COSY: Compositional 3DGS Synthesis for Disentangled Human Head Editing
Pith reviewed 2026-06-30 15:32 UTC · model grok-4.3
The pith
A new generator architecture synthesizes hair, skin, glasses, and torso independently so that editing one region leaves the others fixed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
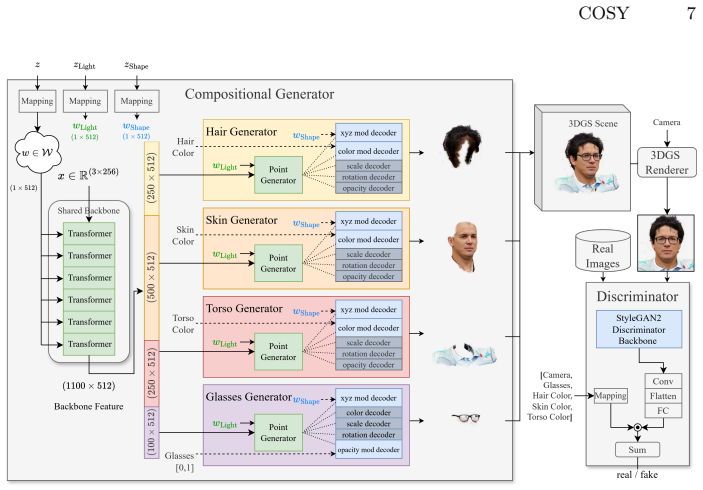
The central claim is that a generator built from independent synthesis networks for each semantic component of a 3D Gaussian head model, joined only by minimal context tokens, produces outputs in which a change to one component's latent vector leaves all remaining components unchanged. The separation is driven solely by sparse cues such as color values and requires neither segmentation masks nor geometric priors. The same tokens allow direct control of global shape and lighting without any extra annotation.
What carries the argument
Compositional generator of independent component synthesis networks coupled by shared context tokens.
If this is right
- Editing the latent code of one region produces no measurable change in any other region.
- Training and inference need only color labels rather than full segmentation or geometry.
- Context tokens permit shape and lighting adjustments without any additional labels.
- Disentanglement exceeds that obtained by estimating directions in a fully entangled latent space after training.
Where Pith is reading between the lines
- The same split-generator pattern could be applied to full-body or scene-level 3D models.
- Because each component is trained separately, the approach may tolerate smaller or less diverse training sets than a single entangled network.
- Extreme edits could be tested to quantify whether any leakage still occurs through the context tokens.
Load-bearing premise
Minimal shared context tokens suffice to enforce matching shape and lighting across independently generated components without reintroducing entanglement or requiring geometric priors or segmentation masks.
What would settle it
Generate pairs of heads that differ only in the hair latent code and measure whether any skin or glasses pixels change in color distribution, depth, or identity embedding.
Figures







read the original abstract
Recent 3D Gaussian Splatting (3DGS) GANs for human heads synthesize and render photorealistic 3D models in real-time and offer a vast variety in identity and appearance. However, controlling specific semantic attributes such as hair color or glasses remains challenging, as edits in the entangled latent space often induce unintended changes in identity or appearance. Although there are several methods that aim to disentangle the latent space post training by estimating directions that only modify certain features, these methods cannot guarantee complete disentanglement and often require pre-trained classifiers. In our approach, we propose a new generator architecture that synthesizes components, such as hair, skin, glasses, and torso, completely independently. This allows for changing the latent vector for one region while keeping the remaining parts fixed. Further, we achieve this separation using only sparse information such as the hair or skin color, eliminating the requirement of segmentation masks or geometric priors, often seen in prior work. To ensure matching shape and lighting conditions during editing, we allow minimal shared information via context tokens between the independent generators. These tokens even allow us to control the shape and light, without any prior annotation. Compared to existing works on GAN-based generation and editing, our method shows better disentanglement, more precise editing control, and competitive visual quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents COSY, a compositional architecture for 3D Gaussian Splatting GANs that generates human head components (hair, skin, glasses, torso) independently using separate generators. Conditioning is done with sparse signals such as color and a small set of shared context tokens to ensure consistency in shape and lighting. The method claims to achieve disentangled editing by modifying individual latent vectors without affecting other parts, without needing segmentation masks or geometric priors, and reports better disentanglement and precise control compared to prior work.
Significance. If the claims hold, this work would offer a meaningful contribution to controllable 3D head synthesis by addressing disentanglement at the architectural level rather than through post-training analysis. The idea of using minimal context tokens for cross-component consistency without explicit priors could influence future designs in compositional generation if empirically validated.
major comments (4)
- [Abstract] Abstract: The abstract asserts that the method shows 'better disentanglement, more precise editing control, and competitive visual quality' but provides no quantitative metrics, ablation studies, or comparisons to support these assertions, leaving the central claims unverified.
- [Method] The description of the context tokens does not specify their implementation, dimensionality, or the exact information they transmit; without this, it is unclear how they enforce 3D consistency (matching shape, lighting, no boundary artifacts) while preserving the independence of the component generators.
- [Experiments] No ablation studies are presented to test the necessity or sufficiency of the shared context tokens, nor are there quantitative evaluations of disentanglement (e.g., using metrics like attribute editing accuracy or identity preservation) or visual quality (e.g., FID, PSNR).
- [Abstract] The claim that the approach eliminates the requirement for segmentation masks or geometric priors is central, but the manuscript does not demonstrate through examples or analysis that the token-based approach avoids visible misalignments or re-entanglement at component boundaries.
minor comments (1)
- [Abstract] The term '3DGS' is introduced without an initial expansion, although it is standard in the field.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each of the major comments below and outline the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] The abstract asserts that the method shows 'better disentanglement, more precise editing control, and competitive visual quality' but provides no quantitative metrics, ablation studies, or comparisons to support these assertions, leaving the central claims unverified.
Authors: The abstract is intended as a concise summary of the contributions and results detailed in the body of the paper, which includes qualitative demonstrations and comparisons. We agree that including quantitative support would enhance the presentation of our claims. In the revised manuscript, we will incorporate quantitative metrics such as FID for visual quality and disentanglement scores to substantiate the assertions. revision: yes
-
Referee: [Method] The description of the context tokens does not specify their implementation, dimensionality, or the exact information they transmit; without this, it is unclear how they enforce 3D consistency (matching shape, lighting, no boundary artifacts) while preserving the independence of the component generators.
Authors: We will revise the method section to provide a more detailed specification of the context tokens, including their implementation as shared learnable embeddings, dimensionality, and the specific information they convey to maintain consistency across components without explicit priors. revision: yes
-
Referee: [Experiments] No ablation studies are presented to test the necessity or sufficiency of the shared context tokens, nor are there quantitative evaluations of disentanglement (e.g., using metrics like attribute editing accuracy or identity preservation) or visual quality (e.g., FID, PSNR).
Authors: The current experiments focus on qualitative evaluations to illustrate the disentanglement capabilities. We acknowledge the value of quantitative ablations and metrics. We will add ablation studies on the context tokens and quantitative evaluations including FID, PSNR, and disentanglement metrics in the revised version. revision: yes
-
Referee: [Abstract] The claim that the approach eliminates the requirement for segmentation masks or geometric priors is central, but the manuscript does not demonstrate through examples or analysis that the token-based approach avoids visible misalignments or re-entanglement at component boundaries.
Authors: The manuscript presents editing results that show independent control using sparse signals without masks. To address this concern, we will include additional boundary analysis and examples demonstrating the absence of misalignments in the revised manuscript. revision: yes
Circularity Check
No circularity: architectural proposal with no equations or self-referential derivations
full rationale
The paper presents a generator architecture for independent component synthesis (hair, skin, etc.) conditioned on sparse signals plus minimal context tokens. No equations, fitted parameters, or derivation chain are described in the provided text that reduce a claimed prediction to its own inputs by construction. The central claim is an empirical architectural choice whose validity rests on experimental outcomes rather than algebraic identity or self-citation load-bearing. No self-citation, ansatz smuggling, or renaming of known results is exhibited. This is the normal non-circular case for a design paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ACM Transactions on Graphics (ToG)40(3), 1–21 (2021)
Abdal, R., Zhu, P., Mitra, N.J., Wonka, P.: Styleflow: Attribute-conditioned ex- ploration of stylegan-generated images using conditional continuous normalizing flows. ACM Transactions on Graphics (ToG)40(3), 1–21 (2021)
2021
-
[2]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
An, S., Xu, H., Shi, Y., Song, G., Ogras, U.Y., Luo, L.: Panohead: Geometry-aware 3d full-head synthesis in 360deg. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 20950–20959 (2023)
2023
-
[3]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)
Barthel, F., Beckmann, A., Morgenstern, W., Hilsmann, A., Eisert, P.: Gaus- sian splatting decoder for 3d-aware generative adversarial networks. In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). pp. 7963–7972 (2024).https://doi.org/10.1109/CVPRW63382.2024. 00794
- [4]
-
[5]
Bilecen, B.B., Yalin, Y., Yu, N., Dundar, A.: Reference-based 3d-aware image edit- ingwithtriplanes.In:ProceedingsoftheComputerVisionandPatternRecognition Conference. pp. 5904–5915 (2025)
2025
-
[6]
In: International Conference on Learning Representations (2019),https://openreview.net/forum?id=B1xsqj09Fm
Brock, A., Donahue, J., Simonyan, K.: Large scale GAN training for high fidelity natural image synthesis. In: International Conference on Learning Representations (2019),https://openreview.net/forum?id=B1xsqj09Fm
2019
-
[7]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chan, E.R., Lin, C.Z., Chan, M.A., Nagano, K., Pan, B., De Mello, S., Gallo, O., Guibas, L.J., Tremblay, J., Khamis, S., et al.: Efficient geometry-aware 3d generative adversarial networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16123–16133 (2022)
2022
-
[8]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Chan, E.R., Monteiro, M., Kellnhofer, P., Wu, J., Wetzstein, G.: pi-gan: Periodic implicit generative adversarial networks for 3d-aware image synthesis. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5799–5809 (2021)
2021
-
[9]
ACM Transactions on Graphics (TOG)41(1), 1–26 (2022)
Chen, A., Liu, R., Xie, L., Chen, Z., Su, H., Yu, J.: Sofgan: A portrait image generator with dynamic styling. ACM Transactions on Graphics (TOG)41(1), 1–26 (2022)
2022
-
[10]
IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR) (2024)
Chen, X., Mihajlovic, M., Wang, S., Prokudin, S., Tang, S.: Morphable diffusion: 3d-consistent diffusion for single-image avatar creation. IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR) (2024)
2024
-
[11]
Dcgm: Dcgm/ffhq-features-dataset: Gender, age, and emotion for flickr-faces-hq dataset (ffhq),https://github.com/DCGM/ffhq-features-dataset
-
[12]
Seedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model
Gong, L., Hou, X., Li, F., Li, L., Lian, X., Liu, F., Liu, L., Liu, W., Lu, W., Shi, Y., et al.: Seedream 2.0: A native chinese-english bilingual image generation foundation model. arXiv preprint arXiv:2503.07703 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Advances in neural in- formation processing systems27(2014)
Goodfellow, I.J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. Advances in neural in- formation processing systems27(2014)
2014
-
[14]
Computational visual media7, 187–199 (2021)
Guo, M.H., Cai, J.X., Liu, Z.N., Mu, T.J., Martin, R.R., Hu, S.M.: Pct: Point cloud transformer. Computational visual media7, 187–199 (2021)
2021
-
[15]
ACM Transactions on Graphics44(4), 1–12 (2025) 16 F
He, C., Li, J., Kirschstein, T., Sevastopolsky, A., Saito, S., Tan, Q., Romero, J., Cao, C., Rushmeier, H., Nam, G.: 3dgh: 3d head generation with composable hair and face. ACM Transactions on Graphics44(4), 1–12 (2025) 16 F. Barthel et al
2025
-
[16]
Advances in neural information processing systems30(2017)
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017)
2017
-
[17]
In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https://openreview.net/forum?id=sFaFDcVNbW
Hyun, S., Heo, J.P.: GSGAN: Adversarial learning for hierarchical generation of 3d gaussian splats. In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https://openreview.net/forum?id=sFaFDcVNbW
2024
-
[18]
In: Proc
Härkönen, E., Hertzmann, A., Lehtinen, J., Paris, S.: Ganspace: Discovering inter- pretable gan controls. In: Proc. NeurIPS (2020)
2020
-
[19]
Kafri, O., Patashnik, O., Alaluf, Y., Cohen-Or, D.: Stylefusion: A generative model for disentangling spatial segments (2021)
2021
-
[20]
In: Proc
Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., Aila, T.: Analyzing and improving the image quality of StyleGAN. In: Proc. CVPR (2020)
2020
-
[21]
ACM Transactions on Graphics42(4) (July 2023),https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics42(4) (July 2023),https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
2023
-
[22]
In: SIGGRAPH Asia 2024 Con- ference Papers
Kirschstein, T., Giebenhain, S., Tang, J., Georgopoulos, M., Nießner, M.: GGHead: Fast and Generalizable 3D Gaussian Heads. In: SIGGRAPH Asia 2024 Con- ference Papers. SA ’24, Association for Computing Machinery, New York, NY, USA (2024).https://doi.org/10.1145/3680528.3687686,https://doi.org/ 10.1145/3680528.3687686
-
[23]
In: ICLR (2023)
Kynkäänniemi, T., Karras, T., Aittala, M., Aila, T., Lehtinen, J.: The role of imagenet classes in fréchet inception distance. In: ICLR (2023)
2023
-
[24]
Labs,B.F.,Batifol,S.,Blattmann,A.,Boesel,F.,Consul,S.,Diagne,C.,Dockhorn, T., English, J., English, Z., Esser, P., Kulal, S., Lacey, K., Levi, Y., Li, C., Lorenz, D., Müller, J., Podell, D., Rombach, R., Saini, H., Sauer, A., Smith, L.: Flux.1 kontext: Flow matching for in-context image generation and editing in latent space (2025),https://arxiv.org/abs/2...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
In: ECCV (2024)
Lan, Y., Tan, F., Qiu, D., Xu, Q., Genova, K., Huang, Z., Fanello, S., Pandey, R., Funkhouser, T., Loy, C.C., Zhang, Y.: Gaussian3diff: 3d gaussian diffusion for 3d full head synthesis and editing. In: ECCV (2024)
2024
-
[26]
In: ICASSP 2025 (2025)
Li, G., Yang, H., Men, Y., Huang, D., Li, W., Yang, R., Wang, Y.: Generating editable head avatars with 3d gaussian gans. In: ICASSP 2025 (2025)
2025
-
[27]
ACM Transactions on Graphics, (Proc
Li, T., Bolkart, T., Black, M.J., Li, H., Romero, J.: Learning a model of facial shape and expression from 4D scans. ACM Transactions on Graphics, (Proc. SIGGRAPH Asia)36(6), 194:1–194:17 (2017),https://doi.org/10.1145/3130800.3130813
-
[28]
In: Proceedings of the IEEE/CVF inter- national conference on computer vision
Liu, R., Wu, R., Van Hoorick, B., Tokmakov, P., Zakharov, S., Vondrick, C.: Zero- 1-to-3: Zero-shot one image to 3d object. In: Proceedings of the IEEE/CVF inter- national conference on computer vision. pp. 9298–9309 (2023)
2023
-
[29]
SyncDreamer: Generating Multiview-consistent Images from a Single-view Image
Liu, Y., Lin, C., Zeng, Z., Long, X., Liu, L., Komura, T., Wang, W.: Syncdreamer: Generating multiview-consistent images from a single-view image. arXiv preprint arXiv:2309.03453 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
In: ECCV (2020)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. In: ECCV (2020)
2020
-
[31]
Conditional Generative Adversarial Nets
Mirza, M., Osindero, S.: Conditional generative adversarial nets. CoRR abs/1411.1784(2014),http://arxiv.org/abs/1411.1784
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[32]
Nichol, A., Jun, H., Dhariwal, P., Mishkin, P., Chen, M.: Point-e: A system for generating3dpointcloudsfromcomplexprompts.arXivpreprintarXiv:2212.08751 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
In: ACM SIGGRAPH 2022 conference proceedings
Sauer, A., Schwarz, K., Geiger, A.: Stylegan-xl: Scaling stylegan to large diverse datasets. In: ACM SIGGRAPH 2022 conference proceedings. pp. 1–10 (2022) COSY 17
2022
-
[34]
IEEE transactions on pattern analysis and machine intelligence44(4), 2004–2018 (2020)
Shen, Y., Yang, C., Tang, X., Zhou, B.: Interfacegan: Interpreting the disentangled face representation learned by gans. IEEE transactions on pattern analysis and machine intelligence44(4), 2004–2018 (2020)
2004
-
[35]
ACM Transactions on Graphics (ToG)41(6), 1–10 (2022)
Sun, J., Wang, X., Shi, Y., Wang, L., Wang, J., Liu, Y.: Ide-3d: Interactive disen- tangled editing for high-resolution 3d-aware portrait synthesis. ACM Transactions on Graphics (ToG)41(6), 1–10 (2022)
2022
-
[36]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Sun, J., Wang, X., Zhang, Y., Li, X., Zhang, Q., Liu, Y., Wang, J.: Fenerf: Face editing in neural radiance fields. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7672–7682 (2022)
2022
-
[37]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z.: Rethinking the incep- tion architecture for computer vision. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2818–2826 (2016)
2016
-
[38]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Trevithick, A., Chan, M., Takikawa, T., Iqbal, U., De Mello, S., Chandraker, M., Ramamoorthi, R., Nagano, K.: What you see is what you gan: rendering every pixel for high-fidelity geometry in 3d gans. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22765–22775 (2024)
2024
-
[39]
Proceedings of the IEEE/CVF International Conference on Computer Vision (2023)
Wei, T., Chen, D., Zhou, W., Liao, J., Zhang, W., Hua, G., Yu, N.: Hairclipv2: Unifying hair editing via proxy feature blending. Proceedings of the IEEE/CVF International Conference on Computer Vision (2023)
2023
-
[40]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Xiang, J., Yang, J., Deng, Y., Tong, X.: Gram-hd: 3d-consistent image genera- tion at high resolution with generative radiance manifolds. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2195–2205 (2023)
2023
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xue, Y., Li, Y., Singh, K.K., Lee, Y.J.: Giraffe hd: A high-resolution 3d-aware generative model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18440–18449 (2022)
2022
-
[42]
In: Proceedings of the European conference on computer vision (ECCV)
Yu, C., Wang, J., Peng, C., Gao, C., Yu, G., Sang, N.: Bisenet: Bilateral segmenta- tion network for real-time semantic segmentation. In: Proceedings of the European conference on computer vision (ECCV). pp. 325–341 (2018)
2018
-
[43]
In: ACM SIGGRAPH (2025)
Yu, Z., Li, T., Sun, J., Shapira, O., Park, S., Stengel, M., Chan, M., Li, X., Wang, W., Nagano, K., Mello, S.D.: GAIA: Generative animatable interactive avatars with expression-conditioned gaussians. In: ACM SIGGRAPH (2025)
2025
-
[44]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yun, K., Kim, C., Shin, H., Noh, J.: Ffacenerf: few-shot face editing in neural radiance fields. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 10825–10835 (2025)
2025
-
[45]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhang, K., Zhou, Y., Xu, X., Dai, B., Pan, X.: Diffmorpher: Unleashing the capa- bility of diffusion models for image morphing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7912–7921 (2024)
2024
-
[46]
In: Proceed- ings of the IEEE/CVF international conference on computer vision
Zhao, H., Jiang, L., Jia, J., Torr, P.H., Koltun, V.: Point transformer. In: Proceed- ings of the IEEE/CVF international conference on computer vision. pp. 16259– 16268 (2021)
2021
-
[47]
Zhu, P., Abdal, R., Femiani, J., Wonka, P.: Barbershop: Gan-based image com- positing using segmentation masks (2021)
2021
-
[48]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhu, P., Abdal, R., Qin, Y., Wonka, P.: Sean: Image synthesis with semantic region- adaptive normalization. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5104–5113 (2020)
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.