PACT: Proactive Asking for Continual Task Assistance in Human-Robot Collaboration
Pith reviewed 2026-06-30 13:31 UTC · model grok-4.3
The pith
PACT lets robots decide when to ask for clarification using past interactions to improve long-term assistance accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
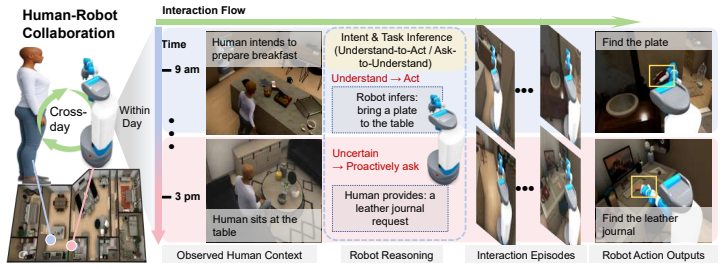
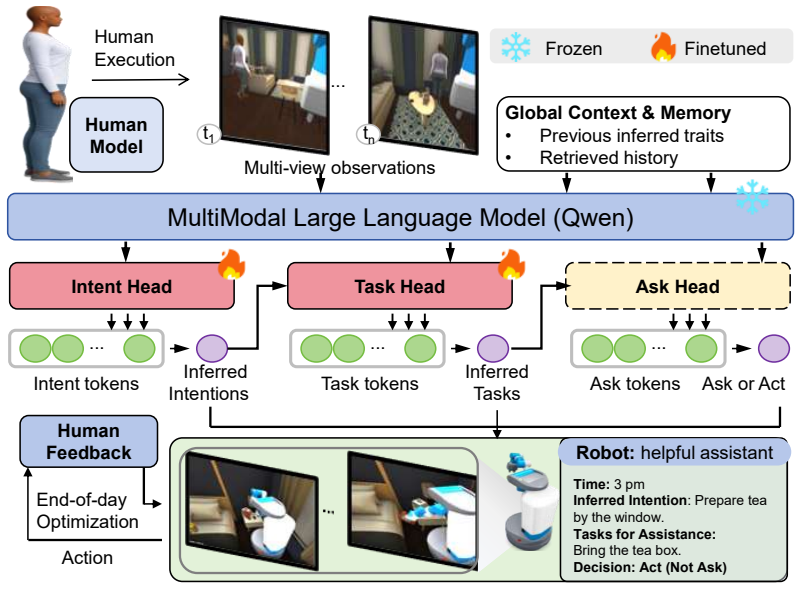
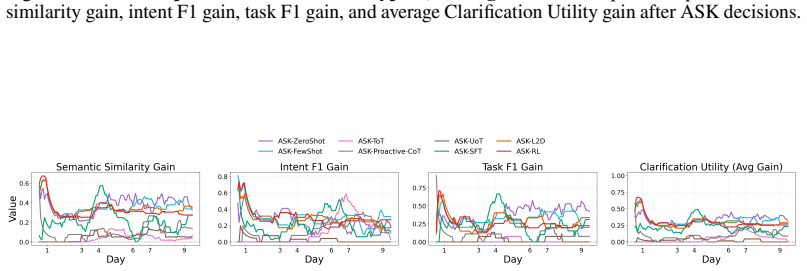
PACT is an ask-or-act framework that determines whether clarification should be sought before taking action by leveraging current observations together with accumulated interaction history to evaluate contextual sufficiency, enabling the robot to provide more reliable assistance and progressively adapt to the user over time; its primary learned instantiation uses reinforcement learning, and experiments in multi-day embodied collaboration scenarios show it improves both assistance accuracy and clarification utility compared with passive inference baselines.
What carries the argument
The ask-or-act decision that evaluates contextual sufficiency from observations and history to choose between seeking clarification or acting.
If this is right
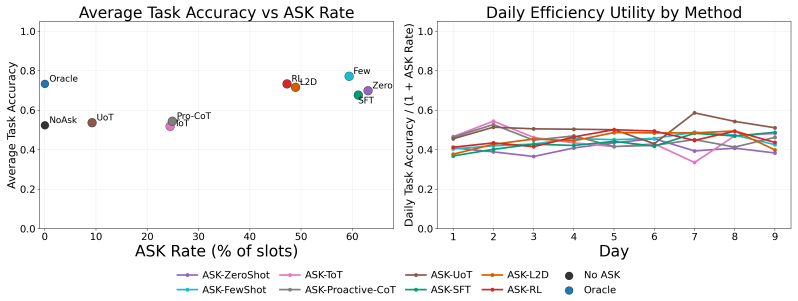
- Robots achieve higher assistance accuracy than passive inference methods in partial-observation settings.
- Clarification utility improves by balancing accuracy gains against the frequency of requests.
- The robot adapts progressively to unknown user traits across multiple days of collaboration.
- Alternative decision mechanisms can be compared directly under the same ask-or-act structure.
Where Pith is reading between the lines
- The same decision structure could reduce repeated errors in other uncertain collaborative settings such as home assistants.
- Over longer time scales, fewer incorrect actions might increase user willingness to rely on the robot.
- The framework could be tested with changing user preferences to check whether history still supports good ask-or-act choices.
Load-bearing premise
Current observations together with accumulated interaction history are sufficient to judge contextual sufficiency for reliable ask-or-act decisions.
What would settle it
A multi-day trial in which PACT's ask decisions produce equal or lower assistance accuracy than a passive inference baseline that never asks.
Figures



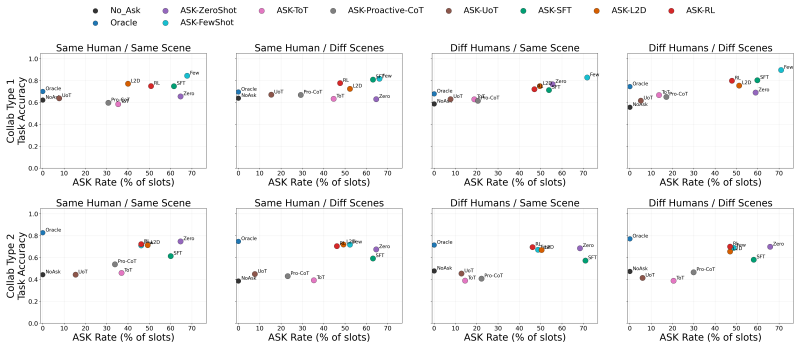
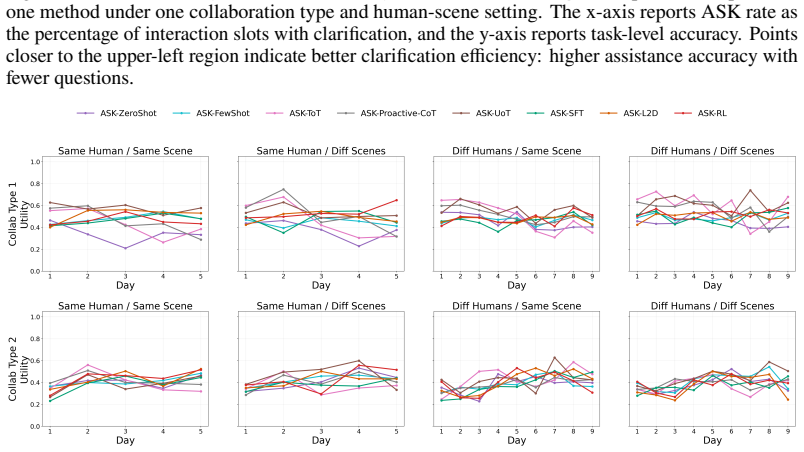
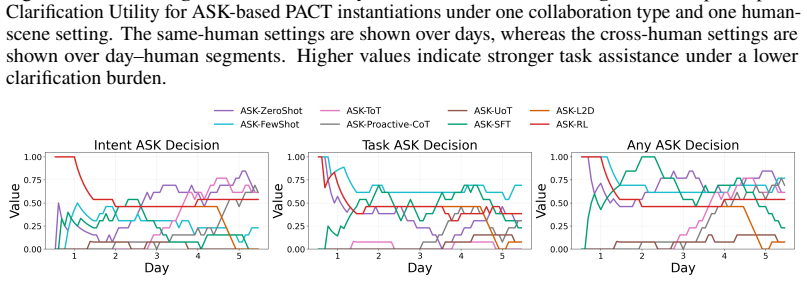
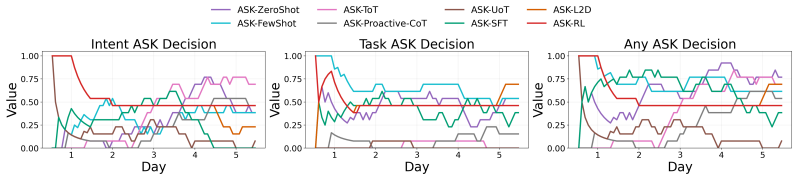
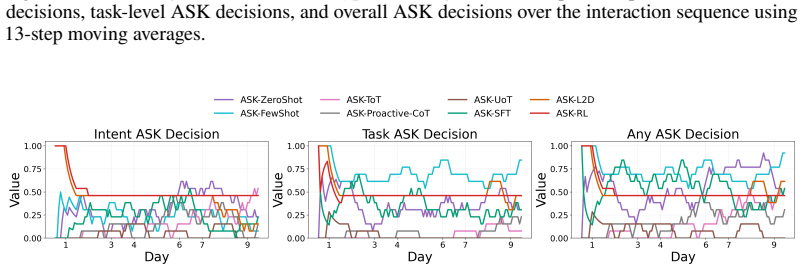
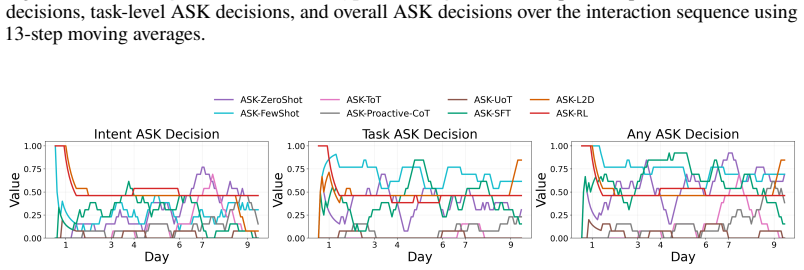
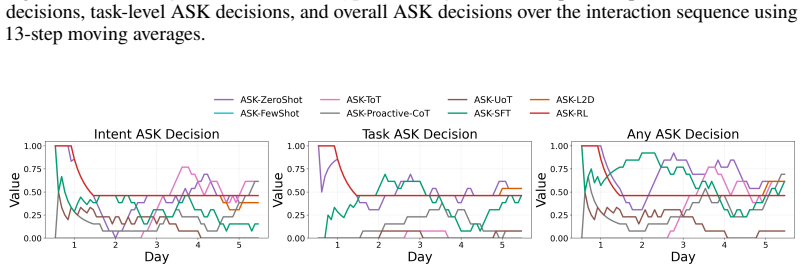
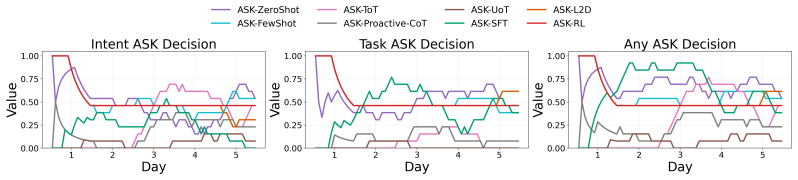
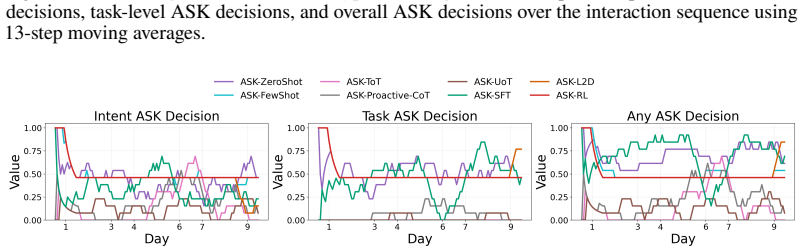
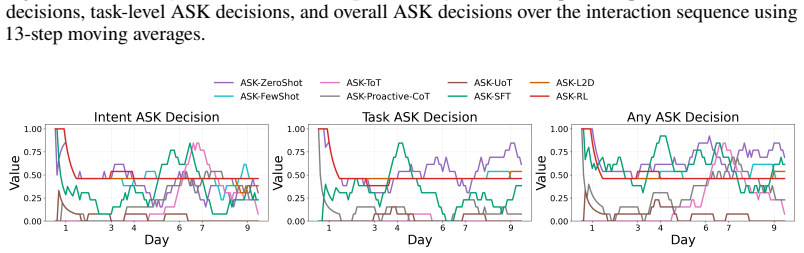
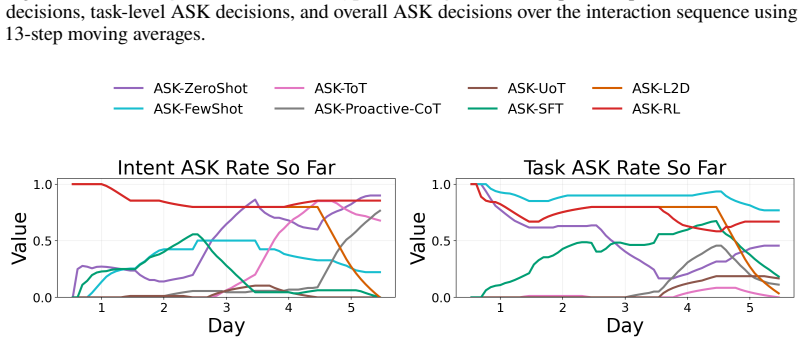
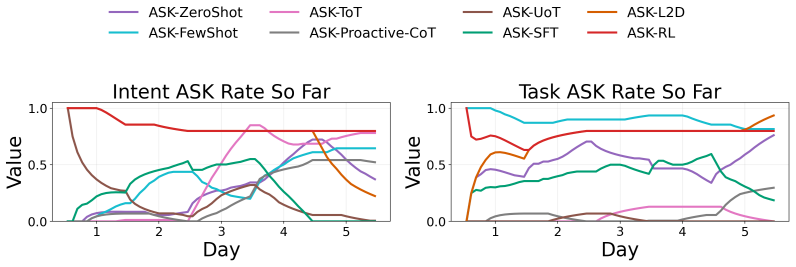
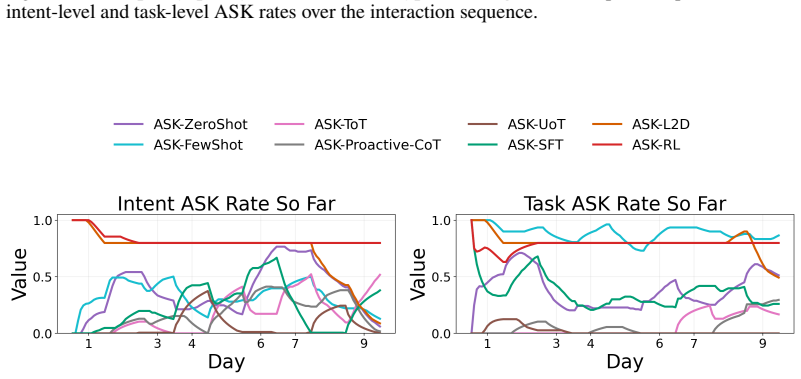
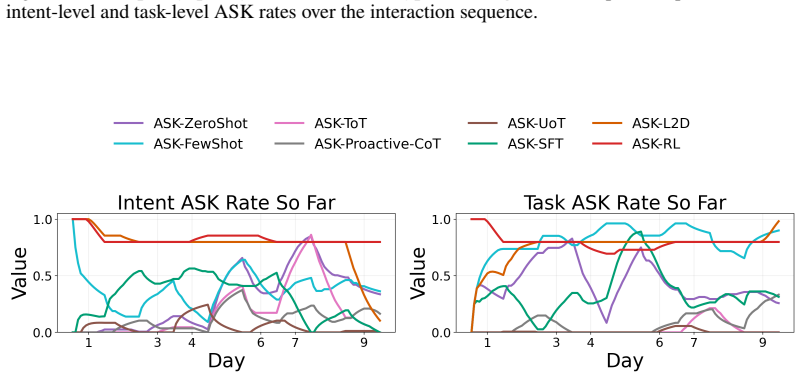
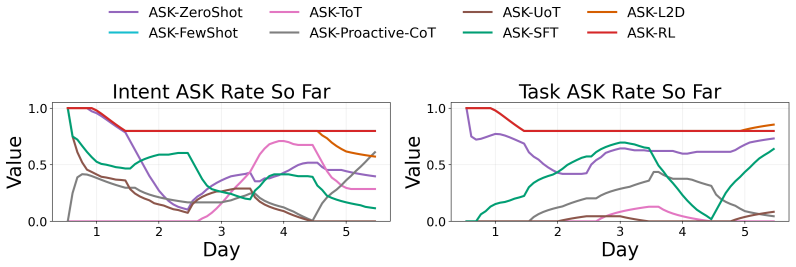
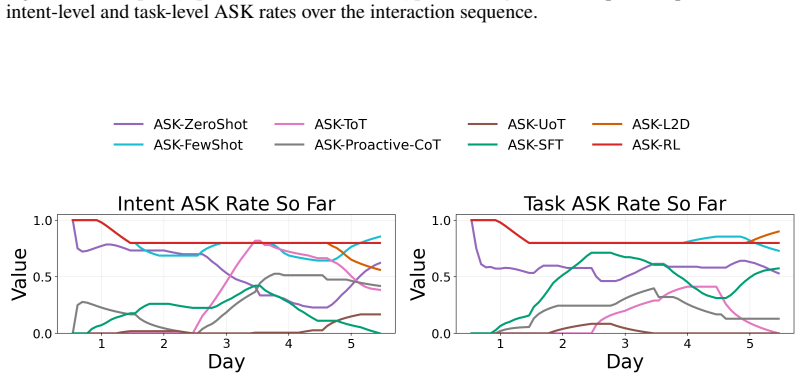
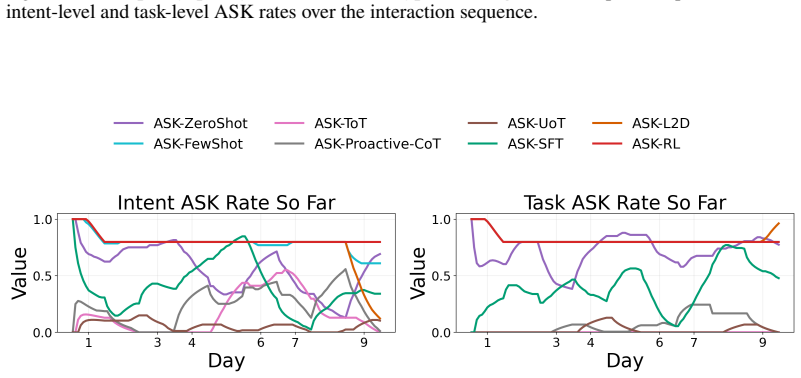
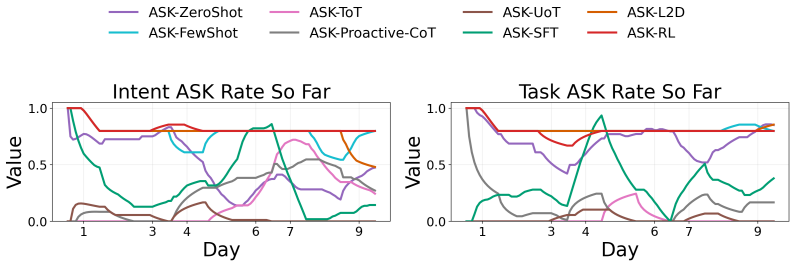
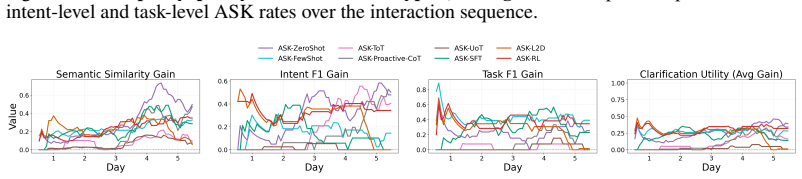
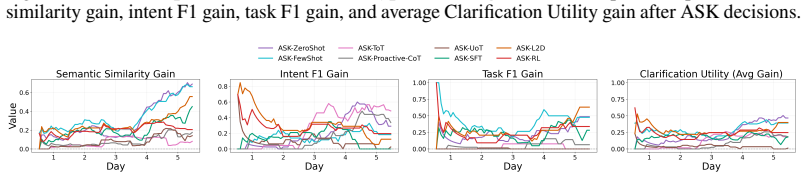
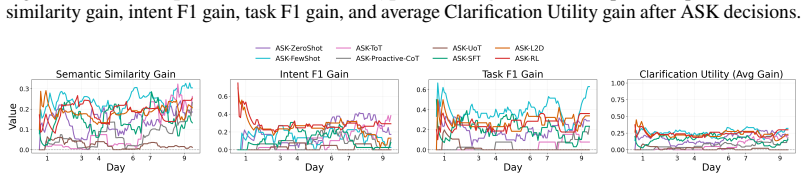
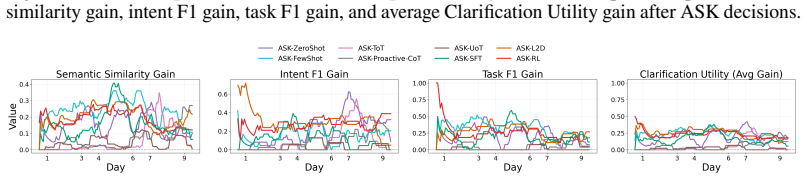

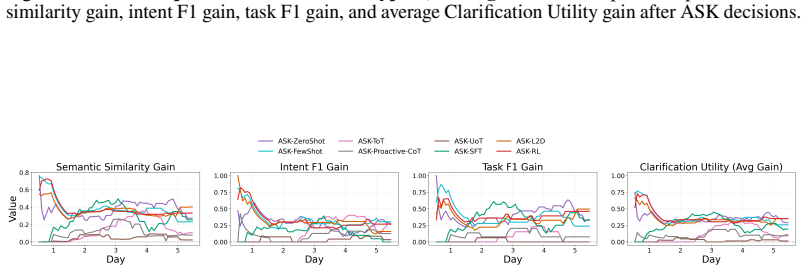
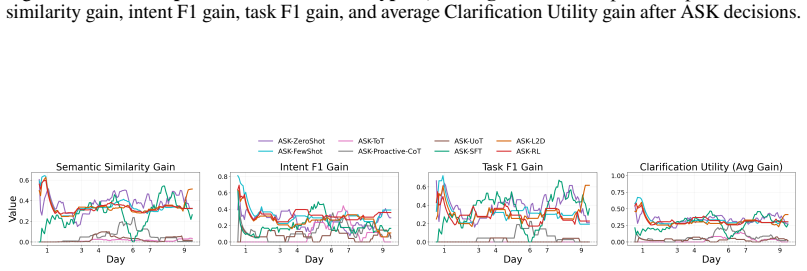
read the original abstract
Robotic assistants in long-term human-robot collaboration need to assist users under partial observations while leveraging cross-day interaction history. However, human traits and routines are often unknown at the beginning of collaboration, making passive infer-then-act assistance ineffective and inefficient. To address this challenge, we study a cross-day proactive asking setting for continual task assistance and propose PACT (Proactive Asking for Continual Task Assistance), an ask-or-act framework that determines whether clarification should be sought before taking action. PACT leverages current observations together with accumulated interaction history to evaluate contextual sufficiency, enabling the robot to provide more reliable assistance and progressively adapt to the user over time. We implement its primary learned instantiation using reinforcement learning and evaluate alternative instantiations under the same framework. To assess such behavior, we further introduce a clarification utility metric that quantifies the trade-off between assistance accuracy and the frequency of clarification requests. Experiments in multi-day embodied collaboration scenarios demonstrate that, compared with passive inference baselines, PACT consistently improves both assistance accuracy and clarification utility, highlighting the importance of proactive asking in continual human-robot collaboration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PACT, an ask-or-act framework for proactive clarification in cross-day human-robot collaboration. It uses RL (and alternative instantiations) to decide whether to seek clarification or act, based on current observations plus accumulated interaction history, to handle unknown user traits. A clarification utility metric is introduced to quantify accuracy-clarification trade-offs. Experiments in multi-day embodied scenarios claim consistent gains in assistance accuracy and utility over passive inference baselines.
Significance. If the experimental support holds after clarification, the work addresses a practical gap in long-term HRC where passive inference fails under partial information and unknown routines. The proactive framework and utility metric could inform more adaptive robot policies; the multi-day setting is a strength for continual collaboration claims.
major comments (3)
- [§3, §4.1] §3 (PACT framework) and §4.1 (RL instantiation): the state representation fed to the RL policy is not specified, nor is the reward function that encodes the accuracy-vs-clarification trade-off. These omissions are load-bearing because the central claim that 'current observations together with accumulated interaction history' suffice for reliable ask-or-act decisions cannot be evaluated or reproduced without them.
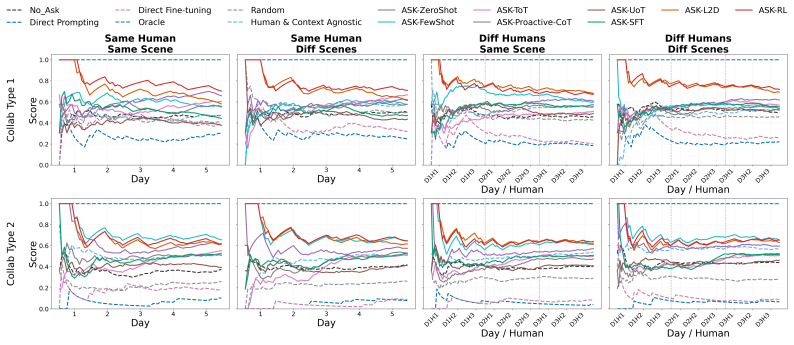
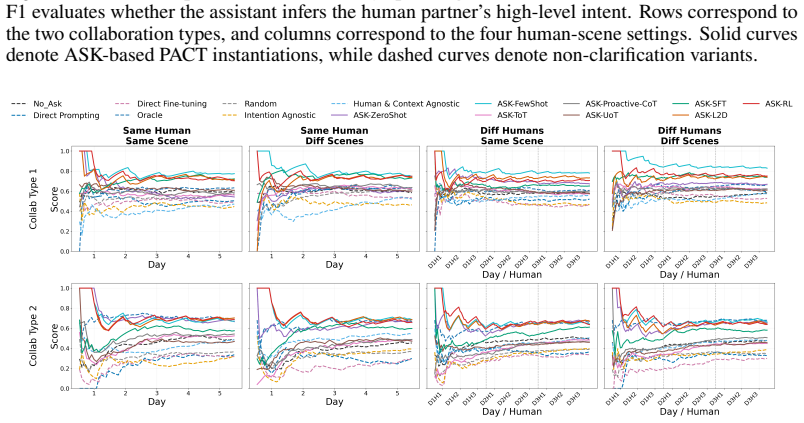
- [§4.3, Table 2] §4.3 (experiments) and Table 2: no ablation isolates the contribution of cross-day history versus single-day observations, and no statistical tests or confidence intervals are reported for the claimed 'consistent improvement.' This directly undermines the strongest claim that PACT outperforms passive baselines in multi-day scenarios.
- [§4.2] §4.2 (baselines): the passive inference baselines are described only at a high level; without explicit state representations or learning procedures matching those used in PACT, it is impossible to determine whether reported gains arise from the proactive mechanism or from unstated differences in feature engineering or data requirements.
minor comments (2)
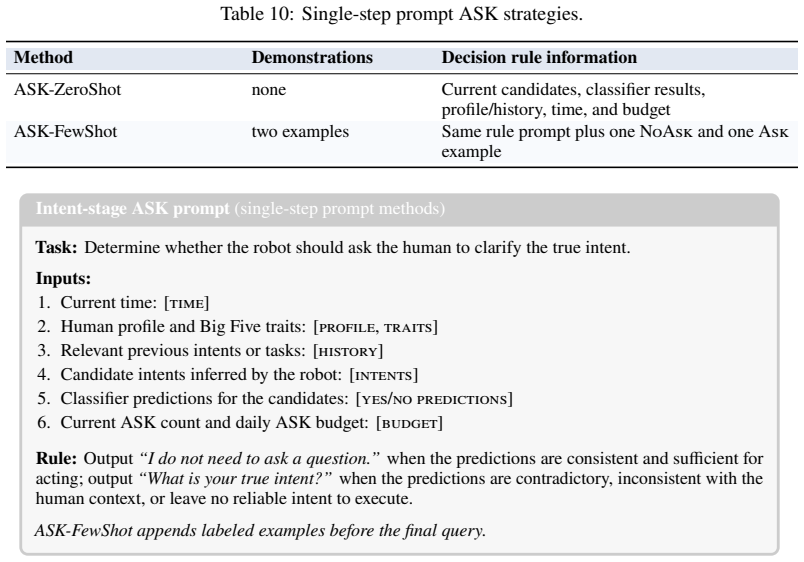
- [§3.3] The clarification utility metric is introduced without an explicit equation; adding a numbered equation would improve clarity when comparing to accuracy alone.
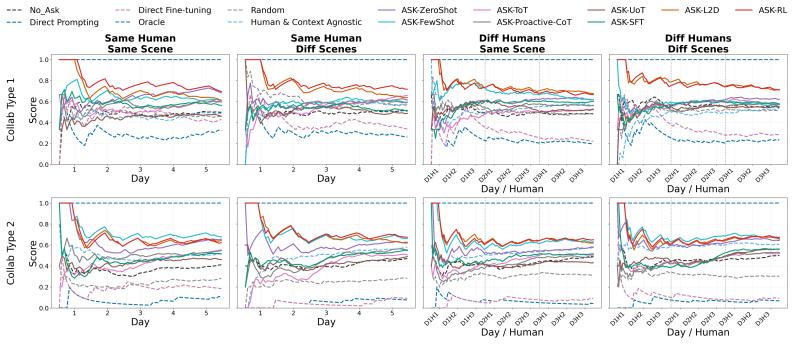
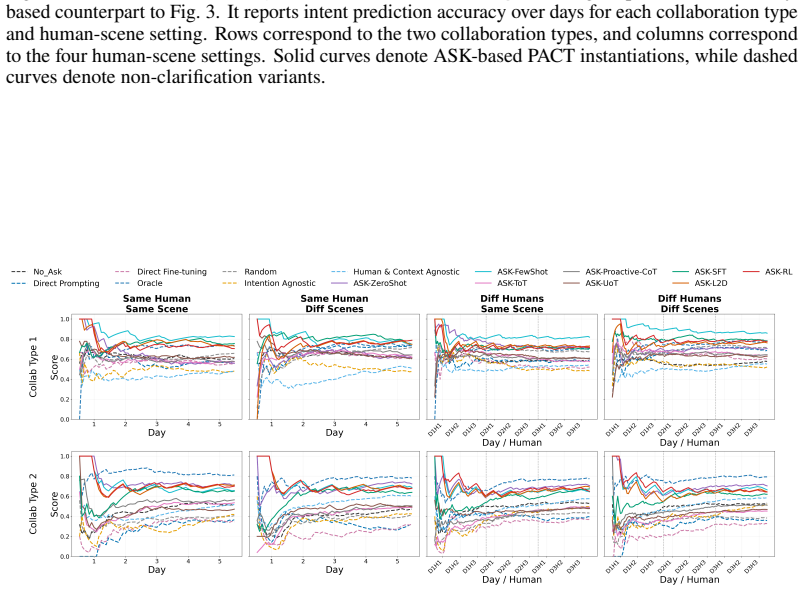
- [Figure 3] Figure 3 (example trajectories) would benefit from explicit annotation of ask versus act decisions to illustrate the policy behavior.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback. We address each of the major comments below and plan to revise the manuscript to improve clarity and rigor.
read point-by-point responses
-
Referee: [§3, §4.1] §3 (PACT framework) and §4.1 (RL instantiation): the state representation fed to the RL policy is not specified, nor is the reward function that encodes the accuracy-vs-clarification trade-off. These omissions are load-bearing because the central claim that 'current observations together with accumulated interaction history' suffice for reliable ask-or-act decisions cannot be evaluated or reproduced without them.
Authors: We agree that explicit details on the state representation and reward function are essential for reproducibility. In the revised manuscript, we will provide a precise definition of the state as a vector combining current observations and interaction history features, along with the reward function that balances assistance accuracy with a cost for clarification requests. This will be added to Sections 3 and 4.1. revision: yes
-
Referee: [§4.3, Table 2] §4.3 (experiments) and Table 2: no ablation isolates the contribution of cross-day history versus single-day observations, and no statistical tests or confidence intervals are reported for the claimed 'consistent improvement.' This directly undermines the strongest claim that PACT outperforms passive baselines in multi-day scenarios.
Authors: We acknowledge these omissions in the experimental analysis. We will add an ablation study to isolate the effect of cross-day history and include statistical tests with confidence intervals in the revised Table 2 and Section 4.3 to support the claims of consistent improvement. revision: yes
-
Referee: [§4.2] §4.2 (baselines): the passive inference baselines are described only at a high level; without explicit state representations or learning procedures matching those used in PACT, it is impossible to determine whether reported gains arise from the proactive mechanism or from unstated differences in feature engineering or data requirements.
Authors: We will expand the description of the passive inference baselines in Section 4.2 to include their specific state representations, learning procedures, and how they process interaction history, ensuring they are comparable to PACT's setup. revision: yes
Circularity Check
No circularity; framework claims rest on experimental evaluation without derivation reductions
full rationale
The provided abstract and description present PACT as an RL-learned ask-or-act policy using observations plus history, with gains shown via multi-day experiments against passive baselines. No equations, state representations, reward functions, or derivations appear that would reduce any claimed prediction or sufficiency evaluation to a fitted parameter or self-citation by construction. The central assumption about contextual sufficiency is stated as an input to the framework rather than derived from it, and no self-citation chains or ansatzes are invoked in the text. This matches the default expectation of a non-circular empirical proposal paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nehaniv, and Kerstin Dautenhahn
Ali Ayub, Zachary De Francesco, Patrick Holthaus, Chrystopher L. Nehaniv, and Kerstin Dautenhahn. Continual learning through human-robot interaction: Human perceptions of a continual learning robot in repeated interactions.International Journal of Social Robotics, 17 (2):277–296, 2025. doi: 10.1007/s12369-025-01214-9
-
[2]
Berk Calli, Arjun Singh, Aaron Walsman, Siddhartha Srinivasa, Pieter Abbeel, and Aaron M. Dollar. The ycb object and model set: Towards common benchmarks for manipulation research. InProceedings of the IEEE International Conference on Advanced Robotics, pages 510–517, 2015
2015
-
[3]
ShiyeCao,JiwonMoon,YifanXu,AnqiLiu,andChien-MingHuang. Reframingconversational design in hri: Deliberate design with ai scaffolds.arXiv preprint arXiv:2601.12084, 2026
-
[4]
Matthew Chang, Gunjan Chhablani, Alexander Clegg, Mikael Dallaire Cote, Ruta Desai, Michal Hlavac, Vladimir Karashchuk, Jacob Krantz, Roozbeh Mottaghi, Priyam Parashar, et al. Partnr: A benchmark for planning and reasoning in embodied multi-agent tasks.arXiv preprint arXiv:2411.00081, 2024
-
[5]
Robotic task ambi- guity resolution via natural language interaction
Eugenio Chisari, Jan Ole Von Hartz, Fabien Despinoy, and Abhinav Valada. Robotic task ambi- guity resolution via natural language interaction. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 14821–14827. IEEE, 2025
2025
-
[6]
Prompting and evaluating large language models for proactive dialogues: Clarification, target-guided, and non-collaboration
YangDeng,LiziLiao,LiangChen,HongruWang,WenqiangLei,andTat-SengChua. Prompting and evaluating large language models for proactive dialogues: Clarification, target-guided, and non-collaboration. InFindings of the Association for Computational Linguistics: EMNLP 2023, 2023
2023
-
[7]
Shaping human-ai collaboration: Varied scaffolding levels in co-writing with language models
Paramveer S Dhillon, Somayeh Molaei, Jiaqi Li, Maximilian Golub, Shaochun Zheng, and Lionel Peter Robert. Shaping human-ai collaboration: Varied scaffolding levels in co-writing with language models. InProceedings of the 2024 CHI conference on human factors in computing systems, pages 1–18, 2024
2024
-
[8]
and Breazeal, Cynthia and Park, Hae Won , month = mar, year =
Fethiye Irmak Dogan, Amir Hossein Saffari, Julian Hough, and Iolanda Leite. Asking follow- up clarifications to resolve ambiguities in human-robot conversation. InProceedings of the ACM/IEEE International Conference on Human-Robot Interaction (HRI), pages 461–469, 2022. doi: 10.1109/HRI53351.2022.9889368
-
[9]
Overcookedv2: Rethinking overcooked for zero-shot coordination.arXiv preprint arXiv:2503.17821, 2025
TobiasGessler,TinDizdarevic,AniCalinescu,BenjaminEllis,AndreiLupu,andJakobNicolaus Foerster. Overcookedv2: Rethinking overcooked for zero-shot coordination.arXiv preprint arXiv:2503.17821, 2025
-
[10]
Uncertainty of thoughts: Uncertainty-aware planning enhances information seeking in large language models
ZhiyuanHu,ChuminLiu,XidongFeng,YilunZhao,See-KiongNg,AnhTuanLuu,JunxianHe, Pang Wei Koh, and Bryan Hooi. Uncertainty of thoughts: Uncertainty-aware planning enhances information seeking in large language models. InAdvances in Neural Information Processing Systems, 2024
2024
-
[11]
’it was 80% me, 20% ai’: Seeking authenticity in co-writing with large language models
AngelHsing-ChiHwang,QVeraLiao,SuLinBlodgett,AlexandraOlteanu,andAdamTrischler. ’it was 80% me, 20% ai’: Seeking authenticity in co-writing with large language models. Proceedings of the ACM on Human-Computer Interaction, 9(2):1–41, 2025
2025
-
[12]
A review of human intention recognition frameworks in industrial collaborative robotics.Robotics, 14 (12):174, 2025
Mokone Kekana, Shengzhi Du, Nico Steyn, Abderraouf Benali, and Halim Djerroud. A review of human intention recognition frameworks in industrial collaborative robotics.Robotics, 14 (12):174, 2025
2025
-
[13]
Chang, and Manolis Savva
Mukul Khanna, Yongsen Mao, Hanxiao Jiang, Sanjay Haresh, Brennan Shacklett, Dhruv Batra, Alexander Clegg, Eric Undersander, Angel X. Chang, and Manolis Savva. Habitat synthetic scenes dataset (hssd-200): An analysis of 3d scene scale and realism tradeoffs for objectgoal navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Re...
2024
-
[14]
Learning to cooperate with humans using generative agents.Advances in Neural Information Processing Systems, 37:60061–60087, 2024
Yancheng Liang, Daphne Chen, Abhishek Gupta, Simon S Du, and Natasha Jaques. Learning to cooperate with humans using generative agents.Advances in Neural Information Processing Systems, 37:60061–60087, 2024
2024
-
[15]
Motion-x: A large-scale 3d expressive whole-body human motion dataset
JingLin,AilingZeng,ShunlinLu,YuanhaoCai,RuimaoZhang,HaoqianWang,andLeiZhang. Motion-x: A large-scale 3d expressive whole-body human motion dataset. InAdvances in Neural Information Processing Systems, 2023
2023
-
[16]
Thinkbot: Embodied instruction following with thought chain reasoning
Guanxing Lu, Ziwei Wang, Changliu Liu, Jiwen Lu, and Yansong Tang. Thinkbot: Embodied instruction following with thought chain reasoning. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[17]
Spatialpin: Enhancing spatial reasoning capabilities of vision-language models through prompting and interacting 3d priors
Chenyang Ma, Kai Lu, Ta-Ying Cheng, Niki Trigoni, and Andrew Markham. Spatialpin: Enhancing spatial reasoning capabilities of vision-language models through prompting and interacting 3d priors. InProceedings of the Conference on Neural Information Processing Systems (NeurIPS), 2024
2024
-
[18]
Coopera: Continual open-ended human-robot assistance.arXiv preprint arXiv:2510.23495, 2025
Chenyang Ma, Kai Lu, Ruta Desai, Xavier Puig, Andrew Markham, and Niki Trigoni. Coopera: Continual open-ended human-robot assistance.arXiv preprint arXiv:2510.23495, 2025
-
[19]
Predict responsibly: Improving fairness and accuracy by learning to defer
David Madras, Toni Pitassi, and Richard Zemel. Predict responsibly: Improving fairness and accuracy by learning to defer. InAdvances in Neural Information Processing Systems, 2018
2018
-
[20]
Troje, Gerard Pons-Moll, and Michael J
Naureen Mahmood, Nima Ghorbani, Nikolaus F. Troje, Gerard Pons-Moll, and Michael J. Black. Amass: Archive of motion capture as surface shapes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5442–5451, 2019
2019
-
[21]
Kayla Matheus, Rebecca Ramnauth, Brian Scassellati, and Nicole Salomons. Long-term interactions with social robots: Trends, insights, and recommendations.ACM Transactions on Human-Robot Interaction, 14(3):1–42, 2025. doi: 10.1145/3729539
-
[22]
Situated in- struction following
So Yeon Min, Xavi Puig, Devendra Singh Chaplot, Tsung-Yen Yang, Akshara Rai, Priyam Parashar, Ruslan Salakhutdinov, Yonatan Bisk, and Roozbeh Mottaghi. Situated in- struction following. InComputer Vision – ECCV 2024, pages 202–228, 2024. doi: 10.1007/978-3-031-73030-6_12
-
[23]
Ruaridh Mon-Williams, Gen Li, Ran Long, Wenqian Du, and Christopher G. Lucas. Embodied large language models enable robots to complete complex tasks in unpredictable environments. Nature Machine Intelligence, 7:592–601, 2025
2025
-
[24]
Consistent estimators for learning to defer to an expert
Hussein Mozannar and David Sontag. Consistent estimators for learning to defer to an expert. InInternational Conference on Machine Learning, pages 7076–7087, 2020
2020
-
[25]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, JanLeike,andRyanLowe. Traininglanguagemodelstofollowinstructionswithhumanfeedback. InAdvanc...
2022
-
[26]
Habitat 3.0: A co-habitat for humans, avatars, and robots
Xavier Puig, Eric Undersander, Andrew Szot, Mikael Dallaire Cote, Tsung-Yen Yang, Ruslan Partsey, Ruta Desai, Alexander Clegg, Michal Hlavac, So Yeon Min, Vladimir Vondrus, Theophile Gervet, Vincent-Pierre Berges, John Turner, Oleksandr Maksymets, Zsolt Kira, Mrinal Kalakrishnan, Jitendra Malik, Devendra Singh Chaplot, Unnat Jain, Dhruv Batra, Akshara Rai...
2024
-
[27]
Grounding multimodal llms to embodied agents that ask for help with reinforcement learning
Ram Ramrakhya, Matthew Chang, Xavier Puig, Ruta Desai, Zsolt Kira, and Roozbeh Mottaghi. Grounding multimodal llms to embodied agents that ask for help with reinforcement learning. arXiv preprint arXiv:2504.00907, 2025
-
[28]
Ask4help: Learning to leverage an expert for embodied tasks
Kunal Pratap Singh, Luca Weihs, Alvaro Herrasti, Jonghyun Choi, Aniruddha Kembhavi, and Roozbeh Mottaghi. Ask4help: Learning to leverage an expert for embodied tasks. InAdvances in Neural Information Processing Systems, 2022. 11
2022
-
[29]
Applying general turn-taking models to conversational human-robot interaction
G Skantze and B Irfan. Applying general turn-taking models to conversational human-robot interaction. in 2025 acm. InIEEE international conference on human-robot interaction, 2025
2025
-
[30]
Collaborative instance object navigation: Leveraging uncertainty-awareness to minimize human-agent dialogues
Francesco Taioli, Edoardo Zorzi, Gianni Franchi, Alberto Castellini, Alessandro Farinelli, Marco Cristani, and Yiming Wang. Collaborative instance object navigation: Leveraging uncertainty-awareness to minimize human-agent dialogues. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18781–18792, 2025
2025
-
[31]
Asking the right question at the right time: Human and modeluncertaintyguidancetoaskclarificationquestions
Alberto Testoni and Raquel Fernández. Asking the right question at the right time: Human and modeluncertaintyguidancetoaskclarificationquestions. InProceedingsofthe18thConference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 258–275, 2024
2024
-
[32]
When combinations of humans and ai are useful: A systematic review and meta-analysis.Nature Human Behaviour, 8(12): 2293–2303, 2024
Michelle Vaccaro, Abdullah Almaatouq, and Thomas Malone. When combinations of humans and ai are useful: A systematic review and meta-analysis.Nature Human Behaviour, 8(12): 2293–2303, 2024
2024
-
[33]
it felt like having a second mind
Qian Wan, Siying Hu, Yu Zhang, Piaohong Wang, Bo Wen, and Zhicong Lu. " it felt like having a second mind": Investigating human-ai co-creativity in prewriting with large language models. Proceedings of the ACM on human-computer interaction, 8(CSCW1):1–26, 2024
2024
-
[34]
InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 25474–25482, 2025
YanmingWan,YueWu,YipingWang,JiayuanMao,andNatashaJaques.Inferhuman’sintentions before following natural language instructions. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 25474–25482, 2025
2025
-
[35]
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. InAdvances in Neural Information Processing Systems, 2020
2020
-
[36]
Affordbot: 3d fine-grained embodied reasoning via multimodal large language models
Xinyi Wang, Xun Yang, Yanlong Xu, Yuchen Wu, Zhen Li, and Na Zhao. Affordbot: 3d fine-grained embodied reasoning via multimodal large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[37]
Fetch & freight: Standard platforms for service robot applications
Melonee Wise, Michael Ferguson, Derek King, Eric Diehr, and David Dymesich. Fetch & freight: Standard platforms for service robot applications. InWorkshop on Autonomous Mobile Service Robots, held at the International Joint Conference on Artificial Intelligence, pages 1–6, 2016
2016
-
[38]
Fang, J., Jiang, H., Wang, K., Ma, Y ., Shi, J., Wang, X., He, X., and Chua, T
Siheng Xiong, Ali Payani, Yuan Yang, and Faramarz Fekri. Deliberate reasoning in language models as structure-aware planning with an accurate world model. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 31900–31931. Association for Computational Linguistics, July 2025. doi: 10.18653/...
-
[39]
Adaptive Information Control for Search-Augmented LLM Reasoning
Siheng Xiong, Oguzhan Gungordu, Blair Johnson, James C. Kerce, and Faramarz Fekri. Scaling search-augmented llm reasoning via adaptive information control.arXiv preprint arXiv:2602.01672, 2026. URLhttps://arxiv.org/abs/2602.01672
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Enhancing language model reasoning with structured multi-level modeling
Siheng Xiong, Ali Payani, and Faramarz Fekri. Enhancing language model reasoning with structured multi-level modeling. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=PlkzZhqBCd
2026
-
[41]
Embodiedbench: Comprehensive benchmarking multi-modal large language models for vision-driven embodied agents
RuiYang,HanyangChen,JunyuZhang,MarkZhao,ChengQian,KangruiWang,QinengWang, Teja Venkat Koripella, MarziyehMovahedi, Manling Li, etal. Embodiedbench: Comprehensive benchmarking multi-modal large language models for vision-driven embodied agents. In International Conference on Machine Learning, pages 70576–70631. PMLR, 2025
2025
-
[42]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In Advances in Neural Information Processing Systems, 2023
2023
-
[43]
LanceYing,JasonXinyuLiu,ShivamAarya,YiziruiFang,StefanieTellex,JoshuaB.Tenenbaum, and Tianmin Shu. Siftom: Robust spoken instruction following through theory of mind.arXiv preprint arXiv:2409.10849, 2024. 12
-
[44]
Mixed-initiative dialog for human-robot collaborative manipulation
Albert Yu, Chengshu Li, Luca Macesanu, Arnav Balaji, Ruchira Ray, Raymond Mooney, and Roberto Martín-Martín. Mixed-initiative dialog for human-robot collaborative manipulation. arXiv preprint arXiv:2508.05535, 2025
-
[45]
Multiagentbench: Evaluating the collaboration and competition of llm agents
Kunlun Zhu, Hongyi Du, Zhaochen Hong, Xiaocheng Yang, Shuyi Guo, Daisy Zhe Wang, Zhenhailong Wang, Cheng Qian, Robert Tang, Heng Ji, et al. Multiagentbench: Evaluating the collaboration and competition of llm agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8580–8622, 2025. 13...
2025
-
[46]
Current time: [time]
-
[47]
Human profile and Big Five traits: [profile,traits]
-
[48]
Relevant previous intents or tasks: [history]
-
[49]
Candidate intents inferred by the robot: [intents]
-
[50]
Classifier predictions for the candidates: [yes/no predictions]
-
[51]
I do not need to ask a question
Current ASK count and daily ASK budget: [budget] Rule:Output“I do not need to ask a question.”when the predictions are consistent and sufficient for acting; output“What is your true intent?”when the predictions are contradictory, inconsistent with the human context, or leave no reliable intent to execute. ASK-FewShot appends labeled examples before the fi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.