Analyzing the Effects of Two-Stage Peer Evaluation
Pith reviewed 2026-06-30 14:15 UTC · model grok-4.3
The pith
Two-stage peer evaluation selects different agents based on how noisy reviewer beliefs are.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
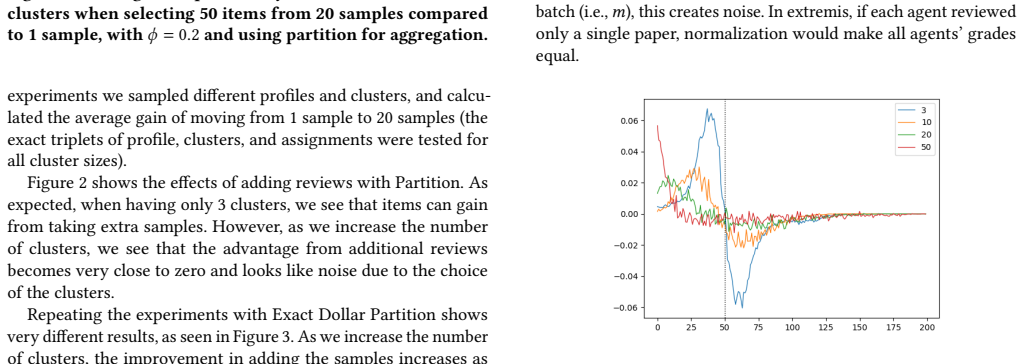
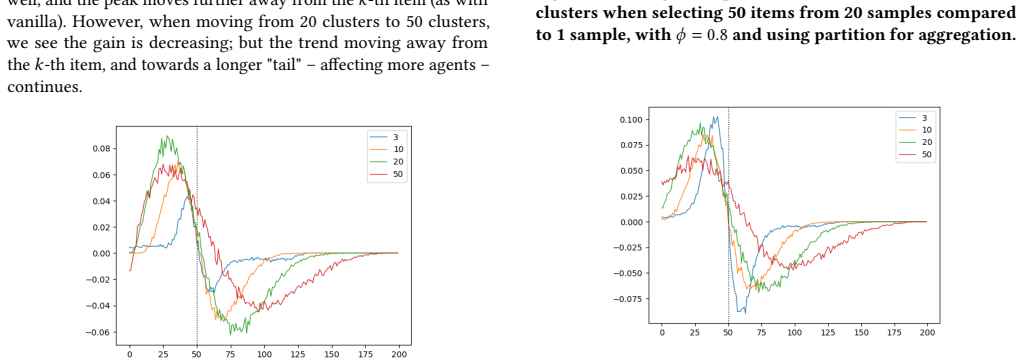
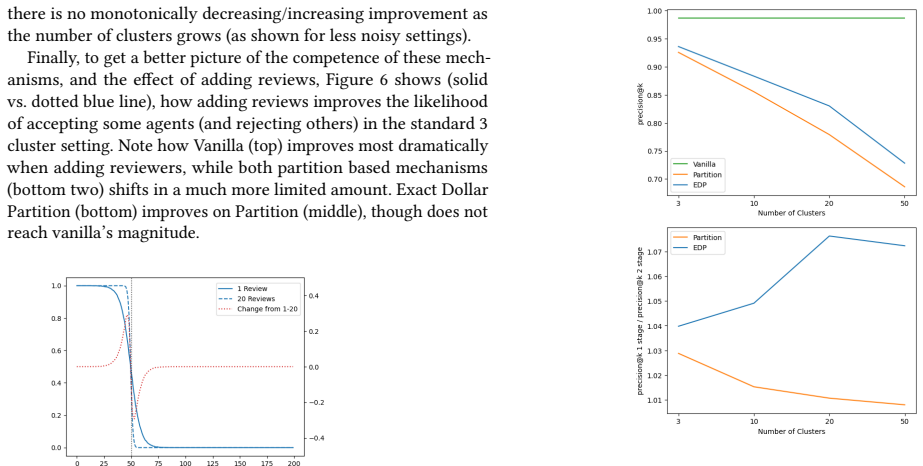
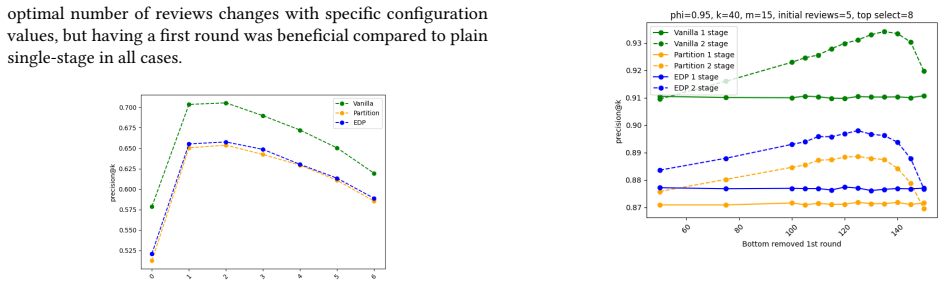
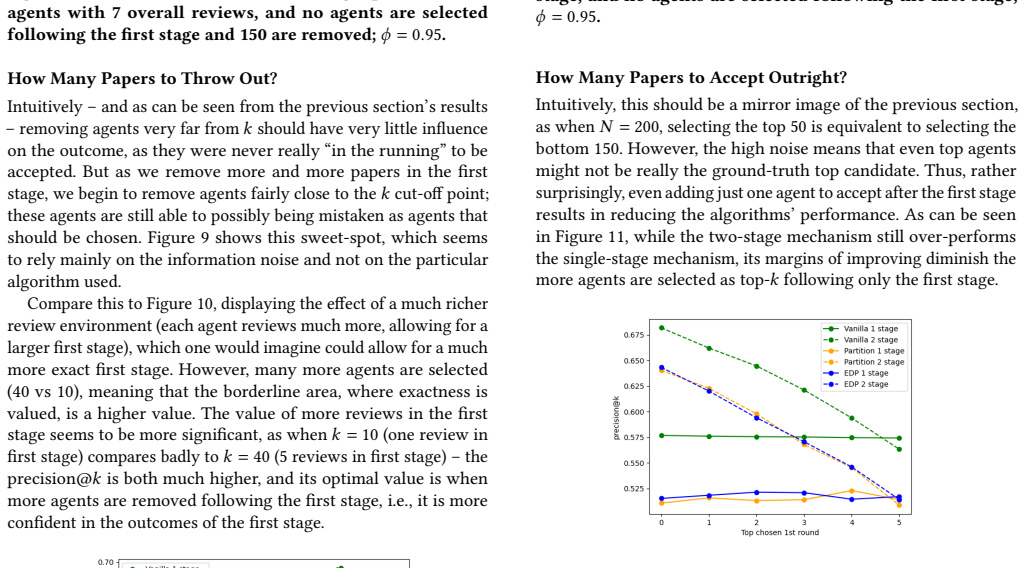
The authors establish that converting Partition and ExactDollarPartition into two-stage processes changes selection probabilities in ways that depend on reviewer noise: borderline agents are helped most when noise is low, while high-rank agents are helped most when noise is high. They also show that the size of these shifts is sensitive to the number of agents ultimately selected, the number of reviews requested from each agent, and the degree of correlation among reviewers.
What carries the argument
Two-stage adaptations of the Partition and ExactDollarPartition mechanisms, in which an initial round of reviews eliminates some agents before survivors receive additional reviews.
If this is right
- Borderline agents receive higher selection probability under two-stage Partition and ExactDollarPartition when reviewer noise is low.
- High-rank agents receive higher selection probability under the same mechanisms when reviewer noise is high.
- Changing the target number of selected agents or the number of reviews per agent can reverse or amplify the two-stage effect.
- Higher correlation among reviewers reduces the size of the shifts produced by moving to two stages.
Where Pith is reading between the lines
- Organizers could estimate typical reviewer disagreement in their field before deciding whether a two-stage process is likely to change the selected set.
- Domains with naturally low reviewer correlation may see more stable outcomes across one-stage and two-stage designs.
- Empirical tests on archived review data could check whether the simulated noise thresholds match observed selection changes.
Load-bearing premise
That the range of simulated noise levels, correlations, and parameter values captures the essential behavior of real peer-evaluation systems where agents may strategize and reviews follow the modeled distributions.
What would settle it
A controlled experiment or analysis of conference data before and after switching to a two-stage process that checks whether the selection rate for borderline agents rises relative to top agents precisely when reviewer disagreement is low.
Figures




read the original abstract
Peer-evaluation and selection systems are used when sets of agents evaluate each other in order to select the best $k$ among them. These are commonly used in real-world settings, including academic conferences where those reviewing papers are often the set of submitters. Conferences have attempted to better allocate their reviewing resources by moving to a two-stage mechanism, in which some papers are eliminated after a first stage of review and remaining papers receive additional reviewers. We investigate how two major strategyproof peer selection mechanisms, Partition and ExactDollarPartition, perform when adapted to a two-stage system, in order to try and understand the effect of the two-stage mechanism on which agents get selected. We also examine how the various parameters of the two-stage mechanism influence the outcome. We provide a theoretical basis by showing how a particular setting is influenced by the two stages. However, solving for the general case seems implausible at the moment, and we use extensive simulations of different scenarios and settings to observe which agents benefit and which are harmed by adopting two-stage mechanisms (and we vary this mechanisms parameters as well). We show that the two-stage mechanism's advantage depends the noisiness of reviewer beliefs. Borderline agents benefit most in a low noise environment, while high rank agents benefit more in noisy environments. We show that the effectiveness of these mechanisms is highly dependent on the number of chosen agents, the number of reviews requested from agents, and reviewers' correlation, indicating that organizers need to exercise caution when selecting these parameters for a reviewing process.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes adaptations of the Partition and ExactDollarPartition peer-selection mechanisms to a two-stage review process, in which some agents are eliminated after an initial round of reviews and the remainder receive additional reviews. It derives a theoretical result for one specific setting showing how the two stages affect selection probabilities, but states that the general analytic case is intractable. The authors therefore rely on extensive simulations that vary reviewer noise levels, correlations, number of agents selected, and number of reviews per agent. The central claim is that the two-stage mechanism's advantage depends on the noisiness of reviewer beliefs: borderline agents benefit most under low noise, while high-rank agents benefit more under high noise. The paper further reports that outcomes are highly sensitive to the number of chosen agents, reviews requested, and reviewer correlation.
Significance. If the simulation patterns prove robust, the work supplies concrete guidance for conference organizers on when and how to deploy two-stage mechanisms while preserving strategyproofness properties. The explicit recognition that the general case is intractable and the consequent turn to simulation is a methodological strength. The differential benefit findings (borderline vs. high-rank agents) are falsifiable predictions that could be tested against real review-score distributions. At present, however, the absence of calibration or validation against empirical peer-review data limits immediate applicability to deployed systems.
major comments (2)
- [Abstract] Abstract and simulation sections: The headline claim that 'the two-stage mechanism's advantage depends on the noisiness of reviewer beliefs' (with borderline agents benefiting in low noise and high-rank agents in high noise) rests on simulations whose generative models for noise and correlation are not validated against real conference score data. No sensitivity checks or external calibration are described, which is load-bearing for any claim that the reported patterns inform actual peer-evaluation systems.
- [Theoretical Analysis] Theoretical analysis: The paper provides a closed-form result only for one particular setting and states that the general analytic case is intractable. Without an explicit statement of the assumptions of that setting or a formal argument bounding how far the simulation results may deviate from it, the link between the proven case and the broader simulation conclusions remains unclear.
minor comments (3)
- [Abstract] Abstract: 'depends the noisiness' is missing the preposition 'on'.
- [Abstract] Abstract: 'this mechanisms parameters' should read 'this mechanism's parameters'.
- [Abstract] The abstract states that the effectiveness 'is highly dependent on' three parameters but does not quantify the magnitude of those dependencies or report confidence intervals from the simulations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the methodological approach of turning to simulation given the intractability of the general case. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and simulation sections: The headline claim that 'the two-stage mechanism's advantage depends on the noisiness of reviewer beliefs' (with borderline agents benefiting in low noise and high rank agents in high noise) rests on simulations whose generative models for noise and correlation are not validated against real conference score data. No sensitivity checks or external calibration are described, which is load-bearing for any claim that the reported patterns inform actual peer-evaluation systems.
Authors: We acknowledge that the simulations employ parametric generative models for noise and correlation without direct calibration to empirical conference score distributions. The reported patterns demonstrate qualitative dependence on noise level across varied parameter regimes, but we agree this limits immediate applicability. In revision we will expand the sensitivity analyses (already present for mechanism parameters) to include additional variations in the noise distribution family and will add an explicit limitations subsection discussing the absence of empirical calibration. revision: partial
-
Referee: [Theoretical Analysis] Theoretical analysis: The paper provides a closed-form result only for one particular setting and states that the general analytic case is intractable. Without an explicit statement of the assumptions of that setting or a formal argument bounding how far the simulation results may deviate from it, the link between the proven case and the broader simulation conclusions remains unclear.
Authors: We will revise the theoretical section to state the assumptions of the closed-form result explicitly and to include a discussion of the relationship between that result and the simulation regime, noting the lack of a general bounding argument as a limitation of the current analysis. revision: yes
- Direct empirical calibration or validation against real conference peer-review score data, which would require access to proprietary or restricted datasets not available to the authors for this simulation study.
Circularity Check
No circularity; theory and simulations are independent of fitted inputs or self-citations
full rationale
The paper provides a theoretical analysis only for one narrow setting and then relies on simulations that vary noise, correlation, and other parameters to explore outcomes. No equations or claims reduce by construction to fitted parameters renamed as predictions, and no load-bearing steps depend on self-citations whose content is unverified. The simulations constitute an independent exploration of the generative model rather than a statistical fit to the target quantities.
Axiom & Free-Parameter Ledger
free parameters (4)
- noise level of reviewer beliefs
- number of chosen agents
- number of reviews requested from agents
- reviewers' correlation
axioms (2)
- domain assumption Partition and ExactDollarPartition remain strategyproof when adapted to two stages
- domain assumption Reviewer beliefs about quality can be modeled as noisy signals whose noise level can be controlled in simulation
Reference graph
Works this paper leans on
-
[1]
Procaccia, and Moshe Tennenholtz
Noga Alon, Felix Fischer, Ariel D. Procaccia, and Moshe Tennenholtz. 2011. Sum of us: strategyproof selection from the selectors. InProceedings of the 13th Conference on Theoretical Aspects of Rationality and Knowledge (TARK). Groningen, The Netherlands, 101–110
2011
-
[3]
InProceedings of the 30th Conference on Artificial Intelligence (AAAI)
Strategyproof Peer Selection: Mechanisms, Analyses, and Experiments. InProceedings of the 30th Conference on Artificial Intelligence (AAAI). Phoenix, Arizona, 397–403
-
[4]
Rosenschein, and Toby Walsh
Haris Aziz, Omer Lev, Nicholas Mattei, Jeffrey S. Rosenschein, and Toby Walsh
-
[5]
https: //doi.org/10.1016/j.artint.2019.06.004
Strategyproof peer selection using randomization, partitioning, and ap- portionment.Artificial Intelligence (AIJ)275 (October 2019), 295–309. https: //doi.org/10.1016/j.artint.2019.06.004
-
[6]
Yukino Baba and Hisashi Kashima. 2013. Statistical quality estimation for gen- eral crowdsourcing tasks. InProceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. 554–562
2013
-
[7]
Terry A Beehr, Lana Ivanitskaya, Curtiss P Hansen, Dmitry Erofeev, and David M Gudanowski. 2001. Evaluation of 360 degree feedback ratings: Relationships with each other and with performance and selection predictors.Journal of Organizational Behavior: The International Journal of Industrial, Occupational and Organizational Psychology and Behavior22, 7 (20...
2001
-
[8]
Antje Bjelde, Felix Fischer, and Max Klimm. 2017. Impartial Selection and the Power of Up to Two Choices.ACM Transactions on Economics and Computation (TEAC)5, 4 (December 2017), 1–20. 10Similar to the ARR Rolling Review Process in the NLP community, https:// aclrollingreview.org/
2017
-
[9]
Niclas Boehmer, Piotr Faliszewski, Łukasz Janeczko, Andrzej Kaczmarczyk, Grze- gorz Lisowski, Grzegorz Pierczyński, Simon Rey, Dariusz Stolicki, Stanisław Szufa, and Tomasz Wąs. 2024. Guide to numerical experiments on elections in computational social choice.arXiv preprint arXiv:2402.11765(2024)
-
[10]
Niclas Boehmer, Piotr Faliszewski, and Sonja Kraiczy. 2023. Properties of the Mallows model depending on the number of alternatives: A warning for an experimentalist. InInternational Conference on Machine Learning. PMLR, 2689– 2711
2023
-
[11]
Nicolas Bousquet, Sergey Norin, and Adrian Vetta. 2014. A Near-Optimal Mecha- nism for Impartial Selection. InProceedings of the 10th International Conference on Web and Internet Economics (WINE). Beijing, China, 133–146
2014
-
[12]
Alec Burmania, Srinivas Parthasarathy, and Carlos Busso. 2015. Increasing the reliability of crowdsourcing evaluations using online quality assessment.IEEE Transactions on Affective Computing7, 4 (2015), 374–388
2015
-
[13]
Vincent Conitzer and Tuomas Sandholm. 2005. Common voting rules as max- imum likelihood estimators. InProceedings of the Twenty-First Conference on Uncertainty in Artificial Intelligence. 145–152
2005
-
[14]
Felix Fischer and Max Klimm. 2015. Optimal Impartial Selection.SIAM J. Comput. 44, 5 (2015), 1263–1285
2015
-
[15]
Procaccia
Bailey Flanigan, Gregory Kehne, and Ariel D. Procaccia. 2021. Fair Sortition Made Transparent. InProceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS), Vol. 34. 25720–25731
2021
-
[16]
Wright, and Kevin Leyton-Brown
Xi Alice Gao, James R. Wright, and Kevin Leyton-Brown. 2019. Incentivizing evaluation with peer prediction and limited access to ground truth.Artificial Intelligence (AIJ)275 (October 2019), 618–638
2019
-
[17]
Alexander Goldberg, Ivan Stelmakh, Kyunghyun Cho, Alice Oh, Alekh Agar- wal, Danielle Belgrave, and Nihar B Shah. 2025. Peer reviews of peer reviews: A randomized controlled trial and other experiments.PloS one20, 4 (2025), e0320444
2025
-
[18]
Iryna Gurevych, Anna Rogers, Nihar B Shah, and Jingyan Wang. 2024. Reviewer No. 2: Old and New Problems in Peer Review (Dagstuhl Seminar 24052).Dagstuhl Reports14, 1 (2024), 130–161
2024
-
[19]
Ron Holzman and Hervé Moulin. 2013. Impartial Nominations for a Prize.Econo- metrica81, 1 (January 2013), 173–196
2013
-
[20]
Maurice G Kendall. 1938. A new measure of rank correlation.Biometrika30, 1-2 (1938), 81–93
1938
-
[21]
Jaeho Kim, Yunseok Lee, and Seulki Lee. 2025. Position: The AI Con- ference Peer Review Crisis Demands Author Feedback and Reviewer Re- wards.CoRRabs/2505.04966 (2025). https://doi.org/10.48550/ARXIV.2505.04966 arXiv:2505.04966
-
[22]
Procaccia
David Kurokawa, Omer Lev, Jamie Morgenstern, and Ariel D. Procaccia. 2015. Impartial Peer Review. InProceedings of the 24th International Joint Conference on Artificial Intelligence (IJCAI). Buenos Aires, Argentina, 582–588. http://www. cs.toronto.edu/~omerl/papers/ijcai15a.pdf
2015
-
[23]
Lawrence
Neil D. Lawrence. 2022. The NeurIPS Experiment. http://inverseprobability. com/talks/notes/the-neurips-experiment-snsf.html
2022
-
[24]
Omer Lev, Harper Lyon, and Nicholas Mattei. 2024. Impartial Peer Selection: An Annotated Reading List.ACM SIGecom Exchanges22, 1 (2024), 113–117
2024
-
[25]
Omer Lev, Nicholas Mattei, Paolo Turrini, and Stanislav Zhydkov. 2023. Peer- Nomination: A novel peer selection algorithm to handle strategic and noisy assessments.Artificial Intelligence (AIJ)316 (March 2023), 103843
2023
-
[26]
Kevin Leyton-Brown, Mausam, Yatin Nandwani, Hedayat Zarkoob, Chris Cameron, Neil Newman, and Dinesh Raghu. 2022. Matching Papers and Re- viewers at Large Conferences. (August 2022). ArXiV
2022
-
[27]
Heng Luo, Anthony C Robinson, and Jae-Young Park. 2014. Peer grading in a MOOC: Reliability, validity, and perceived effects.Journal of Asynchronous Learning Networks18, 2 (2014), n2
2014
-
[28]
Colin Lingwood Mallows. 1957. Non-null ranking models. I.Biometrika44, 1-2 (June 1957), 114–130
1957
-
[29]
Nicholas Mattei, Paolo Turrini, and Stanislav Zhydkov. 2020. PeerNomination: Relaxing Exactness for Increased Accuracy in Peer Selection. InProceedings of the 29th International Joint Conference on Artificial Intelligence (IJCAI). Yokohama, Japan, 393–399
2020
-
[30]
Nicholas Mattei and Toby Walsh. 2013. Preflib: A library for preferences http://www. preflib. org. InInternational conference on algorithmic decision theory. Springer, 259–270
2013
-
[31]
Merrifield and Donald G
Michael R. Merrifield and Donald G. Saari. 2009. Telescope time without tears: a distributed approach to peer review.Astronomy & Geophysics50, 4 (2009), 4–16
2009
-
[32]
Noam Nisan and Amir Ronen. 1999. Algorithmic mechanism design. InProceed- ings of the thirty-first annual ACM symposium on Theory of computing. 129–140
1999
-
[33]
Ritesh Noothigattu, Nihar Shah, and Ariel Procaccia. 2021. Loss functions, axioms, and peer review.Journal of Artificial Intelligence Research70 (2021), 1481–1515
2021
-
[34]
Shah, and Ariel D
Ritesh Noothigattu, Nihar B. Shah, and Ariel D. Procaccia. 2019.Choosing How to Choose Papers. Technical Report. Carnegie Mellon University
2019
-
[35]
Matthew Olckers and Toby Walsh. 2024. Manipulation and peer mechanisms: A survey.Artificial Intelligence336 (2024), 104196
2024
-
[36]
Francesco Ricci, Lior Rokach, and Bracha Shapira. 2021. Recommender systems: Techniques, applications, and challenges.Recommender systems handbook(2021), 1–35
2021
-
[37]
Nihar B. Shah. 2022. Challenges, experiments, and computational solutions in peer review.Commun. ACM65, 6 (2022), 76–87
2022
-
[38]
Nihar B Shah, Behzad Tabibian, Krikamol Muandet, Isabelle Guyon, and Ulrike Von Luxburg. 2018. Design and analysis of the NIPS 2016 review process.Journal of machine learning research19, 49 (2018), 1–34
2018
-
[39]
Shah, and Aarti Singh
Ivan Stelmakh, Nihar B. Shah, and Aarti Singh. 2019.On Testing for Biases in Peer Review. Technical Report. Carnegie Mellon University
2019
-
[40]
Pothula Sujatha and P Dhavachelvan. 2011. Precision at K in multilingual infor- mation retrieval.Int J Comput Appl24 (2011), 40–3
2011
-
[41]
Toby Walsh. 2014. The PeerRank Method for Peer Assessment. InProceedings of the 21st European Conference on Artificial Intelligence (ECAI). Prague, Czech Republic, 909–914
2014
-
[42]
Jingyan Wang and Nihar B Shah. 2019. Your 2 is My 1, Your 3 is My 9: Handling Arbitrary Miscalibrations in Ratings. InProceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems. 864–872
2019
-
[43]
Jingyan Wang and Nihar B. Shah. 2019. Your 2 is My 1, Your 3 is My 9: Handling Arbitrary Miscalibrations in Ratings. InProceedings of the 18th International Conference on Autonomous Agents and Multiagent Systems (AAMAS). Montréal, Canada, 864–872
2019
-
[44]
Yichong Xu, Han Zhao, Xiaofei Shi, and Nihar B. Shah. 2019. On Strategyproof Conference Peer Review. InProceedings of the 28th International Joint Conference on Artificial Intelligence (IJCAI). Macau, 616–622
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.