Reframing LLM Agent Security as an Agent-Human Interaction Problem
Pith reviewed 2026-06-30 13:48 UTC · model grok-4.3
The pith
LLM agent security is fundamentally an agent-human interaction problem rather than a purely algorithmic one.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Analysis of the surveyed literature and deployments establishes that human participation in agent security decisions is indispensable given current capabilities, that a clear industry-academia mismatch exists where deployed mechanisms receive little research focus while studied ones remain unused, and that agent-human interaction security must be treated as its own research domain with distinct design principles, evaluation methods, and theoretical foundations.
What carries the argument
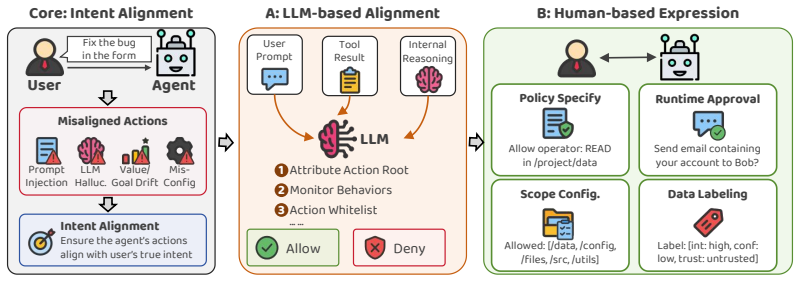
The agent-human interaction (AHI) framing, which treats security outcomes as products of human oversight mechanisms interacting with agent autonomy rather than as results of algorithmic improvements alone.
If this is right
- Human participation mechanisms will continue to be required for security until agents demonstrate independent intent alignment at production scale.
- Security evaluations must measure both protection strength and the cognitive load imposed on users by approval and configuration steps.
- Research priorities should shift toward improving the three deployed human-centric mechanisms rather than solely advancing undeployed academic categories.
- A dedicated AHI research program would develop its own metrics for balancing autonomy against oversight burden.
Where Pith is reading between the lines
- Treating AHI as central could prompt similar interaction-focused security work for other AI systems that act on behalf of users.
- Interface designers may need tools that let users set policies once and adjust them with low effort while preserving security guarantees.
- The mismatch points to value in joint industry-academic projects that test whether new human-in-the-loop designs can reduce approval fatigue in real deployments.
Load-bearing premise
The surveyed systems and papers capture a persistent structural divide between what gets built and what gets studied instead of a temporary imbalance that will correct itself.
What would settle it
Widespread adoption of an intent-anchoring or trust-labeling technique in multiple production agent systems that operate without any human approval or policy steps would test whether algorithmic methods can suffice without human involvement.
Figures
read the original abstract
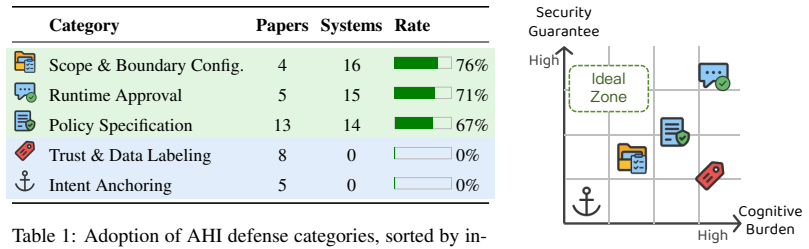
We argue that LLM agent security is fundamentally an agent-human interaction (AHI) problem, not a purely algorithmic one. To substantiate this position, we conduct a systematic analysis of 59 academic papers, 21 production agent systems, and 26 security plugins as of April 2026. Our analysis reveals a striking pattern: the three widely deployed human-centric security mechanisms (policy specification, runtime approval, and scope configuration) dominate industry practice, each adopted by at least 14 of 21 systems (14, 15, and 16, respectively), while the categories most heavily studied in academia (intent anchoring and trust labeling) see zero production deployment. Yet current human participation mechanisms are far from satisfactory: they suffer from a fundamental trade-off between cognitive burden and security guarantees, leaving users caught between approval fatigue and uncontrolled agent autonomy. We make three contributions. First, through a systematic comparison of LLM-based and human-based intent alignment, we argue that human participation in agent security decisions is indispensable given current capabilities. Second, we quantify a pronounced industry-academia mismatch: the security mechanisms that practitioners actually deploy receive scant research attention, while the approaches that researchers favor remain undeployed. Third, we propose a three-direction research agenda and call for AHI security to be recognized as a first-class research citizen, one that demands its own design principles, evaluation methods, and theoretical foundations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that LLM agent security is fundamentally an agent-human interaction (AHI) problem rather than purely algorithmic. It substantiates this via a systematic analysis of 59 academic papers, 21 production agent systems, and 26 security plugins (as of April 2026), finding that human-centric mechanisms (policy specification in 14/21 systems, runtime approval in 15/21, scope configuration in 16/21) dominate industry practice while academic favorites (intent anchoring, trust labeling) have zero deployment. It claims human participation is indispensable given current LLM capabilities due to a cognitive-burden/security trade-off, quantifies an industry-academia mismatch, and proposes a three-direction research agenda to treat AHI security as a first-class area with its own design principles and foundations.
Significance. If the reframing holds, the work could usefully redirect security research toward interaction-focused methods, evaluation protocols, and theory that account for human oversight in agent systems. The survey snapshot of deployment patterns is a concrete contribution that highlights a potential gap between research and practice. However, the significance is tempered because the evidence is observational and time-bound; stronger justification for the 'fundamental' and 'indispensable' claims would be needed for the agenda to reshape the field durably.
major comments (2)
- [§3] §3 (Systematic Analysis of Papers, Systems, and Plugins): The abstract and this section report precise adoption counts (14/21, 15/21, 16/21) and zero-deployment claims but supply no information on how the 21 production systems were selected, the coding scheme for classifying mechanisms into categories such as 'policy specification' vs. 'intent anchoring,' or any measure of inter-rater reliability. This directly affects the robustness of the central mismatch pattern used to support the AHI reframing.
- [§4] §4 (Comparison of LLM-based and human-based intent alignment): The claim that human participation is 'indispensable given current capabilities' and that AHI is 'fundamentally' required rests on the observed trade-off and the April 2026 snapshot. The section does not address whether future algorithmic improvements in intent alignment or verification could in principle narrow the cognitive-burden gap; without such an argument or impossibility result, the leap from current deployment patterns to a structural, non-algorithmic characterization remains unsupported and load-bearing for the research-agenda recommendation.
minor comments (2)
- [Abstract] Abstract: The date 'April 2026' is prospective relative to the present; a brief clarification on data-collection timing or whether the counts are projected would prevent reader confusion.
- [§3] §3: A summary table listing the 59 papers and 26 plugins by category (with example citations) would make the categorization more transparent and easier to verify than the current prose description alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to improve methodological transparency and strengthen the justification for our core claims. We address each major comment below with specific revisions where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (Systematic Analysis of Papers, Systems, and Plugins): The abstract and this section report precise adoption counts (14/21, 15/21, 16/21) and zero-deployment claims but supply no information on how the 21 production systems were selected, the coding scheme for classifying mechanisms into categories such as 'policy specification' vs. 'intent anchoring,' or any measure of inter-rater reliability. This directly affects the robustness of the central mismatch pattern used to support the AHI reframing.
Authors: We agree that additional methodological details are needed to support the robustness of the reported adoption patterns. The original manuscript omitted explicit description of the selection process and classification procedures. In the revised manuscript, we will expand the opening of §3 to specify: the criteria for selecting the 21 production systems (prioritizing systems with documented public usage, industry reports, and GitHub activity as of April 2026); the taxonomy and decision rules used to map mechanisms to categories such as policy specification versus intent anchoring; and the collaborative author review process used for classification. We will also note the absence of formal inter-rater reliability statistics. These additions will be presented without changing the underlying counts or conclusions. revision: yes
-
Referee: [§4] §4 (Comparison of LLM-based and human-based intent alignment): The claim that human participation is 'indispensable given current capabilities' and that AHI is 'fundamentally' required rests on the observed trade-off and the April 2026 snapshot. The section does not address whether future algorithmic improvements in intent alignment or verification could in principle narrow the cognitive-burden gap; without such an argument or impossibility result, the leap from current deployment patterns to a structural, non-algorithmic characterization remains unsupported and load-bearing for the research-agenda recommendation.
Authors: The manuscript explicitly qualifies its claims as holding 'given current capabilities' and grounds the 'fundamental' characterization in the persistent cognitive-burden/security trade-off documented across deployed human-centric mechanisms, together with the complete absence of purely algorithmic approaches in production. This evidence supports treating AHI as a first-class concern for the present state of the field. We acknowledge, however, that §4 does not explicitly consider whether future algorithmic progress could materially reduce reliance on human oversight. In revision we will insert a short paragraph in §4 that (a) notes the possibility of such advances and (b) argues that the AHI perspective remains useful for designing and evaluating hybrid systems even if algorithmic capabilities improve. This addition clarifies the scope of the claim while preserving the motivation for the proposed research agenda. revision: partial
Circularity Check
No significant circularity; survey-based argument relies on external data
full rationale
The paper's central claim—that LLM agent security is fundamentally an AHI problem—is substantiated by a systematic analysis of 59 external academic papers, 21 production systems, and 26 security plugins, revealing deployment patterns (e.g., policy specification in 14/21 systems) and an industry-academia mismatch. No load-bearing steps reduce by construction to self-referential definitions, fitted inputs renamed as predictions, or self-citation chains; the argument is interpretive from independent counts rather than any internal derivation or ansatz. This is a standard non-circular survey paper whose evidence is externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human participation in agent security decisions is indispensable given current LLM capabilities
Forward citations
Cited by 2 Pith papers
-
One Goal, Many Commands: Characterizing Denylist Fragility in AI Agents
ShellSieve, an LLM-driven pipeline, detects command denylist fragility in terminal AI agents and finds 69.0-98.6% of 1,709 GitHub-collected denylists to be bypassable.
-
Oversight Has a Capacity: Calibrating Agent Guards to a Subjective, Fatiguing Human
Human oversight for LLM agent actions is capacity-limited by subjective disagreement (kappa 0.52) and fatigue, producing an inverted-U safety curve and vulnerability to flooding attacks in a modeling study.
Reference graph
Works this paper leans on
-
[1]
Nadya Abaev, Denis Klimov, Gerard Levinov, David Mimran, Yuval Elovici, and Asaf Shabtai. Agent- guardian: Learning access control policies to govern ai agent behavior.arXiv preprint arXiv:2601.10440, 2026
-
[2]
SecureClaw: OW ASP-aligned security plugin.https://github.com/adversa-ai/ secureclaw, 2025
Adversa AI. SecureClaw: OW ASP-aligned security plugin.https://github.com/adversa-ai/ secureclaw, 2025
2025
-
[3]
Aider: Terminal-based AI pair programming.https://aider.chat, 2025
Aider. Aider: Terminal-based AI pair programming.https://aider.chat, 2025
2025
-
[4]
99% false positives: A qualitative study of {SOC}analysts’ perspectives on security alarms
Bushra A Alahmadi, Louise Axon, and Ivan Martinovic. 99% false positives: A qualitative study of {SOC}analysts’ perspectives on security alarms. In31st USENIX Security Symposium (USENIX Security 22), pages 2783–2800, 2022
2022
-
[5]
Amazon bedrock agents.https://aws.amazon.com/bedrock/agents/, 2025
Amazon Web Services. Amazon bedrock agents.https://aws.amazon.com/bedrock/agents/, 2025
2025
-
[6]
Claude code: Anthropic’s agentic coding tool.https://docs.anthropic.com/en/docs/ claude-code, 2025
Anthropic. Claude code: Anthropic’s agentic coding tool.https://docs.anthropic.com/en/docs/ claude-code, 2025
2025
-
[7]
Claude code sandboxing.https://www.anthropic.com/engineering/ claude-code-sandboxing, 2025
Anthropic. Claude code sandboxing.https://www.anthropic.com/engineering/ claude-code-sandboxing, 2025
2025
-
[8]
AgentBound: Securing Execution Boundaries of AI Agents
Christoph B ¨uhler, Matteo Biagiola, Luca Di Grazia, and Guido Salvaneschi. Securing ai agent execution. arXiv preprint arXiv:2510.21236, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Systems security foundations for agentic computing.arXiv preprint arXiv:2512.01295, 2025
Mihai Christodorescu, Earlence Fernandes, Ashish Hooda, Somesh Jha, Johann Rehberger, Kamalika Chaudhuri, Xiaohan Fu, Khawaja Shams, Guy Amir, Jihye Choi, et al. Systems security foundations for agentic computing.arXiv preprint arXiv:2512.01295, 2025
-
[10]
Devin: Autonomous AI software engineer.https://devin.ai/, 2025
Cognition. Devin: Autonomous AI software engineer.https://devin.ai/, 2025
2025
-
[11]
Securing AI Agents with Information-Flow Control
Manuel Costa, Boris K ¨opf, Aashish Kolluri, Andrew Paverd, Mark Russinovich, Ahmed Salem, Shruti Tople, Lukas Wutschitz, and Santiago Zanella-B ´eguelin. Securing ai agents with information-flow con- trol.arXiv preprint arXiv:2505.23643, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
CrewAI: Multi-agent orchestration framework.https://crewai.com/, 2025
CrewAI. CrewAI: Multi-agent orchestration framework.https://crewai.com/, 2025
2025
-
[13]
Cursor AI-native IDE security.https://cursor.com/security, 2025
Cursor. Cursor AI-native IDE security.https://cursor.com/security, 2025
2025
-
[14]
Defeating Prompt Injections by Design
Edoardo Debenedetti, Ilia Shumailov, Tianqi Fan, Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, Chongyang Shi, Andreas Terzis, and Florian Tram `er. Defeating prompt injections by design.arXiv preprint arXiv:2503.18813, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Towards verifiably safe tool use for llm agents.arXiv preprint arXiv:2601.08012, 2026
Aarya Doshi, Yining Hong, Congying Xu, Eunsuk Kang, Alexandros Kapravelos, and Christian K ¨astner. Towards verifiably safe tool use for llm agents.arXiv preprint arXiv:2601.08012, 2026
-
[16]
mcp-guardian: MCP proxy with human approval.https://github.com/eqtylab/ mcp-guardian, 2025
Eqty Lab. mcp-guardian: MCP proxy with human approval.https://github.com/eqtylab/ mcp-guardian, 2025
2025
-
[17]
Improving ssl warnings: Comprehension and adherence
Adrienne Porter Felt, Alex Ainslie, Robert W Reeder, Sunny Consolvo, Somas Thyagaraja, Alan Bettes, Helen Harris, and Jeff Grimes. Improving ssl warnings: Comprehension and adherence. InProceedings of the 33rd annual ACM conference on human factors in computing systems, pages 2893–2902, 2015
2015
-
[18]
KJ Feng, Tae Soo Kim, Rock Yuren Pang, Faria Huq, Tal August, and Amy X Zhang. On the regulatory potential of user interfaces for ai agent governance.arXiv preprint arXiv:2512.00742, 2025
-
[19]
Github copilot CLI.https://github.com/features/copilot/cli, 2025
GitHub. Github copilot CLI.https://github.com/features/copilot/cli, 2025
2025
-
[20]
Haochen Gong, Chenxiao Li, Rui Chang, and Wenbo Shen. Secure and efficient access control for computer-use agents via context space.arXiv preprint arXiv:2509.22256, 2025
-
[21]
Google agent development kit (ADK).https://github.com/google/adk-python, 2025
Google. Google agent development kit (ADK).https://github.com/google/adk-python, 2025
2025
-
[22]
Gemini CLI.https://gemini.google.com/, 2025
Google. Gemini CLI.https://gemini.google.com/, 2025
2025
-
[23]
Guardrails AI: Python framework for LLM validation.https://github.com/ guardrails-ai/guardrails, 2025
Guardrails AI. Guardrails AI: Python framework for LLM validation.https://github.com/ guardrails-ai/guardrails, 2025. 10
2025
-
[24]
An empirical study of llm-as-a-judge for llm evaluation: Fine-tuned judge model is not a general substitute for gpt-4
Hui Huang, Xingyuan Bu, Hongli Zhou, Yingqi Qu, Jing Liu, Muyun Yang, Bing Xu, and Tiejun Zhao. An empirical study of llm-as-a-judge for llm evaluation: Fine-tuned judge model is not a general substitute for gpt-4. InFindings of the Association for Computational Linguistics: ACL 2025, pages 5880–5895, 2025
2025
-
[25]
Understanding the planning of LLM agents: A survey
Xu Huang, Weiwen Liu, Xiaolong Chen, Xingmei Wang, Hao Wang, Defu Lian, Yasheng Wang, Ruim- ing Tang, and Enhong Chen. Understanding the planning of llm agents: A survey.arXiv preprint arXiv:2402.02716, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
mcp-scan: MCP server security scanner.https://github.com/ invariantlabs-ai/mcp-scan, 2025
Invariant Labs / Snyk. mcp-scan: MCP server security scanner.https://github.com/ invariantlabs-ai/mcp-scan, 2025
2025
-
[27]
Zimo Ji, Daoyuan Wu, Wenyuan Jiang, Pingchuan Ma, Zongjie Li, Yudong Gao, Shuai Wang, and Yingjiu Li. Taming various privilege escalation in llm-based agent systems: A mandatory access control frame- work.arXiv preprint arXiv:2601.11893, 2026
-
[28]
The task shield: Enforcing task alignment to defend against indirect prompt injection in llm agents
Feiran Jia, Tong Wu, Xin Qin, and Anna Squicciarini. The task shield: Enforcing task alignment to defend against indirect prompt injection in llm agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 29680–29697, 2025
2025
-
[29]
claude-code-safety-net: Hook for blocking dangerous commands.https://github.com/ kenryu42/claude-code-safety-net, 2025
kenryu42. claude-code-safety-net: Hook for blocking dangerous commands.https://github.com/ kenryu42/claude-code-safety-net, 2025
2025
-
[30]
Juhee Kim, Woohyuk Choi, and Byoungyoung Lee. Prompt flow integrity to prevent privilege escalation in llm agents.arXiv preprint arXiv:2503.15547, 2025
-
[31]
LangChain/LangGraph agent framework.https://www.langchain.com/langgraph, 2025
LangChain. LangChain/LangGraph agent framework.https://www.langchain.com/langgraph, 2025
2025
-
[32]
ACE: A Security Architecture for LLM-Integrated App Systems
Evan Li, Tushin Mallick, Evan Rose, William Robertson, Alina Oprea, and Cristina Nita-Rotaru. Ace: A security architecture for llm-integrated app systems.arXiv preprint arXiv:2504.20984, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Hao Li, Xiaogeng Liu, Hung-Chun Chiu, Dianqi Li, Ning Zhang, and Chaowei Xiao. Drift: Dynamic rule-based defense with injection isolation for securing llm agents.arXiv preprint arXiv:2506.12104, 2025
-
[34]
Peiran Li, Xinkai Zou, Zhuohang Wu, Ruifeng Li, Shuo Xing, Hanwen Zheng, Zhikai Hu, Yuping Wang, Haoxi Li, Qin Yuan, et al. Safeflow: A principled protocol for trustworthy and transactional autonomous agent systems.arXiv preprint arXiv:2506.07564, 2025
-
[35]
Agrail: A lifelong agent guardrail with effective and adaptive safety detection
Weidi Luo, Shenghong Dai, Xiaogeng Liu, Suman Banerjee, Huan Sun, Muhao Chen, and Chaowei Xiao. Agrail: A lifelong agent guardrail with effective and adaptive safety detection. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8104– 8139, 2025
2025
-
[36]
Contex- tualized evaluations: Judging language model responses to underspecified queries.Transactions of the Association for Computational Linguistics, 13:878–900, 2025
Chaitanya Malaviya, Joseph Chee Chang, Dan Roth, Mohit Iyyer, Mark Yatskar, and Kyle Lo. Contex- tualized evaluations: Judging language model responses to underspecified queries.Transactions of the Association for Computational Linguistics, 13:878–900, 2025
2025
-
[37]
Microsoft agent framework autogen.https://github.com/microsoft/autogen, 2025
Microsoft. Microsoft agent framework autogen.https://github.com/microsoft/autogen, 2025
2025
-
[38]
Codex: OpenAI’s cloud coding agent.https://developers.openai.com/codex/ agent-approvals-security, 2025
OpenAI. Codex: OpenAI’s cloud coding agent.https://developers.openai.com/codex/ agent-approvals-security, 2025
2025
-
[39]
Llmz+: Contextual prompt whitelist principles for agentic llms
Tom Pawelek, Raj Patel, Charlotte Crowell, Noorbakhsh Amiri Golilarz, Sudip Mittal, Shahram Rahimi, and Andy Perkins. Llmz+: Contextual prompt whitelist principles for agentic llms. In2025 International Conference on Machine Learning and Applications (ICMLA), pages 1396–1402. IEEE, 2025
2025
-
[40]
Intercept: Y AML policy enforcement for MCP.https://github.com/PolicyLayer/ Intercept, 2025
PolicyLayer. Intercept: Y AML policy enforcement for MCP.https://github.com/PolicyLayer/ Intercept, 2025
2025
-
[41]
I} do (not) need that{Feature!
Sarah Prange, Pascal Knierim, Gabriel Knoll, Felix Dietz, Alexander De Luca, and Florian Alt.{“I} do (not) need that{Feature!”}–understanding{Users’}awareness and control of privacy permissions on android smartphones. InTwentieth Symposium on Usable Privacy and Security (SOUPS 2024), pages 453–472, 2024
2024
-
[42]
Nemo guardrails: A toolkit for controllable and safe llm applications with programmable rails
Traian Rebedea, Razvan Dinu, Makesh Narsimhan Sreedhar, Christopher Parisien, and Jonathan Co- hen. Nemo guardrails: A toolkit for controllable and safe llm applications with programmable rails. InProceedings of the 2023 conference on empirical methods in natural language processing: system demonstrations, pages 431–445, 2023. 11
2023
-
[43]
Replit agent.https://blog.replit.com/safe-vibe-coding, 2025
Replit. Replit agent.https://blog.replit.com/safe-vibe-coding, 2025
2025
-
[44]
Agentforce: Salesforce enterprise agent platform.https:// trailhead.salesforce.com/content/learn/modules/trusted-agentic-ai/ explore-agentforce-guardrails-and-trust-patterns, 2025
Salesforce. Agentforce: Salesforce enterprise agent platform.https:// trailhead.salesforce.com/content/learn/modules/trusted-agentic-ai/ explore-agentforce-guardrails-and-trust-patterns, 2025
2025
-
[45]
Agent-Sentry: Bounding LLM Agents via Execution Provenance
Rohan Sequeira, Stavros Damianakis, Umar Iqbal, and Konstantinos Psounis. Agent-sentry: Bounding llm agents via execution provenance.arXiv preprint arXiv:2603.22868, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[46]
Zhengyang Shan, Jiayun Xin, Yue Zhang, and Minghui Xu. Don’t let the claw grip your hand: A security analysis and defense framework for openclaw.arXiv preprint arXiv:2603.10387, 2026
-
[47]
Progent: Securing AI Agents with Privilege Control
Tianneng Shi, Jingxuan He, Zhun Wang, Hongwei Li, Linyu Wu, Wenbo Guo, and Dawn Song. Progent: Programmable privilege control for llm agents.arXiv preprint arXiv:2504.11703, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Shoaib Ahmed Siddiqui, Radhika Gaonkar, Boris K ¨opf, David Krueger, Andrew Paverd, Ahmed Salem, Shruti Tople, Lukas Wutschitz, Menglin Xia, and Santiago Zanella-B ´eguelin. Permissive information- flow analysis for large language models.arXiv preprint arXiv:2410.03055, 2024
-
[49]
Stuck in the permissions with you: Developer & end-user perspectives on app permissions & their privacy ramifications
Mohammad Tahaei, Ruba Abu-Salma, and Awais Rashid. Stuck in the permissions with you: Developer & end-user perspectives on app permissions & their privacy ramifications. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems, pages 1–24, 2023
2023
-
[50]
Trail of bits security skills for claude code.https://github.com/trailofbits/skills, 2025
Trail of Bits. Trail of bits security skills for claude code.https://github.com/trailofbits/skills, 2025
2025
-
[51]
Contextual agent security: A policy for every purpose
Lillian Tsai and Eugene Bagdasarian. Contextual agent security: A policy for every purpose. InProceed- ings of the 2025 Workshop on Hot Topics in Operating Systems, pages 8–17, 2025
2025
-
[52]
Ambig-swe: Interactive agents to overcome underspecificity in software engineering
Sanidhya Vijayvargiya, Xuhui Zhou, Akhila Yerukola, Maarten Sap, and Graham Neubig. Ambig-swe: Interactive agents to overcome underspecificity in software engineering. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[53]
Agentspec: Customizable runtime enforcement for safe and reliable llm agents.(2026)
Haoyu Wang, Christopher M Poskitt, and Jun Sun. Agentspec: Customizable runtime enforcement for safe and reliable llm agents.(2026). InProceedings of the IEEE/ACM International Conference on Soft- ware Engineering, ICSE, pages 12–18, 2026
2026
-
[54]
Fath: Authentication-based test-time defense against indirect prompt injection attacks
Jiongxiao Wang, Fangzhou Wu, Wendi Li, Jinsheng Pan, Edward Suh, Z Morley Mao, Muhao Chen, and Chaowei Xiao. Fath: Authentication-based test-time defense against indirect prompt injection attacks. arXiv preprint arXiv:2410.21492, 2024
-
[55]
Peiran Wang, Yang Liu, Yunfei Lu, Yifeng Cai, Hongbo Chen, Qingyou Yang, Jie Zhang, Jue Hong, and Ye Wu. Agentarmor: Enforcing program analysis on agent runtime trace to defend against prompt injection.arXiv preprint arXiv:2508.01249, 2025
-
[56]
Peiran Wang, Xinfeng Li, Chong Xiang, Jinghuai Zhang, Ying Li, Lixia Zhang, Xiaofeng Wang, and Yuan Tian. The landscape of prompt injection threats in llm agents: From taxonomy to analysis.arXiv preprint arXiv:2602.10453, 2026
-
[57]
Fangzhou Wu, Ethan Cecchetti, and Chaowei Xiao. System-level defense against indirect prompt injec- tion attacks: An information flow control perspective.arXiv preprint arXiv:2409.19091, 2024
-
[58]
Yuhao Wu, Franziska Roesner, Tadayoshi Kohno, Ning Zhang, and Umar Iqbal. Isolategpt: An execution isolation architecture for llm-based agentic systems.arXiv preprint arXiv:2403.04960, 2024
-
[59]
Towards automating data access permissions in ai agents.arXiv preprint arXiv:2511.17959, 2025
Yuhao Wu, Ke Yang, Franziska Roesner, Tadayoshi Kohno, Ning Zhang, and Umar Iqbal. Towards automating data access permissions in ai agents.arXiv preprint arXiv:2511.17959, 2025
-
[60]
Chong Xiang, Drew Zagieboylo, Shaona Ghosh, Sanjay Kariyappa, Kai Greshake, Hanshen Xiao, Chaowei Xiao, and G Edward Suh. Architecting secure ai agents: Perspectives on system-level defenses against indirect prompt injection attacks.arXiv preprint arXiv:2603.30016, 2026
-
[61]
Boyang Yan. Fault-tolerant sandboxing for ai coding agents: A transactional approach to safe autonomous execution.arXiv preprint arXiv:2512.12806, 2025
-
[62]
What Prompts Don't Say: Understanding and Managing Underspecification in LLM Prompts
Chenyang Yang, Yike Shi, Qianou Ma, Michael Xieyang Liu, Christian K ¨astner, and Tongshuang Wu. What prompts don’t say: Understanding and managing underspecification in llm prompts.arXiv preprint arXiv:2505.13360, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[64]
Adaptive attacks break defenses against indirect prompt injection attacks on llm agents
Qiusi Zhan, Richard Fang, Henil Shalin Panchal, and Daniel Kang. Adaptive attacks break defenses against indirect prompt injection attacks on llm agents. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 7101–7117, 2025
2025
-
[65]
Judging llm-as-a-judge with mt-bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems, 36:46595–46623, 2023
2023
-
[66]
Peter Yong Zhong, Siyuan Chen, Ruiqi Wang, McKenna McCall, Ben L Titzer, Heather Miller, and Phillip B Gibbons. Rtbas: Defending llm agents against prompt injection and privacy leakage.arXiv preprint arXiv:2502.08966, 2025
-
[67]
Jinhao Zhu, Kevin Tseng, Gil Vernik, Xiao Huang, Shishir G Patil, Vivian Fang, and Raluca Ada Popa. Miniscope: A least privilege framework for authorizing tool calling agents.arXiv preprint arXiv:2512.11147, 2025
-
[68]
Kaijie Zhu, Xianjun Yang, Jindong Wang, Wenbo Guo, and William Yang Wang. Melon: Provable defense against indirect prompt injection attacks in ai agents.arXiv preprint arXiv:2502.05174, 2025. A SoK Methodology We define AHI as any mechanism in which a human explicitly or implicitly participates in a security-relevant decision made by, or about, an LLM age...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.