ImPartial: Multi-channel Whole-Cell Segmentation using Partial Annotations
Pith reviewed 2026-06-30 15:28 UTC · model grok-4.3
The pith
ImPartial reaches fully supervised cell segmentation accuracy using only sparse scribble annotations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
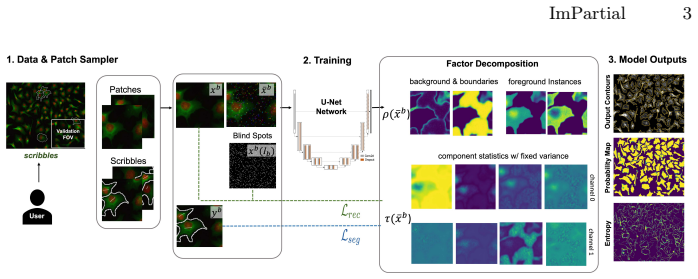
ImPartial combines partial scribble supervision with self-supervised multi-channel quantized imputation to produce whole-cell segmentations whose accuracy matches that of models trained on complete pixel-wise labels. The imputation step converts reconstruction into a quantized classification task across channels, which the authors show aligns more directly with segmentation than pixel-level denoising would.
What carries the argument
Self-supervised multi-channel quantized imputation, which augments the segmentation loss by turning partial image reconstruction into a per-channel classification objective.
If this is right
- Multiplexed imaging datasets with arbitrary channel counts become trainable with only sparse scribbles instead of exhaustive masks.
- Clinical brightfield immunohistochemistry slides can be segmented at scale without requiring dense expert labeling.
- Annotation effort for emerging biological modalities drops while maintaining parity with full-supervision baselines.
- The same partial-label plus imputation recipe applies across both multiplexed fluorescence and single-plex brightfield domains.
Where Pith is reading between the lines
- The method suggests that many dense-labeling tasks in imaging could be reframed around classification-style self-supervision rather than reconstruction.
- If the quantized imputation generalizes, it may reduce the need for modality-specific full-supervision pipelines in pathology.
- One could test whether the same partial-annotation regime works for 3D volumetric cell segmentation without additional architectural changes.
Load-bearing premise
The premise that perfect pixel-wise image reconstruction is unnecessary and that a classification-based self-supervised task aligns better with segmentation than standard reconstruction losses.
What would settle it
An ablation on the same partial-annotation training sets in which the quantized imputation head is removed or replaced by a standard pixel-reconstruction loss and the resulting segmentation accuracy falls below that of a fully supervised model trained on full labels.
Figures
read the original abstract
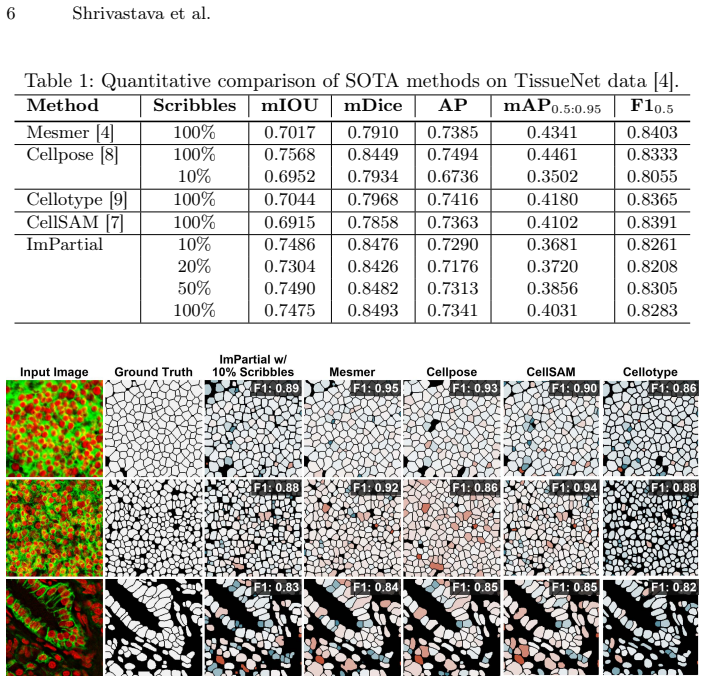
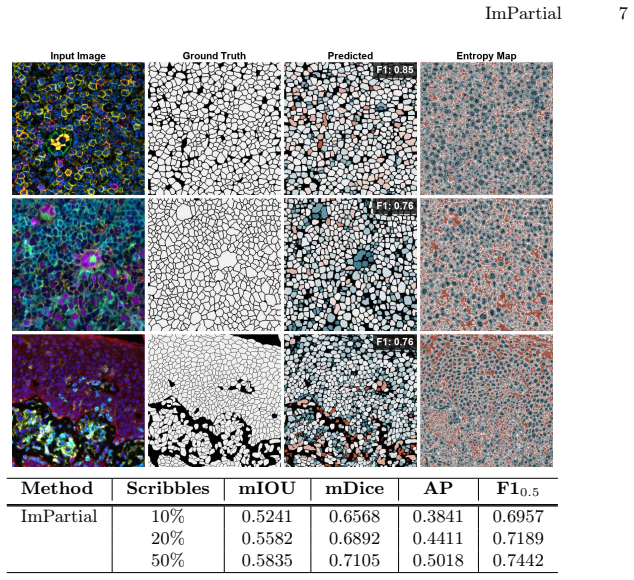
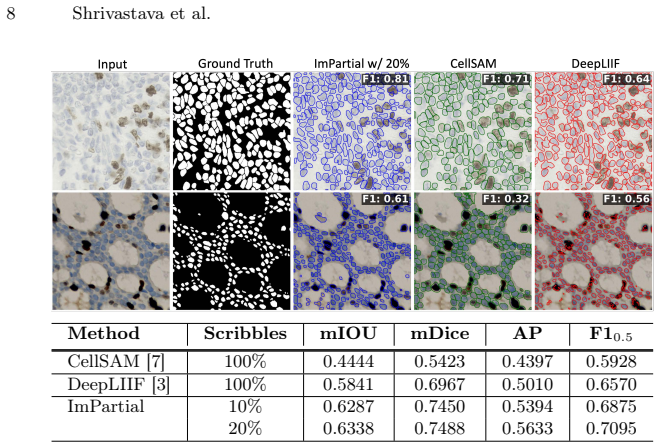
Accurate cell segmentation in pathology images typically requires dense pixel-wise annotations, which are costly and time-consuming to obtain. This challenge is especially important for emerging biological imaging modalities and multiplexed datasets with variable channel configurations, where expert-labeled data are scarce. In this work, we introduce ImPartial, a deep learning framework designed to achieve state-of-the-art segmentation performance in low-annotation regimes using sparse scribbles and limited supervision. ImPartial augments the segmentation objective via self-supervised multi-channel quantized imputation. This approach leverages the observation that perfect pixel-wise reconstruction or denoising of the image is not needed for accurate segmentation, and thus, introduces a self-supervised classification objective that better aligns with the overall segmentation goal. We demonstrate that ImPartial achieves performance at par with fully supervised models while requiring substantially fewer annotations. Extensive experiments on benchmark multiplexed cellular imaging and single-plex clinical brightfield immunohistochemistry datasets show consistent improvements over strong baselines with only partial annotations. All benchmark datasets and code are available via our Github: https://github.com/nadeemlab/ImPartial.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ImPartial, a framework for multi-channel whole-cell segmentation in pathology images that combines sparse scribble annotations with a self-supervised multi-channel quantized imputation task. It claims this yields segmentation performance at parity with fully supervised models while requiring substantially fewer annotations, with consistent improvements over baselines on multiplexed cellular imaging and brightfield IHC datasets.
Significance. If the central claim is supported by the experiments, the work would be significant for reducing annotation costs in low-supervision regimes for multiplexed and emerging imaging modalities. The release of code and benchmarks strengthens reproducibility.
major comments (2)
- [Methods / Experiments] The abstract and introduction motivate the quantized classification objective by claiming that 'perfect pixel-wise reconstruction or denoising of the image is not needed' and that a classification objective 'better aligns' with segmentation. However, no ablation is described that trains the identical architecture and partial-annotation pipeline with the proposed classification loss versus a standard regression (MSE) reconstruction loss. This comparison is required to establish that the alignment argument, rather than the multi-channel structure or scribble supervision alone, drives the reported gains.
- [Abstract / §4 Experiments] The central claim of performance parity with fully supervised models is stated without quantitative support in the abstract (no Dice/IoU values, no baseline tables, no annotation-fraction curves). The full experimental section must provide these metrics with error bars and statistical tests to substantiate parity under substantially reduced annotation budgets.
minor comments (1)
- [Abstract] The GitHub link is provided but the manuscript should specify the exact commit or release tag used for the reported results to ensure reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Methods / Experiments] The abstract and introduction motivate the quantized classification objective by claiming that 'perfect pixel-wise reconstruction or denoising of the image is not needed' and that a classification objective 'better aligns' with segmentation. However, no ablation is described that trains the identical architecture and partial-annotation pipeline with the proposed classification loss versus a standard regression (MSE) reconstruction loss. This comparison is required to establish that the alignment argument, rather than the multi-channel structure or scribble supervision alone, drives the reported gains.
Authors: We agree that a direct ablation comparing the quantized classification loss to an MSE reconstruction loss on the same architecture and partial-annotation pipeline would strengthen the justification for our design choice. The current experiments demonstrate the overall framework but do not isolate this factor. We will add this ablation study to the revised manuscript. revision: yes
-
Referee: [Abstract / §4 Experiments] The central claim of performance parity with fully supervised models is stated without quantitative support in the abstract (no Dice/IoU values, no baseline tables, no annotation-fraction curves). The full experimental section must provide these metrics with error bars and statistical tests to substantiate parity under substantially reduced annotation budgets.
Authors: The experimental section already reports Dice/IoU metrics, baseline comparisons, and annotation-fraction results across the multiplexed and IHC datasets. However, the abstract contains only qualitative claims. We will revise the abstract to include key quantitative results and will ensure error bars plus statistical tests are explicitly presented or added in §4 of the revised version. revision: partial
Circularity Check
No circularity; self-supervised objective is independent design choice with no derivation or self-citation reduction
full rationale
The paper presents ImPartial as a framework that augments segmentation with a self-supervised multi-channel quantized imputation task. This is motivated by an explicit observation ('perfect pixel-wise reconstruction or denoising of the image is not needed for accurate segmentation, and thus, introduces a self-supervised classification objective that better aligns with the overall segmentation goal') but is not derived from or fitted to the target labels. No equations, uniqueness theorems, or self-citations are invoked to force the choice; the component is described as an independent augmentation. Central claims rest on empirical benchmarks rather than any closed derivation chain that reduces to inputs by construction. This matches the default case of a self-contained empirical method.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Perfect pixel-wise reconstruction or denoising of the image is not needed for accurate segmentation
Reference graph
Works this paper leans on
-
[1]
Scientific Data10(1), 193 (2023)
Aleynick, N., Li, Y., Xie, Y., Zhang, M., Posner, A., Roshal, L., Pe’er, D., Van- guri, R.S., Hollmann, T.J.: Cross-platform dataset of multiplex fluorescent cellular object image annotations. Scientific Data10(1), 193 (2023)
2023
-
[2]
European Conference on Computer Vision pp
Buchholz, T.O., Prakash, M., Krull, A., Jug, F.: Denoiseg: Joint denoising and segmentation. European Conference on Computer Vision pp. 324–337 (2020)
2020
-
[3]
Nature Machine Intelligence4(4), 401–412 (2022)
Ghahremani, P., Li, Y., Kaufman, A., Vanguri, R., Greenwald, N., Angelo, M., Hollmann, T.J., Nadeem, S.: Deep learning-inferred multiplex immunofluorescence for immunohistochemical image quantification. Nature Machine Intelligence4(4), 401–412 (2022)
2022
-
[4]
Nature biotechnology40(4), 555–565 (2022)
Greenwald, N.F., Miller, G., Moen, E., Kong, A., Kagel, A., Dougherty, T., Full- away, C.C., McIntosh, B.J., Leow, K.X., Schwartz, M.S., et al.: Whole-cell seg- mentation of tissue images with human-level performance using large-scale data annotation and deep learning. Nature biotechnology40(4), 555–565 (2022)
2022
-
[5]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4015–4026 (2023)
2023
-
[6]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Krull, A., Buchholz, T.O., Jug, F.: Noise2void-learning denoising from single noisy images. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 2129–2137 (2019)
2019
-
[7]
Nature Methods22(12), 2585–2593 (Dec 2025)
Marks, M., Israel, U., Dilip, R., Li, Q., Yu, C., Laubscher, E., Iqbal, A., Pradhan, E., Ates, A., Abt, M., Brown, C., Pao, E., Li, S., Pearson-Goulart, A., Perona, P., Gkioxari, G., Barnowski, R., Yue, Y., Van Valen, D.: CellSAM: a foundation model for cell segmentation. Nature Methods22(12), 2585–2593 (Dec 2025)
2025
-
[8]
Nature methods19(12), 1634–1641 (2022)
Pachitariu, M., Stringer, C.: Cellpose 2.0: how to train your own model. Nature methods19(12), 1634–1641 (2022)
2022
-
[9]
Nature Methods (2024)
Pang, M., Roy, T.K., Wu, X., Tan, K.: Cellotype: A unified model for segmentation and classification of tissue images. Nature Methods (2024)
2024
-
[10]
In: The IEEE Winter Conference on Applications of Computer Vision (WACV) (March 2020)
Weigert, M., Schmidt, U., Haase, R., Sugawara, K., Myers, G.: Star-convex poly- hedra for 3d object detection and segmentation in microscopy. In: The IEEE Winter Conference on Applications of Computer Vision (WACV) (March 2020). https://doi.org/10.1109/WACV45572.2020.9093435
-
[11]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Wen, R., Yuan, H., Ni, D., Xiao, W., Wu, Y.: From denoising training to test-time adaptation: Enhancing domain generalization for medical image segmentation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 464–474 (2024)
2024
-
[12]
ACM Transactions on Multimedia Computing, Communications and Applications19(2), 1–23 (2023)
Xu, S., Sun, K., Liu, D., Xiong, Z., Zha, Z.J.: Synergy between semantic segmenta- tion and image denoising via alternate boosting. ACM Transactions on Multimedia Computing, Communications and Applications19(2), 1–23 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.