CoDA: Color Distribution Probing for Efficient and Generalizable AI-Generated Image Detection
Pith reviewed 2026-06-30 14:20 UTC · model grok-4.3
The pith
A compact detector using noise-quantization on color distributions detects AI-generated images efficiently and generalizes across domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
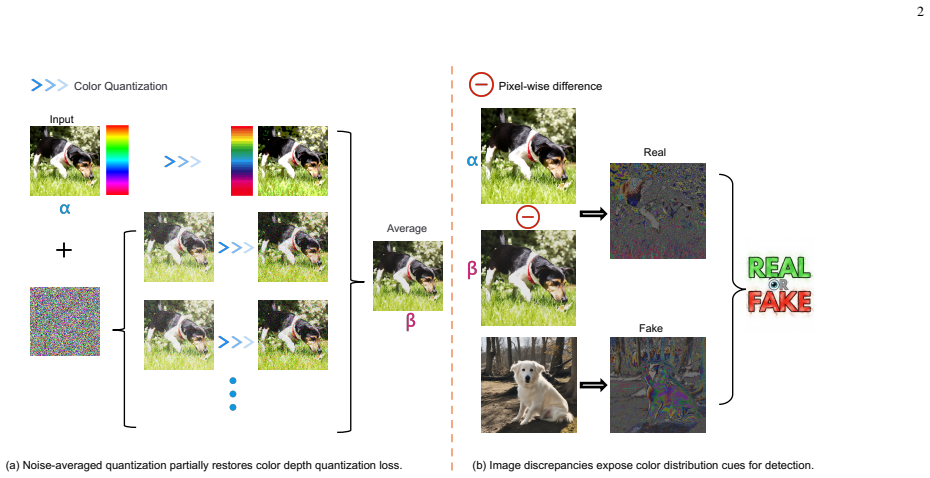
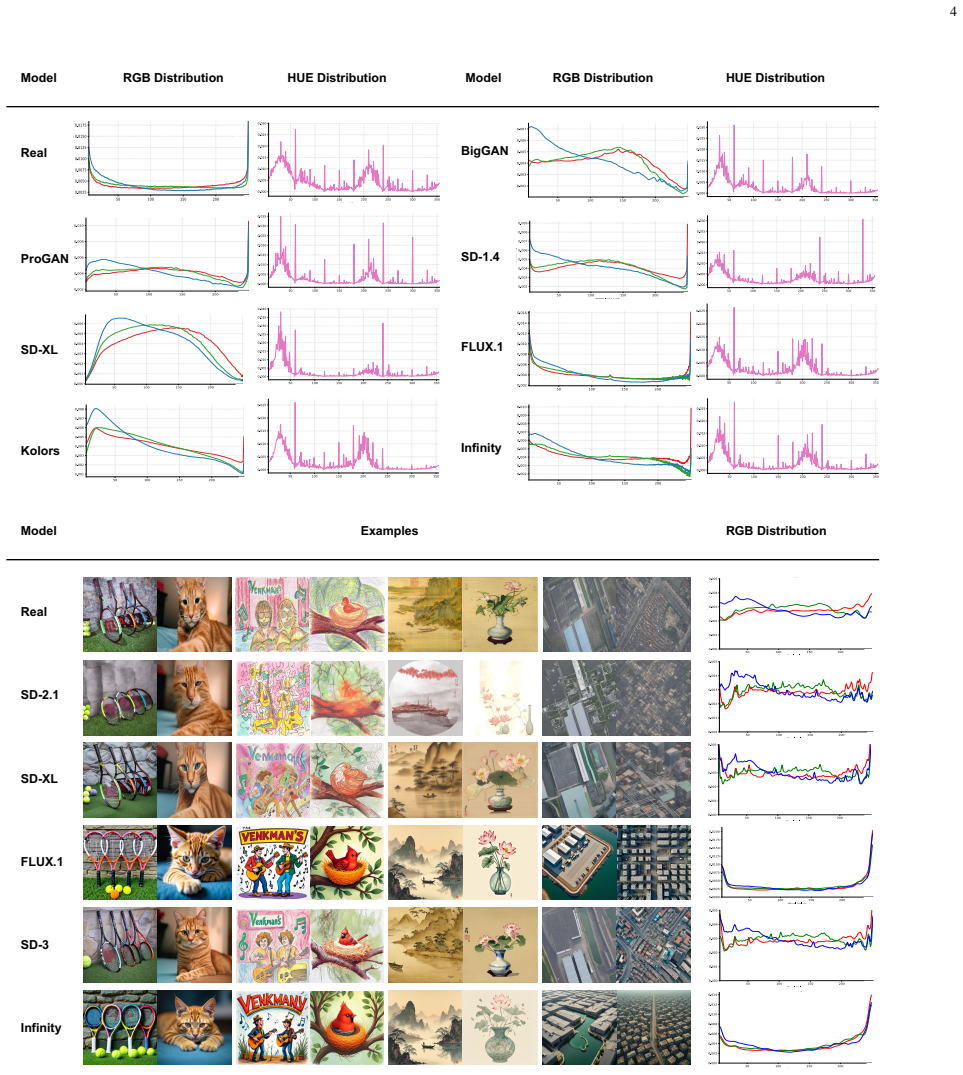
We propose CoDA, a compact detector built on a Noise-Quantization Probe that quantifies color non-uniformity. Real photographs tend to exhibit smoother and more stable color patterns, whereas synthetic images display characteristic imbalances introduced by neural generation; the probe responses are shown to track this non-uniformity. On standard benchmarks CoDA reaches state-of-the-art performance; on the new FakeForm benchmark of approximately 370,000 images across 62 domains it records the strongest cross-domain results while remaining highly competitive in cross-model photorealistic settings.
What carries the argument
The Noise-Quantization Probe, which extracts responses directly linked to color non-uniformity.
If this is right
- Persistent color imbalances from neural generators provide a practical foundation for efficient detection without large-scale models.
- Cross-domain evaluation on FakeForm reveals robustness gaps that cross-model photorealistic tests alone do not expose.
- A 1.48M-parameter detector can match or exceed larger models on challenging generalization tasks.
- Making the probe responses and the 370k-image benchmark public enables direct comparison and further refinement of color-based cues.
Where Pith is reading between the lines
- Color-distribution probing could be combined with existing artifact detectors to improve ensemble robustness without increasing parameter count substantially.
- The same non-uniformity signal may appear in other media such as video frames or 3D renders where generation pipelines also affect color stability.
- If the probe can be further compressed while preserving its link to color non-uniformity, even smaller on-device detectors become feasible.
Load-bearing premise
Real photographs tend to exhibit smoother and more stable color patterns whereas synthetic images often show characteristic color imbalances introduced by neural generation.
What would settle it
A collection of photorealistic AI-generated images whose color-distribution statistics match those of real photographs as closely as real photographs match one another.
Figures



read the original abstract
AI-generated image detection faces a persistent trade-off between generalization and efficiency: lightweight artifact-based methods often degrade on unseen generators or domains, whereas more robust large-scale models are computationally expensive. Meanwhile, existing benchmarks mainly focus on cross-model evaluation in photorealistic settings, leaving cross-domain robustness underexplored. To address this gap, we introduce FakeForm, a large-scale benchmark with approximately 370,000 images across 62 diverse domains for both cross-model and cross-domain evaluation. Motivated by this broader setting, we revisit color-distribution probing as an efficient complementary cue for AI-generated image detection. We observe that, especially for photographic content, real photographs tend to exhibit smoother and more stable color patterns, whereas synthetic images often show characteristic color imbalances introduced by neural generation. Based on this observation, we propose CoDA, a compact 1.48M-parameter detector built on a Noise-Quantization Probe, together with a theoretical analysis linking probe responses to color non-uniformity. Experiments show that CoDA achieves state-of-the-art performance on standard benchmarks and the best results on the challenging cross-domain evaluation of FakeForm, while remaining highly competitive in cross-model photorealistic settings. These results suggest that persistent generative artifacts can provide a practical foundation for efficient and robust AI-generated image detection. The models and FakeForm benchmark will be made publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FakeForm, a benchmark of ~370k images across 62 domains for cross-model and cross-domain AI-generated image detection evaluation. Motivated by observed differences in color pattern stability between real photographs and neural-generated images, it proposes CoDA: a 1.48M-parameter detector using a Noise-Quantization Probe, accompanied by a theoretical analysis linking probe responses to color non-uniformity. Experiments claim SOTA results on standard benchmarks, best cross-domain performance on FakeForm, and competitive cross-model photorealistic results, with public release of models and benchmark planned.
Significance. If the reported performance and generalization hold under scrutiny, CoDA demonstrates that lightweight color-distribution cues can deliver efficient, robust detection without relying on large-scale models, directly addressing the efficiency-generalization trade-off. The scale and diversity of FakeForm would provide a valuable new resource for the community to evaluate cross-domain robustness, which prior benchmarks have largely overlooked.
major comments (2)
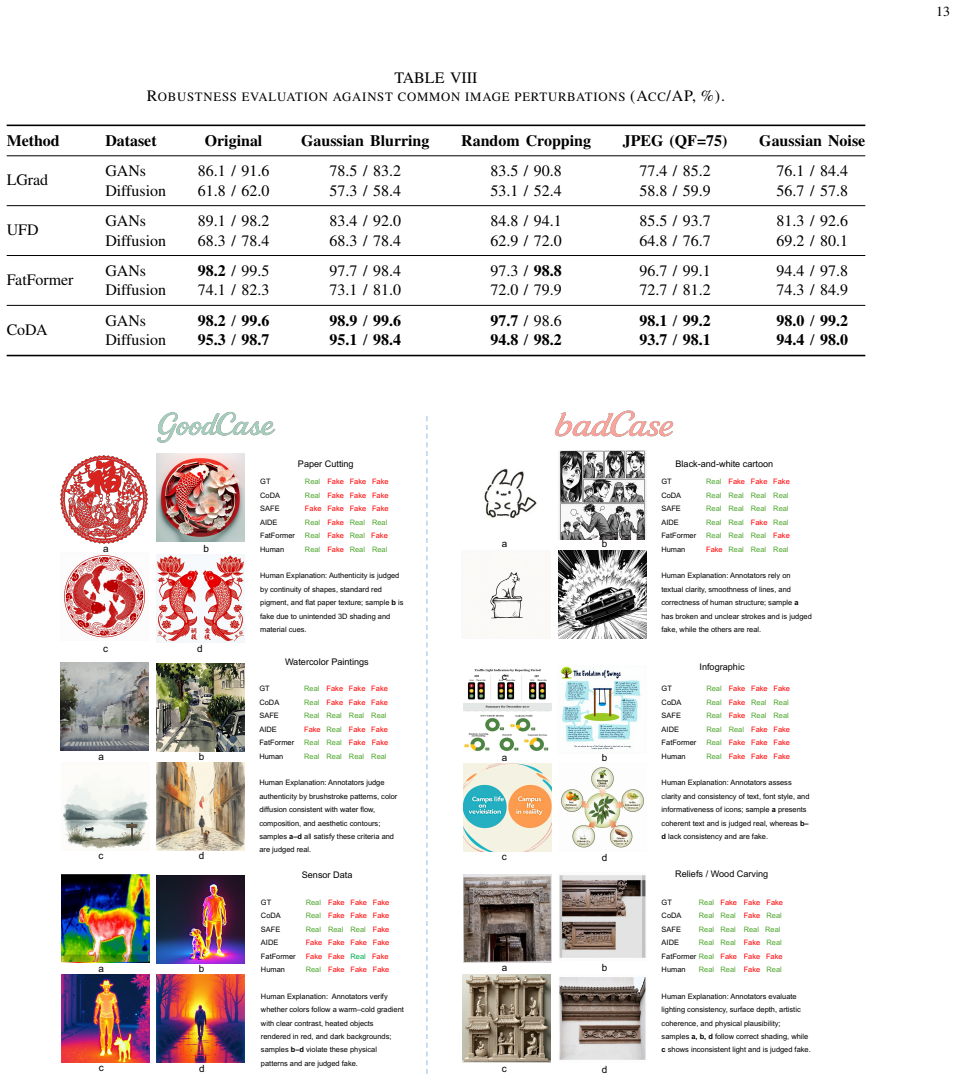
- [§4] §4 (Experiments): the claim of state-of-the-art performance on standard benchmarks and best cross-domain results on FakeForm is presented without error bars, multiple random seeds, or statistical significance tests against the strongest baselines; this makes it impossible to determine whether the reported margins are reliable or could be explained by variance.
- [§3.2] §3.2 (Noise-Quantization Probe and theoretical analysis): the link between probe responses and observable color non-uniformity is asserted but the manuscript supplies no derivation steps, assumptions, or closed-form relation; without these, it is unclear whether the theoretical analysis adds predictive power beyond the empirical observation stated in the abstract.
minor comments (2)
- The abstract and introduction refer to "standard benchmarks" without enumerating them; the experiments section should explicitly list the datasets, generators, and protocols used for the cross-model comparisons.
- Table captions and axis labels in the result figures should include the exact number of images/domains per split to allow direct comparison with FakeForm's 370k/62-domain scale.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the experimental reporting and clarify the theoretical analysis.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): the claim of state-of-the-art performance on standard benchmarks and best cross-domain results on FakeForm is presented without error bars, multiple random seeds, or statistical significance tests against the strongest baselines; this makes it impossible to determine whether the reported margins are reliable or could be explained by variance.
Authors: We agree that the lack of error bars, multiple random seeds, and statistical significance tests makes it difficult to assess the reliability of the performance margins. In the revised manuscript, we will rerun key experiments across multiple random seeds, report means with standard deviations as error bars, and include statistical significance tests (such as paired t-tests) comparing CoDA against the strongest baselines on both standard benchmarks and FakeForm. revision: yes
-
Referee: [§3.2] §3.2 (Noise-Quantization Probe and theoretical analysis): the link between probe responses and observable color non-uniformity is asserted but the manuscript supplies no derivation steps, assumptions, or closed-form relation; without these, it is unclear whether the theoretical analysis adds predictive power beyond the empirical observation stated in the abstract.
Authors: We acknowledge that Section 3.2 asserts the connection between probe responses and color non-uniformity without providing explicit derivation steps, assumptions, or a closed-form relation. In the revision, we will expand the theoretical analysis to include the full derivation, list all assumptions clearly, and present the closed-form relation, thereby demonstrating how the analysis provides predictive insight beyond the empirical observations in the abstract. revision: yes
Circularity Check
No significant circularity; derivation is observation-driven and externally benchmarked
full rationale
The paper's central claim rests on an empirical observation about color stability in real vs. synthetic photographs, followed by introduction of a Noise-Quantization Probe whose responses are linked via stated theoretical analysis to measurable color non-uniformity. No equations, fitted parameters, or self-citations are shown that reduce the reported performance metrics or the probe definition to the inputs by construction. The cross-domain results on the newly introduced FakeForm benchmark (370k images, 62 domains) and standard benchmarks are presented as independent experimental outcomes rather than tautological predictions. The method is described as compact (1.48M parameters) and motivated by observable properties, with no load-bearing self-referential steps visible in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real photographs tend to exhibit smoother and more stable color patterns, whereas synthetic images often show characteristic color imbalances introduced by neural generation.
Reference graph
Works this paper leans on
-
[1]
An- alyzing and improving the image quality of StyleGAN,
T. Karras, S. Laine, M. Aittala, J. Hellsten, J. Lehtinen, and T. Aila, “An- alyzing and improving the image quality of StyleGAN,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 8110–8119
2020
-
[2]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[3]
SDXL: Improving latent diffusion models for high-resolution image synthesis,
D. Podell, A. Sauer, Z. Ke, J. M ¨ulleret al., “SDXL: Improving latent diffusion models for high-resolution image synthesis,” inInternational Conference on Learning Representations (ICLR), 2024
2024
-
[4]
Zero-shot text-to-image generation,
A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. V oss, A. Radford, M. Chen, and I. Sutskever, “Zero-shot text-to-image generation,” inInternational Conference on Machine Learning (ICML), 2021
2021
-
[5]
Scaling autoregressive models for content-rich text-to-image generation,
J. Yu, Z. Xu, J. Y . Koh, T. Luong, G. Baid, Z. Wang, V . Vasudevan, A. Ku, Y . Yang, B. K. Ayan, B. Hutchinson, W. Han, Z. Parekh, X. Li, H. Zhang, J. Baldridge, and Y . Wu, “Scaling autoregressive models for content-rich text-to-image generation,”Transactions on Machine Learning Research (TMLR), 2022
2022
-
[6]
CNN- generated images are surprisingly easy to spot... for now,
S.-Y . Wang, O. Wang, R. Zhang, A. Owens, and A. A. Efros, “CNN- generated images are surprisingly easy to spot... for now,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 8695–8704
2020
-
[7]
Detecting GAN-generated fake images using co-occurrence matrices,
L. Nataraj, T. Mohammed, B. S. Manjunath, S. Chandrasekaran, A. Flen- ner, J. H. Bappy, and A. K. Roy-Chowdhury, “Detecting GAN-generated fake images using co-occurrence matrices,” inElectronic Imaging, 2019
2019
-
[8]
Deepfake detection by analyzing convolutional traces,
L. Guarnera, O. Giudice, and S. Battiato, “Deepfake detection by analyzing convolutional traces,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 10, pp. 6721–6734, 2022
2022
-
[9]
Responsible disclosure of generative models using scalable fingerprinting,
N. Yu, L. S. Davis, and M. Fritz, “Responsible disclosure of generative models using scalable fingerprinting,” inInternational Conference on Learning Representations (ICLR), 2022
2022
-
[10]
Leveraging frequency analysis for deep fake image recognition,
S. Frank, M. Andrus, B. Jou, and M. Agrawala, “Leveraging frequency analysis for deep fake image recognition,” inInternational Conference on Machine Learning (ICML) Workshop, 2020
2020
-
[11]
Frequency-aware deepfake detection: Improving generalizability through frequency space domain learning,
C. Tan, Y . Zhao, S. Wei, G. Gu, P. Liu, and Y . Wei, “Frequency-aware deepfake detection: Improving generalizability through frequency space domain learning,” inAAAI Conference on Artificial Intelligence (AAAI), vol. 38, no. 5, 2024, pp. 5052–5060
2024
-
[12]
Media forensics and deepfakes: An overview,
L. Verdoliva, “Media forensics and deepfakes: An overview,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 42, no. 11, pp. 910–932, 2020
2020
-
[13]
Towards universal fake image detectors that generalize across generative models,
U. Ojha, Y . Li, J. Yang, A. A. Efros, R. Zhang, E. Shechtman, and A. Holynski, “Towards universal fake image detectors that generalize across generative models,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 24 480–24 490
2023
-
[14]
Forgery-aware adaptive transformer for generalizable synthetic image detection,
Z. Liu, K. Zhang, W. Wang, A. Zeng, Y . Tian, P. Luo, and Z. Liu, “Forgery-aware adaptive transformer for generalizable synthetic image detection,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[15]
A sanity check for AI-generated image detection,
S. Yan, O. Li, J. Cai, Y . Hao, X. Jiang, Y . Hu, and W. Xie, “A sanity check for AI-generated image detection,” inInternational Conference on Learning Representations (ICLR), 2025
2025
-
[16]
AIGI-Holmes: Towards explainable and generalizable AI- generated image detection via multimodal large language models,
Z. Zhou, Y . Luo, Y . Wu, K. Sun, J. Ji, K. Yan, S. Ding, X. Sun, Y . Wu, and R. Ji, “AIGI-Holmes: Towards explainable and generalizable AI- generated image detection via multimodal large language models,” in IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[17]
A visual leap in clip compositionality reasoning through generation of counterfactual sets,
Z. Jia, C. Huang, H. Fei, Y . Zhu, Z. Yuan, Y . Deng, J. Zhang, J. Zhang, and J. Zhou, “A visual leap in clip compositionality reasoning through generation of counterfactual sets,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 23 498–23 507
2025
-
[18]
Too vivid to be real? benchmarking and calibrating generative color fidelity,
Z. Fang, Z. Jia, Y . Zhong, P. Luo, J. Zhang, G. Lu, J. Yu, and W. Pei, “Too vivid to be real? benchmarking and calibrating generative color fidelity,”arXiv preprint arXiv:2603.10990, 2026
-
[19]
Styledecoupler: Generalizable artistic style disentanglement,
Z. Jia, J. Zhang, and J. Zhou, “Styledecoupler: Generalizable artistic style disentanglement,”arXiv preprint arXiv:2601.17697, 2026
-
[20]
Intrinsic images by entropy minimization,
G. D. Finlayson, S. D. Hordley, and M. S. Drew, “Intrinsic images by entropy minimization,”International Journal of Computer Vision, vol. 56, no. 3, pp. 131–147, 2004
2004
-
[21]
Color correction using principal components,
M. J. Vrhel and H. J. Trussell, “Color correction using principal components,”IEEE Transactions on Image Processing, vol. 1, no. 4, pp. 512–517, 1992
1992
-
[22]
J. D. Foley and A. van Dam,Fundamentals of Interactive Computer Graphics. Addison-Wesley, 1982
1982
-
[23]
Attributing fake images to GANs: Learning and analyzing GAN fingerprints,
N. Yu, L. S. Davis, and M. Fritz, “Attributing fake images to GANs: Learning and analyzing GAN fingerprints,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 7556–7566
2019
-
[24]
Faceforensics++: Learning to detect manipulated facial images,
A. R ¨ossler, D. Cozzolino, L. Verdoliva, C. Riess, J. Thies, and M. Nießner, “Faceforensics++: Learning to detect manipulated facial images,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 1–11
2019
-
[25]
Thinking in frequency: Face forgery detection by mining frequency-aware clues,
Y . Qian, G. Yin, L. Liu, S. Chen, and W. Wang, “Thinking in frequency: Face forgery detection by mining frequency-aware clues,” inEuropean Conference on Computer Vision (ECCV), 2020, pp. 86–103
2020
-
[26]
BiHPF: Bilateral high-pass filters for robust deepfake detection,
Y . Jeong, H. Choi, Y . Cho, Y . Kim, S. Kim, and S. Yoon, “BiHPF: Bilateral high-pass filters for robust deepfake detection,” inEuropean Conference on Computer Vision (ECCV), 2022, pp. 617–633
2022
-
[27]
Unveiling universal forensics of diffusion models with adversarial perturbations,
K. Xie, J. Liu, M. Zhu, G. Ding, Z. Liu, H. Chen, and H. Chen, “Unveiling universal forensics of diffusion models with adversarial perturbations,” inInternational Joint Conference on Neural Networks (IJCNN). IEEE, 2024, pp. 1–8
2024
-
[28]
Evaluating gener- ative models via one-dimensional code distributions,
Z. Jia, P. Luo, Y . Zhong, J. Zhang, and J. Zhou, “Evaluating gener- ative models via one-dimensional code distributions,”arXiv preprint arXiv:2603.08064, 2026
-
[29]
DIRE for diffusion- generated image detection,
K. Wang, X. Li, X. Wang, R. Zhang, and J.-Y . Zhu, “DIRE for diffusion- generated image detection,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[30]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, 16 “Learning transferable visual models from natural language supervi- sion,” inAdvances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[31]
Forensics adapter: Adapting CLIP for generalizable face forgery detection,
X. Cui, Y . Li, A. Luo, J. Zhou, and J. Dong, “Forensics adapter: Adapting CLIP for generalizable face forgery detection,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[32]
Multimodal conditional information bottleneck for generalizable AI-generated image detection,
H. Qin, D. Chang, Y . Gao, B. Yu, L. Chen, and Z. Ma, “Multimodal conditional information bottleneck for generalizable AI-generated image detection,”arXiv preprint arXiv:2505.15217, 2025
-
[33]
Large scale GAN training for high fidelity natural image synthesis,
A. Brock, J. Donahue, and K. Simonyan, “Large scale GAN training for high fidelity natural image synthesis,” inInternational Conference on Learning Representations (ICLR), 2019
2019
-
[34]
Classifier-Free Diffusion Guidance
J. Ho and T. Salimans, “Classifier-free diffusion guidance,”arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Photorealistic text-to- image diffusion models with deep language understanding,
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, S. K. S. Ghasemipour, B. K. Ayan, S. S. Mahdavi, R. G. Lopes, T. Salimans, J. Ho, D. J. Fleet, and M. Norouzi, “Photorealistic text-to- image diffusion models with deep language understanding,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[36]
Angle domain guidance: Latent diffusion requires rotation rather than extrapolation,
C. Jin, Z. Xiao, C. Liu, and Y . Gu, “Angle domain guidance: Latent diffusion requires rotation rather than extrapolation,” inInternational Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol. 267, 2025, pp. 28 187–28 212
2025
-
[37]
Eliminating oversaturation and artifacts of high guidance scales in diffusion models,
S. Sadat, O. Hilliges, and R. M. Weber, “Eliminating oversaturation and artifacts of high guidance scales in diffusion models,” inInternational Conference on Learning Representations (ICLR), 2025
2025
-
[38]
Common diffusion noise schedules and sample steps are flawed,
S. Lin, B. Liu, J. Li, and X. Yang, “Common diffusion noise schedules and sample steps are flawed,” inIEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2024, pp. 5404–5411
2024
-
[39]
Neural discrete representation learning,
A. van den Oord, O. Vinyals, and K. Kavukcuoglu, “Neural discrete representation learning,” inAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[40]
Sequence level training with recurrent neural networks,
M. Ranzato, S. Chopra, M. Auli, and W. Zaremba, “Sequence level training with recurrent neural networks,” inInternational Conference on Learning Representations (ICLR), 2016
2016
-
[41]
Visual autoregressive modeling: Scalable image generation via next-scale prediction,
K. Tian, Y . Jiang, Z. Yuan, B. Peng, and L. Wang, “Visual autoregressive modeling: Scalable image generation via next-scale prediction,” in Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[42]
Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis,
J. Han, J. Liu, Y . Jiang, B. Yan, Y . Zhang, B. Peng, and X. Liu, “Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 29 265–29 274
2025
-
[43]
HART: Efficient visual generation with hybrid autoregressive transformer,
H. Tang, Y . Wu, S. Yang, E. Xie, J. Chen, J. Chen, Z. Zhang, H. Cai, Y . Lu, and S. Han, “HART: Efficient visual generation with hybrid autoregressive transformer,” inInternational Conference on Learning Representations (ICLR), 2025
2025
-
[44]
Hierarchical masked autoregressive models with low-resolution token pivots,
G. Zheng, Y . Li, Y . Pan, J. Deng, T. Yao, Y . Zhang, and T. Mei, “Hierarchical masked autoregressive models with low-resolution token pivots,” inInternational Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol. 267, 2025, pp. 92 928– 92 948
2025
-
[45]
D 3QE: Learning discrete distribution discrepancy-aware quantization error for autoregressive-generated image detection,
Y . Zhang, B. Yu, Y . Zheng, W. Zheng, Y . Duan, L. Chen, J. Zhou, and J. Lu, “D 3QE: Learning discrete distribution discrepancy-aware quantization error for autoregressive-generated image detection,” in IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[46]
Microsoft COCO: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, L. Bourdev, R. Girshick, J. Hays, P. Perona, D. Ramanan, C. L. Zitnick, and P. Doll ´ar, “Microsoft COCO: Common objects in context,” inEuropean Conference on Computer Vision (ECCV), 2014, pp. 740–755
2014
-
[47]
ImageNet large scale visual recognition challenge,
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei- Fei, “ImageNet large scale visual recognition challenge,”International Journal of Computer Vision, vol. 115, no. 3, pp. 211–252, 2015
2015
-
[48]
LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop
F. Yu, Y . Zhang, S. Song, A. Seff, and J. Xiao, “LSUN: Construction of a large-scale image dataset using deep learning with humans in the loop,”arXiv preprint arXiv:1506.03365, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[49]
X. Wu, Y . Hao, K. Sun, Y . Chen, F. Zhu, R. Zhao, and H. Li, “Human preference score v2: A solid benchmark for evaluating human pref- erences of text-to-image synthesis,”arXiv preprint arXiv:2306.09341, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Progressive growing of GANs for improved quality, stability, and variation,
T. Karras, T. Aila, S. Laine, and J. Lehtinen, “Progressive growing of GANs for improved quality, stability, and variation,” inInternational Conference on Learning Representations (ICLR), 2018
2018
-
[51]
GenImage: A million-scale benchmark for detecting AI-generated images,
Z.-T. Zhu, H. Zhang, J. Ouyang, Z. Liu, Z. Chen, Y . Shen, S. Zhang, J. Li, L. Chen, C. Wang, W. Zuo, and Z. Liu, “GenImage: A million-scale benchmark for detecting AI-generated images,” inAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2023
2023
-
[52]
Learning on gradi- ents: Generalized artifacts representation for GAN-generated images detection,
C. Tan, Y . Zhao, S. Wei, G. Gu, and Y . Wei, “Learning on gradi- ents: Generalized artifacts representation for GAN-generated images detection,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 12 105–12 114
2023
-
[53]
PatchCraft: Exploring texture patch for efficient AI-generated image detection,
N. Zhong, Y . Xu, S. Li, Z. Qian, and X. Zhang, “PatchCraft: Exploring texture patch for efficient AI-generated image detection,”arXiv preprint arXiv:2311.12397, 2023
-
[54]
Rethinking the up- sampling operations in CNN-based generative network for generalizable deepfake detection,
C. Tan, Y . Zhao, S. Wei, G. Gu, P. Liu, and Y . Wei, “Rethinking the up- sampling operations in CNN-based generative network for generalizable deepfake detection,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 28 130–28 139
2024
-
[55]
Improving synthetic image detection towards generalization: An image transformation per- spective,
O. Li, J. Cai, Y . Hao, X. Jiang, Y . Hu, and F. Feng, “Improving synthetic image detection towards generalization: An image transformation per- spective,” inACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2025
2025
-
[56]
Secret lies in color: Enhancing AI-generated image detection with color distribution analysis,
Z. Jia, C. Huang, Y . Zhu, H. Fei, X. Duan, Z. Yuan, Y . Deng, J. Zhang, J. Zhang, and J. Zhou, “Secret lies in color: Enhancing AI-generated image detection with color distribution analysis,” inIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 13 445–13 454. Zexi Jiareceived the B.Eng. degree in software engineering (data...
2025
-
[57]
His research interests include machine learning and multimodal models
He is currently a Senior Researcher and Man- ager of the Multimodal Models Research Team with Tencent WeChat AI, Beijing, China. His research interests include machine learning and multimodal models. He has published over 70 peer-reviewed research papers at top-tier AI conferences and in reputable journals, including ACL, NeurIPS, CVPR, and AAAI. Jie Zhou...
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.