Polar: Agentic RL on Any Harness at Scale
Pith reviewed 2026-06-30 14:35 UTC · model grok-4.3
The pith
Polar lets any agent harness run scalable RL by proxying LLM calls and rebuilding token-faithful trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
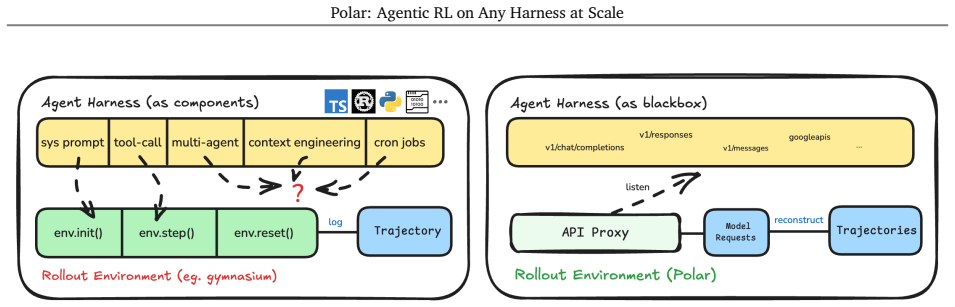
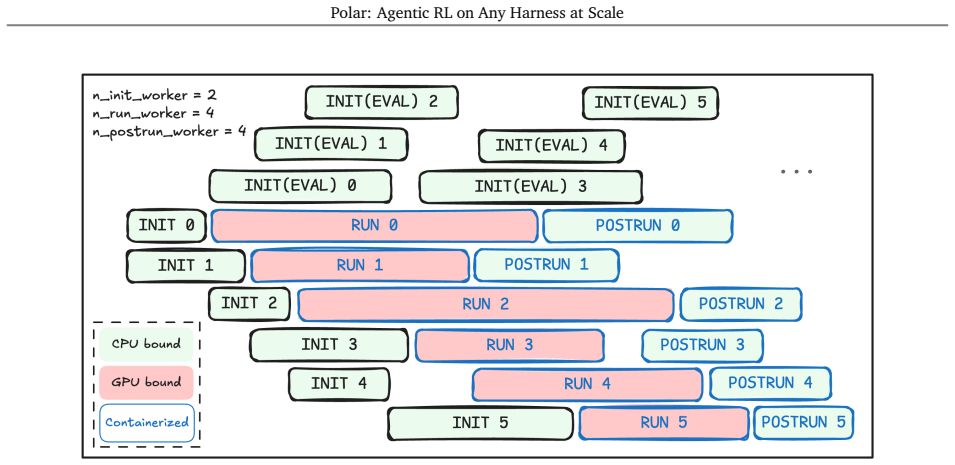
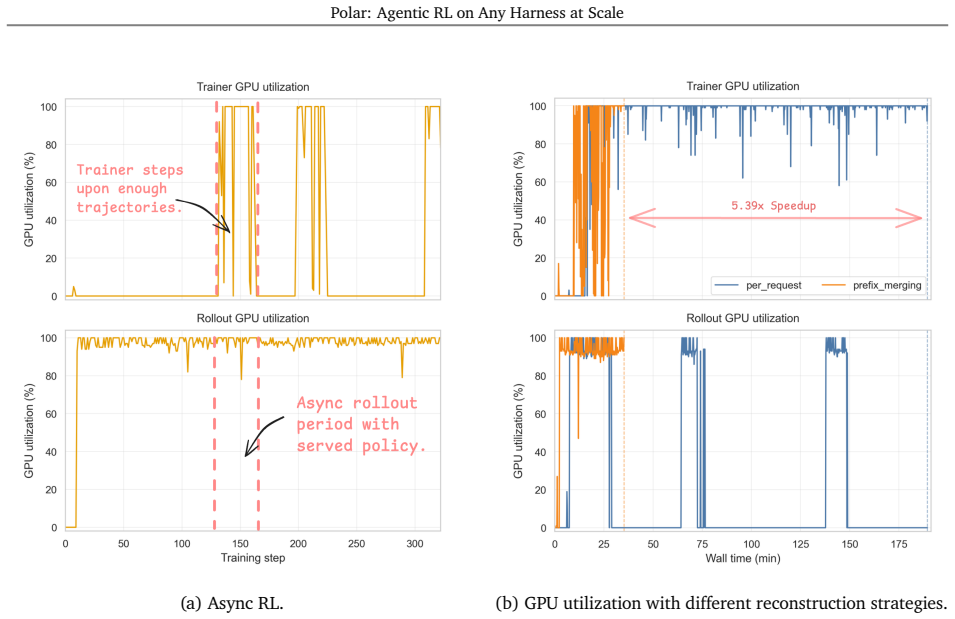
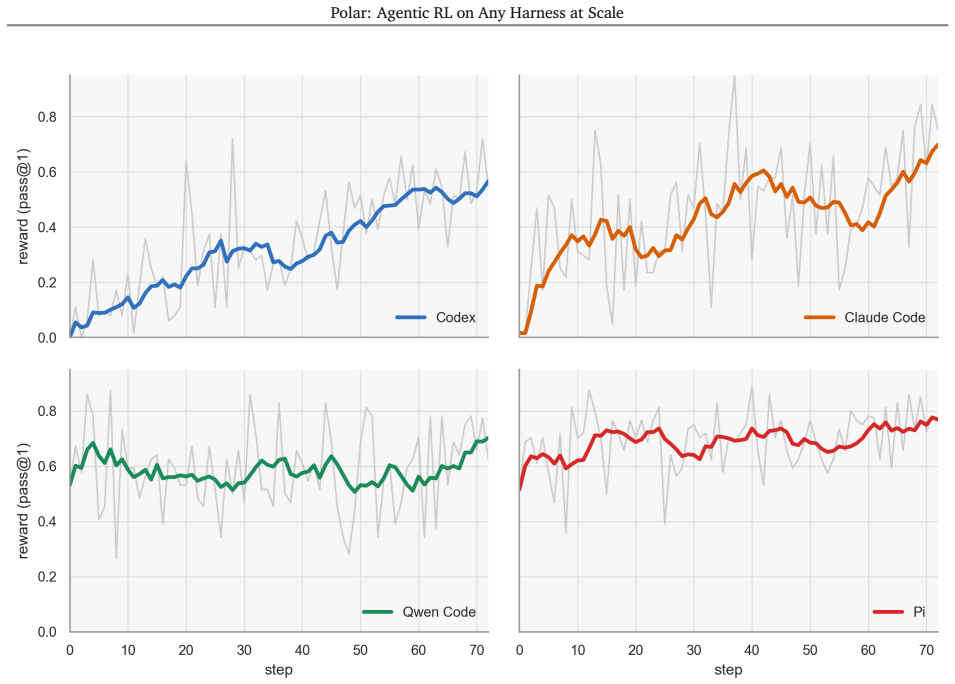
Polar treats the agent harness as a black box: it proxies LLM API calls, records token-level model interactions, and reconstructs token-faithful trajectories for training. Each rollout node handles runtime prewarming, agent execution, trajectory reconstruction, and evaluation in parallel, exposing asynchronous service endpoints that independent trainers can consume at scale. Using this mechanism with GRPO, the framework improves Qwen3.5-4B by 22.6, 4.8, 0.6 and 6.2 points on SWE-Bench Verified with the Codex, Claude Code, Qwen Code and Pi harnesses respectively.
What carries the argument
Black-box proxy of LLM API calls plus token-level trajectory reconstruction that turns an arbitrary harness into a source of training data without internal changes.
If this is right
- Existing coding harnesses can be used for RL without rewriting them as RL environments.
- Rollout nodes can be scaled independently of trainers for better utilization on long-running tasks.
- The same framework supports both online RL and offline data generation over custom harnesses.
- Simple algorithms like GRPO become viable across multiple harnesses without harness-specific tuning.
Where Pith is reading between the lines
- The approach could let researchers train agents on closed-source or proprietary harnesses where source access is unavailable.
- If reconstruction fidelity holds, the same proxy pattern might apply to non-coding agent domains that already have mature harnesses.
- Decoupling could reduce duplication of effort in the community by letting one harness serve both evaluation and RL training pipelines.
Load-bearing premise
Proxying the LLM calls inside an arbitrary harness and reconstructing trajectories from those calls preserves every training signal required for effective RL.
What would settle it
A side-by-side comparison on the same harness and model where native RL integration produces higher final performance or faster convergence than Polar-mediated training.
Figures

read the original abstract
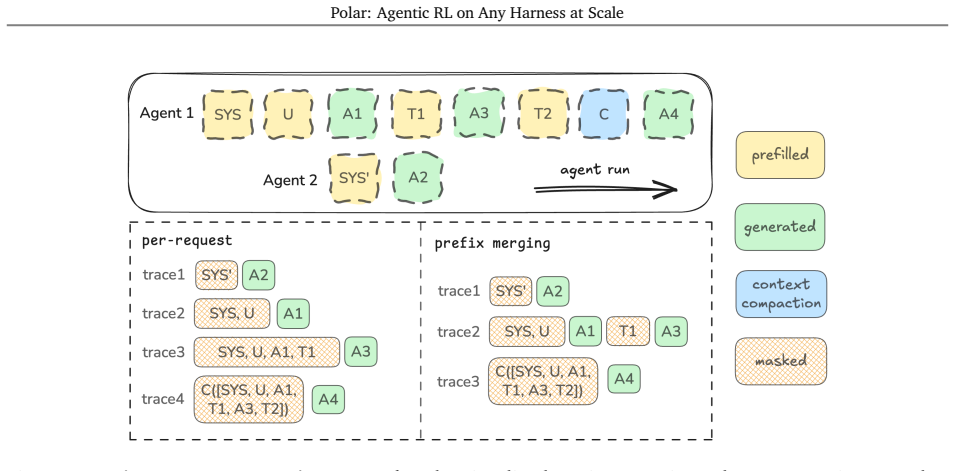
Reinforcement learning for language agents increasingly depends on custom harnesses that manage long-running context, multi-turn tool use and multi-agent orchestration. However, porting these harnesses into RL environment interfaces remains difficult and often loses important training signals. We bridge this gap with polar, a rollout framework for scalable asynchronous RL over arbitrary agent harnesses. Polar treats the agent harness as a black box: it proxies LLM API calls, records token-level model interactions, and reconstructs token-faithful trajectories for training. Each rollout node efficiently manages runtime prewarming, agent execution, trajectory reconstruction, and evaluation in parallel, exposing asynchronous service endpoints that can be consumed by independent trainers at scale. This decoupled design makes Polar agnostic to agent harnesses, training infrastructure, and RL algorithms while improving compute utilization for long-running agent workloads. We validate polar by training agents on software-engineering tasks with popular coding harnesses. Using simple GRPO, polar improves Qwen3.5-4B by 22.6, 4.8, 0.6 and 6.2 points on SWE-Bench Verified with the Codex, Claude Code, Qwen Code and Pi harnesses, respectively. We further demonstrate Polar for offline data generation over custom harnesses and ablate trajectory reconstruction strategies. Polar rewrites its preceding work, Prorl Agent, and has been registered as one of NeMo Gym environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Polar, a rollout framework for scalable asynchronous RL over arbitrary agent harnesses. It treats harnesses as black boxes by proxying LLM API calls, recording token-level interactions, and reconstructing token-faithful trajectories for training. Using GRPO, it reports improvements of 22.6, 4.8, 0.6, and 6.2 points on SWE-Bench Verified for Qwen3.5-4B across the Codex, Claude Code, Qwen Code, and Pi harnesses, respectively, along with demonstrations of offline data generation and ablations of reconstruction strategies.
Significance. If the empirical results hold under rigorous evaluation, Polar would meaningfully lower the barrier to applying RL to complex, long-running agent systems by decoupling harness logic from training infrastructure. The multi-harness validation and explicit ablations directly test the viability of the black-box proxy approach, which is a practical strength.
major comments (1)
- [Results] Results section (and abstract): the reported point improvements on SWE-Bench Verified are presented without error bars, number of runs, statistical significance tests, baseline details, or controls for harness-specific variance. These omissions are load-bearing because the gains constitute the primary evidence that proxying and trajectory reconstruction preserve sufficient training signal for effective GRPO.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of Polar to lower barriers for RL on complex agent systems. We address the major comment on results presentation below and commit to revisions that strengthen the empirical evidence.
read point-by-point responses
-
Referee: [Results] Results section (and abstract): the reported point improvements on SWE-Bench Verified are presented without error bars, number of runs, statistical significance tests, baseline details, or controls for harness-specific variance. These omissions are load-bearing because the gains constitute the primary evidence that proxying and trajectory reconstruction preserve sufficient training signal for effective GRPO.
Authors: We agree that the absence of these details weakens the primary claims. In the revised manuscript we will: (1) report the number of independent training runs (minimum three seeds per harness), (2) add error bars (standard deviation across runs) to all reported point improvements, (3) include statistical significance tests (e.g., paired t-tests or Wilcoxon) comparing Polar-trained agents against the corresponding baselines, (4) expand baseline descriptions to clarify the exact harness configurations and evaluation protocols used, and (5) add explicit controls or discussion of harness-specific variance (e.g., by reporting per-harness variance and any normalization steps). These changes will appear in both the results section and the abstract. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an engineering framework (Polar) for asynchronous RL rollouts over arbitrary agent harnesses, validated empirically via performance gains on the external SWE-Bench Verified benchmark across four distinct harnesses plus ablations of reconstruction strategies. No mathematical derivations, first-principles predictions, or fitted parameters are claimed; the central results are direct measurements against independent external benchmarks rather than quantities defined internally by the framework. The incidental note that Polar rewrites prior work (Prorl Agent) is not load-bearing for any claim and does not invoke uniqueness theorems or ansatzes from self-citations. The work is therefore self-contained against external benchmarks with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Trajectory reconstruction from proxied LLM API calls inside an arbitrary harness is faithful and lossless for RL purposes
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
2 Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025. 2 Harbor Framework Team. Harbor: A framework for evaluating and optimizing agents and models in container ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
URLhttps://github.com/PrimeIntellect-ai/prime-rl. GitHub repository. 2, 3, 15 13 Polar: Agentic RL on Any Harness at Scale Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
SGLang: Efficient Execution of Structured Language Model Programs
URLhttps://arxiv.org/abs/2312.07104. 3 Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents. arXiv preprint arXiv:2307.13854, 2023. 2 Zilin Zhu, Chengxing Xie, Xin Lv, and Contributors. slime: An llm post-t...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.