Advancing Graph Few-Shot Learning via In-Context Learning
Pith reviewed 2026-06-30 13:50 UTC · model grok-4.3
The pith
VISION reframes graph few-shot learning as fine-tuning-free sequence reasoning that fuses local topology with task context in one forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
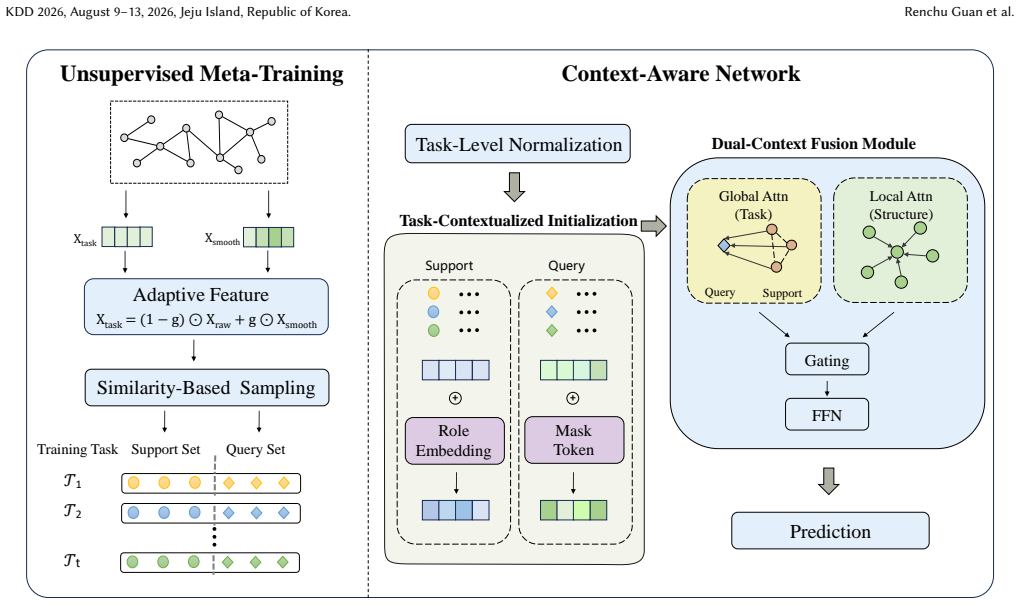
VISION reframes graph few-shot learning as a fine-tuning-free sequence reasoning problem. At its core is a context-aware network that initializes nodes with role embeddings and employs a dual-context fusion module to synergistically integrate local topological structures and global task-level dependencies. This allows the model to dynamically generate class-aware representations for the query set conditioned on the support set context in a single forward pass. An unsupervised task generator creates structure-adaptive features and constructs diverse pseudo-tasks from abundant unlabeled data, unifying unsupervised meta-learning with graph in-context learning.
What carries the argument
Dual-context fusion module inside a context-aware network that merges local topological structures with global task-level dependencies to produce class-aware query representations from support-set context.
If this is right
- Inference requires only a single forward pass with no task-specific adaptation or fine-tuning.
- Unlabeled nodes are turned into training signal through an unsupervised task generator that builds structure-adaptive pseudo-tasks.
- The same trained model handles multiple novel classes across different graphs without retraining.
- Local node topology and global task context are combined inside one module to condition query representations on support examples.
Where Pith is reading between the lines
- The single-pass design could support online updates on streaming graphs where new nodes arrive continuously.
- Role embeddings that encode support versus query status might transfer to few-shot settings on non-graph structured data such as sequences or tables.
- Unsupervised pseudo-task construction opens the possibility of scaling the approach to graphs with millions of nodes by sampling diverse subgraphs.
Load-bearing premise
The dual-context fusion module can synergistically integrate local topological structures and global task-level dependencies to dynamically generate accurate class-aware representations for the query set conditioned on the support set context in a single forward pass without any task adaptation or fine-tuning.
What would settle it
Ablation experiments on standard benchmarks where removing the dual-context fusion module produces accuracy no better than fine-tuned baselines, or full-model tests on held-out graphs where accuracy fails to exceed prior methods that require adaptation.
Figures
read the original abstract
Graph few-shot learning, which aims to classify nodes from novel classes with only a few labeled examples, is a widely studied problem in graph learning. However, existing methods often face two key limitations. First, the predominant graph few-shot learning paradigm relies on supervised tasks, failing to leverage the vast number of unlabeled nodes in the graph. Second, many approaches require complex task adaptation or fine-tuning during inference, limiting their efficiency and applicability. Inspired by the powerful in-context learning capabilities of large language models, we propose a novel model named VISION for adVancIng graph few-Shot learning via In-cOntext LearNing to address these challenges. Our model reframes graph few-shot learning as a fine-tuning-free sequence reasoning problem. At its core is a context-aware network that initializes nodes with role embeddings and employs a dual-context fusion module to synergistically integrate local topological structures and global task-level dependencies. This allows our model to dynamically generate class-aware representations for the query set conditioned on the support set context in a single forward pass. To effectively train our model, we introduce an unsupervised task generator that creates structure-adaptive features and constructs diverse pseudo-tasks from abundant unlabeled data. Our method unifies unsupervised meta-learning with graph in-context learning, achieving efficient inference. Extensive experiments on multiple benchmark datasets demonstrate the superiority of our model. Our public code can be found
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VISION, a model that reframes graph few-shot learning as fine-tuning-free in-context learning. It introduces a context-aware network that uses role embeddings and a dual-context fusion module to integrate local topological structures with global task-level dependencies, enabling single-forward-pass generation of class-aware query representations conditioned on support-set context. Training relies on an unsupervised task generator that constructs pseudo-tasks from unlabeled nodes. The work claims this unifies unsupervised meta-learning with graph in-context learning and demonstrates superiority via extensive experiments on benchmark datasets.
Significance. If the dual-context fusion module and unsupervised task generator function as described, the approach could provide an efficiency advantage over adaptation-based meta-learning methods in graph few-shot settings by enabling inference without task-specific fine-tuning and by exploiting abundant unlabeled graph data.
major comments (2)
- [Abstract] Abstract: The central performance claim rests on the dual-context fusion module (with role embeddings) achieving synergistic integration of local and global dependencies to produce accurate class-aware query representations conditioned solely on support-set context in one forward pass. No equations, pseudocode, or architectural diagram specifying the fusion operation (e.g., how support information propagates to queries without leakage or collapse) are supplied, leaving the load-bearing mechanism unverified.
- [Abstract] Abstract: The superiority claim and the effectiveness of both the fusion module and the unsupervised task generator are asserted via 'extensive experiments on multiple benchmark datasets,' yet no results, tables, error bars, dataset statistics, ablation studies, or baseline comparisons appear in the manuscript.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to address these points. We respond to each major comment below and commit to revisions that improve technical clarity without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claim rests on the dual-context fusion module (with role embeddings) achieving synergistic integration of local and global dependencies to produce accurate class-aware query representations conditioned solely on support-set context in one forward pass. No equations, pseudocode, or architectural diagram specifying the fusion operation (e.g., how support information propagates to queries without leakage or collapse) are supplied, leaving the load-bearing mechanism unverified.
Authors: We agree the abstract is high-level and does not contain the requested technical specifications. The manuscript will be revised to include the equations defining role embeddings and the dual-context fusion operation (cross-attention between support and query with explicit masking to avoid leakage), along with pseudocode and an architectural diagram in Section 3. revision: yes
-
Referee: [Abstract] Abstract: The superiority claim and the effectiveness of both the fusion module and the unsupervised task generator are asserted via 'extensive experiments on multiple benchmark datasets,' yet no results, tables, error bars, dataset statistics, ablation studies, or baseline comparisons appear in the manuscript.
Authors: We agree that the current manuscript text does not include the experimental results, tables, or ablations referenced in the abstract. We will add a dedicated experimental section (Section 4) containing these elements, including dataset statistics, baseline comparisons, ablation studies on the fusion module and task generator, and results with error bars on the benchmark datasets. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes a new model VISION that reframes graph few-shot learning as a fine-tuning-free sequence reasoning task, introducing a context-aware network with role embeddings and a dual-context fusion module, plus an unsupervised task generator from unlabeled data. No equations, definitions, or claims in the provided text reduce any central result (such as class-aware query representations or unification of meta-learning with in-context learning) to a fitted input or self-referential construction by definition. The performance claims rest on experimental validation rather than tautological derivation, making the method self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Graph data contains local topological structures and global task-level dependencies that can be fused to produce useful node representations.
invented entities (1)
-
VISION model with context-aware network and dual-context fusion module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Amir Bar, Yossi Gandelsman, Trevor Darrell, Amir Globerson, and Alexei Efros
-
[2]
InNeurIPS
Visual prompting via image inpainting. InNeurIPS. 25005–25017
-
[3]
Peter L Bartlett and Shahar Mendelson. 2002. Rademacher and gaussian complex- ities: Risk bounds and structural results.Journal of Machine Learning Research3, Nov (2002), 463–482
2002
-
[4]
Aleksandar Bojchevski and Stephan Günnemann. 2018. Deep gaussian embedding of graphs: Unsupervised inductive learning via ranking. InICLR
2018
-
[5]
Victor Ion Butoi, Jose Javier Gonzalez Ortiz, Tianyu Ma, Mert R Sabuncu, John Guttag, and Adrian V Dalca. 2023. Universeg: Universal medical image segmen- tation. InICCV. 21438–21451
2023
-
[6]
Stephanie Chan, Adam Santoro, Andrew Lampinen, Jane Wang, Aaditya Singh, Pierre Richemond, James McClelland, and Felix Hill. 2022. Data distributional properties drive emergent in-context learning in transformers. InNeurIPS. 18878– 18891
2022
-
[7]
Michaël Defferrard, Xavier Bresson, and Pierre Vandergheynst. 2016. Convolu- tional neural networks on graphs with fast localized spectral filtering. InNeurIPS. 3837–3845
2016
-
[8]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In NAACL. 4171–4186
2019
-
[9]
Kaize Ding, Jianling Wang, Jundong Li, Kai Shu, Chenghao Liu, and Huan Liu
-
[10]
Graph prototypical networks for few-shot learning on attributed networks. InCIKM. 295–304
-
[11]
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, and Zhifang Sui. 2024. A Survey on In-context Learning. InEMNLP. 1107–1128
2024
-
[12]
Junkins, Ehsan Amid, Jure Leskovec, Christopher Ré, and Sebastian Thrun
Christopher Fifty, Dennis Duan, Ronald G. Junkins, Ehsan Amid, Jure Leskovec, Christopher Ré, and Sebastian Thrun. 2024. Context-Aware Meta-Learning. In ICLR
2024
-
[13]
Chelsea Finn, Pieter Abbeel, and Sergey Levine. 2017. Model-agnostic meta- learning for fast adaptation of deep networks. InICML. 1126–1135
2017
-
[14]
Aditya Grover and Jure Leskovec. 2016. node2vec: Scalable feature learning for networks. InKDD. 855–864
2016
-
[15]
Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs. InNeurIPS. 1024–1034
2017
-
[16]
Mikael Henaff, Joan Bruna, and Yann LeCun. 2015. Deep convolutional networks on graph-structured data.arXiv preprint arXiv:1506.05163(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[17]
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. 2020. Open graph benchmark: Datasets for machine learning on graphs. InNeurIPS. 22118–22133
2020
-
[18]
Kexin Huang and Marinka Zitnik. 2020. Graph Meta Learning via Local Subgraphs. InNeurIPS. 5862–5874
2020
-
[19]
Kexin Huang and Marinka Zitnik. 2020. Graph meta learning via local subgraphs. InNeurIPS. 5862–5874
2020
-
[20]
Qian Huang, Hongyu Ren, Peng Chen, Gregor Kržmanc, Daniel Zeng, Percy S Liang, and Jure Leskovec. 2023. Prodigy: Enabling in-context learning over graphs. InNeurIPS. 16302–16317
2023
-
[21]
Siavash Khodadadeh, Ladislau Bölöni, and Mubarak Shah. 2019. Unsupervised Meta-Learning for Few-Shot Image Classification. InNeurIPS. 10132–10142
2019
-
[22]
Sungwon Kim, Junseok Lee, Namkyeong Lee, Wonjoong Kim, Seungyoon Choi, and Chanyoung Park. 2023. Task-equivariant graph few-shot learning. InKDD. 1120–1131
2023
-
[23]
Kipf and Max Welling
Thomas N. Kipf and Max Welling. 2017. Semi-supervised classification with graph convolutional networks. InICLR
2017
- [24]
-
[25]
Yonghao Liu, Lan Huang, Bowen Cao, Ximing Li, Fausto Giunchiglia, Xiaoyue Feng, and Renchu Guan. 2024. A simple but effective approach for unsupervised few-shot graph classification. InWWW. 4249–4259
2024
-
[26]
Yonghao Liu, Mengyu Li, Fausto Giunchiglia, Lan Huang, Ximing Li, Xiaoyue Feng, and Renchu Guan. 2025. Dual-level Mixup for Graph Few-shot Learning with Fewer Tasks. InWWW. 2646–2656
2025
-
[27]
Yonghao Liu, Mengyu Li, Ximing Li, Fausto Giunchiglia, Xiaoyue Feng, and Renchu Guan. 2022. Few-shot node classification on attributed networks with graph meta-learning. InSIGIR. 471–481
2022
-
[28]
Yonghao Liu, Mengyu Li, Ximing Li, Lan Huang, Fausto Giunchiglia, Yanchun Liang, Xiaoyue Feng, and Renchu Guan. 2024. Meta-GPS++: Enhancing graph meta-learning with contrastive learning and self-training.ACM Transactions on Knowledge Discovery from Data18, 9 (2024), 1–30
2024
-
[29]
Yonghao Liu, Chuyao Wang, Zhikang Wang, Liang Chen, Zhi Li, Jiangning Song, Qi Zou, Rui Gao, Binzhi Qian, Xiaoyue Feng, et al. 2026. High-Parameter Spatial Multi-Omics through Histology-Anchored Integration.Nature Methods23, 2 (2026), 373–386
2026
-
[30]
Yonghao Liu, Yajun Wang, Chunli Guo, Wei Pang, Ximing Li, Fausto Giunchiglia, Xiaoyue Feng, and Renchu Guan. 2026. Graph few-shot learning via adaptive spectrum experts and cross-set distribution calibration. InAdvances in Neural Information Processing Systems. 160490–160517. KDD 2026, August 9–13, 2026, Jeju Island, Republic of Korea. Renchu Guan et al
2026
-
[31]
Zemin Liu, Xingtong Yu, Yuan Fang, and Xinming Zhang. 2023. Graphprompt: Unifying pre-training and downstream tasks for graph neural networks. InWWW. 417–428
2023
-
[32]
Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization. InICLR
2019
-
[33]
Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. 2014. Deepwalk: Online learning of social representations. InKDD. 701–710
2014
-
[34]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners.OpenAI blog 1, 8 (2019), 9
2019
-
[35]
Oleksandr Shchur, Maximilian Mumme, Aleksandar Bojchevski, and Stephan Günnemann. 2018. Pitfalls of graph neural network evaluation.arXiv preprint arXiv:1811.05868(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
Aaditya Singh, Stephanie Chan, Ted Moskovitz, Erin Grant, Andrew Saxe, and Felix Hill. 2023. The transient nature of emergent in-context learning in trans- formers. InNeurIPS. 27801–27819
2023
-
[37]
Jake Snell, Kevin Swersky, and Richard Zemel. 2017. Prototypical networks for few-shot learning. InNeurIPS. 4077–4087
2017
-
[38]
Zhen Tan, Ruocheng Guo, Kaize Ding, and Huan Liu. 2023. Virtual node tuning for few-shot node classification. InKDD. 2177–2188
2023
-
[39]
Zhen Tan, Song Wang, Kaize Ding, Jundong Li, and Huan Liu. 2022. Transductive linear probing: A novel framework for few-shot node classification. InLoG
2022
-
[40]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, Yoshua Bengio, et al. 2018. Graph attention networks. InICLR
2018
-
[42]
Song Wang, Chen Chen, and Jundong Li. 2022. Graph Few-shot Learning with Task-specific Structures. InNeurIPS. 38925–38936
2022
-
[43]
Song Wang, Kaize Ding, Chuxu Zhang, Chen Chen, and Jundong Li. 2022. Task- adaptive few-shot node classification. InKDD. 1910–1919
2022
-
[44]
Song Wang, Yushun Dong, Kaize Ding, Chen Chen, and Jundong Li. 2023. Few- shot node classification with extremely weak supervision. InWSDM. 276–284
2023
-
[45]
Song Wang, Zhen Tan, Huan Liu, and Jundong Li. 2023. Contrastive meta-learning for few-shot node classification. InKDD. 2386–2397
2023
-
[46]
Felix Wu, Amauri Souza, Tianyi Zhang, Christopher Fifty, Tao Yu, and Kilian Weinberger. 2019. Simplifying graph convolutional networks. InICML. 6861– 6871
2019
-
[47]
Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and Philip S Yu. 2020. A comprehensive survey on graph neural networks.IEEE Transactions on Neural Networks and Learning Systems32, 1 (2020), 4–24
2020
-
[48]
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. 2019. How powerful are graph neural networks?. InICLR
2019
-
[49]
Zhilin Yang, William Cohen, and Ruslan Salakhudinov. 2016. Revisiting semi- supervised learning with graph embeddings. InICML. 40–48
2016
-
[50]
Chuxu Zhang, Kaize Ding, Jundong Li, Xiangliang Zhang, Yanfang Ye, Nitesh V Chawla, and Huan Liu. 2022. Few-shot learning on graphs. InIJCAI. 5662–5669
2022
-
[51]
Qiannan Zhang, Shichao Pei, Yuan Fang, and Xiangliang Zhang. 2025. Unlocking the Potential of Black-box Pre-trained GNNs for Graph Few-shot Learning. In AAAI. 22497–22505
2025
-
[52]
Fan Zhou, Chengtai Cao, Kunpeng Zhang, Goce Trajcevski, Ting Zhong, and Ji Geng. 2019. Meta-gnn: On few-shot node classification in graph meta-learning. InCIKM. 2357–2360
2019
-
[53]
Jie Zhou, Ganqu Cui, Shengding Hu, Zhengyan Zhang, Cheng Yang, Zhiyuan Liu, Lifeng Wang, Changcheng Li, and Maosong Sun. 2020. Graph neural networks: A review of methods and applications.AI Open1 (2020), 57–81
2020
-
[54]
Zhiyuan Zhou, Yueming Yin, Hao Han, Yiping Jia, Jun Hong Koh, Adams Wai-Kin Kong, and Yuguang Mu. 2024. ProAffinity-GNN: a novel approach to structure- based protein–Protein binding affinity prediction via a curated data set and graph neural networks.Journal of Chemical Information and Modeling64, 23 (2024), 8796–8808. A Appendix A.1 Verification of Rando...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.