Learning Laplacian Eigenspace with Mass-Aware Neural Operators on Point Clouds
Pith reviewed 2026-06-30 14:47 UTC · model grok-4.3
The pith
NEO learns a redundant basis for the low-frequency eigenspace of the Laplace-Beltrami operator on point clouds, recovering eigenpairs via Rayleigh-Ritz refinement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
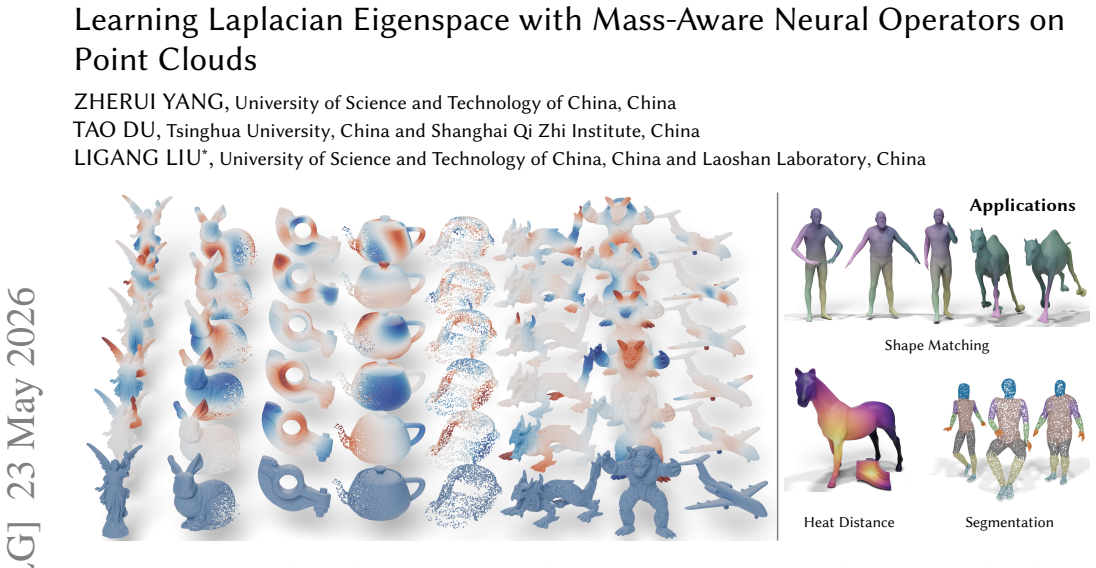
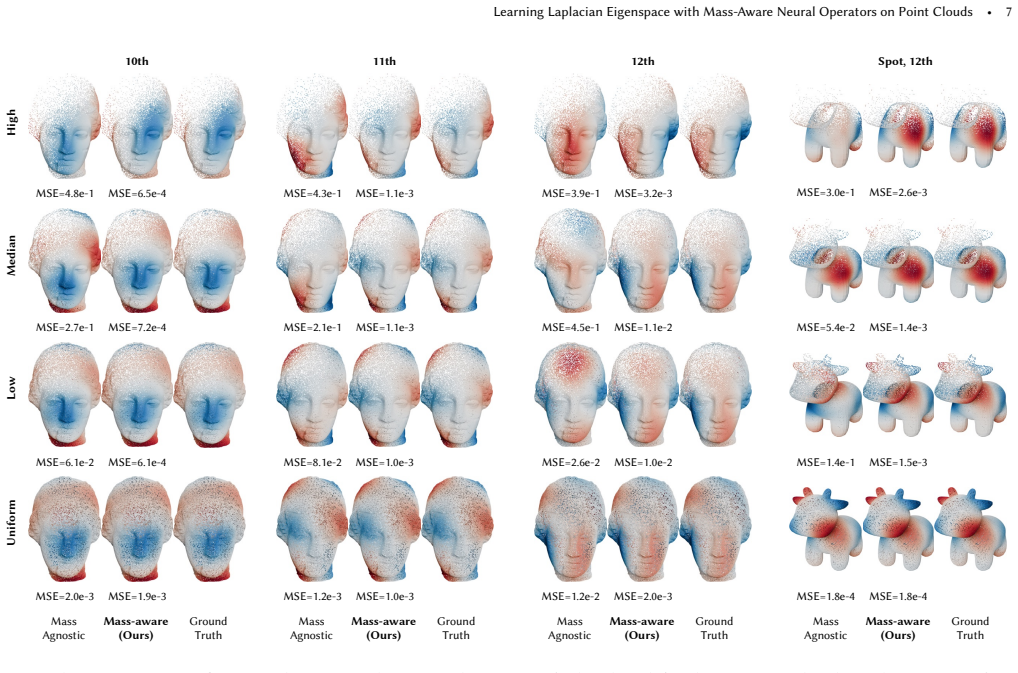
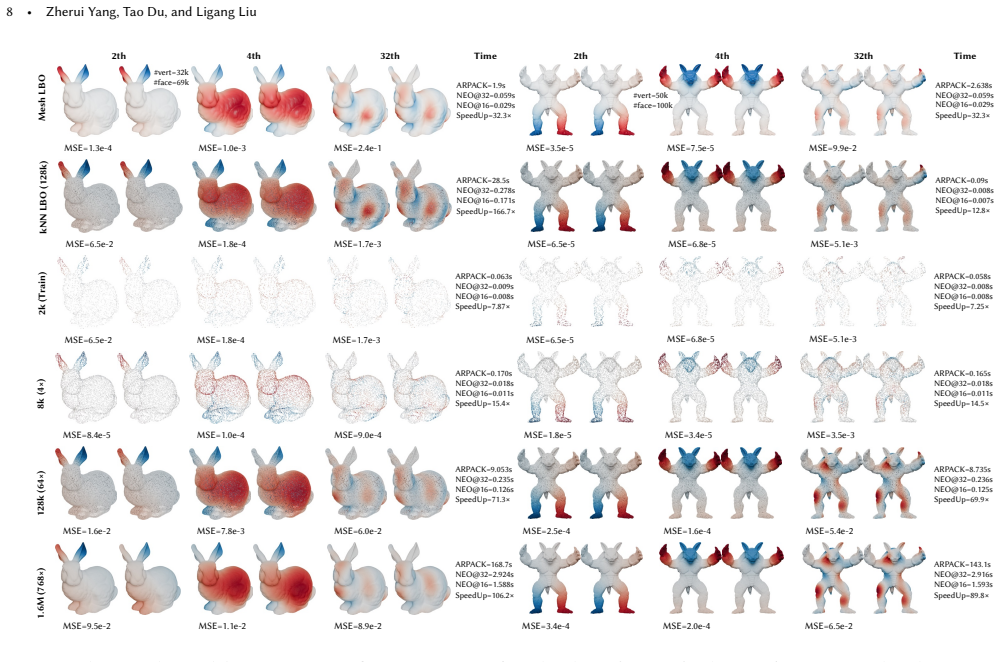
The Neural Eigenspace Operator (NEO) is a feed-forward framework that predicts a redundant set of basis functions whose span robustly covers the target low-frequency eigenspace of the Laplace-Beltrami operator on point clouds. Accurate eigenpairs are recovered via lightweight Rayleigh-Ritz refinement. The mass-aware neural operator incorporates per-point area weights into attention-based aggregation, improving robustness to non-uniform densities and enabling zero-shot generalization across resolutions.
What carries the argument
Mass-aware neural operator that incorporates per-point area weights into attention-based aggregation to predict a redundant basis spanning the target LBO eigenspace.
If this is right
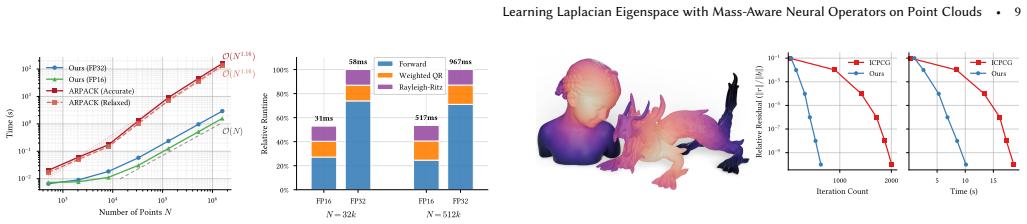
- Enables near-linear runtime scaling for eigenmode computation on large point clouds.
- Delivers substantial wall-clock speedups over iterative solvers at comparable accuracy.
- Supports zero-shot transfer to high-resolution point clouds without retraining.
- Yields raw basis functions that serve as effective point-wise features for downstream tasks.
- Produces eigenpairs usable in standard spectral geometry applications.
Where Pith is reading between the lines
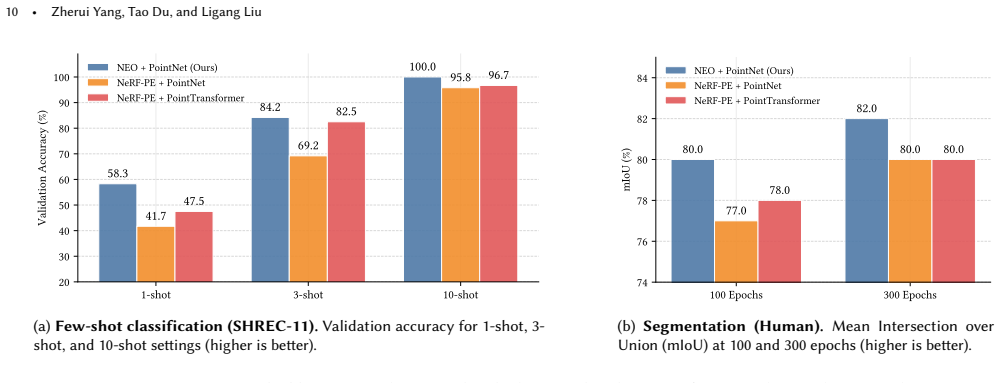
- The feed-forward prediction could support real-time spectral analysis inside interactive 3D modeling or simulation pipelines.
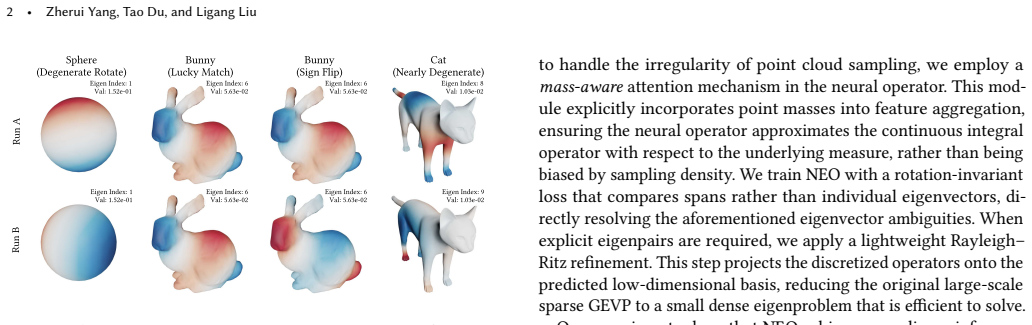
- The redundant-basis strategy for avoiding eigenvector ambiguities might transfer to other spectral problems on graphs or meshes.
- Evaluating performance on scanned real-world objects with natural density variations would test practical robustness beyond synthetic data.
Load-bearing premise
Incorporating per-point area weights into attention-based aggregation will improve robustness to non-uniform densities and enable zero-shot generalization across resolutions.
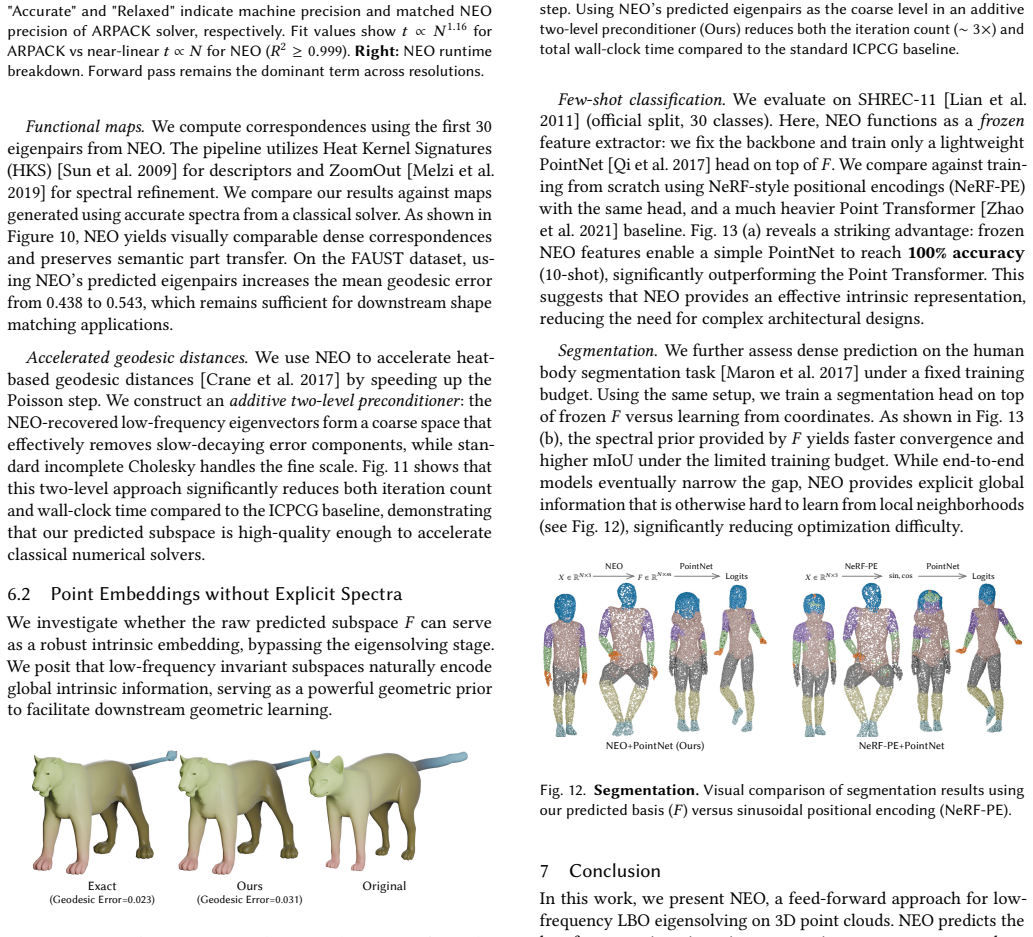
What would settle it
Running NEO on a point cloud with strongly varying local densities and measuring whether the recovered eigenpairs match those from a standard iterative solver on the corresponding surface mesh within a small tolerance.
Figures


read the original abstract
The eigendecomposition of the Laplace--Beltrami Operator (LBO) is fundamental to geometric analysis, yet computing its low-frequency eigenmodes remains a significant bottleneck due to the high cost of iterative solvers on large-scale data. To amortize this cost, we introduce the Neural Eigenspace Operator (NEO), a feed-forward framework designed to predict the spectrum directly from point clouds. Crucially, NEO circumvents the ill-posed nature of standard eigenvector regression, which suffers from intrinsic sign flips and rotation ambiguities, by learning the stable, invariant low-frequency subspace instead. Specifically, the network predicts a redundant set of basis functions whose span robustly covers the target eigenspace, allowing for the recovery of accurate eigenpairs via a lightweight Rayleigh--Ritz refinement. To handle irregular sampling, we propose a mass-aware neural operator that incorporates per-point area weights into attention-based aggregation, improving robustness to non-uniform densities and enabling zero-shot generalization across resolutions. Our approach achieves near-linear runtime scaling and substantial wall-clock speedups over iterative solvers at comparable accuracy, and exhibits strong zero-shot transfer to high-resolution point clouds. The resulting eigenpairs support standard spectral geometry tasks, while the raw basis functions provide effective point-wise features for downstream learning. Code: https://github.com/Adversarr/NEO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Neural Eigenspace Operator (NEO), a feed-forward neural framework that predicts a redundant set of basis functions whose span covers the low-frequency eigenspace of the Laplace-Beltrami operator on point clouds. Accurate eigenpairs are recovered via lightweight Rayleigh-Ritz refinement. A mass-aware neural operator incorporates per-point area weights into attention-based aggregation to improve robustness to non-uniform densities and enable zero-shot generalization across resolutions. The method reports near-linear runtime scaling with substantial speedups over iterative solvers at comparable accuracy, and the resulting eigenpairs support standard spectral geometry tasks.
Significance. If the central claims hold, the work could substantially reduce the computational bottleneck of eigendecomposition on large point clouds, enabling broader use of spectral methods in geometric deep learning and shape analysis. The redundant-basis formulation is a sound way to sidestep sign-flip and rotation ambiguities that plague direct eigenvector regression. The public code link supports reproducibility.
major comments (2)
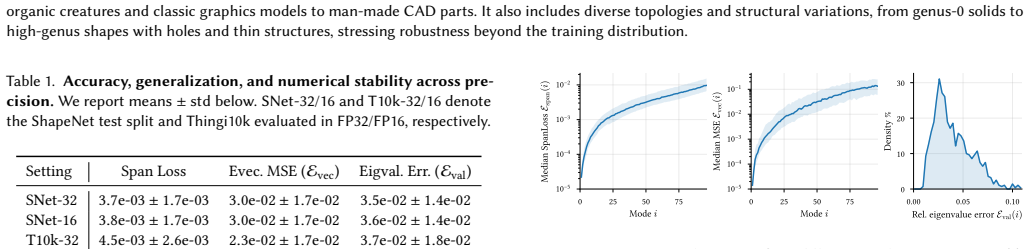
- [Abstract] Abstract: the claim that per-point area weights inside attention aggregation deliver robustness to non-uniform densities and zero-shot resolution transfer is load-bearing for the zero-shot generalization result, yet the manuscript provides no explicit ablation or sensitivity analysis isolating the contribution of these weights under controlled density variation.
- [Abstract] The near-linear runtime scaling assertion rests on the learned operator replacing iterative solvers, but without a complexity breakdown (e.g., attention cost versus number of points) or scaling plots that separate model inference from Rayleigh-Ritz post-processing, it is difficult to assess whether the speedup remains substantial at the largest scales claimed.
minor comments (2)
- The abstract states that the raw basis functions provide effective point-wise features for downstream learning; a brief quantitative demonstration on at least one downstream task would strengthen this secondary claim.
- Notation for the mass-aware aggregation operator should be introduced with an explicit equation rather than descriptive text only.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive overall assessment. We address each major comment point by point below. Where the manuscript would benefit from additional material, we commit to revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that per-point area weights inside attention aggregation deliver robustness to non-uniform densities and zero-shot resolution transfer is load-bearing for the zero-shot generalization result, yet the manuscript provides no explicit ablation or sensitivity analysis isolating the contribution of these weights under controlled density variation.
Authors: We agree that an explicit ablation isolating the per-point area weights under controlled density variation would strengthen the presentation. The current experiments compare mass-aware and mass-agnostic variants across sampling densities and resolutions, but do not isolate the weights in a dedicated sensitivity study. We will add such an ablation (with controlled density perturbations) to the revised manuscript. revision: yes
-
Referee: [Abstract] The near-linear runtime scaling assertion rests on the learned operator replacing iterative solvers, but without a complexity breakdown (e.g., attention cost versus number of points) or scaling plots that separate model inference from Rayleigh-Ritz post-processing, it is difficult to assess whether the speedup remains substantial at the largest scales claimed.
Authors: We acknowledge that a finer-grained complexity breakdown and scaling plots separating neural-operator inference from the subsequent Rayleigh-Ritz step would improve clarity. The reported near-linear wall-clock scaling includes both components; we will add an asymptotic analysis of the attention mechanism together with separate timing curves for inference versus post-processing in the revision. revision: yes
Circularity Check
No significant circularity; empirical operator learning is self-contained
full rationale
The paper introduces an empirical neural operator (NEO) trained to predict a redundant basis for the LBO eigenspace from point clouds, followed by standard Rayleigh-Ritz post-processing and a mass-aware attention design. These components are data-driven and validated on benchmarks rather than derived via equations that reduce to the inputs by construction. No self-definitional mappings, fitted parameters renamed as predictions, or load-bearing self-citations appear in the claimed pipeline; the mass-aware weighting is an architectural choice whose effect is tested empirically, not presupposed.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The low-frequency eigenspace of the LBO can be stably represented by a redundant learned basis that is refined by Rayleigh-Ritz.
invented entities (1)
-
Mass-aware neural operator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
On the bottleneck of graph neural networks and its practical implications.arXiv preprint arXiv:2006.05205(2020). Mathieu Aubry, Ulrich Schlickewei, and Daniel Cremers
-
[2]
Ido Ben-Shaul, Leah Bar, Dalia Fishelov, and Nir Sochen
Laplacian eigenmaps for dimensionality reduction and data representation.Neural computation15, 6 (2003), 1373–1396. Ido Ben-Shaul, Leah Bar, Dalia Fishelov, and Nir Sochen
2003
-
[3]
Michael M Bronstein, Joan Bruna, Yann LeCun, Arthur Szlam, and Pierre Vandergheynst
Deep learning solution of the eigenvalue problem for differential operators.Neural Computation35, 6 (2023), 1100–1134. Michael M Bronstein, Joan Bruna, Yann LeCun, Arthur Szlam, and Pierre Vandergheynst
2023
-
[4]
Joan Bruna, Wojciech Zaremba, Arthur Szlam, and Yann LeCun
Geometric deep learning: going beyond euclidean data.IEEE Signal Processing Magazine34, 4 (2017), 18–42. Joan Bruna, Wojciech Zaremba, Arthur Szlam, and Yann LeCun
2017
-
[5]
Spectral Networks and Locally Connected Networks on Graphs
Spectral Networks and Locally Connected Networks on Graphs.CoRRabs/1312.6203 (2013). https: //api.semanticscholar.org/CorpusID:17682909 Angel X. Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianxiong Xiao, Li Yi, and Fisher Yu. 2015.ShapeNet: An Information-Rich 3D Mod...
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[6]
Ronald R Coifman and Stéphane Lafon
Shape Space Spectra.arXiv preprint arXiv:2408.10099(2024). Ronald R Coifman and Stéphane Lafon
-
[7]
Keenan Crane, Clarisse Weischedel, and Max Wardetzky
Diffusion maps.Applied and computational harmonic analysis21, 1 (2006), 5–30. Keenan Crane, Clarisse Weischedel, and Max Wardetzky
2006
-
[8]
ACM60, 11 (2017), 90–99
The heat method for distance computation.Commun. ACM60, 11 (2017), 90–99. Chandler Davis and William Morton Kahan
2017
-
[9]
III.SIAM J
The rotation of eigenvectors by a perturbation. III.SIAM J. Numer. Anal.7, 1 (1970), 1–46. Gene H Golub and Charles F Van Loan. 2013.Matrix computations. JHU press. Wenjie Hu, Sidun Liu, Peng Qiao, Zhenglun Sun, and Yong Dou
1970
-
[10]
Xutong Jin, Sheng Li, Guoping Wang, and Dinesh Manocha
Transolver is a Linear Transformer: Revisiting Physics-Attention through the Lens of Linear Attention.arXiv preprint arXiv:2511.06294(2025). Xutong Jin, Sheng Li, Guoping Wang, and Dinesh Manocha
-
[11]
NeuralSound: Learning-based Modal Sound Synthesis with Acoustic Transfer.ACM Transactions on Graphics (SIGGRAPH 2022). https://doi.org/10.1145/3528223.3530184 Keller Jordan, Yuchen Jin, Vlado Boza, You Jiacheng, Franz Cesista, Laker Newhouse, and Jeremy Bernstein
-
[12]
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhat- tacharya, Andrew Stuart, and Anima Anandkumar
Toward the optimal preconditioned eigensolver: Locally optimal block preconditioned conjugate gradient method.SIAM journal on scientific computing23, 2 (2001), 517–541. Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhat- tacharya, Andrew Stuart, and Anima Anandkumar
2001
-
[13]
Richard B Lehoucq, Danny C Sorensen, and Chao Yang
Neural operator: Learning maps between function spaces with applications to pdes.Journal of Machine Learn- ing Research24, 89 (2023), 1–97. Richard B Lehoucq, Danny C Sorensen, and Chao Yang. 1998.ARPACK users’ guide: solution of large-scale eigenvalue problems with implicitly restarted Arnoldi methods. SIAM. Bruno Lévy
2023
-
[14]
under- stands
Laplace-beltrami eigenfunctions towards an algorithm that" under- stands" geometry. InIEEE International Conference on Shape Modeling and Applica- tions 2006 (SMI’06). IEEE, 13–13. Bruno Lévy and Hao Zhang
2006
-
[15]
InACM SIGGRAPH 2010 Courses
Spectral mesh processing. InACM SIGGRAPH 2010 Courses. 1–312. SIGGRAPH Conference Papers ’26, July 19–23, 2026, Los Angeles, CA, USA. Learning Laplacian Eigenspace with Mass-Aware Neural Operators on Point Clouds•11 H. Li, J. Sun, and Z. Zhang
2010
-
[16]
Deep Eigenspace Network and Its Application to Parametric Non-selfadjoint Eigenvalue Problems. arXiv:2512.20058 [math.NA] https://arxiv.org/abs/2512.20058 Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhat- tacharya, Andrew Stuart, and Anima Anandkumar. 2020a. Fourier neural operator for parametric partial differential equation...
-
[17]
SHREC’11 Track: Shape Retrieval on Non-rigid 3D Watertight Meshes.3DOR@ eurographics5 (2011). Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, Yanru Chen, Huabin Zheng, Yibo Liu, Shaowei Liu, Bohong Yin, Weiran He, Han Zhu, Yuzhi Wang, Jianzhou Wang, Mengnan Dong, Zheng Zhang, Yongshe...
2011
-
[18]
Muon is Scalable for LLM Training
Muon is Scalable for LLM Training. arXiv:2502.16982 [cs.LG] https://arxiv.org/abs/2502.16982 Ilya Loshchilov and Frank Hutter
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Decoupled Weight Decay Regularization
Decoupled Weight Decay Regularization. arXiv:1711.05101 [cs.LG] https://arxiv.org/abs/1711.05101 Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Haggai Maron, Meirav Galun, Noam Aigerman, Miri Trope, Nadav Dym, Ersin Yumer, Vladimir G Kim, and Yaron Lipman
Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators.Nature machine intelligence3, 3 (2021), 218–229. Haggai Maron, Meirav Galun, Noam Aigerman, Miri Trope, Nadav Dym, Ersin Yumer, Vladimir G Kim, and Yaron Lipman
2021
-
[21]
Graph.36, 4 (2017), 71–1
Convolutional neural networks on surfaces via seamless toric covers.ACM Trans. Graph.36, 4 (2017), 71–1. Simone Melzi, Jing Ren, Emanuele Rodolà, Abhishek Sharma, Peter Wonka, and Maks Ovsjanikov
2017
-
[22]
ZoomOut: spectral upsampling for efficient shape correspondence. ACM Trans. Graph.38, 6, Article 155 (Nov. 2019), 14 pages. doi:10.1145/3355089. 3356524 Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ra- mamoorthi, and Ren Ng
-
[23]
Maks Ovsjanikov, Mirela Ben-Chen, Justin Solomon, Adrian Butscher, and Leonidas Guibas
Fast Approximation of Laplace-–Beltrami Eigenproblems.Computer Graphics Forum37, 5 (2018). Maks Ovsjanikov, Mirela Ben-Chen, Justin Solomon, Adrian Butscher, and Leonidas Guibas
2018
-
[24]
ACM Transactions on Graphics (ToG)31, 4 (2012), 1–11
Functional maps: a flexible representation of maps between shapes. ACM Transactions on Graphics (ToG)31, 4 (2012), 1–11. Bo Pang, Zhongtian Zheng, Yilong Li, Guoping Wang, and Peng-Shuai Wang
2012
-
[25]
Alex Pentland and John Williams
Neural Laplacian Operator for 3D Point Clouds.ACM Transactions on Graphics (SIGGRAPH Asia)(2024). Alex Pentland and John Williams
2024
-
[26]
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred Ham- precht, Yoshua Bengio, and Aaron Courville
Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems30 (2017). Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred Ham- precht, Yoshua Bengio, and Aaron Courville
2017
-
[27]
Jing Ren, Adrien Poulenard, Peter Wonka, and Maks Ovsjanikov
Physics-informed neu- ral networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational physics 378 (2019), 686–707. Jing Ren, Adrien Poulenard, Peter Wonka, and Maks Ovsjanikov
2019
-
[28]
Martin Reuter, Franz-Erich Wolter, and Niklas Peinecke
Continuous and orientation-preserving correspondences via functional maps.ACM Transactions on Graphics (ToG)37, 6 (2018), 1–16. Martin Reuter, Franz-Erich Wolter, and Niklas Peinecke
2018
-
[29]
Nicholas Sharp, Souhaib Attaiki, Keenan Crane, and Maks Ovsjanikov
Laplace–Beltrami spectra as ‘Shape-DNA’of surfaces and solids.Computer-Aided Design38, 4 (2006), 342–366. Nicholas Sharp, Souhaib Attaiki, Keenan Crane, and Maks Ovsjanikov
2006
-
[30]
Nicholas Sharp and Keenan Crane
Diffusion- net: Discretization agnostic learning on surfaces.ACM Transactions on Graphics (TOG)41, 3 (2022), 1–16. Nicholas Sharp and Keenan Crane
2022
-
[31]
HodgeNet.ACM Transactions on Graphics (TOG)40 (2021), 1 –
2021
-
[32]
https://proceedings.neurips.cc/paper_files/paper/2021/file/ 2d3d9d5373f378108cdbd30a3c52bd3e-Paper.pdf Bruno Vallet and Bruno Lévy
Curran Asso- ciates, Inc., 5731–5744. https://proceedings.neurips.cc/paper_files/paper/2021/file/ 2d3d9d5373f378108cdbd30a3c52bd3e-Paper.pdf Bruno Vallet and Bruno Lévy
2021
-
[33]
Transolver: A Fast Transformer Solver for PDEs on General Geometries
Transolver: A fast transformer solver for pdes on general geometries.arXiv preprint arXiv:2402.02366(2024). Zherui Yang, Haiyang Xin, Tao Du, and Ligang Liu
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Simple yet Effective: Low-Rank Spatial Attention for Neural Operators
Simple yet Effective: Low- Rank Spatial Attention for Neural Operators. arXiv:2604.03582 [cs.LG] https: //arxiv.org/abs/2604.03582 L. Yi, Hao Su, Xingwen Guo, and Leonidas J. Guibas
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
https://api.semanticscholar.org/ CorpusID:14487589 Bing Yu et al
SyncSpecCNN: Synchronized Spectral CNN for 3D Shape Segmentation.2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)(2016), 6584–6592. https://api.semanticscholar.org/ CorpusID:14487589 Bing Yu et al
2017
-
[36]
Chong Zeng, Yue Dong, Pieter Peers, Hongzhi Wu, and Xin Tong
The deep Ritz method: a deep learning-based numerical algorithm for solving variational problems.Communications in Mathematics and Statistics6, 1 (2018), 1–12. Chong Zeng, Yue Dong, Pieter Peers, Hongzhi Wu, and Xin Tong
2018
-
[37]
InACM SIGGRAPH 2025 Conference Papers
RenderFormer: Transformer-based Neural Rendering of Triangle Meshes with Global Illumination. InACM SIGGRAPH 2025 Conference Papers. Hao Zhang, Oliver van Kaick, and Ramsay Dyer
2025
-
[38]
InProceedings of the IEEE/CVF International Conference on Computer Vision
Point transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision. 16259–16268. 8 Full Experiment Details In this section, we provide the complete hyperparameter settings, training dynamics, and data generation details to ensure repro- ducibility. 8.1 Model Architecture and Configurations Architecture Overview.The NEO backbone i...
2026
-
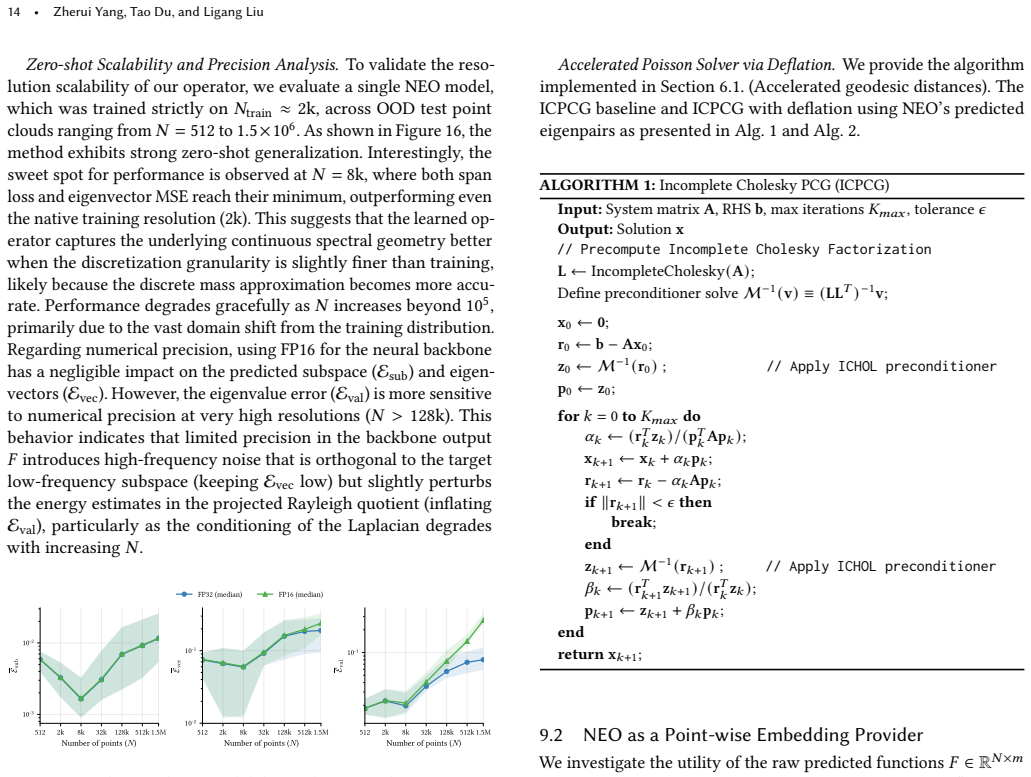
[39]
Test(2k)
requires roughly 17 hours, while the wider NEO- Large (𝐿=6) requires approximately 36 hours. 9 Full Experiment Results 9.1 NEO as an Eigen Solver To strictly isolate the impact of architectural design from model capacity, we evaluate the PointNet++[Qi et al. 2017] and Point Trans- former [Zhao et al. 2021] baselines under a rigorous iso-parameter setting....
2017
-
[40]
2018], a mesh-based approximate eigensolver
Backbone Esub 𝑇sample Test(2k) 64k Non-Uniform (ms) PointNet++ 6.97e-3 1.00e-2 1.21e-2 763 Point Transformer 4.81e-3 4.92e-1 4.18e-1 1418 NEO (Ours) 3.47e-3 3.27e-3 2.63e-3 159 Comparison with FastSpectrum.We further compare NEO with FastSpectrum [Nasikun et al . 2018], a mesh-based approximate eigensolver. Using the authors’ implementation with matched s...
2018
-
[41]
2.93s), NEO achieves a much more signif- icant73 × speedup (0.04s)
and evaluation settings on our mesh datasets, we observed that while FastSpectrum offers a14× speedup over ARPACK (0.21s vs. 2.93s), NEO achieves a much more signif- icant73 × speedup (0.04s). As detailed in Table 7, NEO also yields a lower mean Span Loss (8 .60e−3compared to FastSpectrum’s SIGGRAPH Conference Papers ’26, July 19–23, 2026, Los Angeles, CA...
2026
-
[42]
Method Span Loss Evec
NEO yields lower span loss and eigenvector MSE but marginally higher variance. Method Span Loss Evec. MSE Evec. MSE Var. FastSpectrum 1.08e−2 2.28e−11.08e−1 NEO (Ours) 8.60e−3 1.97e−11.17e−1 Baselines Setting and Scalability Evaluation.To comprehensively evaluate the computational efficiency and scalability of traditional eigensolvers across varying probl...
2026
-
[43]
For the NEO-based method, we freeze the backbone and only train the SIGGRAPH Conference Papers ’26, July 19–23, 2026, Los Angeles, CA, USA
and activation scheme. For the NEO-based method, we freeze the backbone and only train the SIGGRAPH Conference Papers ’26, July 19–23, 2026, Los Angeles, CA, USA. Learning Laplacian Eigenspace with Mass-Aware Neural Operators on Point Clouds•15 ALGORITHM 2:Spectral Deflated ICPCG (Additive) Input:System matrixA, RHSb, Basis vectorsY∈R 𝑁×𝑘 from NEOOutput:S...
2026
-
[44]
Positional Encoding.To establish a competitive coordinate-based baseline, we employ the Positional Encoding (PE) mechanism popu- larized by NeRF [Mildenhall et al
Warm Start using coarse solution x0 ← C (b); r0 ←b−Ax 0; // Two-level additive apply:z=z 𝑏𝑎𝑠𝑒 +z 𝑐𝑜𝑎𝑟𝑠𝑒 z0 ← M −1 𝑏𝑎𝑠𝑒 (r0 ) + C (r 0 ); p0 ←z 0; for𝑘=0to𝐾 𝑚𝑎𝑥 do 𝛼𝑘 ← (r 𝑇 𝑘 z𝑘 )/(p 𝑇 𝑘 Ap𝑘 ); x𝑘+1 ←x 𝑘 +𝛼 𝑘 p𝑘; r𝑘+1 ←r 𝑘 −𝛼 𝑘 Ap𝑘; if∥r 𝑘+1 ∥<𝜖then break; end // Additive Preconditioner Step zℎ𝑖𝑔ℎ ← M −1 𝑏𝑎𝑠𝑒 (r𝑘+1 ); z𝑙𝑜𝑤 ← C (r 𝑘+1 ); z𝑘+1 ←z ℎ𝑖𝑔ℎ +z 𝑙𝑜...
2020
-
[45]
16•Zherui Yang, Tao Du, and Ligang Liu Table 12.Segmentation on Human Body.We report the mean IoU (mIoU) evaluated at 100 and 300 training epochs
This setting simulates a simplified deployment scenario where local area estimation is skipped, treating the integration effectively as a SIGGRAPH Conference Papers ’26, July 19–23, 2026, Los Angeles, CA, USA. 16•Zherui Yang, Tao Du, and Ligang Liu Table 12.Segmentation on Human Body.We report the mean IoU (mIoU) evaluated at 100 and 300 training epochs. ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.