Interdomain Attention: Beyond Token-Level Key-Value Memory
Pith reviewed 2026-06-30 13:56 UTC · model grok-4.3
The pith
Interdomain Attention recovers query-conditioned attention over a fixed recurrent state by projecting keys and values onto SSM basis functions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
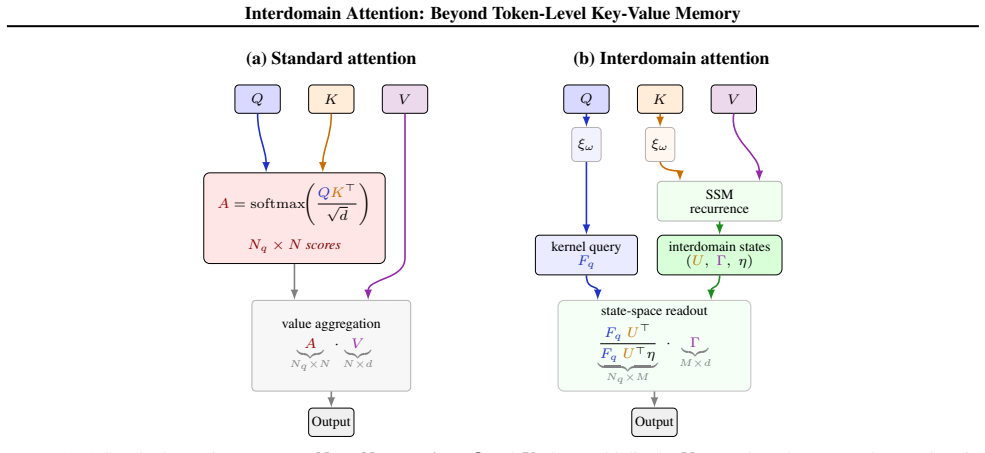
Interdomain Attention integrates an SSM into an attention module through kernel methods: an attention kernel is approximated by a finite feature map, the resulting key features and values are projected onto a shared set of basis functions maintained by a single SSM recurrence, and each query attends to the compressed coefficients through its own feature map, recovering query-conditioned attention over a fixed-size state. The scalable layer is a learned relaxation of this derivation.
What carries the argument
Interdomain Attention, the mechanism that projects finite-feature-map key and value representations onto SSM-maintained basis functions so that queries can attend to the resulting compressed coefficients.
If this is right
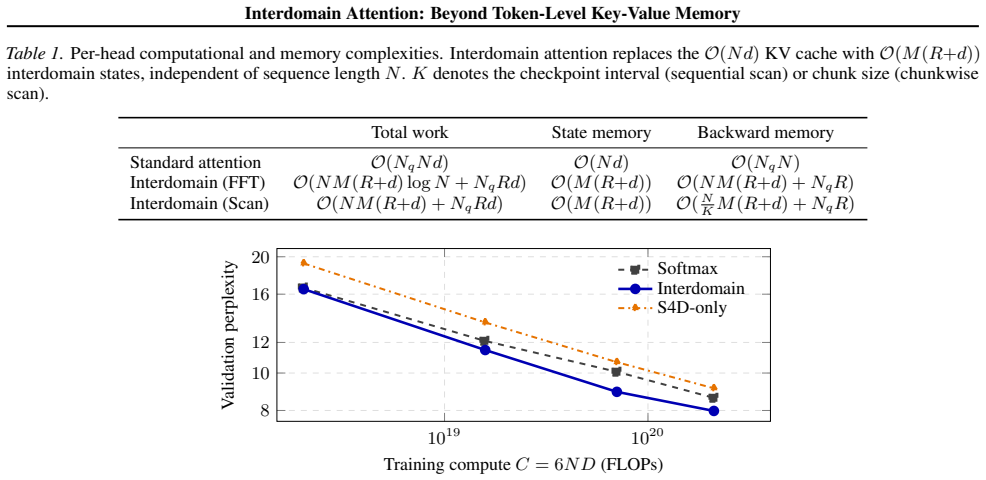
- At matched recurrent-state budget, Interdomain Attention improves on an SSM token mixer at every scale from 125M to 1.3B in autoregressive language modeling on FineWeb-Edu.
- At 1.3B parameters it surpasses a same-recipe softmax baseline on validation perplexity and on the eight-task commonsense suite.
- The model inherits the length-flat behavior of its fixed-state core out to 3.5 times the training context.
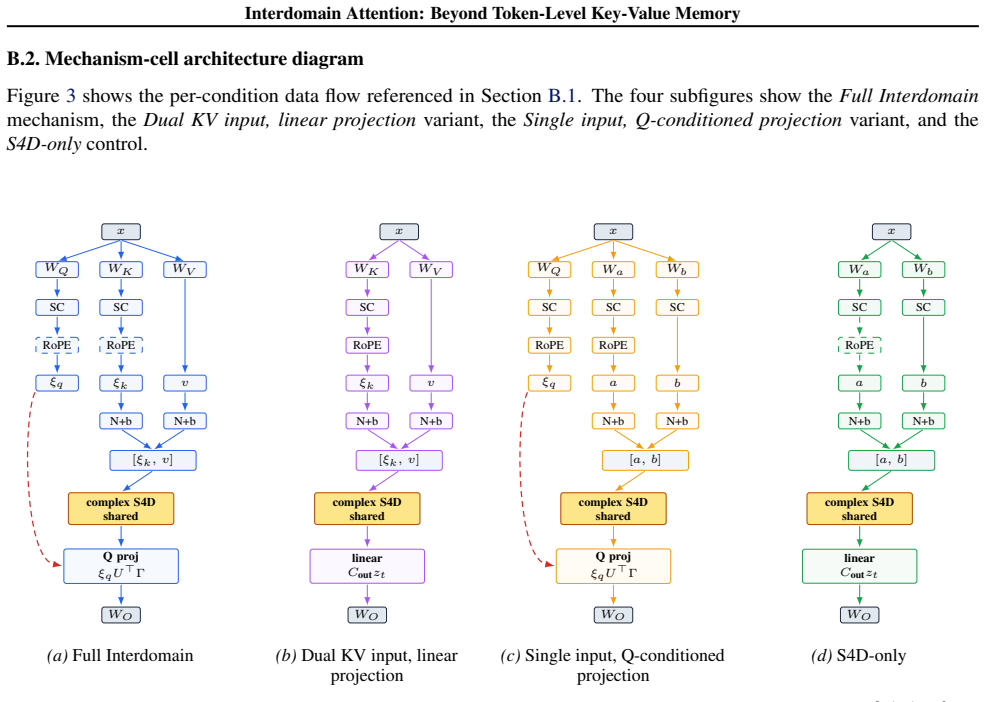
- Ablations show that the query-conditioned projection step accounts for most of the observed gain.
Where Pith is reading between the lines
- The same projection idea could be applied to other kernel approximations or to recurrent cores besides the SSM used here.
- Hybrid layers that mix standard attention blocks with Interdomain Attention blocks might further improve long-context efficiency.
- The fixed-state design removes the need for a growing KV cache while retaining a form of content-based addressing.
Load-bearing premise
An attention kernel approximated by a finite feature map, when its keys and values are projected onto SSM basis functions, still lets each query recover query-conditioned attention to those compressed coefficients.
What would settle it
A 1.3B-parameter run with the same training recipe in which Interdomain Attention fails to beat the softmax baseline on validation perplexity or on the eight-task commonsense suite.
Figures
read the original abstract
Transformers and deep state space models (SSMs) sit at opposite ends of a basic design choice: attention routes each query through a growing key-value (KV) cache by content-based matching at quadratic cost, while deep SSMs compress context into a fixed-size recurrent state that is not directly addressed by query-key matching. We propose Interdomain Attention, which integrates an SSM into an attention module through kernel methods: an attention kernel is approximated by a finite feature map, the resulting key features and values are projected onto a shared set of basis functions maintained by a single SSM recurrence, and each query attends to the compressed coefficients through its own feature map, recovering query-conditioned attention over a fixed-size state. The scalable layer is a learned relaxation of this derivation, and we validate its components through ablations. In a 125M to 1.3B autoregressive language-modeling study on FineWeb-Edu at matched recurrent-state budget, Interdomain Attention improves on an SSM token mixer at every scale, surpasses a same-recipe softmax baseline at 1.3B on validation perplexity and on the eight-task commonsense suite, and inherits the length-flat behavior of its fixed-state core out to 3.5x the training context. Ablations indicate that the query-conditioned projection is the main source of the gain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Interdomain Attention to integrate state-space models into attention layers via kernel methods: an attention kernel is approximated by a finite feature map, keys and values are projected onto basis functions maintained by a single SSM recurrence, and each query attends over the resulting compressed coefficients through its own feature map. The scalable implementation is presented as a learned relaxation of this exact construction. In autoregressive language-modeling experiments on FineWeb-Edu with models ranging from 125M to 1.3B parameters at matched recurrent-state budget, the method is reported to improve over an SSM token mixer at every scale, to surpass a same-recipe softmax baseline at 1.3B on validation perplexity and an eight-task commonsense suite, and to retain the length-flat extrapolation behavior of its fixed-state core out to 3.5 imes the training context. Ablations are said to attribute the gains primarily to the query-conditioned projection.
Significance. If the empirical results prove robust, the work supplies a kernel-derived route for injecting content-based addressing into fixed-size recurrent states, offering a hybrid motif that could improve both efficiency and extrapolation in long-context modeling. The explicit separation between the exact derivation and its learned relaxation, together with the reported length-flat behavior, would constitute a concrete architectural contribution if the supporting evidence is made reproducible.
major comments (2)
- [Abstract] Abstract (empirical study paragraph): the central performance claims—outperformance of the SSM mixer at all scales and of the softmax baseline at 1.3B—are presented without any description of training procedures, hyperparameter search protocol, statistical significance testing, or data filtering. Because these claims constitute the primary evidence for the method’s utility, the absence of such details renders the results uninspectable and load-bearing for the manuscript’s conclusions.
- [Abstract] Abstract (derivation and relaxation sentence): the text states that the scalable layer is a learned relaxation of the kernel-derived construction, yet provides neither the exact equations for the finite-feature-map projection onto the SSM basis nor the precise form of the relaxation. Without these, it is impossible to determine how closely the implemented layer follows the claimed query-conditioned attention over compressed coefficients, which is the mechanistic justification for the reported gains.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments identify important gaps in the abstract's presentation of experimental details and the derivation. We address each below and will revise the manuscript accordingly to improve clarity and inspectability while preserving the core contribution.
read point-by-point responses
-
Referee: [Abstract] Abstract (empirical study paragraph): the central performance claims—outperformance of the SSM mixer at all scales and of the softmax baseline at 1.3B—are presented without any description of training procedures, hyperparameter search protocol, statistical significance testing, or data filtering. Because these claims constitute the primary evidence for the method’s utility, the absence of such details renders the results uninspectable and load-bearing for the manuscript’s conclusions.
Authors: We agree that the abstract's empirical claims would benefit from greater transparency. In the revised manuscript we will expand the experimental setup section (currently Section 5) to explicitly detail the FineWeb-Edu preprocessing and filtering steps, the hyperparameter search protocol (including learning rate schedules, batch sizes, and optimizer choices), the number of random seeds used, and any statistical testing performed. Because abstracts have strict length limits, we will add a concise pointer sentence in the abstract directing readers to this expanded section and will include a short methods summary paragraph immediately after the abstract in the camera-ready version. revision: yes
-
Referee: [Abstract] Abstract (derivation and relaxation sentence): the text states that the scalable layer is a learned relaxation of the kernel-derived construction, yet provides neither the exact equations for the finite-feature-map projection onto the SSM basis nor the precise form of the relaxation. Without these, it is impossible to determine how closely the implemented layer follows the claimed query-conditioned attention over compressed coefficients, which is the mechanistic justification for the reported gains.
Authors: The exact finite-feature-map construction, the projection of keys/values onto the SSM-maintained basis functions, and the learned relaxation (including the specific parameterization that replaces the exact kernel with a trainable module) are derived in Section 3 and implemented in Section 4. We will revise the abstract sentence to include a parenthetical reference to these sections and, space permitting, a one-line high-level equation sketch. This will make the connection between the kernel derivation and the deployed layer explicit without altering the abstract's length substantially. revision: partial
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents a kernel-based derivation for Interdomain Attention that integrates an SSM into an attention module via finite feature map approximation of the attention kernel, projection of key features and values onto SSM-maintained basis functions, and query-conditioned attention over the compressed coefficients. It explicitly states that the scalable layer is a learned relaxation of this derivation, with components validated through ablations. The reported gains on language modeling (125M–1.3B scales, matched recurrent-state budget) and length extrapolation are obtained from the learned model and separate empirical tests on FineWeb-Edu and downstream tasks; no equation reduces these gains to quantities defined by the same fitted parameters by construction, and no load-bearing self-citations or uniqueness theorems are invoked in the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameters of the learned relaxation layer
axioms (2)
- standard math Attention kernels can be approximated by finite feature maps
- domain assumption A single SSM recurrence can maintain a shared set of basis functions for projected keys and values
Reference graph
Works this paper leans on
-
[1]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Association for Computational Linguistics. doi: 10.18653/v1/N19-1300. Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try ARC, the AI2 reasoning challenge, 2018. URL https://arxiv.org/abs/ 1803.05457. Dao, T. Flashattention-2: Faster attention with better paral- lelism a...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/n19-1300 2018
-
[2]
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
doi: 10.18653/V1/2021.NAACL-MAIN.365. De, S., Smith, S. L., Fernando, A., Botev, A., Cristian- Muraru, G., Gu, A., Haroun, R., Berrada, L., Chen, Y ., Srinivasan, S., Desjardins, G., Doucet, A., Budden, D., Teh, Y . W., Pascanu, R., Freitas, N. D., and Gulcehre, C. Griffin: Mixing gated linear recurrences with lo- cal attention for efficient language mode...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2021.naacl-main.365 2021
-
[3]
Enriching word vectors with subword information , volume =
doi: 10.1162/tacl a 00023. Lahoti, A., Li, K., Chen, B., Wang, C., Bick, A., Kolter, J. Z., Dao, T., and Gu, A. Mamba-3: Improved sequence modeling using state space principles. InThe Fourteenth International Conference on Learning Representations, 2026. L´azaro-Gredilla, M. and Figueiras-Vidal, A. R. Inter- domain gaussian processes for sparse inference ...
work page internal anchor Pith review doi:10.1162/tacl 2026
-
[4]
Fast Transformer Decoding: One Write-Head is All You Need
Association for Computational Linguistics. doi: 10.18653/v1/P16-1144. Penedo, G., Kydl´ıˇcek, H., allal, L. B., Lozhkov, A., Mitchell, M., Raffel, C., V on Werra, L., and Wolf, T. The fineweb datasets: Decanting the web for the finest text data at scale. In Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., and Zhang, C. (eds.),Ad-...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/p16-1144 2024
-
[5]
Association for Computational Linguistics, 2021. doi: 10.18653/V1/2021.NAACL-MAIN.472. 11 Interdomain Attention: Beyond Token-Level Key-Value Memory A. Implementation and Training Details A.1. SSM kernel backends The FFT convolution computes the S4D recurrence (Gu et al., 2022b;a) via O(NlogN) transforms per input channel and state dimension. The sequenti...
-
[6]
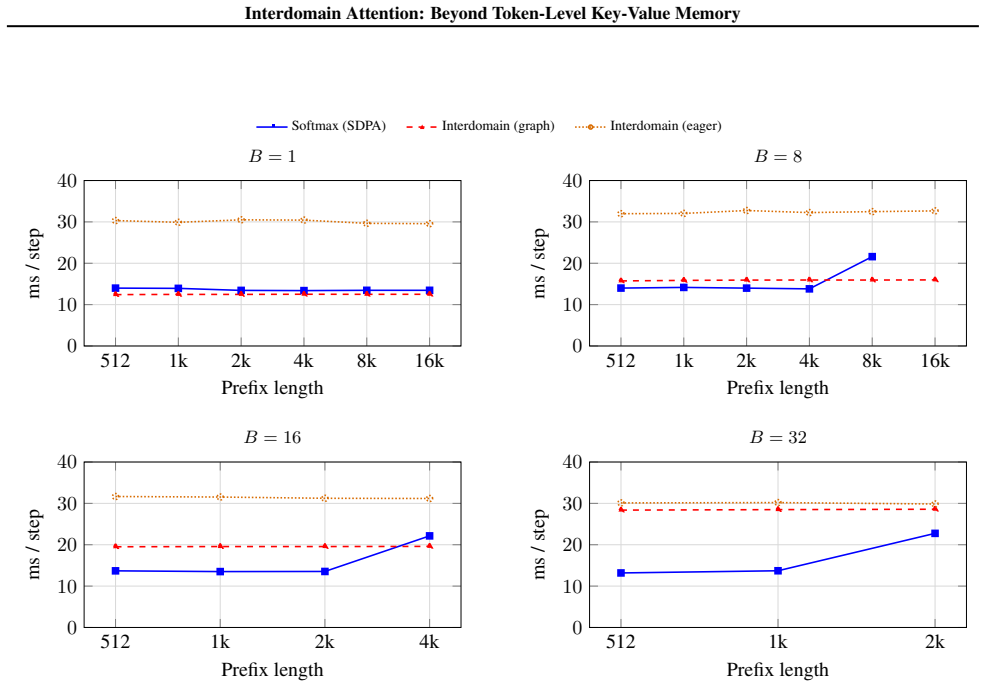
Softmax decode requires a dynamically growing KV cache and is not directly graph-capturable
CUDA graph compatibility.The fixed-shape SSM state lets the entire decode body be captured into a single static graph and replayed once per token, removing the per-step Python and kernel-launch overhead. Softmax decode requires a dynamically growing KV cache and is not directly graph-capturable
-
[7]
Range” is the min–max over the prefix lengths that fit; “max-fit L
Lower peak prefill memory via chunking.Because the recurrent state has a size independent of prefix length, prefill can be processed in fixed-size chunks of C=2048 tokens with the running state retained and per-chunk activations released. This lets interdomain decode reach(B, L)cells where softmax exhausts the GPU memory. Protocol.Prefill L tokens → captu...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.