Loki: Representation over Architecture for Diffusion-Based Portrait Animation
Pith reviewed 2026-06-30 15:21 UTC · model grok-4.3
The pith
A face model's identity-orthogonal parameters for expression and pose let diffusion portrait animation perform cross-identity reenactment by coefficient substitution at inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
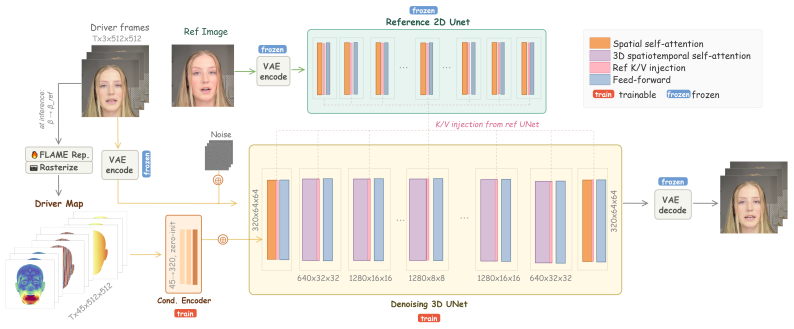
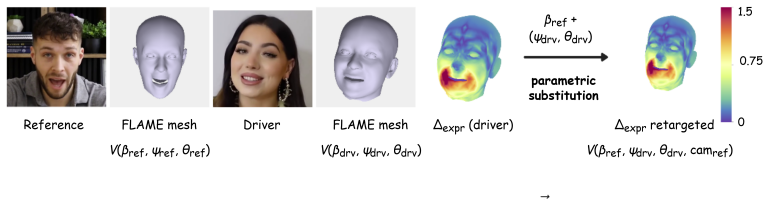
Loki encodes driver expression and head pose with a face model whose parameter axes are identity-orthogonal by construction, rasterizes those parameters into a spatial map that the diffusion backbone consumes directly, and routes identity separately via key-value injection into the backbone's pretrained features. Because the parametric representation already factorises identity from expression and pose, cross-ID reenactment reduces to substituting coefficients at inference time and requires no cross-ID training data at all.
What carries the argument
The identity-orthogonal parametric face model whose coefficients are rasterised into spatial conditioning maps, paired with separate key-value identity injection.
If this is right
- Cross-identity reenactment needs only single-identity training videos and no paired cross-ID data.
- Inference runs with approximately 43 percent fewer parameters than leading diffusion baselines.
- Training converges on 1496 times fewer video samples than prior diffusion systems.
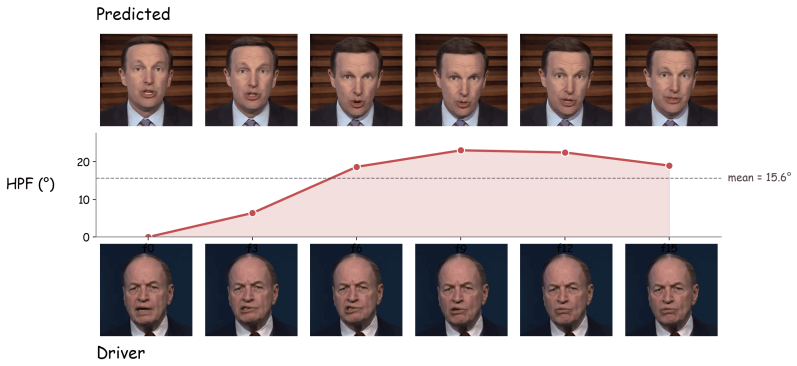
- Two new trajectory metrics directly quantify driver pose and expression adherence rather than relying on indirect image quality scores.
Where Pith is reading between the lines
- The same parametric conditioning could be tested on non-face animation tasks where identity-like attributes must stay fixed while motion changes.
- If the rasterised maps preserve separation, similar lightweight injection might simplify conditioning in other diffusion video tasks.
- Coefficient substitution at inference opens the possibility of real-time identity swaps once the base model is trained.
Load-bearing premise
The face model's parameter axes stay identity-orthogonal after rasterisation and the diffusion backbone can use those maps without re-entangling identity into expression or pose.
What would settle it
Generate a cross-identity reenactment sequence and measure whether identity features leak into the expression or pose outputs; leakage above baseline would falsify the claimed separation.
Figures




read the original abstract
Portrait animation transfers a driver clip's facial expression and head pose onto a single reference image while preserving the reference's identity. State-of-the-art diffusion systems address this by stacking trained modules for expression, pose, and identity in turn, paying for it in trainable parameters, proprietary corpora, and residual entanglement between the very axes the system is meant to control independently. This complexity compensates for an upstream choice -- learning facial expression and head pose from RGB, a representation in which identity, pose, and expression are inseparable without being learned apart. Loki steps out of RGB on the conditioning path. Driver expression and head pose are encoded by a face model whose parameter axes are identity-orthogonal by construction, then rasterised into a spatial map that the diffusion backbone consumes natively. Identity is routed separately through the diffusion backbone's own pretrained features via lightweight key-value injection. Because the parametric representation factorises identity from expression and pose, cross ID reenactment reduces to a coefficient substitution at inference, requiring no cross ID training data. Loki requires ~43% fewer inference parameters than leading diffusion baselines and trained on 1496x less video samples. We define two metrics that directly measure whether the generated head pose trajectory and facial expression followed the driver's -- the questions portrait animation actually asks; Loki leads or co-leads on both.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Loki for diffusion-based portrait animation: driver expression and pose are encoded via a face model's identity-orthogonal parameters, rasterized into spatial maps fed to the diffusion backbone, while identity is injected separately via lightweight key-value conditioning on pretrained features. This factorization is claimed to enable cross-ID reenactment by coefficient substitution at inference (no cross-ID training data required), with ~43% fewer inference parameters than leading baselines and training on 1496x less video data. Two new metrics directly measuring pose trajectory and expression fidelity are introduced, on which Loki leads or co-leads.
Significance. If the orthogonality preservation after rasterization holds and the new metrics prove robust, the work would demonstrate that a strong parametric representation can simplify diffusion conditioning for controllable animation, reducing reliance on large proprietary cross-ID corpora and stacked modules. The reported data and parameter efficiency would be practically valuable for the field if the claims are substantiated with the missing verification steps.
major comments (3)
- [Abstract] Abstract (driver encoding paragraph): The central claim that 'the parametric representation factorises identity from expression and pose' and thereby allows cross-ID reenactment 'by coefficient substitution at inference, requiring no cross ID training data' rests on the unverified assumption that rasterizing the face-model coefficients into a spatial map preserves the claimed orthogonality; no coefficient correlation matrix, no identity-probe classifier accuracy on the rasterized map alone, and no ablation on identity leakage when driver coefficients are taken from a different subject are supplied.
- [Abstract] Abstract: The two new metrics that 'directly measure whether the generated head pose trajectory and facial expression followed the driver's' are asserted to show leadership without any definition, formula, implementation details, baseline code references, error bars, or statistical significance tests; this directly undermines the performance claims that are load-bearing for the contribution.
- [Abstract] Abstract: The quantitative claims of '~43% fewer inference parameters than leading diffusion baselines' and 'trained on 1496x less video samples' lack explicit baseline names, exact parameter counts, training corpus sizes, or a table/equation showing the arithmetic; without these, the efficiency advantage cannot be assessed as load-bearing evidence.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, providing clarifications from the manuscript and indicating where revisions will be made to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract (driver encoding paragraph): The central claim that 'the parametric representation factorises identity from expression and pose' and thereby allows cross-ID reenactment 'by coefficient substitution at inference, requiring no cross ID training data' rests on the unverified assumption that rasterizing the face-model coefficients into a spatial map preserves the claimed orthogonality; no coefficient correlation matrix, no identity-probe classifier accuracy on the rasterized map alone, and no ablation on identity leakage when driver coefficients are taken from a different subject are supplied.
Authors: The face model parameters are constructed to be identity-orthogonal by design (Section 3.1), with identity, expression, and pose axes separated at the coefficient level. Rasterization performs a direct, per-coefficient spatial mapping without cross-term mixing or learned entanglement, preserving this factorization for coefficient substitution at inference. We agree that explicit verification would strengthen the claim and will add an ablation on cross-ID leakage (including identity-probe accuracy on rasterized maps) in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: The two new metrics that 'directly measure whether the generated head pose trajectory and facial expression followed the driver's' are asserted to show leadership without any definition, formula, implementation details, baseline code references, error bars, or statistical significance tests; this directly undermines the performance claims that are load-bearing for the contribution.
Authors: Full definitions, formulas, and implementation details for the two metrics (Pose Trajectory Error and Expression Fidelity Score) appear in Section 4.3, with baseline comparisons, error bars, and significance testing reported in Section 5. The abstract omits these due to length limits. We will revise the abstract to include concise metric definitions and reference the main-text details. revision: partial
-
Referee: [Abstract] Abstract: The quantitative claims of '~43% fewer inference parameters than leading diffusion baselines' and 'trained on 1496x less video samples' lack explicit baseline names, exact parameter counts, training corpus sizes, or a table/equation showing the arithmetic; without these, the efficiency advantage cannot be assessed as load-bearing evidence.
Authors: Exact baseline names, parameter counts, and training corpus sizes (including the arithmetic for the 43% and 1496x figures) are provided in Section 5.2 and Table 2. We will add a compact summary table or equation highlighting these comparisons in the revised abstract or introduction for clarity. revision: yes
Circularity Check
No circularity: factorization attributed to external pre-existing face model
full rationale
The paper's central claim follows from the asserted property of an upstream face model (parameter axes identity-orthogonal by construction) rather than from any equation, fit, or self-citation internal to the diffusion training. The abstract explicitly states the orthogonality is 'by construction' of that model and that cross-ID reenactment therefore reduces to coefficient substitution; this is presented as a logical consequence of an external representation, not derived or verified inside the paper's own training loop. No load-bearing step reduces a reported gain (parameter count, data volume, or metric) to a quantity fitted or renamed within the same manuscript. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A face model's parameter axes are identity-orthogonal by construction
Reference graph
Works this paper leans on
-
[1]
One-shot free-view neural talking-head synthesis for video conferencing
Ting-Chun Wang, Arun Mallya, and Ming-Yu Liu. One-shot free-view neural talking-head synthesis for video conferencing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10039–10049, 2021
2021
-
[2]
Emo: Emote portrait alive generating expressive portrait videos with audio2video diffusion model under weak conditions
Linrui Tian, Qi Wang, Bang Zhang, and Liefeng Bo. Emo: Emote portrait alive generating expressive portrait videos with audio2video diffusion model under weak conditions. InEuropean Conference on Computer Vision, pages 244–260. Springer, 2024
2024
-
[3]
Cong Wang, Kuan Tian, Jun Zhang, Yonghang Guan, Feng Luo, Fei Shen, Zhiwei Jiang, Qing Gu, Xiao Han, and Wei Yang. V-express: Conditional dropout for progressive training of portrait video generation.arXiv preprint arXiv:2406.02511, 2024
-
[4]
Huawei Wei, Zejun Yang, and Zhisheng Wang. Aniportrait: Audio-driven synthesis of photore- alistic portrait animation.arXiv preprint arXiv:2403.17694, 2024
-
[5]
Jianzhu Guo, Dingyun Zhang, Xiaoqiang Liu, Zhizhou Zhong, Yuan Zhang, Pengfei Wan, and Di Zhang. Liveportrait: Efficient portrait animation with stitching and retargeting control.arXiv preprint arXiv:2407.03168, 2024
-
[6]
Mingwang Xu, Hui Li, Qingkun Su, Hanlin Shang, Liwei Zhang, Ce Liu, Jingdong Wang, Yao Yao, and Siyu Zhu. Hallo: Hierarchical audio-driven visual synthesis for portrait image animation.arXiv preprint arXiv:2406.08801, 2024. 36
-
[7]
Marionette: Few-shot face reenactment preserving identity of unseen targets
Sungjoo Ha, Martin Kersner, Beomsu Kim, Seokjun Seo, and Dongyoung Kim. Marionette: Few-shot face reenactment preserving identity of unseen targets. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 10893–10900, 2020
2020
-
[8]
Learning identity-invariant motion representations for cross-id face reenactment
Po-Hsiang Huang, Fu-En Yang, and Yu-Chiang Frank Wang. Learning identity-invariant motion representations for cross-id face reenactment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7084–7092, 2020
2020
-
[9]
Fsgan: Subject agnostic face swapping and reenactment
Yuval Nirkin, Yosi Keller, and Tal Hassner. Fsgan: Subject agnostic face swapping and reenactment. InProceedings of the IEEE/CVF international conference on computer vision, pages 7184–7193, 2019
2019
-
[10]
Dinet: Deformation inpainting network for realistic face visually dubbing on high resolution video
Zhimeng Zhang, Zhipeng Hu, Wenjin Deng, Changjie Fan, Tangjie Lv, and Yu Ding. Dinet: Deformation inpainting network for realistic face visually dubbing on high resolution video. In Proceedings of the AAAI conference on artificial intelligence, volume 37, pages 3543–3551, 2023
2023
-
[11]
Ai-generated characters for supporting personalized learning and well- being.Nature Machine Intelligence, 3(12):1013–1022, 2021
Pat Pataranutaporn, Valdemar Danry, Joanne Leong, Parinya Punpongsanon, Dan Novy, Pattie Maes, and Misha Sra. Ai-generated characters for supporting personalized learning and well- being.Nature Machine Intelligence, 3(12):1013–1022, 2021
2021
-
[12]
Face2face: Real-time face capture and reenactment of rgb videos
Justus Thies, Michael Zollhofer, Marc Stamminger, Christian Theobalt, and Matthias Nießner. Face2face: Real-time face capture and reenactment of rgb videos. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2387–2395, 2016
2016
-
[13]
Neural voice puppetry: Audio-driven facial reenactment
Justus Thies, Mohamed Elgharib, Ayush Tewari, Christian Theobalt, and Matthias Nießner. Neural voice puppetry: Audio-driven facial reenactment. InEuropean conference on computer vision, pages 716–731. Springer, 2020
2020
-
[14]
Dpe: Disentanglement of pose and expression for general video portrait editing
Youxin Pang, Yong Zhang, Weize Quan, Yanbo Fan, Xiaodong Cun, Ying Shan, and Dong-ming Yan. Dpe: Disentanglement of pose and expression for general video portrait editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 427–436, 2023
2023
-
[15]
X-portrait: Expressive portrait animation with hierarchical motion attention
You Xie, Hongyi Xu, Guoxian Song, Chao Wang, Yichun Shi, and Linjie Luo. X-portrait: Expressive portrait animation with hierarchical motion attention. InACM SIGGRAPH 2024 conference papers, pages 1–11, 2024
2024
-
[16]
Hunyuanportrait: Implicit condition control for enhanced portrait animation
Zunnan Xu, Zhentao Yu, Zixiang Zhou, Jun Zhou, Xiaoyu Jin, Fa-Ting Hong, Xiaozhong Ji, Junwei Zhu, Chengfei Cai, Shiyu Tang, et al. Hunyuanportrait: Implicit condition control for enhanced portrait animation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15909–15919, 2025
2025
-
[17]
Animate anyone: Consistent and controllable image-to-video synthesis for character animation
Li Hu. Animate anyone: Consistent and controllable image-to-video synthesis for character animation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8153–8163, 2024
2024
-
[18]
Sadtalker: Learning realistic 3d motion coefficients for stylized audio-driven single image talking face animation
Wenxuan Zhang, Xiaodong Cun, Xuan Wang, Yong Zhang, Xi Shen, Yu Guo, Ying Shan, and Fei Wang. Sadtalker: Learning realistic 3d motion coefficients for stylized audio-driven single image talking face animation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8652–8661, 2023
2023
-
[19]
Anitalker: Animate vivid and diverse talking faces through identity-decoupled facial motion encoding
Tao Liu, Feilong Chen, Shuai Fan, Chenpeng Du, Qi Chen, Xie Chen, and Kai Yu. Anitalker: Animate vivid and diverse talking faces through identity-decoupled facial motion encoding. InProceedings of the 32nd ACM International Conference on Multimedia, pages 6696–6705, 2024
2024
-
[20]
Echomimic: Lifelike audio-driven portrait animations through editable landmark conditions
Zhiyuan Chen, Jiajiong Cao, Zhiquan Chen, Yuming Li, and Chenguang Ma. Echomimic: Lifelike audio-driven portrait animations through editable landmark conditions. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 2403–2410, 2025
2025
-
[21]
Learning a model of facial shape and expression from 4d scans.ACM Trans
Tianye Li, Timo Bolkart, Michael J Black, Hao Li, and Javier Romero. Learning a model of facial shape and expression from 4d scans.ACM Trans. Graph., 36(6):194–1, 2017. 37
2017
-
[22]
A Formal Evaluation of PSNR as Quality Measurement Parameter for Image Segmentation Algorithms
Fernando A Fardo, Victor H Conforto, Francisco C De Oliveira, and Paulo S Rodrigues. A formal evaluation of psnr as quality measurement parameter for image segmentation algorithms. arXiv preprint arXiv:1605.07116, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[23]
Bovik, H.R
Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612,
-
[24]
doi: 10.1109/TIP.2003.819861
-
[25]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[26]
Fvd: A new metric for video generation
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphaël Marinier, Marcin Michalski, and Sylvain Gelly. Fvd: A new metric for video generation. 2019
2019
-
[27]
Arcface: Additive angular margin loss for deep face recognition
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4690–4699, 2019
2019
-
[28]
First order motion model for image animation.Advances in neural information processing systems, 32, 2019
Aliaksandr Siarohin, Stéphane Lathuilière, Sergey Tulyakov, Elisa Ricci, and Nicu Sebe. First order motion model for image animation.Advances in neural information processing systems, 32, 2019
2019
-
[29]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023
2023
-
[30]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Emotalk: Speech-driven emotional disentanglement for 3d face animation
Ziqiao Peng, Haoyu Wu, Zhenbo Song, Hao Xu, Xiangyu Zhu, Jun He, Hongyan Liu, and Zhaoxin Fan. Emotalk: Speech-driven emotional disentanglement for 3d face animation. In Proceedings of the IEEE/CVF international conference on computer vision, pages 20687–20697, 2023
2023
-
[33]
Emotional speech-driven animation with content-emotion disentanglement
Radek Danˇeˇcek, Kiran Chhatre, Shashank Tripathi, Yandong Wen, Michael Black, and Timo Bolkart. Emotional speech-driven animation with content-emotion disentanglement. InSIG- GRAPH Asia 2023 Conference Papers, pages 1–13, 2023
2023
-
[34]
Capture, learning, and synthesis of 3d speaking styles
Daniel Cudeiro, Timo Bolkart, Cassidy Laidlaw, Anurag Ranjan, and Michael J Black. Capture, learning, and synthesis of 3d speaking styles. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10101–10111, 2019
2019
-
[35]
Learning an animatable detailed 3d face model from in-the-wild images.ACM Transactions on Graphics (ToG), 40(4):1–13, 2021
Yao Feng, Haiwen Feng, Michael J Black, and Timo Bolkart. Learning an animatable detailed 3d face model from in-the-wild images.ACM Transactions on Graphics (ToG), 40(4):1–13, 2021
2021
-
[36]
Emoca: Emotion driven monocular face capture and animation
Radek Danˇeˇcek, Michael J Black, and Timo Bolkart. Emoca: Emotion driven monocular face capture and animation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20311–20322, 2022
2022
-
[37]
Towards metrical reconstruction of human faces
Wojciech Zielonka, Timo Bolkart, and Justus Thies. Towards metrical reconstruction of human faces. InEuropean conference on computer vision, pages 250–269. Springer, 2022
2022
-
[38]
Spectre: Visual speech-informed perceptual 3d facial expression reconstruction from videos
Panagiotis P Filntisis, George Retsinas, Foivos Paraperas-Papantoniou, Athanasios Katsamanis, Anastasios Roussos, and Petros Maragos. Spectre: Visual speech-informed perceptual 3d facial expression reconstruction from videos. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5745–5755, 2023. 38
2023
-
[39]
George Retsinas, Panagiotis P Filntisis, Radek Danecek, Victoria F Abrevaya, Anastasios Roussos, Timo Bolkart, and Petros Maragos. Smirk: 3d facial expressions through analysis-by- neural-synthesis.arXiv preprint arXiv:2404.04104, 2024
-
[40]
Cap4d: Creating animatable 4d portrait avatars with morphable multi-view diffusion models
Felix Taubner, Ruihang Zhang, Mathieu Tuli, and David B Lindell. Cap4d: Creating animatable 4d portrait avatars with morphable multi-view diffusion models. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5318–5330. IEEE Computer Society, 2025
2025
-
[41]
Gaussianavatars: Photorealistic head avatars with rigged 3d gaussians
Shenhan Qian, Tobias Kirschstein, Liam Schoneveld, Davide Davoli, Simon Giebenhain, and Matthias Nießner. Gaussianavatars: Photorealistic head avatars with rigged 3d gaussians. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20299–20309, 2024
2024
-
[42]
Flashavatar: High-fidelity head avatar with efficient gaussian embedding
Jun Xiang, Xuan Gao, Yudong Guo, and Juyong Zhang. Flashavatar: High-fidelity head avatar with efficient gaussian embedding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1802–1812, 2024
2024
-
[43]
Im avatar: Implicit morphable head avatars from videos
Yufeng Zheng, Victoria Fernández Abrevaya, Marcel C Bühler, Xu Chen, Michael J Black, and Otmar Hilliges. Im avatar: Implicit morphable head avatars from videos. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13545–13555, 2022
2022
-
[44]
Diffusionavatars: Deferred diffusion for high-fidelity 3d head avatars
Tobias Kirschstein, Simon Giebenhain, and Matthias Nießner. Diffusionavatars: Deferred diffusion for high-fidelity 3d head avatars. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5481–5492, 2024
2024
-
[45]
faceformer: Speech- driven 3d facial animation with transformers
Yingruo Fan, Zhaojiang Lin, Jun Saito, Wenping Wang, and Taku Komura. faceformer: Speech- driven 3d facial animation with transformers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18770–18780, 2022
2022
-
[46]
Codetalker: Speech-driven 3d facial animation with discrete motion prior
Jinbo Xing, Menghan Xia, Yuechen Zhang, Xiaodong Cun, Jue Wang, and Tien-Tsin Wong. Codetalker: Speech-driven 3d facial animation with discrete motion prior. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12780–12790, 2023
2023
-
[47]
Facechain-imagineid: Freely crafting high-fidelity diverse talking faces from disentangled audio
Chao Xu, Yang Liu, Jiazheng Xing, Weida Wang, Mingze Sun, Jun Dan, Tianxin Huang, Siyuan Li, Zhi-Qi Cheng, Ying Tai, et al. Facechain-imagineid: Freely crafting high-fidelity diverse talking faces from disentangled audio. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1292–1302, 2024
2024
-
[48]
Smpl: A skinned multi-person linear model
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi-person linear model. InSeminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 851–866. 2023
2023
-
[49]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[50]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[51]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[52]
Shunian Chen, Hejin Huang, Yexin Liu, Zihan Ye, Pengcheng Chen, Chenghao Zhu, Michael Guan, Rongsheng Wang, Junying Chen, Guanbin Li, et al. Talkvid: A large-scale diversified dataset for audio-driven talking head synthesis.arXiv preprint arXiv:2508.13618, 2025
-
[53]
Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset
Zhimeng Zhang, Lincheng Li, Yu Ding, and Changjie Fan. Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3661–3670, 2021. 39
2021
-
[54]
Spatial broadcast decoder: A simple architecture for learning disentangled representations in vaes
Nicholas Watters, Loic Matthey, Christopher P Burgess, and Alexander Lerchner. Spatial broadcast decoder: A simple architecture for learning disentangled representations in vaes. arXiv preprint arXiv:1901.07017, 2019
-
[55]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[56]
Faceboxes: A cpu real-time face detector with high accuracy
Shifeng Zhang, Xiangyu Zhu, Zhen Lei, Hailin Shi, Xiaobo Wang, and Stan Z Li. Faceboxes: A cpu real-time face detector with high accuracy. In2017 IEEE International Joint Conference on Biometrics (IJCB), pages 1–9. IEEE, 2017
2017
-
[57]
Pixel-in-pixel net: Towards efficient facial landmark detection in the wild.International Journal of Computer Vision, 129(12):3174–3194, 2021
Haibo Jin, Shengcai Liao, and Ling Shao. Pixel-in-pixel net: Towards efficient facial landmark detection in the wild.International Journal of Computer Vision, 129(12):3174–3194, 2021
2021
-
[58]
General facial representation learning in a visual- linguistic manner
Yinglin Zheng, Hao Yang, Ting Zhang, Jianmin Bao, Dongdong Chen, Yangyu Huang, Lu Yuan, Dong Chen, Ming Zeng, and Fang Wen. General facial representation learning in a visual- linguistic manner. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18697–18709, 2022
2022
-
[59]
Retinaface: Single-shot multi-level face localisation in the wild
Jiankang Deng, Jia Guo, Evangelos Ververas, Irene Kotsia, and Stefanos Zafeiriou. Retinaface: Single-shot multi-level face localisation in the wild. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5203–5212, 2020
2020
-
[60]
Simon Giebenhain, Tobias Kirschstein, Martin Rünz, Lourdes Agapito, and Matthias Nießner. Pixel3dmm: Versatile screen-space priors for single-image 3d face reconstruction.arXiv preprint arXiv:2505.00615, 2025
-
[61]
L2cs-net: Fine-grained gaze estimation in unconstrained environments
Ahmed A Abdelrahman, Thorsten Hempel, Aly Khalifa, Ayoub Al-Hamadi, and Laslo Dinges. L2cs-net: Fine-grained gaze estimation in unconstrained environments. In2023 8th Interna- tional Conference on Frontiers of Signal Processing (ICFSP), pages 98–102. IEEE, 2023
2023
-
[62]
Robust high-resolution video matting with temporal guidance
Shanchuan Lin, Linjie Yang, Imran Saleemi, and Soumyadip Sengupta. Robust high-resolution video matting with temporal guidance. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 238–247, 2022
2022
-
[63]
Common diffusion noise schedules and sample steps are flawed
Shanchuan Lin, Bingchen Liu, Jiashi Li, and Xiao Yang. Common diffusion noise schedules and sample steps are flawed. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 5404–5411, 2024
2024
-
[64]
simple diffusion: End-to-end diffusion for high resolution images
Emiel Hoogeboom, Jonathan Heek, and Tim Salimans. simple diffusion: End-to-end diffusion for high resolution images. InInternational Conference on Machine Learning, pages 13213– 13232. PMLR, 2023
2023
-
[65]
xformers: A modular and hackable transformer modelling library, 2022
Benjamin Lefaudeux, Francisco Massa, Diana Liskovich, Wenhan Xiong, Vittorio Caggiano, Sean Naren, Min Xu, Jieru Hu, Marta Tintore, Susan Zhang, et al. xformers: A modular and hackable transformer modelling library, 2022
2022
-
[66]
Limitations
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2818–2829, 2023. 40 NeurIPS Paper Checklist 1.Cla...
2023
-
[67]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.