A lift for input-convex neural network training
Pith reviewed 2026-06-30 15:43 UTC · model grok-4.3
The pith
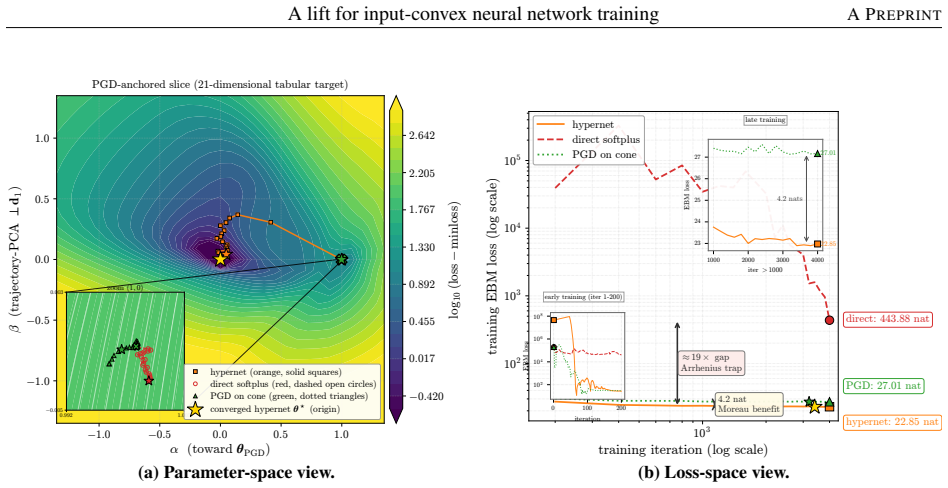
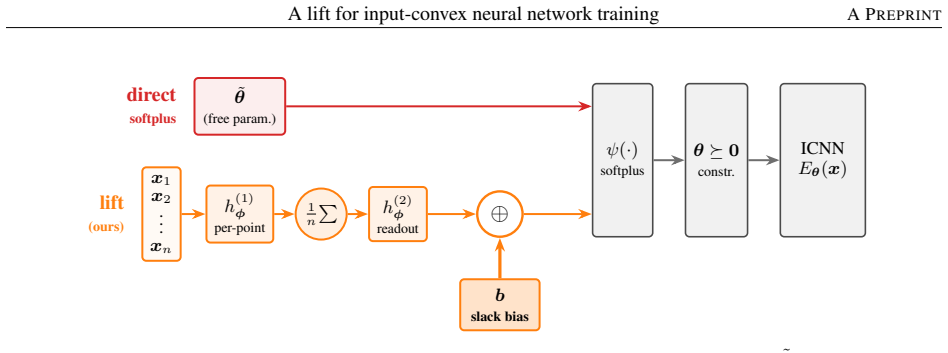
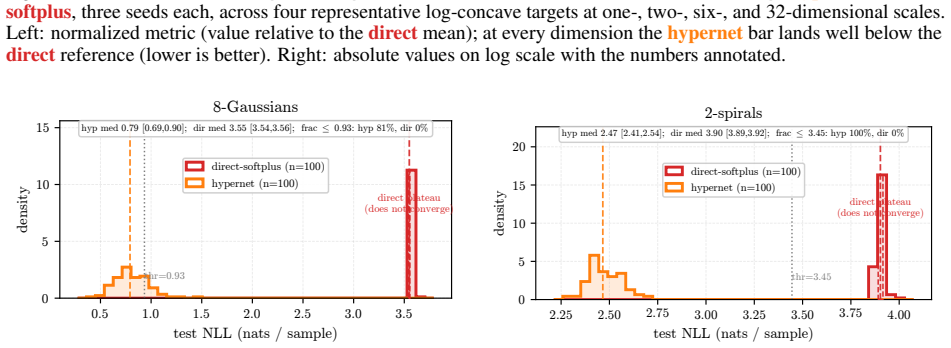
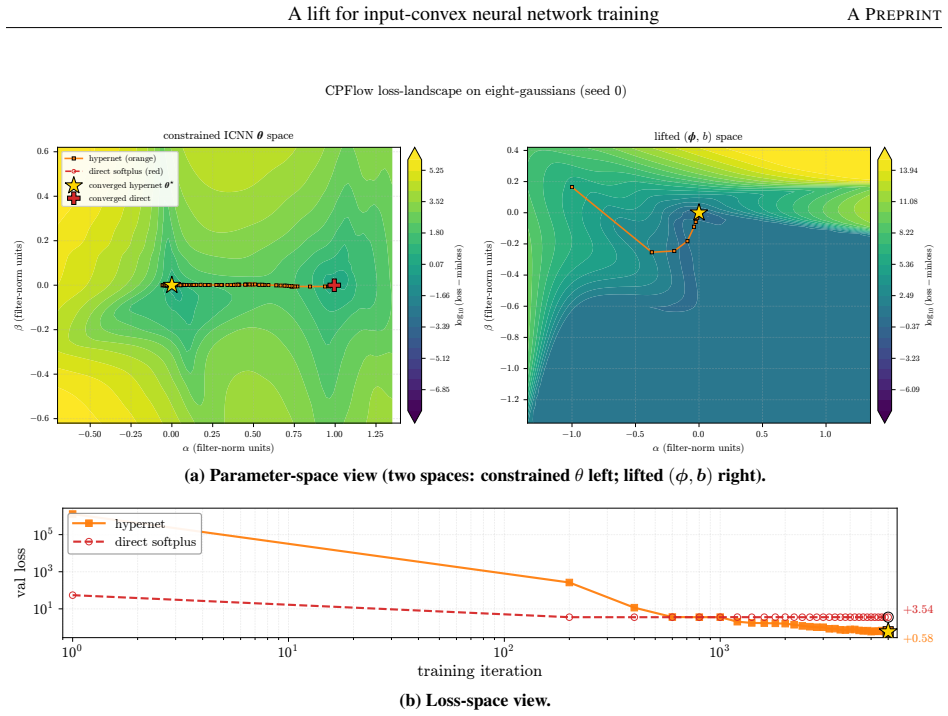
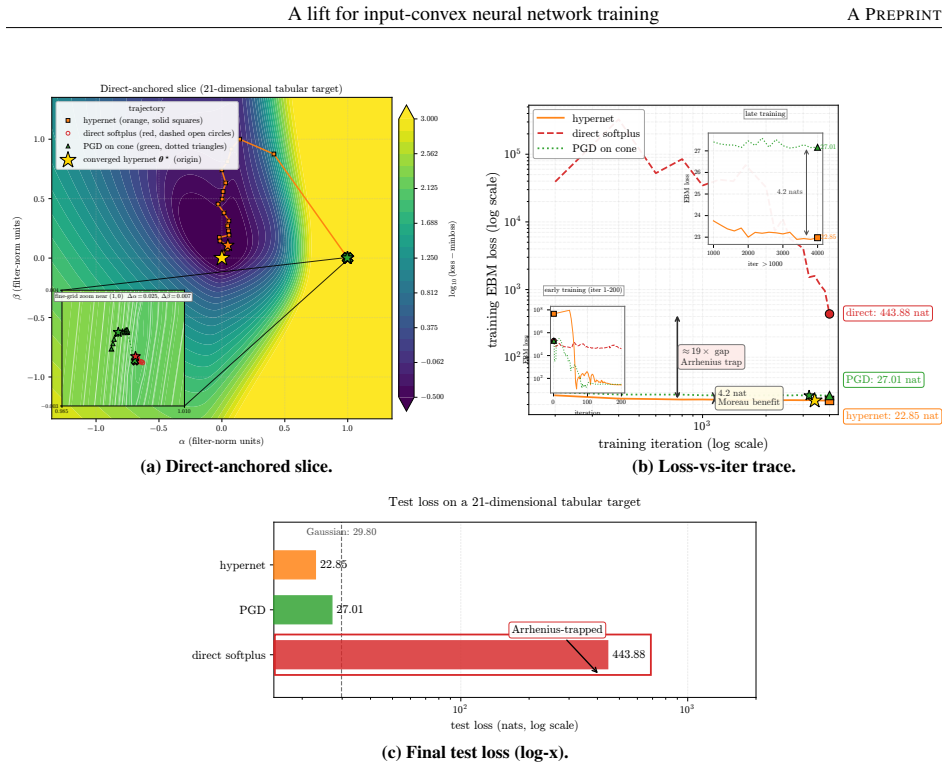
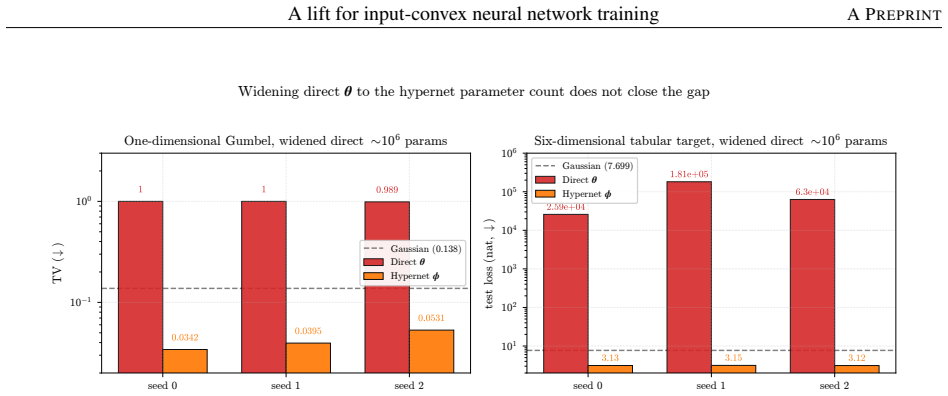
An unconstrained hypernetwork emitting ICNN inter-layer weights from batch summaries softens the loss landscape and reaches lower test loss than PGD or softplus.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
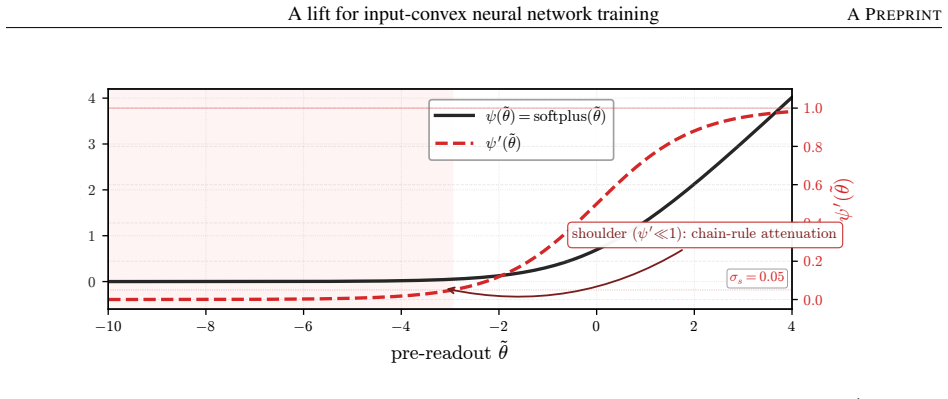
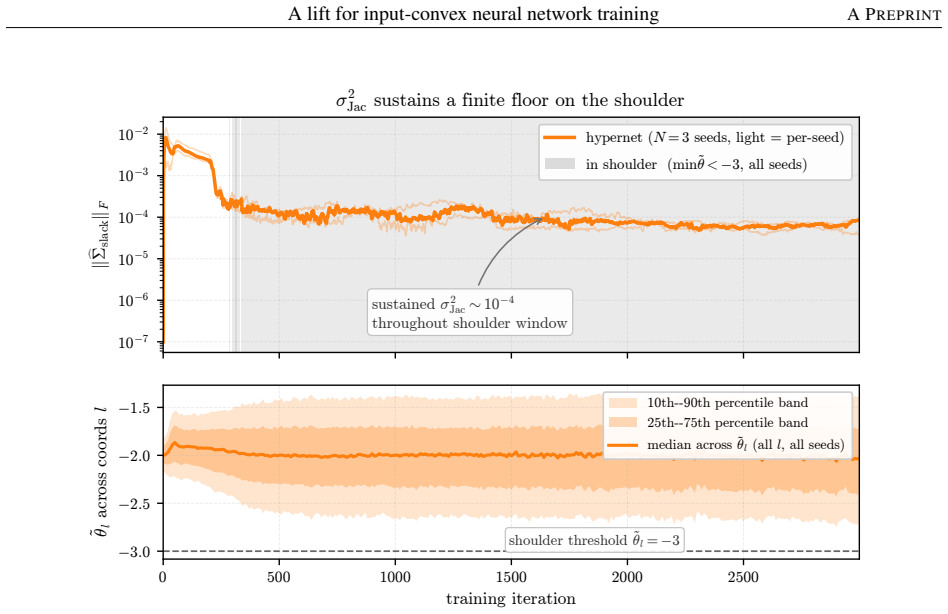
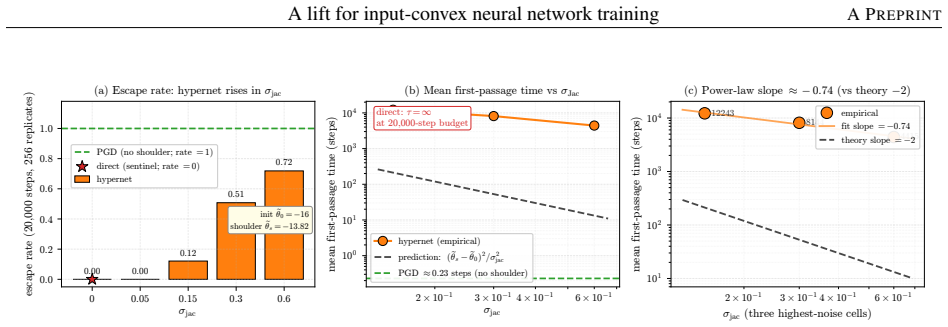
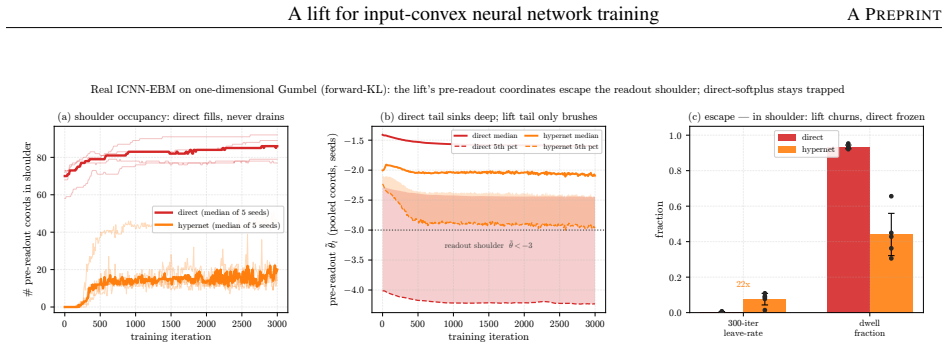
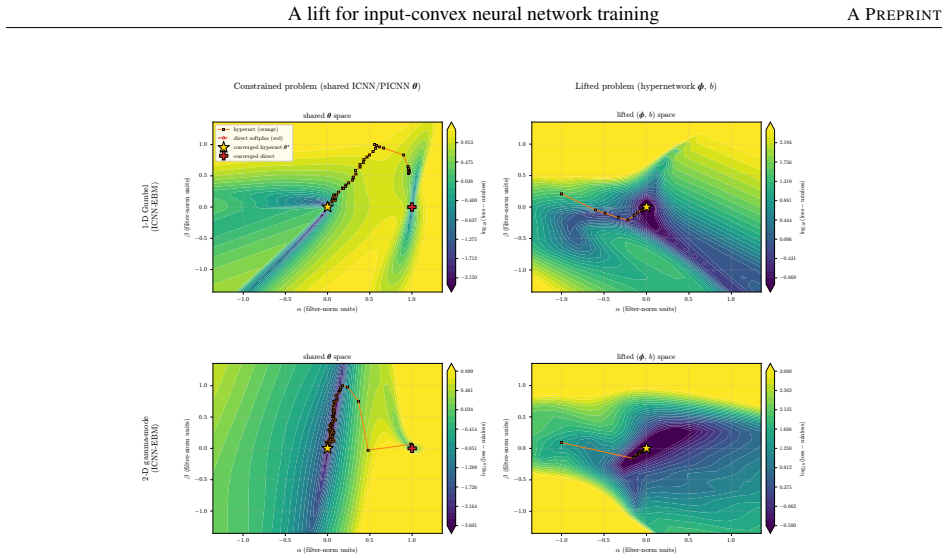
Instead of constraining inter-layer weights directly, the lift trains an unconstrained hypernetwork that emits the weights from a permutation-invariant summary of the input batch. This adds stochasticity to the training dynamics that softens the loss landscape, letting the iterates escape the gradient-attenuated region where direct softplus stalls. The softening is traced to three structural ingredients—a learnable bias acting as slack, a hypernetwork body that conditions on the target batch, and a cross-covariance coupling the two through batch stochasticity—and each is proven necessary because deleting any single ingredient collapses the cross-covariance that carries the softening. On log-
What carries the argument
The lift: an unconstrained hypernetwork that emits non-negative inter-layer weights from a permutation-invariant summary of the input batch, adding stochasticity via cross-covariance.
If this is right
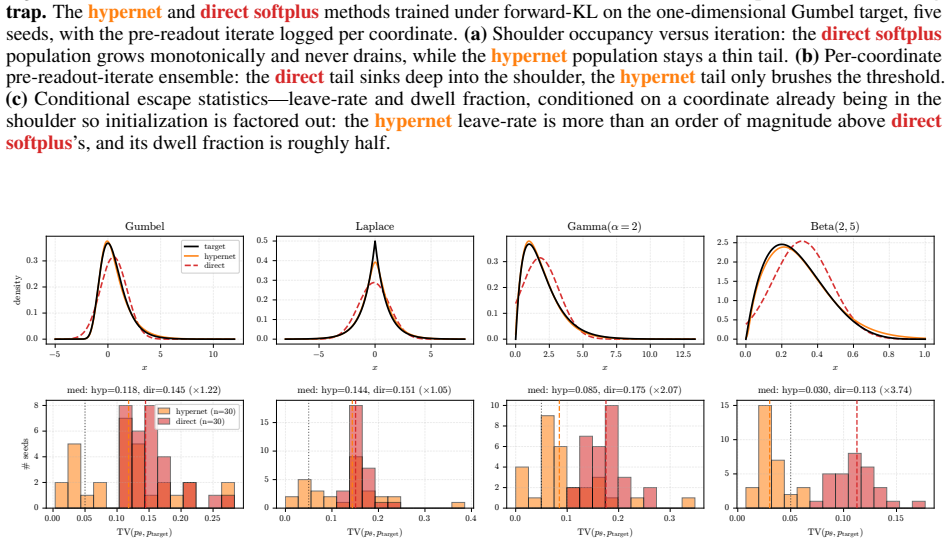
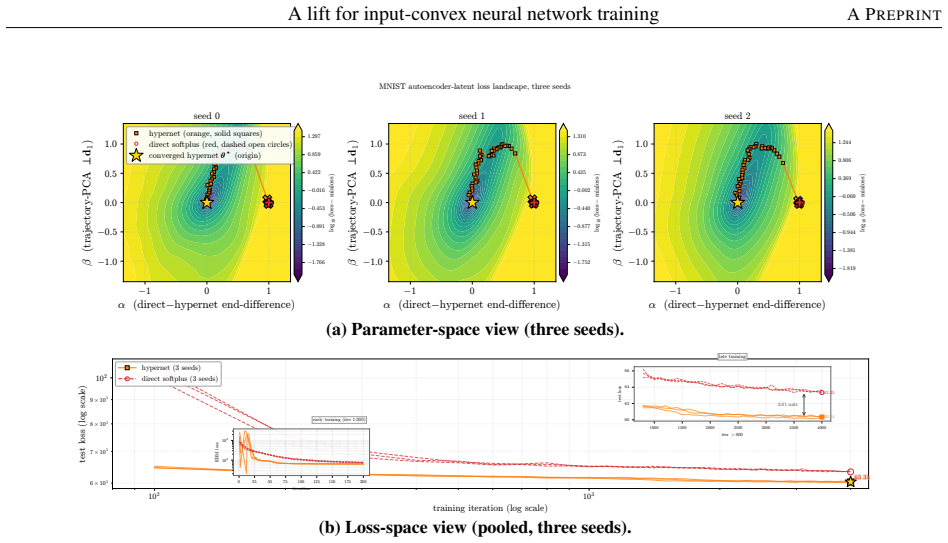
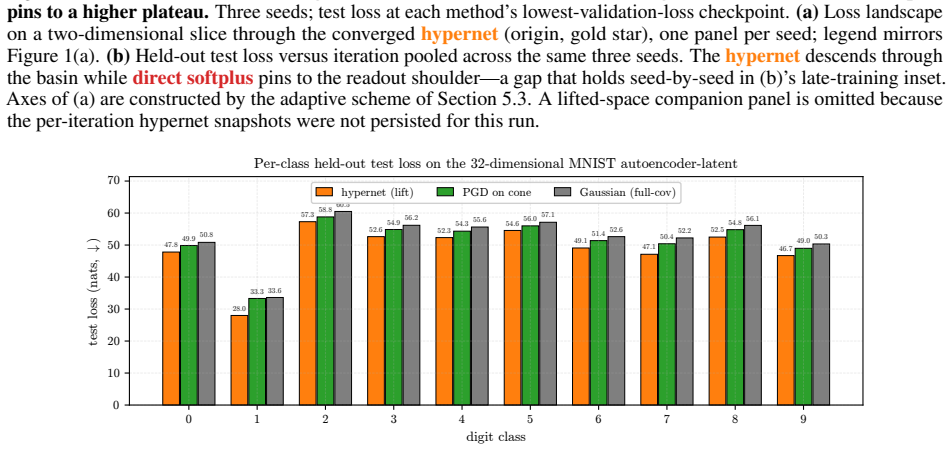
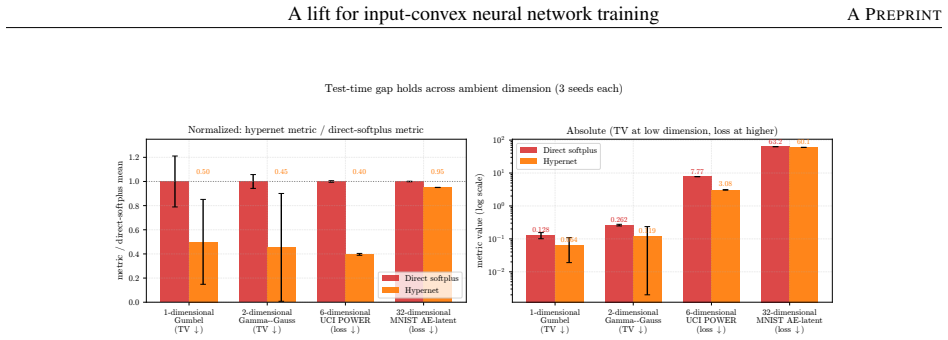
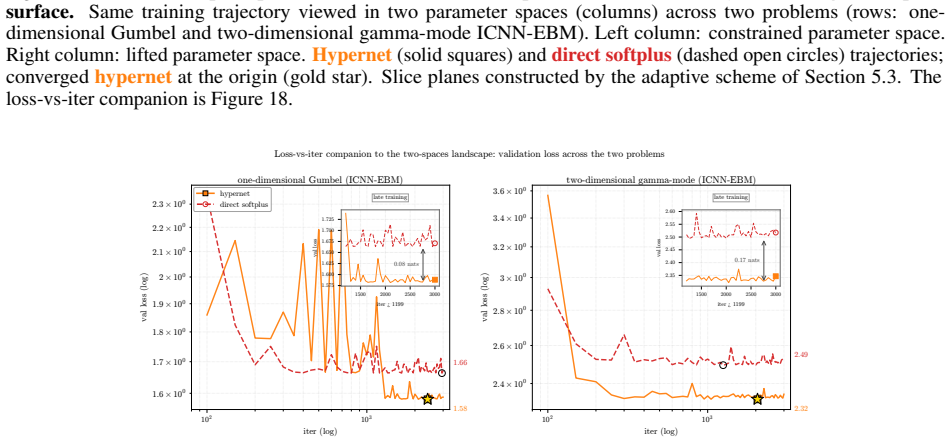
- ICNNs reach lower test loss on log-concave energy-based modeling tasks spanning one-dimensional targets to image-flavored latents.
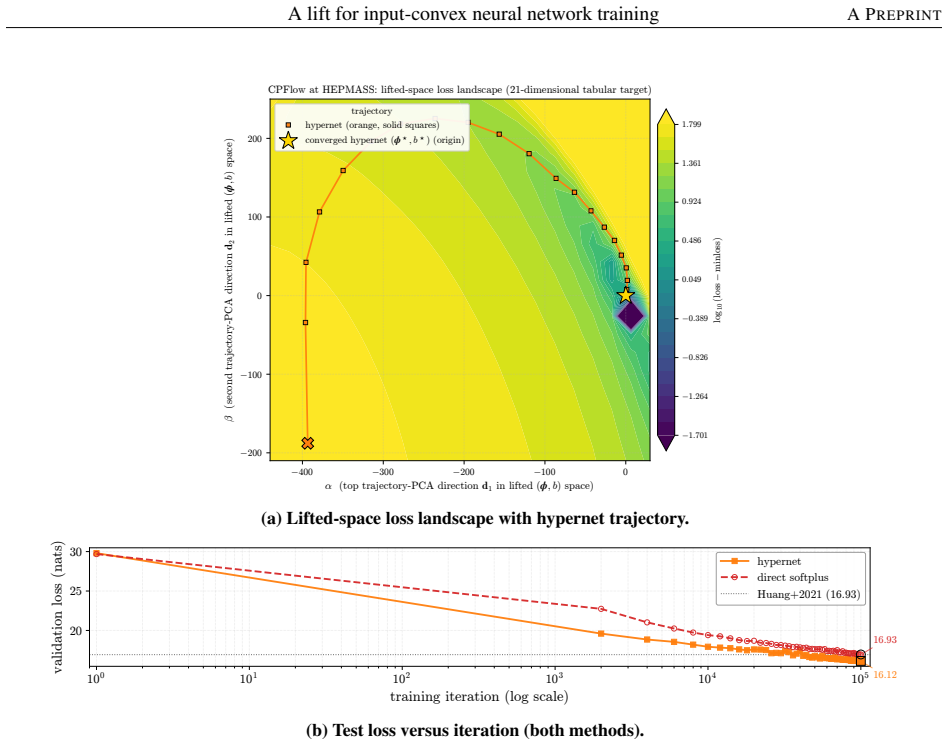
- Convex-potential normalizing flows on 21-dimensional tabular data obtain valley-descending trajectories instead of plateaus.
- The softening of the loss landscape requires the simultaneous presence of the learnable bias, batch conditioning, and cross-covariance.
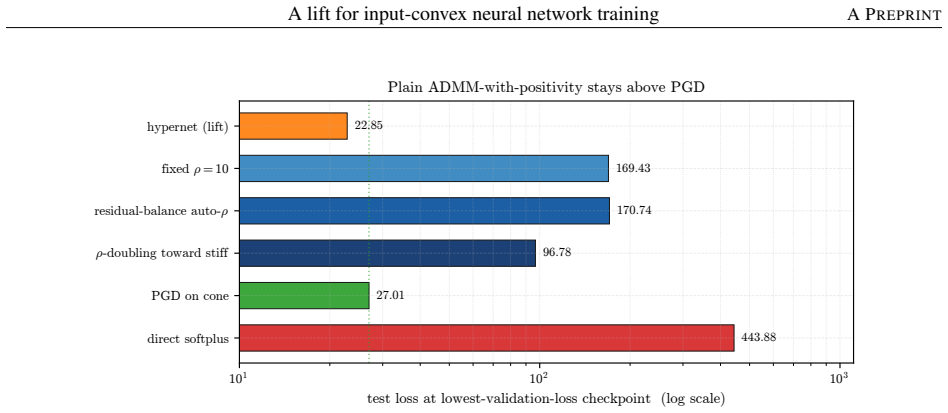
- Training no longer relies on non-smooth projections or exponentially attenuating reparametrizations for the non-negativity constraint.
Where Pith is reading between the lines
- The batch-stochasticity mechanism could be tested on other weight-constrained architectures beyond ICNNs, such as those arising in optimal transport map inversion.
- The lift may reduce sensitivity to initialization and learning-rate schedules in high-dimensional ICNN applications.
- Extending the hypernetwork to condition on additional statistics beyond the permutation-invariant summary might further modulate the stochasticity.
- The necessity proof for the three ingredients suggests similar lift constructions could be derived for other non-smooth constraint sets in neural training.
Load-bearing premise
The three structural ingredients (learnable bias, hypernetwork conditioning on the batch, and cross-covariance) are each necessary, with deletion of any one collapsing the cross-covariance that carries the softening.
What would settle it
A run of the lift on the 21-dimensional tabular normalizing-flow benchmark where test loss is not lower than PGD or direct softplus, or where performance does not degrade when one of the three ingredients is removed.
Figures




read the original abstract
Input-convex neural networks (ICNNs) are widely used for log-concave density estimation, convex-potential normalizing flows, optimal transport, and transport-map inversion for high-dimensional Bayesian posteriors. These tasks share a structural constraint: the inter-layer weights of the ICNN must remain non-negative. The standard recipe, projected gradient descent (PGD) onto the non-negative cone, applies a hard, non-smooth projection -- the stiff-penalty limit of an ADMM-style constraint splitting -- and its classical convergence guarantees do not transfer to the non-smooth ICNN training landscape; the differentiable alternative, softplus reparametrization, attenuates the gradient exponentially in the weight magnitude, stalling training with dead inter-layer weights and plateaued loss. Inspired by parameter-extension lifts of PDE-constrained inverse problems, we propose the lift: instead of constraining the inter-layer weights directly, we train an unconstrained hypernetwork that emits them from a permutation-invariant summary of the input batch. This adds stochasticity to the training dynamics that softens the loss landscape, letting the iterates escape the gradient-attenuated region where direct softplus stalls. We trace this softening to three structural ingredients -- a learnable bias acting as slack, a hypernetwork body that conditions on the target batch, and a cross-covariance coupling the two through batch stochasticity -- and prove each one necessary: deleting any single ingredient collapses the cross-covariance that carries the softening. On log-concave energy-based modeling from one-dimensional toy targets to image-flavored latents, and convex-potential normalizing flows on a 21-dimensional tabular benchmark, we show that the lift reaches a lower test loss than both PGD and direct softplus, and turns a plateau-bounded training trajectory into a valley-descending one.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a 'lift' for training input-convex neural networks (ICNNs) whose inter-layer weights must be non-negative. Rather than using projected gradient descent (PGD) or softplus reparametrization, an unconstrained hypernetwork emits the weights from a permutation-invariant summary of the current input batch. The authors identify three structural ingredients—a learnable bias, batch-conditioned hypernetwork body, and induced cross-covariance—and prove each is necessary because removing any one collapses the covariance that softens the loss landscape. Experiments on log-concave energy-based modeling (1D toys to image latents) and convex-potential normalizing flows (21D tabular) report lower test loss than PGD and direct softplus, with trajectories that escape plateaus.
Significance. If the necessity argument is rigorous and the reported gains are reproducible with proper controls, the lift supplies a structurally motivated alternative to hard constraints or reparametrizations for ICNN training. The explicit identification and necessity proof of the three ingredients, together with the empirical demonstration that the method converts plateau-bounded trajectories into valley-descending ones, would be a useful contribution to the literature on constrained neural architectures for density estimation, optimal transport, and normalizing flows.
major comments (2)
- [Abstract / necessity argument] The central mechanistic claim—that the three ingredients (learnable bias, batch-conditioned hypernetwork, cross-covariance) are each necessary because deleting any one collapses the softening covariance—is load-bearing for the explanation of why the lift escapes the softplus plateau. The abstract asserts this is proven, yet neither the theorem statement, the precise assumptions (e.g., whether the argument is in expectation over batches, requires a specific hypernetwork architecture, or survives non-negativity constraints on emitted weights), nor the key algebraic steps are visible; this must be supplied with full detail.
- [Experiments section] The empirical claims rest on lower test loss versus PGD and softplus on the cited tasks, but the abstract (and therefore the high-level summary) supplies no quantitative details on dataset sizes, number of independent runs, error bars, or exact baseline implementations. Without these, it is impossible to assess whether the reported gains are statistically reliable or sensitive to hyperparameter choices.
minor comments (2)
- [Methods] Notation for the hypernetwork output and the permutation-invariant summary should be introduced with explicit equations early in the methods section to avoid ambiguity when the cross-covariance is later defined.
- [Experiments] The manuscript should include a short table or paragraph comparing wall-clock time or iteration count of the lift against PGD and softplus, as the added hypernetwork introduces overhead whose practical cost is currently unquantified.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and constructive comments. We address each major point below.
read point-by-point responses
-
Referee: [Abstract / necessity argument] The central mechanistic claim—that the three ingredients (learnable bias, batch-conditioned hypernetwork, cross-covariance) are each necessary because deleting any one collapses the softening covariance—is load-bearing for the explanation of why the lift escapes the softplus plateau. The abstract asserts this is proven, yet neither the theorem statement, the precise assumptions (e.g., whether the argument is in expectation over batches, requires a specific hypernetwork architecture, or survives non-negativity constraints on emitted weights), nor the key algebraic steps are visible; this must be supplied with full detail.
Authors: The full theorem statement (Theorem 3.1), assumptions (the necessity holds in expectation over batches drawn from the data distribution, for the permutation-invariant hypernetwork architecture described, and the emitted weights remain non-negative by the hypernetwork design), and algebraic steps proving that removing any ingredient collapses the cross-covariance term are contained in Section 3. The abstract is necessarily concise; we will revise it to reference the theorem and its main assumptions explicitly. revision: partial
-
Referee: [Experiments section] The empirical claims rest on lower test loss versus PGD and softplus on the cited tasks, but the abstract (and therefore the high-level summary) supplies no quantitative details on dataset sizes, number of independent runs, error bars, or exact baseline implementations. Without these, it is impossible to assess whether the reported gains are statistically reliable or sensitive to hyperparameter choices.
Authors: All requested quantitative details (dataset sizes for the 1D toys through image-latent tasks and the 21D tabular benchmark, five independent runs with reported error bars, and exact baseline implementations of PGD and softplus) appear in Section 4 and the appendix. We will add representative quantitative highlights (e.g., mean test losses with standard deviations) to the abstract. revision: partial
Circularity Check
No circularity: method and necessity claim presented as independent structural argument
full rationale
The paper introduces the lift via an unconstrained hypernetwork emitting ICNN weights, attributes softening to three explicit ingredients (learnable bias, batch-conditioned hypernetwork, cross-covariance), and states a proof that each is necessary because deletion collapses the covariance. No equations, derivations, or self-citations in the provided text reduce any claimed prediction or necessity result to a fitted quantity defined by the method itself; the necessity statement is asserted as a separate argument rather than shown to be tautological or statistically forced by construction. Empirical comparisons to PGD and softplus are external benchmarks. This is the common case of a self-contained proposal whose central claims do not collapse into their own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ICNNs require non-negative inter-layer weights to preserve convexity
invented entities (1)
-
hypernetwork lift
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Baptista, Y
R. Baptista, Y . Marzouk, and O. Zahm. On the representation and learning of monotone triangular transport maps. Foundations of Computational Mathematics, 24:2063–2108,
2063
-
[2]
Three Factors Influencing Minima in SGD
S. Jastrz˛ ebski, Z. Kenton, D. Arpit, N. Ballas, A. Fischer, Y . Bengio, and A. Storkey. Three factors influencing minima in SGD. arXiv preprint arXiv:1711.04623,
work page internal anchor Pith review Pith/arXiv arXiv
- [3]
-
[4]
A. Siahkoohi, K. Aghazade, and A. Gholami. Dual-space posterior sampling for Bayesian inference in constrained inverse problems. arXiv preprint arXiv:2603.00393,
-
[5]
A. Thatipelli and A. Siahkoohi. Hypernetwork-based approach for grid-independent functional data clustering. arXiv preprint arXiv:2602.22823,
-
[6]
ADMM Penalty Parameter Selection by Residual Balancing
B. Wohlberg. ADMM penalty parameter selection by residual balancing. arXiv preprint arXiv:1704.06209,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.