When Does Synthetic Patent Data Help? Volume-Fidelity Trade-offs in Low-Resource Multi-Label Classification
Pith reviewed 2026-06-30 15:15 UTC · model grok-4.3
The pith
Synthetic patent data gains in multi-label classification mostly reflect added volume rather than higher fidelity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
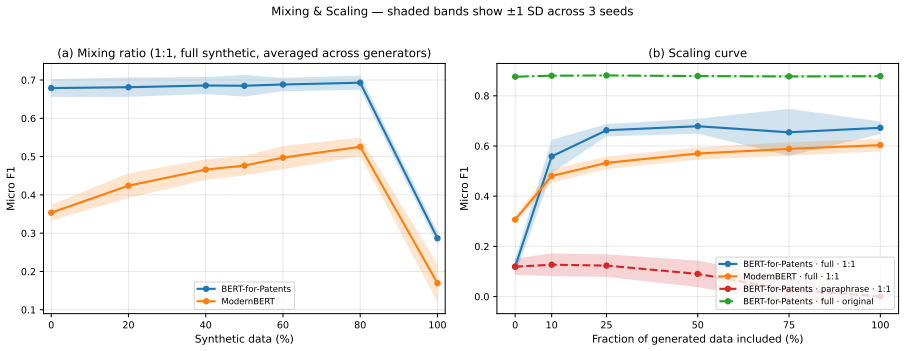
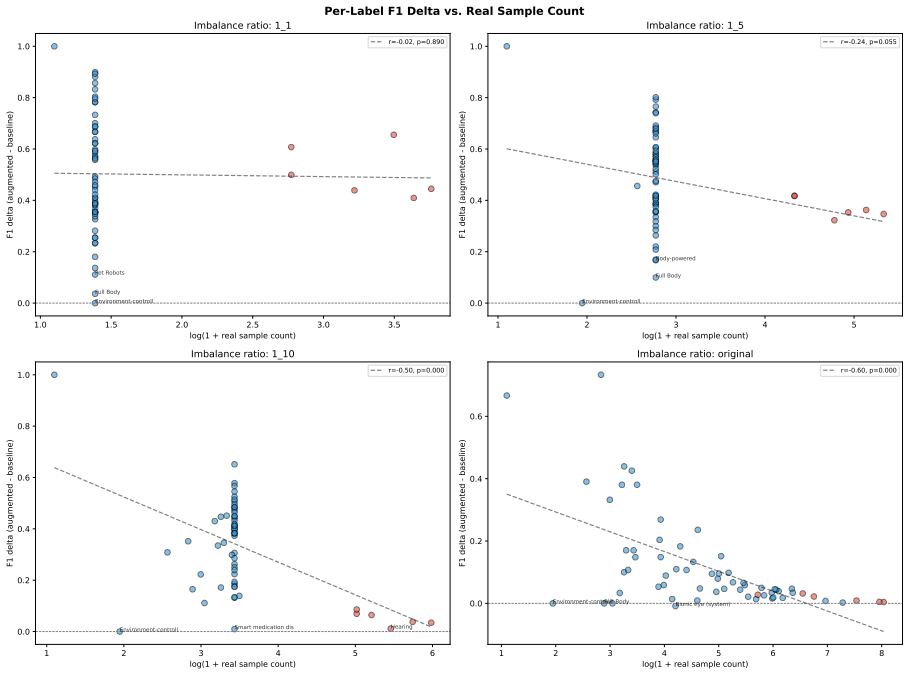
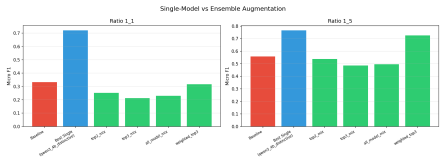
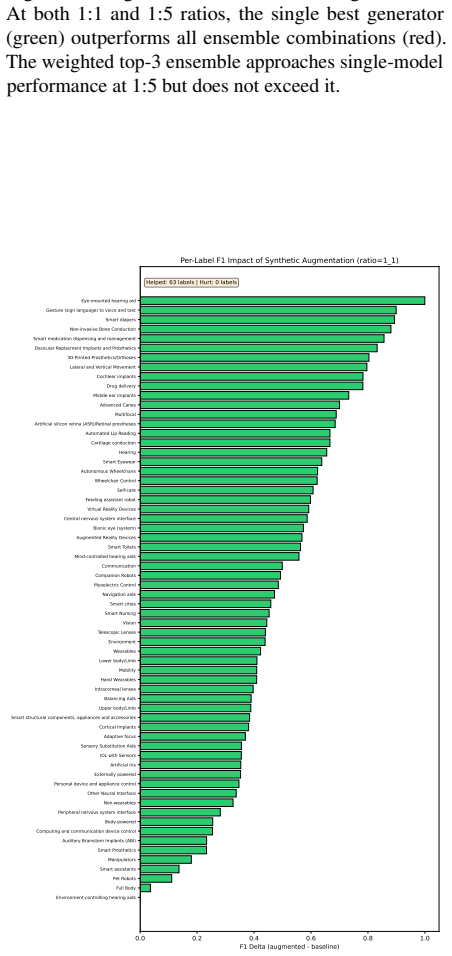
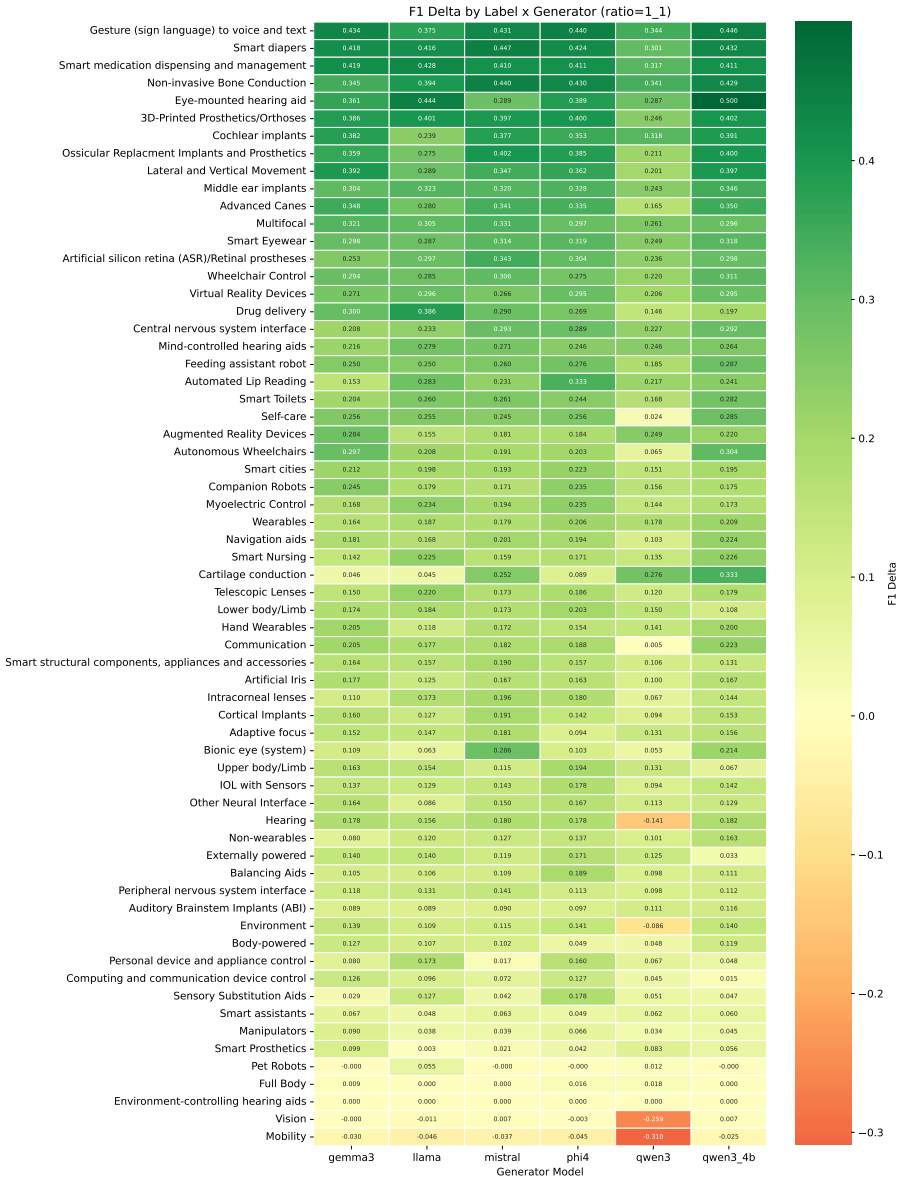
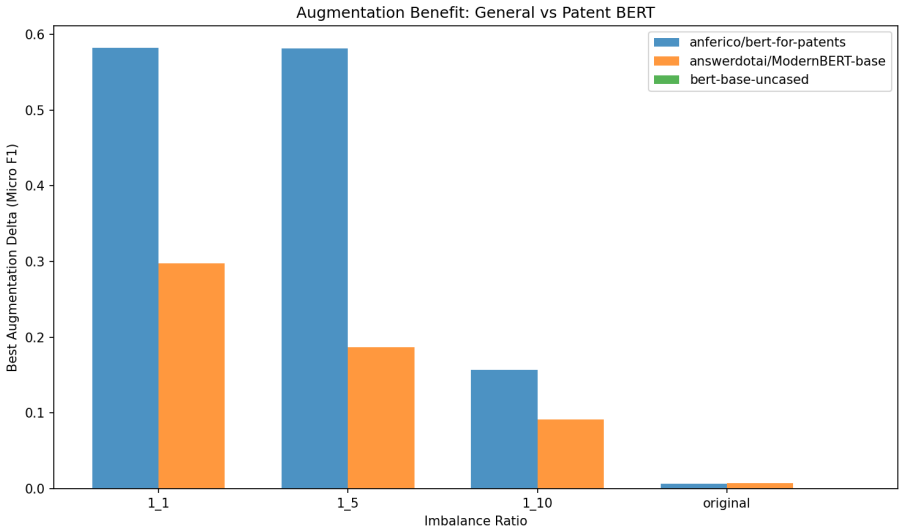
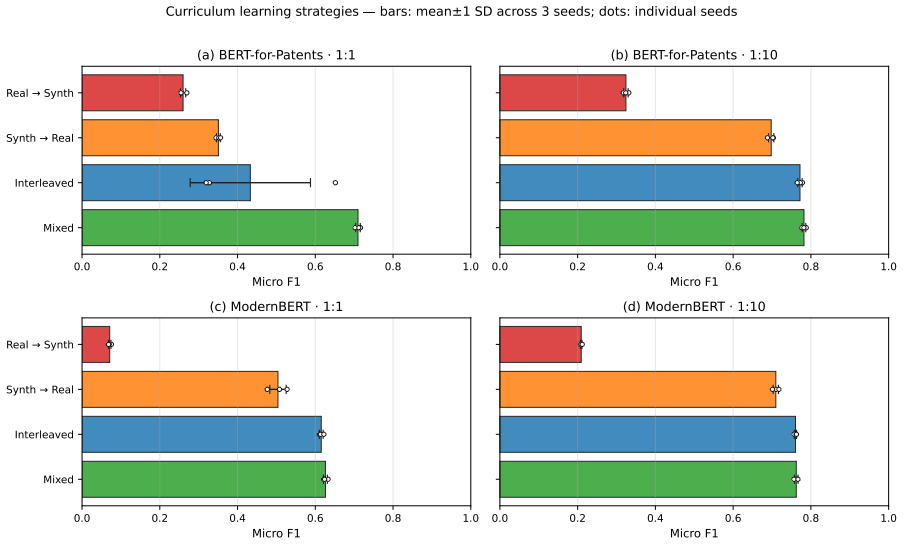
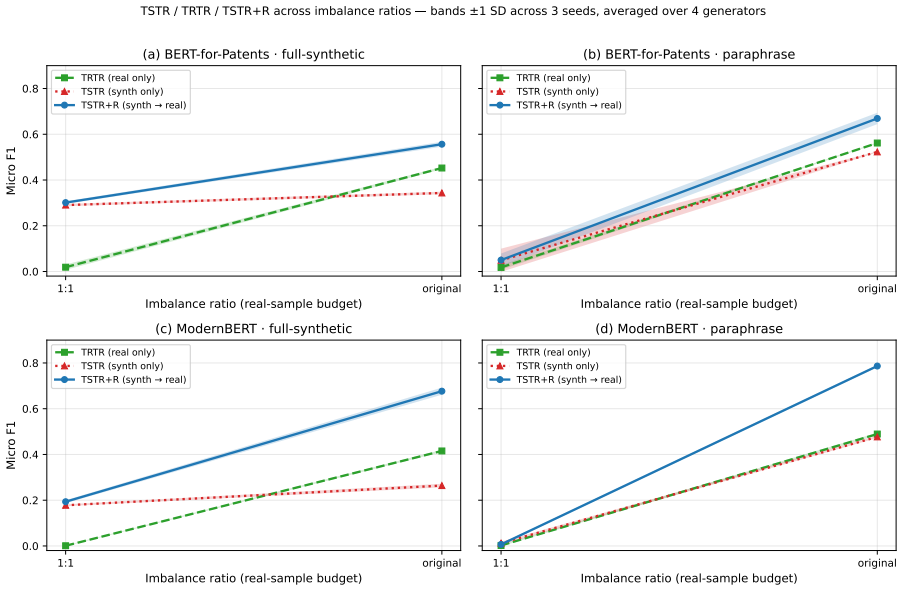
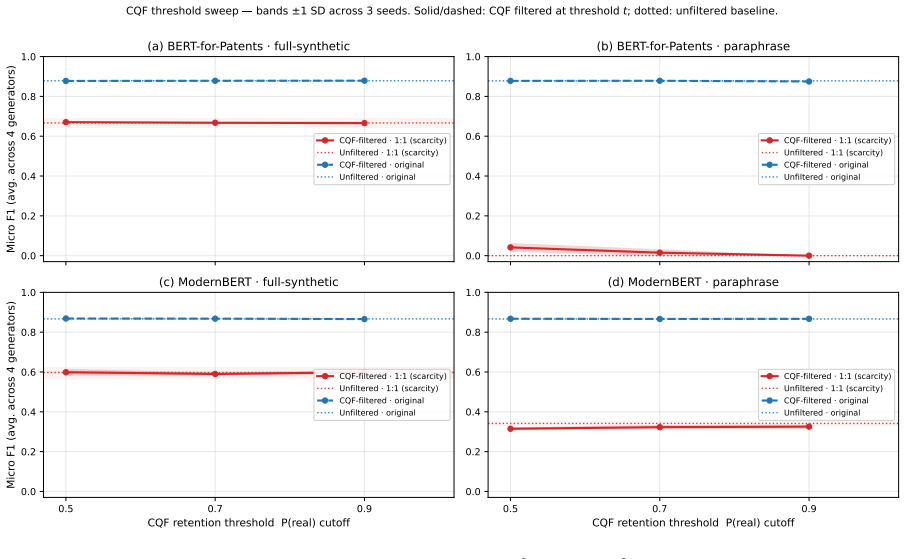
The central claim is that volume effects dominate the benefit of synthetic patent data in low-resource multi-label settings. Replication with replacement on the smallest real set nearly reproduces the performance of LLM-generated examples, while the correlation between maximum mean discrepancy and micro F1 flips from r = +0.95 in the lowest-data regime to r = -0.73 in the 1:10 regime. Under a fixed total budget the best strategy is a 20-30 % real / 70-80 % synthetic mix, although the same synthetic corpus that raises classification scores can lower a Jaccard-overlap retrieval proxy.
What carries the argument
The replication-with-replacement baseline on the 165-example set that isolates the pure volume contribution, together with the sign change in the MMD-performance correlation across real-data regimes.
If this is right
- In the lowest real-data regimes, added volume accounts for nearly all observed gains from synthetic examples.
- Once more real data is available, fidelity measured by MMD becomes the dominant factor and can correlate negatively with gains.
- A fixed total budget is best spent on a majority-synthetic mixture containing 20-30 % real examples.
- Synthetic data that improves classification can simultaneously degrade a Jaccard-overlap retrieval metric.
- Both full-synthesis and paraphrasing generation methods exhibit the same volume-fidelity trade-off pattern.
Where Pith is reading between the lines
- The volume-dominance pattern may appear in other low-resource text-classification domains that use label-conditioned generation.
- The reversal in MMD-performance correlation could be tested by varying real-data size in non-patent multi-label tasks.
- Retrieval metrics may need to be evaluated separately when deploying synthetic data, because classification gains do not guarantee retrieval gains.
- Prompt-family differences across document genres might explain why the standard patent filter reduces nDCG@10.
Load-bearing premise
That duplicating the 165 real examples with replacement produces the same distributional effect as adding LLM-generated synthetic examples without introducing new biases.
What would settle it
Repeating the replication-with-replacement test on a fresh patent-classification dataset and finding that the duplicated real data still falls well short of the synthetic-data performance would falsify the volume-dominance account.
Figures
read the original abstract
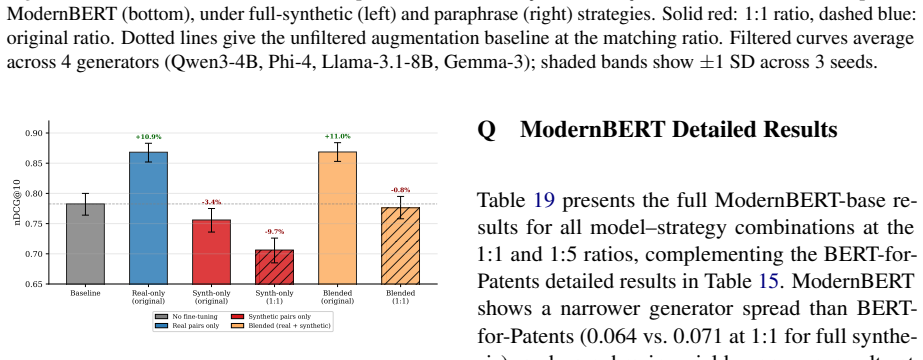
The issues that must be considered regarding the utilization of synthetic data generated through LLMs for multilabel patent classification include (i) when the use of such data may help and (ii) why. Indeed, the former part appropriately adjusts for the possibility of improving results by an increase in sample size. The current experiment involves six open-source LLMs (from 3.8B to 12B parameters) for four real-data regimes in classification of 64 WIPO labels of assistive technologies. Both full-synthesis generation, conditioned on the label set, and paraphrasing methods are applied, with each used in combination with three classifier categories. It is shown that the claimed improvements in micro F1 for BERT-for-Patents from 0.120 to 0.702 mainly reflect a volume effect; indeed, replication with replacement in 165 examples produces 0.678. Thus, the improvement over the control is +0.024, while compared to the best baseline (focal loss reweighting) is +0.219. The second crucial point to consider here is that of evolving fidelity scores as the data generation regime varies. For low real-data regimes, the volume effect dominates and the correlation coefficient between maximum mean discrepancy (MMD) and classification performance equals r = +0.95. As more real data is used, the correlation becomes inverted and reaches r = -0.73 at the 1:10 regime (Fisher z = +6.47, p < 0.001, 95% CI on Delta r [ +0.96, +1.00 ]). In terms of a fixed budget allocation, combining real data (about 20-30%) with synthetic (70-80%) outperforms both purely synthetic and purely real strategies. Moreover, a corpus that allows for improvement in classification performance up to +0.58 in raw micro F1 may adversely affect a Jaccard-overlap retrieval proxy. Prompt-family variations for other genres may provide some explanation of the phenomenon, but using the standard-patent filter still decreases nDCG@10 by 26%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates when and why LLM-generated synthetic data improves low-resource multi-label patent classification (64 WIPO labels for assistive technologies). It reports that micro-F1 gains for BERT-for-Patents (0.120 to 0.702) largely reflect volume rather than fidelity, since replication with replacement on 165 real examples reaches 0.678 (+0.024 over control, +0.219 over focal-loss baseline). It further shows regime-dependent MMD-performance correlations (r=+0.95 in low-data regimes inverting to r=-0.73 at 1:10, Fisher z=+6.47, p<0.001) and recommends hybrid budgets (20-30% real + 70-80% synthetic).
Significance. If the volume-effect and correlation-inversion results hold after strengthening controls, the work supplies concrete empirical guidance on synthetic-data allocation for imbalanced multi-label tasks and identifies practical hybrid strategies that outperform pure real or pure synthetic regimes.
major comments (2)
- [Abstract] Abstract: the central claim that gains 'mainly reflect a volume effect' rests on the +0.024 gap between full-synthesis (0.702) and replication-with-replacement (0.678). Because synthetic generation is explicitly conditioned on the 64-label set while replication is not, the two training distributions can differ in label co-occurrence frequencies; this mismatch means the gap cannot yet be attributed solely to volume.
- [Abstract] Abstract: the reported MMD-performance correlation inversion (r=+0.95 to r=-0.73) is load-bearing for the volume-fidelity trade-off argument. The manuscript must specify how MMD is computed on multi-label data, whether it is evaluated on the joint label distribution, and whether the replication baseline was also subjected to the same MMD measurement.
minor comments (2)
- [Abstract] Exact prompt templates, full experimental protocols, and per-regime dataset sizes are not supplied, limiting reproducibility of the six-LLM, three-classifier, four-regime design.
- The Jaccard-overlap retrieval proxy result (nDCG@10 drop of 26%) is mentioned only briefly; a short table or figure showing the proxy versus classification metric across regimes would clarify the trade-off.
Simulated Author's Rebuttal
We thank the referee for these constructive comments. We address each major point below and will revise the manuscript accordingly to strengthen the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that gains 'mainly reflect a volume effect' rests on the +0.024 gap between full-synthesis (0.702) and replication-with-replacement (0.678). Because synthetic generation is explicitly conditioned on the 64-label set while replication is not, the two training distributions can differ in label co-occurrence frequencies; this mismatch means the gap cannot yet be attributed solely to volume.
Authors: We acknowledge the potential mismatch in label co-occurrence frequencies. Replication with replacement draws directly from the empirical distribution of the 165 real examples and therefore preserves the original joint label statistics exactly. Synthetic generation is conditioned on the observed label vectors but produced via LLM prompting, which can alter co-occurrence patterns. The small +0.024 gap is consistent with volume being the primary driver, yet we agree the attribution would be stronger with explicit controls. In revision we will add a comparison of pairwise label co-occurrence matrices (and selected higher-order statistics) between the replicated and synthetic sets, plus an additional baseline that matches both marginals and co-occurrences where feasible. revision: yes
-
Referee: [Abstract] Abstract: the reported MMD-performance correlation inversion (r=+0.95 to r=-0.73) is load-bearing for the volume-fidelity trade-off argument. The manuscript must specify how MMD is computed on multi-label data, whether it is evaluated on the joint label distribution, and whether the replication baseline was also subjected to the same MMD measurement.
Authors: We will expand the Methods section with the requested details. Each instance is represented as a 64-dimensional binary vector of label presence; MMD is then computed with a Gaussian kernel on these vectors, directly capturing the joint label distribution. The identical procedure was applied to the replication-with-replacement baseline to ensure comparability. Revised text will include the kernel bandwidth selection, explicit confirmation that replication was measured under the same metric, and tabulated MMD values for all conditions. revision: yes
Circularity Check
Empirical experimental study with no circular derivations
full rationale
The paper reports experimental results on synthetic data augmentation for multi-label patent classification, comparing micro-F1 scores across real-data regimes, full-synthesis, paraphrasing, and a replication-with-replacement baseline. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text; all claims rest on direct empirical contrasts (e.g., 0.702 vs. 0.678 micro-F1) rather than any self-referential reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Maximum mean discrepancy (MMD) is a suitable proxy for data fidelity relevant to downstream classification performance
- domain assumption Replication with replacement on the small real set provides an unbiased control for volume effects
Reference graph
Works this paper leans on
-
[1]
Zilong Bai, Ruiji Zhang, Linqing Chen, Qijun Cai, Yuan Zhong, Cong Wang, Yan Fang, Jie Fang, Jing Sun, Weikuan Wang, Lizhi Zhou, Haoran Hua, Tian Qiu, Chaochao Wang, Cheng Sun, Jianping Lu, Yixin Wang, Yubin Xia, Meng Hu, and 8 others. 2024. https://arxiv.org/abs/2404.18255 PatentGPT : A large language model for intellectual property . Preprint, arXiv:2404.18255
-
[2]
Hamid Bekamiri, Daniel S. Hain, and Roman Jurowetzki. 2024. https://doi.org/10.1016/j.techfore.2024.123536 PatentSBERTa : A deep NLP based hybrid model for patent distance and classification using augmented SBERT . Technological Forecasting and Social Change, 206:123536
-
[3]
Jan Cegin, Jakub Simko, and Peter Brusilovsky. 2025. https://aclanthology.org/2025.naacl-long.526/ LLMs vs established text augmentation techniques for classification: When do the benefits outweigh the costs? In Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics. Association for Computational ...
2025
-
[4]
Yin Cui, Menglin Jia, Tsung-Yi Lin, Yang Song, and Serge Belongie. 2019. https://openaccess.thecvf.com/content_CVPR_2019/html/Cui_Class-Balanced_Loss_Based_on_Effective_Number_of_Samples_CVPR_2019_paper.html Class-balanced loss based on effective number of samples . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR...
2019
-
[5]
Haixing Dai, Zhengliang Liu, Wenxiong Liao, Xiaoke Huang, Yihan Cao, Zihao Wu, Lin Zhao, Shaochen Xu, Wei Liu, Ninghao Liu, Sheng Li, Dajiang Zhu, Hongmin Cai, Lichao Sun, Quanzheng Li, Dinggang Shen, Tianming Liu, and Xiang Li. 2023. https://arxiv.org/abs/2302.13007 AugGPT : Leveraging ChatGPT for text data augmentation . Preprint, arXiv:2302.13007
-
[6]
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. https://arxiv.org/abs/2305.14314 QLoRA : Efficient finetuning of quantized LLMs . In Advances in Neural Information Processing Systems 36 (NeurIPS 2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Bosheng Ding, Chengwei Qin, Ruochen Zhao, Tianze Luo, Xinze Li, Guizhen Chen, Wenhan Xia, Junjie Hu, Anh Tuan Luu, and Shafiq Joty. 2024. https://aclanthology.org/2024.findings-acl.97/ Data augmentation using LLMs : Data perspectives, learning paradigms and challenges . In Findings of the Association for Computational Linguistics: ACL 2024. Association fo...
2024
-
[8]
Jacobus du Toit and Marcel Dunaiski. 2024. https://huggingface.co/datasets/marcelsun/wos_hierarchical_multi_label_text_classification WOS-CT : Hierarchical multi-label classification of web of science citation topics . HuggingFace dataset
2024
-
[9]
Rose, Sebastian Erhardt, Erik Buunk, and Dietmar Harhoff
Mainak Ghosh, Michael E. Rose, Sebastian Erhardt, Erik Buunk, and Dietmar Harhoff. 2024. https://arxiv.org/abs/2402.19411 PaECTER : Patent-level representation learning using citation-informed transformers . Preprint, arXiv:2402.19411
- [10]
-
[11]
Borgwardt, Malte J
Arthur Gretton, Karsten M. Borgwardt, Malte J. Rasch, Bernhard Sch \"o lkopf, and Alexander J. Smola. 2012. https://jmlr.org/papers/v13/gretton12a.html A kernel two-sample test . Journal of Machine Learning Research, 13:723--773
2012
-
[12]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. 2017. https://proceedings.neurips.cc/paper/2017/hash/8a1d694707eb0fefe65871369074926d-Abstract.html GANs trained by a two time-scale update rule converge to a local Nash equilibrium . In Advances in Neural Information Processing Systems 30 (NeurIPS 2017)
2017
-
[13]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. https://openreview.net/forum?id=nZeVKeeFYf9 LoRA : Low-rank adaptation of large language models . In The Tenth International Conference on Learning Representations (ICLR)
2022
-
[14]
Jinhee Kim, Taesung Kim, and Jaegul Choo. 2024. https://openreview.net/forum?id=d5cKDHCrFJ EPIC : Effective prompting for imbalanced-class data synthesis in tabular data classification via large language models . In Advances in Neural Information Processing Systems 37 (NeurIPS 2024)
2024
-
[15]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. https://doi.org/10.1145/3600006.3613165 Efficient memory management for large language model serving with PagedAttention . In Proceedings of the 29th Symposium on Operating Systems Principles (SOSP)
-
[16]
Mahoney, Kurt Keutzer, and Amir Gholami
Nicholas Lee, Thanakul Wattanawong, Sehoon Kim, Karttikeya Mangalam, Sheng Shen, Gopala Anumanchipalli, Michael W. Mahoney, Kurt Keutzer, and Amir Gholami. 2024. https://aclanthology.org/2024.findings-acl.388/ LLM2LLM : Boosting LLMs with novel iterative data enhancement . In Findings of the Association for Computational Linguistics: ACL 2024. Association...
2024
-
[17]
Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and Bill Dolan. 2016. https://aclanthology.org/N16-1014/ A diversity-promoting objective function for neural conversation models . In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computat...
2016
-
[18]
Zhuoyan Li, Hangxiao Zhu, Zhuoran Lu, and Ming Yin. 2023. https://aclanthology.org/2023.emnlp-main.647/ Synthetic data generation with large language models for text classification: Potential and limitations . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics
2023
-
[19]
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll \'a r. 2017. https://openaccess.thecvf.com/content_iccv_2017/html/Lin_Focal_Loss_for_ICCV_2017_paper.html Focal loss for dense object detection . In Proceedings of the IEEE International Conference on Computer Vision (ICCV)
2017
-
[20]
Lin Long, Rui Wang, Ruixuan Xiao, Junbo Zhao, Xiao Ding, Gang Chen, and Haobo Wang. 2024. https://aclanthology.org/2024.findings-acl.658/ On LLMs -driven synthetic data generation, curation, and evaluation: A survey . In Findings of the Association for Computational Linguistics: ACL 2024. Association for Computational Linguistics
2024
-
[21]
Anders Giovanni M ller, Arianna Pera, Jacob Dalsgaard, and Luca Aiello. 2024. https://aclanthology.org/2024.eacl-short.17/ The parrot dilemma: Human-labeled vs. LLM -augmented data in classification tasks . In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 2: Short Papers). Association f...
2024
-
[22]
No Language Left Behind: Scaling Human-Centered Machine Translation
NLLB Team , Marta R. Costa-juss \`a , James Cross, and 1 others. 2022. https://arxiv.org/abs/2207.04672 No language left behind: Scaling human-centered machine translation . Preprint, arXiv:2207.04672
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Krishna Pillutla, Swabha Swayamdipta, Rowan Zellers, John Thickstun, Sean Welleck, Yejin Choi, and Zaid Harchaoui. 2021. https://proceedings.neurips.cc/paper/2021/hash/260c2432a0eecc28ce03c10dadc078a4-Abstract.html MAUVE : Measuring the gap between neural text and human text using divergence frontiers . In Advances in Neural Information Processing Systems...
2021
-
[24]
Bjarnad \'o ttir, and Anjalie Field
Krithika Ramesh, Daniel Smolyak, Zihao Zhao, Nupoor Gandhi, Ritu Agarwal, Margr \'e t V. Bjarnad \'o ttir, and Anjalie Field. 2025. https://aclanthology.org/2025.emnlp-demos.35/ SynthTextEval : Synthetic text data generation and evaluation for high-stakes domains . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: ...
2025
-
[25]
Tal Ridnik, Emanuel Ben-Baruch, Nadav Zamir, Asaf Noy, Itamar Friedman, Matan Protter, and Lihi Zelnik-Manor. 2021. https://openaccess.thecvf.com/content/ICCV2021/html/Ridnik_Asymmetric_Loss_for_Multi-Label_Classification_ICCV_2021_paper.html Asymmetric loss for multi-label classification . In Proceedings of the IEEE/CVF International Conference on Comput...
2021
-
[26]
Gaurav Sahu, Olga Vechtomova, Dzmitry Bahdanau, and Issam Laradji. 2023. https://aclanthology.org/2023.emnlp-main.323/ PromptMix : A class boundary augmentation method for large language model distillation . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics
2023
-
[27]
Rob Srebrovic and Jay Yonamine. 2020. https://services.google.com/fh/files/blogs/bert_for_patents_white_paper.pdf Leveraging the BERT algorithm for patents with TensorFlow and BigQuery . White paper, Google
2020
-
[28]
Le, Ed H
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. https://openreview.net/forum?id=1PL1NIMMrw Self-consistency improves chain of thought reasoning in language models . In The Eleventh International Conference on Learning Representations (ICLR)
2023
-
[29]
Benjamin Warner, Antoine Chaffin, Benjamin Clavi \'e , Orion Weller, Oskar Hallstr \"o m, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal Ladhak, Tom Aarsen, Nathan Cooper, Griffin Adams, Jeremy Howard, and Iacopo Poli. 2024. https://arxiv.org/abs/2412.13663 Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Jason Wei and Kai Zou. 2019. https://aclanthology.org/D19-1670/ EDA : Easy data augmentation techniques for boosting performance on text classification tasks . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Association for C...
2019
-
[31]
Tong Wu, Qingqiu Huang, Ziwei Liu, Yu Wang, and Dahua Lin. 2020. https://link.springer.com/chapter/10.1007/978-3-030-58548-8_10 Distribution-balanced loss for multi-label classification in long-tailed datasets . In Proceedings of the European Conference on Computer Vision (ECCV), pages 162--178
-
[32]
Pengcheng Yang, Xu Sun, Wei Li, Shuming Ma, Wei Wu, and Houfeng Wang. 2018. https://aclanthology.org/C18-1330/ SGM : Sequence generation model for multi-label classification . In Proceedings of the 27th International Conference on Computational Linguistics (COLING), pages 3915--3926
2018
-
[33]
Amirhossein Yousefiramandi and 1 others. 2025. https://arxiv.org/abs/2512.12677 Fine-tuning causal LLMs for text classification: Embedding-based vs. instruction-based approaches . Preprint, arXiv:2512.12677
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. 2025. https://arxiv.org/abs/2506.05176 Qwen3 embedding: Advancing text embedding and reranking through foundation models . Preprint, arXiv:2506.05176
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Yaoming Zhu, Sidi Lu, Lei Zheng, Jiaxian Guo, Weinan Zhang, Jun Wang, and Yong Yu. 2018. https://doi.org/10.1145/3209978.3210080 Texygen : A benchmarking platform for text generation models . In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval (SIGIR)
-
[36]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[37]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.