Benchmarking the Limits of In-Context Reinforcement Learning for Ad-Hoc Teamwork
Pith reviewed 2026-06-30 13:38 UTC · model grok-4.3
The pith
In-context RL methods underperform random baselines across unseen teammates and layouts in ad-hoc teamwork.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
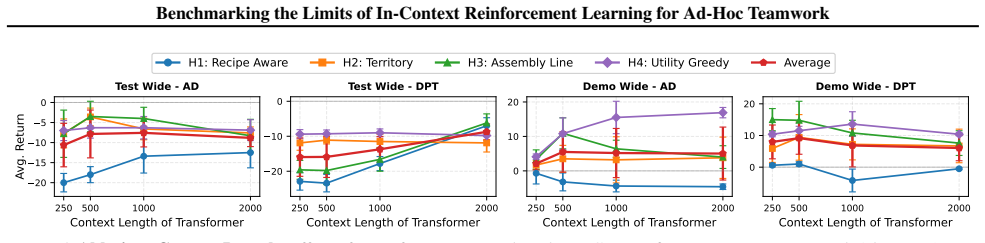
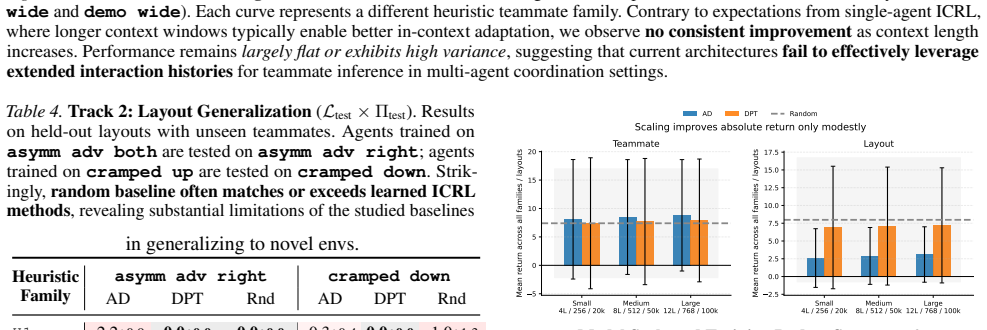
History-conditioned ICRL algorithms fail to exhibit robust test-time adaptation in multi-agent ad-hoc teamwork, frequently underperforming random baselines on both unseen teammate and unseen layout tracks with no clear in-context improvement over long horizons.
What carries the argument
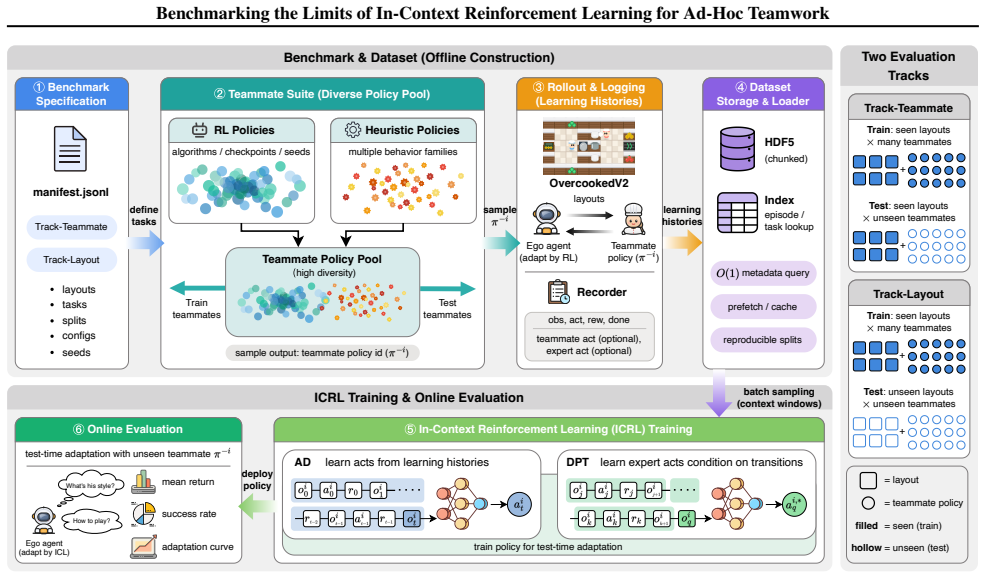
The ICRL4AHT benchmark, consisting of a diverse teammate suite spanning RL and heuristic policies together with a reproducible multi-episode evaluation protocol on Overcooked-V2 under controlled distribution shifts.
If this is right
- Existing ICRL techniques require new mechanisms to handle partial observability and teammate inference in multi-agent environments.
- The benchmark supplies a standardized testbed for measuring whether future coordination algorithms overcome the observed failure modes.
- No clear scaling benefit from longer interaction histories appears under the current AHT protocol.
Where Pith is reading between the lines
- Methods that maintain explicit models of possible teammate strategies may be needed before in-context adaptation succeeds.
- Testing the same algorithms on other partially observable multi-agent domains would clarify whether the limits are specific to Overcooked-V2.
- Hybrid systems that combine in-context learning with lightweight planning could be a direct next step to evaluate.
Load-bearing premise
The generated teammate suite and the multi-episode evaluation protocol in Overcooked-V2 accurately capture the strategic inference challenges of real ad-hoc teamwork under partial observability.
What would settle it
An in-context method that consistently outperforms random baselines on the unseen teammate track and the unseen layout track of the ICRL4AHT benchmark would falsify the reported limitations.
Figures




read the original abstract
In-Context Reinforcement Learning (ICRL) has enabled foundation agents to adapt instantaneously to novel tasks, yet its efficacy in Ad-Hoc Teamwork (AHT)-where coordination with unknown partners is required-remains unexplored. To rigorously evaluate this, we introduce a large-scale benchmark ICRL4AHT, built upon a high-throughput JAX implementation of Overcooked-V2. Our benchmark includes a large, diverse teammate suite spanning both RL and heuristic policies, enabling controlled train-test shifts, and provides a reproducible end-to-end pipeline for teammate generation, learning-history collection, dataset construction, and online multi-episode evaluation. We evaluate representative history-conditioned ICRL algorithms, including Algorithm Distillation (AD) and Decision-Pretrained Transformer (DPT), across millions of transitions. Results reveal notable limitations: contrary to their success in single-agent domains, these baselines fail to exhibit robust test-time adaptation in multi-agent settings. Specifically, these methods frequently underperform random baselines across both unseen teammate and unseen layout tracks, with no clear in-context improvement over long horizons. These findings highlight the challenges of strategic inference under partial observability within the OvercookedV2 AHT protocol, establishing our benchmark as a critical testbed for next-generation coordination algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the ICRL4AHT benchmark on a JAX-based Overcooked-V2 environment to evaluate in-context RL for ad-hoc teamwork. It generates a diverse teammate suite spanning RL and heuristic policies, provides a reproducible pipeline for generation, history collection, and multi-episode evaluation, and reports that representative methods (AD, DPT) frequently underperform random baselines on both unseen-teammate and unseen-layout tracks, with no evident in-context gains over long horizons.
Significance. If the benchmark protocol is robust, the negative results are significant because they expose limits of ICRL approaches that succeed in single-agent settings when applied to multi-agent coordination under partial observability. The reproducible JAX implementation, large-scale evaluation across millions of transitions, and controlled train-test shifts constitute concrete strengths that position the benchmark as a useful testbed for future coordination algorithms.
major comments (1)
- [Evaluation Protocol] The multi-episode evaluation protocol (abstract and §4) is load-bearing for the central claim of no in-context improvement over long horizons. The manuscript does not specify how history length is varied across episodes, how partial-observability observations are tokenized for the transformer-based models, or the exact mechanism by which the random baseline receives equivalent information, making it impossible to isolate whether underperformance is method-intrinsic or protocol-driven.
minor comments (1)
- [Abstract] The abstract states results are obtained 'across millions of transitions' but provides no breakdown by track or number of independent seeds; adding these quantities (with confidence intervals) in the results section would strengthen verifiability without altering the central claim.
Simulated Author's Rebuttal
We thank the referee for their insightful comments. We address the major comment on the evaluation protocol below and will revise the manuscript to incorporate the requested clarifications.
read point-by-point responses
-
Referee: [Evaluation Protocol] The multi-episode evaluation protocol (abstract and §4) is load-bearing for the central claim of no in-context improvement over long horizons. The manuscript does not specify how history length is varied across episodes, how partial-observability observations are tokenized for the transformer-based models, or the exact mechanism by which the random baseline receives equivalent information, making it impossible to isolate whether underperformance is method-intrinsic or protocol-driven.
Authors: We agree with the referee that additional details on the evaluation protocol are necessary for full reproducibility and to substantiate the claims. In the revised manuscript, we will expand the description in Section 4 to specify how history length is varied across episodes, the tokenization of partial-observability observations for the transformer-based models, and the exact mechanism by which the random baseline receives equivalent information. These additions will clarify that the comparison is fair and that the underperformance reflects limitations of the ICRL methods. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical benchmark study introducing ICRL4AHT on Overcooked-V2 and reporting that representative ICRL methods (AD, DPT) underperform random baselines on unseen teammates and layouts. No derivation chain, equations, fitted parameters, or self-citation load-bearing premises exist; the central claims rest on direct experimental comparisons against an external random baseline within the defined protocol. This is self-contained against external benchmarks and receives the default non-circularity outcome.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Overcooked-V2 with partial observability and the generated RL/heuristic teammate suite is representative of ad-hoc teamwork challenges.
Reference graph
Works this paper leans on
-
[1]
org/CorpusID:258845718
URL https://api.semanticscholar. org/CorpusID:258845718. Fu, J., Kumar, A., Nachum, O., Tucker, G., and Levine, S. D4RL: Datasets for deep data-driven reinforcement learning, 2020. Furuta, H., Matsuo, Y ., and Gu, S. S. Generalized decision transformer for offline hindsight information matching. InInternational Conference on Learning Representations, 2022...
2020
-
[2]
Gaussian Error Linear Units (GELUs)
URL https://openreview.net/forum? id=hlvLM3GX8R. Grigsby, J., Fan, J., and Zhu, Y . AMAGO: Scalable in- context reinforcement learning for adaptive agents. In International Conference on Learning Representations, volume 2024, pp. 26919–26952, 2024. Heek, J., Levskaya, A., Oliver, A., Ritter, M., Rondepierre, B., Steiner, A., and van Zee, M. Flax: A neural...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Population Based Training of Neural Networks
URL http://proceedings.mlr.press/ v139/hu21c.html. Jaderberg, M., Dalibard, V ., Osindero, S., Czarnecki, W. M., Donahue, J., Razavi, A., Vinyals, O., Green, T., Dunning, I., Simonyan, K., et al. Population based training of neural networks.arXiv preprint arXiv:1711.09846, 2017. Jaderberg, M., Czarnecki, W. M., Dunning, I., Marris, L., Lever, G., Castaned...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
org/CorpusID:235313679
URL https://api.semanticscholar. org/CorpusID:235313679. Knott, P., Carroll, M., Devlin, S., Ciosek, K., Hofmann, K., Dragan, A., and Shah, R. Evaluating the robustness of collaborative agents. InProceedings of the 20th Interna- tional Conference on Autonomous Agents and MultiAgent Systems, pp. 1560–1562, 2021. Kurach, K., Raichuk, A., Sta´nczyk, P., Zaja...
2021
-
[5]
Lee, K.-H., Nachum, O., Yang, M
URL https://openreview.net/forum? id=dCYBAGQXLo. Lee, K.-H., Nachum, O., Yang, M. S., Lee, L., Free- man, D., Guadarrama, S., Fischer, I., Xu, W., Jang, E., Michalewski, H., et al. Multi-game decision transformers. InAdvances in Neural Information Processing Systems, pp. 27921–27936, 2022. Li, Y ., Zhang, S., Sun, J., Du, Y ., Wen, Y ., Wang, X., and Pan,...
2022
-
[6]
URL https://api.semanticscholar. org/CorpusID:259501163. Moeini, A., Wang, J., Beck, J., Blaser, E., Whiteson, S., Chandra, R., and Zhang, S. A survey of in-context re- inforcement learning.arXiv preprint arXiv:2502.07978, 2025. M¨uller, S., Hollmann, N., Arango, S. P., Grabocka, J., and Hutter, F. Transformers can do Bayesian inference. In International ...
-
[7]
Nikulin, A., Zisman, I., Zemtsov, A., and Kurenkov, V
URL https://openreview.net/forum? id=KSugKcbNf9. Nikulin, A., Zisman, I., Zemtsov, A., and Kurenkov, V . XLand-100b: A large-scale multi-task dataset for in- context reinforcement learning. InThe Thirteenth In- ternational Conference on Learning Representations,
-
[8]
Papoudakis, G., Christianos, F., Sch¨afer, L., and Albrecht, S
URL https://openreview.net/forum? id=p9OsTj0nMP. Papoudakis, G., Christianos, F., Sch¨afer, L., and Albrecht, S. V . Benchmarking multi-agent deep reinforcement learning algorithms in cooperative tasks. InProceed- ings of the Neural Information Processing Systems Track on Datasets and Benchmarks (NeurIPS), 2021. Parker-Holder, J., Pacchiano, A., Choromans...
2021
-
[9]
Rahman, A., Fosong, E., Carlucho, I., and Albrecht, S
URL https://openreview.net/forum? id=gi9MOXNfw2. Rahman, A., Fosong, E., Carlucho, I., and Albrecht, S. V . Generating teammates for training robust ad hoc team- work agents via best-response diversity.Transactions on Machine Learning Research, 2023. ISSN 2835-
2023
-
[10]
Rahman, M., Cui, J., and Stone, P
URL https://openreview.net/forum? id=l5BzfQhROl. Rahman, M., Cui, J., and Stone, P. Minimum coverage sets for training robust ad hoc teamwork agents. InProceed- ings of the AAAI Conference on Artificial Intelligence, volume 38, pp. 17523–17530, 2024. Raparthy, S. C., Hambro, E., Kirk, R., Henaff, M., and Raileanu, R. Generalization to new sequential deci-...
2024
-
[11]
Proximal Policy Optimization Algorithms
URL https://openreview.net/forum? id=lVQ4FUZ6dp. Reed, S., Zolna, K., Parisotto, E., Colmenarejo, S. G., Novikov, A., Barth-maron, G., Gim ´enez, M., Sulsky, Y ., Kay, J., Springenberg, J. T., Eccles, T., Bruce, J., Razavi, A., Edwards, A., Heess, N., Chen, Y ., Hadsell, R., Vinyals, O., Bordbar, M., and de Freitas, N. A generalist agent.Transactions on M...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
URL https://api.semanticscholar. org/CorpusID:278532809. Wu, S., Yao, J., Fu, H., Tian, Y ., Qian, C., Yang, Y ., Fu, Q., and Wei, Y . Quality-similar diversity via population based reinforcement learning. InThe Eleventh International Conference on Learning Representations, 2023. Wu, S. A., Wang, R. E., Evans, J. A., Tenenbaum, J. B., Parkes, D. C., and K...
-
[13]
13 Benchmarking the Limits of In-Context Reinforcement Learning for Ad-Hoc Teamwork A
URL https://openreview.net/forum? id=Y8KsHT1kTV. 13 Benchmarking the Limits of In-Context Reinforcement Learning for Ad-Hoc Teamwork A. OvercookedV2 Environment This section provides a comprehensive specification of the OvercookedV2 environment used in the ICRL4AHT benchmark. We detail the environment mechanics, our implementation enhancements, and the sp...
2025
-
[14]
Random Sampling: From the filtered set, uniformly sample the target number of teammates (default: 20) using a fixed random seed for reproducibility. This procedure reduces the initial 50 candidates to 20 high-quality teammates, ensuring that the training distribution consists of competent partners capable of meaningful coordination. B.2. Heuristic Teammat...
-
[15]
Batch Collector: Orchestrates parallel execution across all tasks in a manifest, with checkpoint-based resume semantics. C.2. PPO Training Procedure We employ Proximal Policy Optimization (PPO) as the ego agent training algorithm, chosen for its stable learning dynamics and widespread adoption in cooperative multi-agent settings. C.2.1. NETWORKARCHITECTUR...
2023
-
[16]
These layers perform channel-wise feature transformation without spatial mixing
Pointwise Feature Extraction: Three 1×1 convolutional layers with 128, 128, and 8 output channels respectively, each followed by ReLU activation. These layers perform channel-wise feature transformation without spatial mixing
-
[17]
with prior
Spatial Feature Extraction: Three 3×3 convolutional layers with 16, 32, and 32 output channels respectively, each followed by ReLU activation. These layers capture local spatial patterns and object relationships. The resulting feature map is flattened and projected through a dense layer to produce an embedding of dimension demb = 64. All convolutional and...
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.