccati and M.S
G. Peccati and M.S. Taqqu.Wiener Chaos: Moments, Cumulants and Diagrams: A survey with Computer Implementation. Bocconi & Springer Series. Springer Milan, 2011. URL: https://books.google.lu/books?id=qizrXkh1LrkC
2011
-
[36]
Pleiss and J
G. Pleiss and J. P. Cunningham. The limitations of large width in neural networks: A deep gaussian process perspective.Advances in Neural Information Processing Systems, 34:3349–3363, 2021
2021
-
[37]
A. Shah, A. Wilson, and Z. Ghahramani. Student-t Processes as Alternatives to Gaussian Processes. In Samuel Kaski and Jukka Corander, editors,Proceedings of the Seventeenth International Conference on Artificial Intelligence and Statistics, volume 33 ofProceedings of Machine Learning Research, pages 877–885, Reykjavik, Iceland, 22–25 Apr 2014. PMLR. URL:h...
2014
-
[38]
R. P. Stanley.Enumerative Combinatorics. Cambridge Studies in Advanced Mathematics. Cambridge University Press, 2 edition, 2011
2011
- [39]
-
[40]
Wefelmeyer and J
W. Wefelmeyer and J. Pfanzagl.Asymptotic Expansions for General Statistical Models. Lecture Notes in Statistics. Springer New York, 2013. URL:https://books.google.lu/ books?id=L14FCAAAQBAJ. 33 Figure 2: The figure displays the signed pointwise error between the Monte Carlo kernel den- sity estimate (KDE) of the output distribution of a shallow neural netw...
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.