From Prompting to Verification: How Experience Shapes Vibe Coding Practices
Pith reviewed 2026-06-30 13:11 UTC · model grok-4.3
The pith
Experience creates a perception-action gap where awareness of AI code risks is common but the ability to verify outputs depends on prior development experience.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
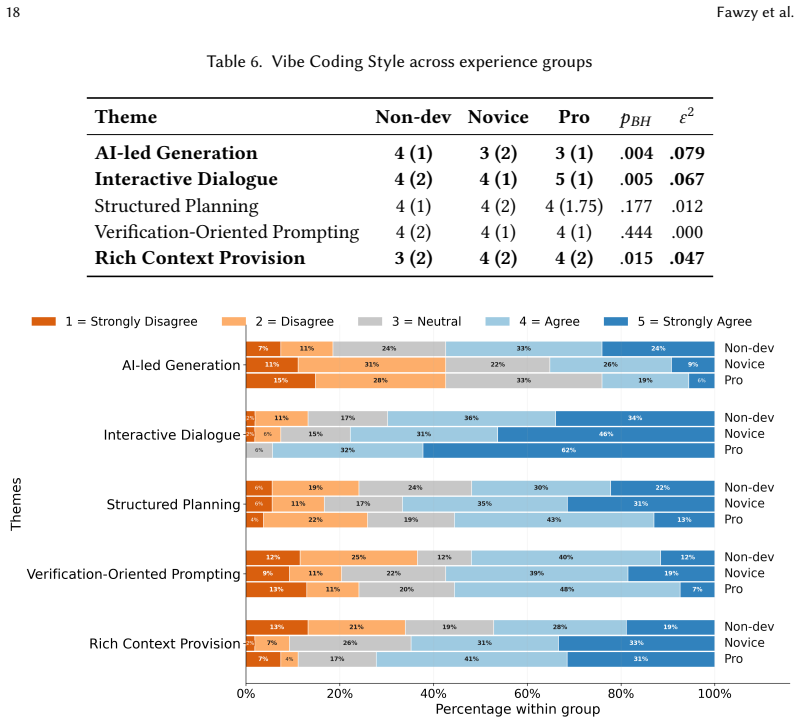
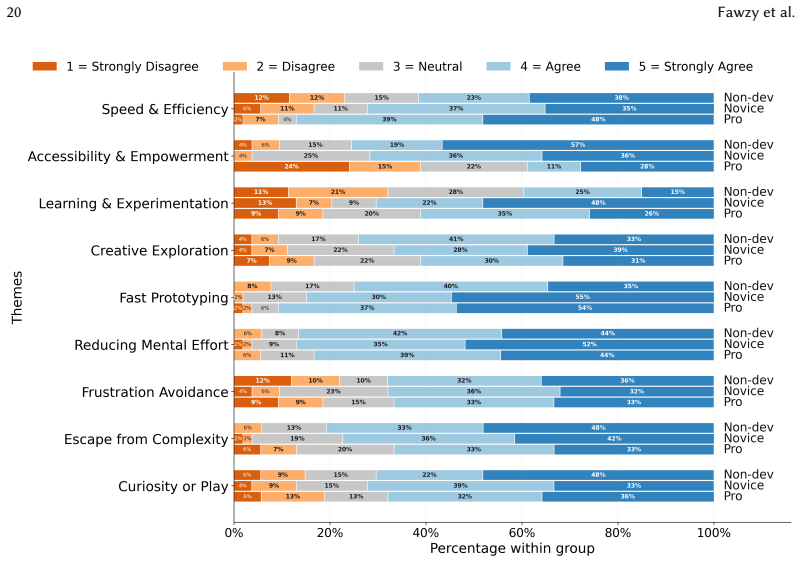
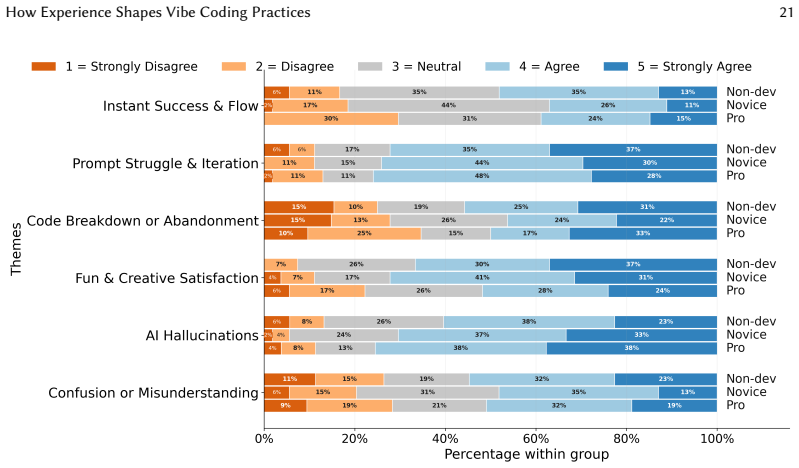
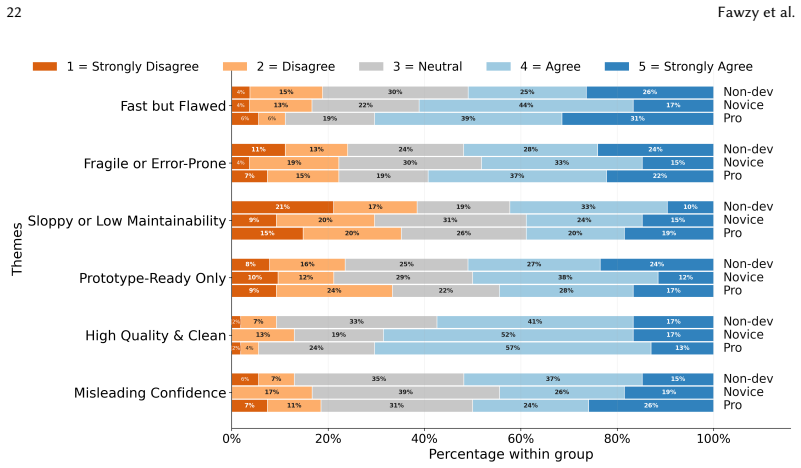
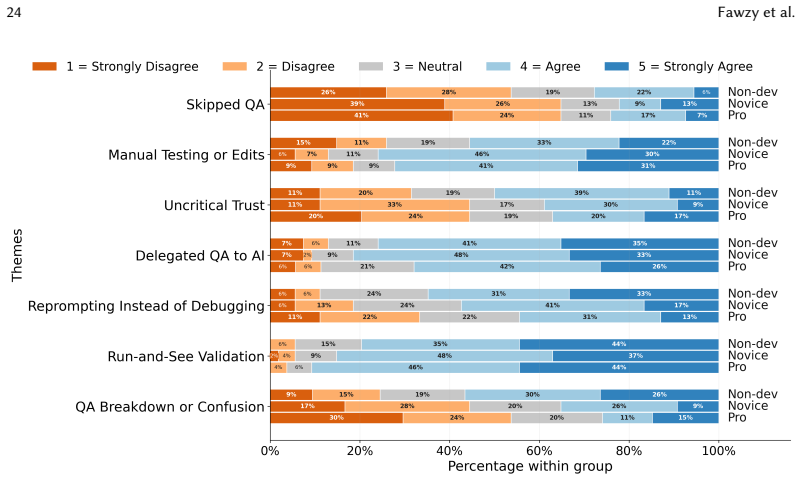
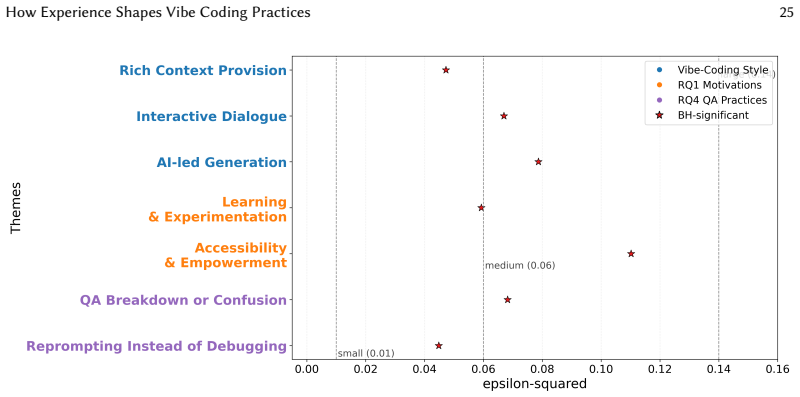
The central claim is that vibe coding produces a perception-action gap: all three experience groups recognise both the strengths and limitations of AI-generated code, yet only the capacity to evaluate, debug, and verify outputs scales with prior development experience. Motivations and quality-assurance behaviours therefore separate cleanly by group while reported perceptions of quality do not.
What carries the argument
The perception-action gap, the disconnect between broadly distributed awareness of risks in AI-generated code and the experience-dependent capacity to evaluate, debug, and verify it.
If this is right
- Vibe coding partially democratises software creation by widening access while leaving verification skills unevenly distributed.
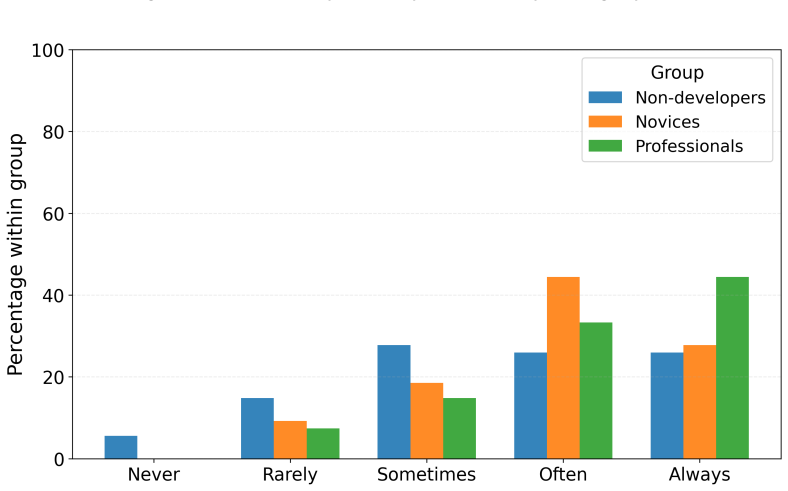
- Quality assurance practices and interaction styles improve selectively with development experience.
- Non-coders are motivated primarily by accessibility, novices by learning and experimentation, and professionals by work-related tasks.
- General awareness of AI code risks does not translate into equivalent verification behaviour across experience levels.
Where Pith is reading between the lines
- The gap suggests that training focused on verification techniques rather than prompting alone could narrow differences between groups.
- Non-coders may generate larger volumes of unverified code that later requires professional intervention.
- Tool designers could add explicit verification scaffolding that reduces reliance on prior experience.
Load-bearing premise
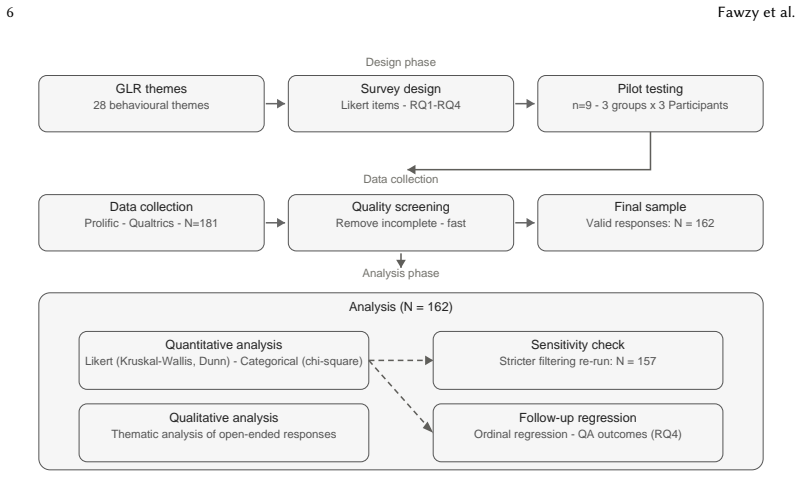
Self-reported survey answers from the 162 participants accurately capture their real practices and the three experience groups are cleanly separable without major sampling or response biases.
What would settle it
An observational study that records actual prompting, execution, and verification steps of matched participants from each experience group and compares those behaviours against the survey self-reports.
Figures
read the original abstract
AI code generation tools have expanded software creation beyond professional developers, giving rise to vibe coding, a practice in which users generate software via natural-language prompts, evaluate outputs primarily by execution. Prior work has examined how AI code generation tools support programming tasks within specific user groups, typically professional developers, leaving open the question of how vibe coding practices differ across experience levels. We address this gap by surveying 162 vibe coders belonging to three user experience groups: non-coders, novices, and professional developers. Our results show that experience selectively shapes vibe coding. Reported experiences and perceptions of code quality are broadly similar across groups, with all three recognising both the strengths and limitations of vibe coding. In contrast, motivations, interaction styles, and quality assurance practices diverge with experience. Non-developers are most motivated by accessibility, novices emphasise learning and experimentation, and professionals use vibe coding more frequently in work-related contexts. We synthesise these findings as a perception--action gap: a general awareness of risks in AI-generated code is broadly distributed, but the capacity to evaluate, debug, and verify remains experience-dependent. We show that vibe coding is partially democratising as it broadens access to software creation without equally distributing the expertise to evaluate it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports results from a survey of 162 participants grouped into non-coders, novices, and professional developers on their use of AI code generation tools for 'vibe coding' (prompt-based generation evaluated primarily by execution). It claims that perceptions of code quality and risk awareness are broadly similar across groups, while motivations, interaction styles, and quality-assurance practices diverge with experience. The authors synthesize these patterns as a perception-action gap in which general awareness of AI-code limitations is distributed but the capacity to evaluate, debug, and verify remains experience-dependent, implying partial rather than full democratization of software creation.
Significance. If the empirical patterns hold after methodological strengthening, the work usefully extends prior AI-assisted programming studies by including non-professional users and by framing experience as a selective rather than uniform shaper of practice. The multi-group design and the explicit articulation of a perception-action gap supply a concrete hypothesis that future work can test with performance measures. The study also supplies descriptive data on how non-developers versus professionals approach the same tools, which is relevant to tool builders and computing-education researchers.
major comments (3)
- [Methods] Methods section: the manuscript provides no information on questionnaire item wording, response scales, piloting, or any validation steps for the self-report measures of quality-assurance practices (debugging frequency, verification steps). Because the perception-action gap claim rests on interpreting these self-reports as evidence of differential verification capacity, the absence of instrument details and bias-mitigation procedures is load-bearing.
- [Results and Discussion] Results/Discussion: the synthesis that 'capacity to evaluate, debug, and verify remains experience-dependent' is drawn solely from retrospective self-reports without objective performance tasks, think-aloud protocols, or artifact analysis. If professionals simply apply stricter internal standards when answering, the reported differences could reflect reporting bias rather than capability; this alternative explanation is not addressed and directly threatens the central claim.
- [Methods] Participant grouping: the criteria used to assign the 162 respondents to the three experience categories (non-coders, novices, professionals) and any checks for overlap or sampling bias are not described. Clean separability of groups is presupposed by all cross-group comparisons yet is not demonstrated.
minor comments (2)
- [Abstract] Abstract: the sample size (162) and group breakdown appear only in the body; moving the key demographic numbers into the abstract would improve immediate readability.
- [Introduction] Terminology: 'vibe coding' is introduced without an explicit operational definition or citation to prior usage; a short definitional sentence in the introduction would reduce ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where methodological transparency can be strengthened. We respond to each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Methods] Methods section: the manuscript provides no information on questionnaire item wording, response scales, piloting, or any validation steps for the self-report measures of quality-assurance practices (debugging frequency, verification steps). Because the perception-action gap claim rests on interpreting these self-reports as evidence of differential verification capacity, the absence of instrument details and bias-mitigation procedures is load-bearing.
Authors: We agree the manuscript should provide these details. The revised version will include the exact wording of items related to quality-assurance practices, the 5-point response scales employed, a description of the pilot testing with 12 participants, and steps taken to mitigate bias such as anonymous administration and neutral item phrasing. revision: yes
-
Referee: [Results and Discussion] Results/Discussion: the synthesis that 'capacity to evaluate, debug, and verify remains experience-dependent' is drawn solely from retrospective self-reports without objective performance tasks, think-aloud protocols, or artifact analysis. If professionals simply apply stricter internal standards when answering, the reported differences could reflect reporting bias rather than capability; this alternative explanation is not addressed and directly threatens the central claim.
Authors: Our study is a survey capturing self-reported perceptions and practices; objective performance data would require a different design. We will revise the discussion to explicitly acknowledge the possibility of reporting bias as a limitation and to qualify the perception-action gap as reflecting reported divergences in practices rather than directly measured capability. This preserves the descriptive contribution while noting the need for future behavioral studies. revision: partial
-
Referee: [Methods] Participant grouping: the criteria used to assign the 162 respondents to the three experience categories (non-coders, novices, and professionals) and any checks for overlap or sampling bias are not described. Clean separability of groups is presupposed by all cross-group comparisons yet is not demonstrated.
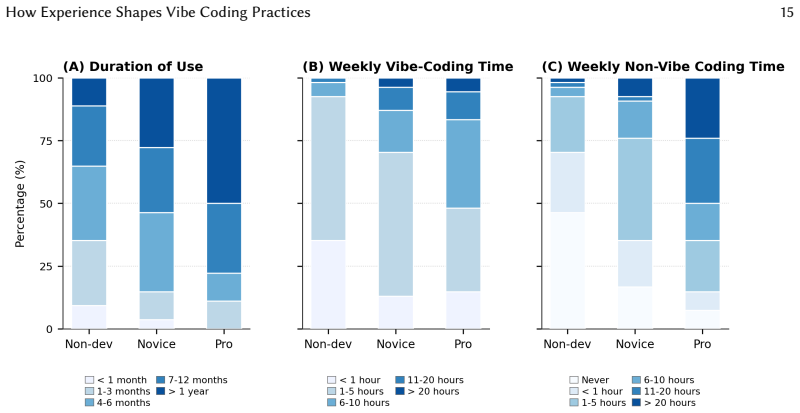
Authors: Grouping relied on self-reported screening questions: non-coders reported zero prior coding experience, novices reported 0–2 years, and professionals reported more than 2 years plus current employment in software development. The revised methods section will detail these criteria, report any post-survey checks for group overlap, and discuss potential sampling biases arising from recruitment channels. revision: yes
Circularity Check
No circularity: empirical survey with independent data collection
full rationale
This paper reports results from a survey of 162 participants grouped by self-reported experience level. The central claim (perception-action gap) is synthesized directly from the collected responses on motivations, interaction styles, and quality-assurance practices. No equations, fitted parameters, derivations, or self-citation chains appear in the provided text. The survey responses constitute external data relative to the authors' prior work; the synthesis step does not reduce any quantity to a prior fit or definition by construction. The study is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-reported survey responses provide reliable data on user motivations, interaction styles, and quality assurance practices.
Reference graph
Works this paper leans on
-
[1]
2010.Analysis of Ordinal Categorical Data(2nd ed.)
Alan Agresti. 2010.Analysis of Ordinal Categorical Data(2nd ed.). Wiley
2010
-
[2]
Sri Haritha Ambati, Norah Ridley, Enrico Branca, and Natalia Stakhanova. 2024. Navigating (in) security of AI-generated code. In2024 IEEE international conference on cyber security and resilience (CSR). IEEE, 1–8
2024
-
[3]
Alberto Bacchelli and Christian Bird. 2013. Expectations, outcomes, and challenges of modern code review. In2013 35th international conference on software engineering (ICSE). IEEE, 712–721
2013
-
[4]
Sebastian Baltes and Stephan Diehl. 2018. Towards a theory of software development expertise. InProceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). 187–200
2018
-
[5]
Shraddha Barke, Michael B James, and Nadia Polikarpova. 2023. Grounded Copilot: How programmers interact with code-generating models.Proceedings of the ACM on Programming Languages7, OOPSLA1 (2023), 85–111
2023
- [6]
-
[7]
Yoav Benjamini and Yosef Hochberg. 1995. Controlling the false discovery rate: A practical and powerful approach to multiple testing.Journal of the Royal Statistical Society: Series B57, 1 (1995), 289–300
1995
-
[8]
Christian Bird, Denae Ford, Thomas Zimmermann, Nicole Forsgren, Eirini Kalliamvakou, Travis Lowdermilk, and Idan Gazit. 2022. Taking Flight with Copilot: Early Insights and Opportunities of AI-Powered Pair-Programming Tools. Queue20, 6 (2022), 35–57. doi:10.1145/3582083
-
[9]
Rollin Brant. 1990. Assessing Proportionality in the Proportional Odds Model for Ordinal Logistic Regression.Biometrics 46, 4 (1990), 1171–1178
1990
-
[10]
Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psychology.Qualitative Research in Psychology3, 2 (2006), 77–101
2006
-
[11]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Valerie Chen, Jasmyn He, Behnjamin Williams, Jason Valentino, and Ameet Talwalkar. 2026. Beyond the Commit: Developer Perspectives on Productivity with AI Coding Assistants. InProceedings of the 48th IEEE/ACM International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP ’26). Association for Computing Machinery, New York, N...
2026
-
[13]
2013.Statistical power analysis for the behavioral sciences
Jacob Cohen. 2013.Statistical power analysis for the behavioral sciences. Routledge
2013
-
[14]
1999.Practical nonparametric statistics
William Jay Conover. 1999.Practical nonparametric statistics. John Wiley & Sons
1999
-
[15]
Creswell and J
John W. Creswell and J. David Creswell. 2018.Research Design: Qualitative, Quantitative, and Mixed Methods Approaches (5 ed.). SAGE Publications
2018
-
[16]
Paul G. Curran. 2016. Methods for the Detection of Carelessly Invalid Responses in Survey Data.Journal of Experimental Social Psychology66 (2016), 4–19. doi:10.1016/j.jesp.2015.07.006 How Experience Shapes Vibe Coding Practices 31
-
[17]
Paul Denny, James Prather, Brett A Becker, James Finnie-Ansley, Arto Hellas, Juho Leinonen, Andrew Luxton-Reilly, Brent N Reeves, Eddie Antonio Santos, and Sami Sarsa. 2024. Computing education in the era of generative AI. Commun. ACM67, 2 (2024), 56–67
2024
-
[18]
Justin A DeSimone, Peter D Harms, and Alice J DeSimone. 2015. Best practice recommendations for data screening. Journal of Organisational Behaviour36, 2 (2015), 171–181
2015
-
[19]
K Anders Ericsson, Ralf T Krampe, and Clemens Tesch-Römer. 1993. The role of deliberate practice in the acquisition of expert performance.Psychological review100, 3 (1993), 363
1993
-
[20]
Sarah Fakhoury, Aaditya Naik, Georgios Sakkas, Saikat Chakraborty, and Shuvendu K Lahiri. 2024. Llm-based test- driven interactive code generation: User study and empirical evaluation.IEEE Transactions on Software Engineering50, 9 (2024), 2254–2268
2024
-
[21]
Ahmed Fawzy, Amjed Tahir, and Kelly Blincoe. 2026. Vibe Coding in Practice: Motivations, Challenges, and a Future Outlook–a Grey Literature Review. InProceedings of the 48th IEEE/ACM International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP ’26). Association for Computing Machinery, New York, NY, USA, 9 pages
2026
-
[22]
FedTec. 2025. Vibe Coding: Accelerating Service Delivery in the Government. https://fedtec.com/insights/vibe-coding- accelerating-service-delivery-in-the-government/. Accessed: 2026-05-07
2025
-
[23]
Molly Q Feldman and Carolyn Jane Anderson. 2024. Non-expert programmers in the generative AI future. InProceedings of the 3rd Annual Meeting of the Symposium on Human-Computer Interaction for Work. 1–19
2024
-
[24]
2024.Discovering statistics using IBM SPSS statistics
Andy Field. 2024.Discovering statistics using IBM SPSS statistics. Sage Publications Limited
2024
-
[25]
John Fox and Georges Monette. 1992. Generalized Collinearity Diagnostics.J. Amer. Statist. Assoc.87, 417 (1992), 178–183
1992
-
[26]
Daniel Fried, Armen Aghajanyan, Jessy Lin, Sida Wang, Eric Wallace, Freda Shi, Ruiqi Zhong, Wen-tau Yih, Luke Zettlemoyer, and Mike Lewis. 2023. InCoder: A Generative Model for Code Infilling and Synthesis. InProceedings of the 11th International Conference on Learning Representations (ICLR). https://openreview.net/forum?id=hQwb-lbM6EL
2023
-
[27]
Yujia Fu, Peng Liang, Amjed Tahir, Zengyang Li, Mojtaba Shahin, Jiaxin Yu, and Jinfu Chen. 2025. Security weaknesses of copilot-generated code in github projects: An empirical study.ACM Transactions on Software Engineering and Methodology34, 8 (2025), 1–34
2025
-
[28]
Matthias Galster, Muhammad Auwal Abubakar, Seyedmoein Mohsenimofidi, Christoph Treude, Jai Lal Lulla, and Sebastian Baltes. 2026. Configuring Agentic AI Coding Tools: An Exploratory Study.arXiv preprint arXiv:2602.14690 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [29]
- [30]
-
[31]
David M Groppe, Thomas P Urbach, and Marta Kutas. 2011. Mass univariate analysis of event-related brain poten- tials/fields I: A critical tutorial review.Psychophysiology48, 12 (2011), 1711–1725
2011
-
[32]
Hao He, Courtney Miller, Shyam Agarwal, Christian Kästner, and Bogdan Vasilescu. 2026. Speed at the Cost of Quality: How Cursor AI Increases Short-Term Velocity and Long-Term Complexity in Open-Source Projects. InProceedings of the 23rd International Conference on Mining Software Repositories (MSR ’26). ACM, Rio de Janeiro, Brazil
2026
-
[33]
Michael Hilton, Timothy Tunnell, Kai Huang, Darko Marinov, and Danny Dig. 2016. Usage, costs, and benefits of continuous integration in open-source projects. InProceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering (ASE). 426–437
2016
-
[34]
Sture Holm. 1979. A simple sequentially rejective multiple test procedure.Scandinavian Journal of Statistics6, 2 (1979), 65–70
1979
- [35]
-
[36]
Jason L Huang, Mengqiao Liu, and Nathan A Bowling. 2015. Insufficient effort responding: examining an insidious confound in survey data.Journal of Applied Psychology100, 3 (2015), 828
2015
-
[37]
Saki Imai. 2022. Is GitHub Copilot a Substitute for Human Pair-Programming? An Empirical Study. InProceedings of the ACM/IEEE 44th International Conference on Software Engineering: Companion Proceedings (ICSE-Companion). Association for Computing Machinery, New York, NY, USA, 319–321. doi:10.1145/3510454.3522684
-
[38]
Vibe Coding
Andrej Karpathy. 2025. There’s a New Kind of Coding I Call “Vibe Coding”. https://x.com/karpathy/status/ 1886192184808149383. Accessed: 2026-05-07
2025
-
[39]
Majeed Kazemitabaar, Justin Chow, Carl Ka To Ma, Barbara J Ericson, David Weintrop, and Tovi Grossman. 2023. Studying the effect of AI code generators on supporting novice learners in introductory programming. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–23. 32 Fawzy et al
2023
-
[40]
Amy J Ko, Robin Abraham, Laura Beckwith, Alan Blackwell, Margaret Burnett, Martin Erwig, Chris Scaffidi, Joseph Lawrance, Henry Lieberman, Brad Myers, et al. 2011. The state of the art in end-user software engineering.ACM Computing Surveys (CSUR)43, 3 (2011), 1–44
2011
-
[41]
Thomas D LaToza and Brad A Myers. 2010. Developers ask reachability questions. InProceedings of the 32nd ACM/IEEE International Conference on Software Engineering (ICSE). 185–194
2010
-
[42]
Dominik J. Leiner. 2019. Too Fast, Too Straight, Too Weird: Non-Reactive Indicators for Meaningless Data in Internet Surveys.Survey Research Methods13, 3 (2019), 229–248. doi:10.18148/srm/2019.v13i3.7403
-
[43]
Jenny T Liang, Chenyang Yang, and Brad A Myers. 2024. A large-scale survey on the usability of AI programming assis- tants: Successes and challenges. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering (ICSE). 1–13
2024
-
[44]
2015.Guidelines for Conducting Surveys in Software Engineering
Johan Linåker, Sardar Muhammad Sulaman, Rafael Maiani de Mello, and Martin Höst. 2015.Guidelines for Conducting Surveys in Software Engineering. Technical Report. Department of Computer Science, Lund University. https: //lup.lub.lu.se/search/files/6062997/5463412.pdf
-
[45]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2023. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation.Advances in neural information processing systems36 (2023), 21558–21572
2023
-
[46]
Noble Saji Mathews and Meiyappan Nagappan. 2024. Test-driven development and llm-based code generation. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 1583–1594
2024
-
[47]
Peter McCullagh. 1980. Regression Models for Ordinal Data.Journal of the Royal Statistical Society: Series B42, 2 (1980), 109–142
1980
-
[48]
Adam W. Meade and S. Bartholomew Craig. 2012. Identifying Careless Responses in Survey Data.Psychological Methods17, 3 (2012), 437–455. doi:10.1037/a0028085
-
[49]
Ivan Mehta. 2025. A Quarter of YC’s Startups Have Codebases That Are Almost Entirely AI-Generated. https://techcrunch.com/2025/03/06/a-quarter-of-startups-in-ycs-current-cohort-have-codebases-that-are-almost- entirely-ai-generated. Accessed: 2026-05-07
2025
-
[50]
Hussein Mozannar, Gagan Bansal, Adam Fourney, and Eric Horvitz. 2024. Reading Between the Lines: Modeling User Behavior and Costs in AI-Assisted Programming. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 142, 16 pages. doi:10.1145/3613904.3641936
-
[51]
Brad A Myers, Amy J Ko, and Margaret M Burnett. 2006. Invited research overview: end-user programming. InCHI’06 extended abstracts on Human factors in computing systems. 75–80
2006
-
[52]
1993.A small matter of programming: perspectives on end user computing
Bonnie A Nardi. 1993.A small matter of programming: perspectives on end user computing. MIT Press
1993
-
[53]
Nhan Nguyen and Sarah Nadi. 2022. An empirical evaluation of GitHub Copilot’s code suggestions. InProceedings of the 19th International Conference on Mining Software Repositories (MSR). 1–5
2022
-
[54]
Chris Parnin and Alessandro Orso. 2011. Are automated debugging techniques actually helping programmers?. In Proceedings of the 2011 International Symposium on Software Testing and Analysis (ISSTA). 199–209
2011
-
[55]
Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt, and Ramesh Karri. 2025. Asleep at the Keyboard? Assessing the Security of GitHub Copilot’s Code Contributions.Commun. ACM68, 2 (Feb. 2025), 96–105. doi:10.1145/3610721
-
[56]
Eyal Peer, Laura Brandimarte, Sonam Samat, and Alessandro Acquisti. 2017. Beyond the Turk: Alternative platforms for crowdsourcing behavioral research.Journal of Experimental Social Psychology70 (2017), 153–163
2017
-
[57]
Sida Peng, Eirini Kalliamvakou, Peter Cihon, and Mert Demirer. 2023. The impact of ai on developer productivity: Evidence from github copilot.arXiv preprint arXiv:2302.06590(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
Neil Perry, Megha Srivastava, Deepak Kumar, and Dan Boneh. 2023. Do users write more insecure code with ai assistants?. InProceedings of the 2023 ACM SIGSAC conference on computer and communications security. 2785–2799
2023
-
[59]
Philip M Podsakoff, Scott B MacKenzie, Jeong-Yeon Lee, and Nathan P Podsakoff. 2003. Common method biases in behavioral research: a critical review of the literature and recommended remedies.Journal of applied psychology88, 5 (2003), 879
2003
-
[60]
It’s Weird That It Knows What I Want
James Prather, Brent N Reeves, Paul Denny, Brett A Becker, Juho Leinonen, Andrew Luxton-Reilly, Garrett Powell, James Finnie-Ansley, and Eddie Antonio Santos. 2023. “It’s Weird That It Knows What I Want”: Usability and Interactions with Copilot for Novice Programmers.ACM transactions on computer-human interaction31, 1 (2023), 1–31
2023
-
[61]
Teade Punter, Marcus Ciolkowski, Bernd Freimut, and Isabel John. 2003. Conducting on-line surveys in software engineering. InInternational Symposium on Empirical Software Engineering (EMSE). IEEE, 80–88
2003
-
[62]
Brian J Reiser. 2018. Scaffolding complex learning: The mechanisms of structuring and problematizing student work. InScaffolding. Psychology Press, 273–304. How Experience Shapes Vibe Coding Practices 33
2018
-
[63]
Gustavo Sandoval, Hammond Pearce, Teo Nys, Ramesh Karri, Siddharth Garg, and Brendan Dolan-Gavitt. 2023. Lost at c: A user study on the security implications of large language model code assistants. In32nd USENIX Security Symposium (USENIX Security 23). 2205–2222
2023
-
[64]
Christopher Scaffidi, Mary Shaw, and Brad Myers. 2005. Estimating the numbers of end users and end user programmers. In2005 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC’05). IEEE, 207–214
2005
-
[65]
Janet Siegmund, Christian Kästner, Sven Apel, Chris Parnin, Anja Bethmann, Thomas Leich, Gunter Saake, and André Brechmann. 2014. Understanding understanding source code with functional magnetic resonance imaging. In Proceedings of the 36th International Conference on Software Engineering (ICSE). 378–389
2014
-
[66]
Stack Overflow. 2025. 2025 Stack Overflow Developer Survey. https://survey.stackoverflow.co/2025/. Accessed: 2026-05-07
2025
-
[67]
Florian Tambon, Arghavan Moradi-Dakhel, Amin Nikanjam, Foutse Khomh, Michel C Desmarais, and Giuliano Antoniol. 2025. Bugs in large language models generated code: An empirical study.Empirical Software Engineering30, 3 (2025), 65
2025
-
[68]
Ningzhi Tang, Meng Chen, Zheng Ning, Aakash Bansal, Yu Huang, Collin McMillan, and Toby Jia-Jun Li. 2024. Developer behaviors in validating and repairing llm-generated code using ide and eye tracking. In2024 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC). IEEE, 40–46
2024
-
[69]
Priyan Vaithilingam, Tianyi Zhang, and Elena L Glassman. 2022. Expectation vs. experience: Evaluating the usability of code generation tools powered by large language models. InCHI Conference on Human Factors in Computing Systems Extended Abstracts. 1–7
2022
-
[70]
Kurt VanLehn. 2011. The relative effectiveness of human tutoring, intelligent tutoring systems, and other tutoring systems.Educational psychologist46, 4 (2011), 197–221
2011
-
[71]
Koen JF Verhoeven, Katy L Simonsen, and Lauren M McIntyre. 2005. Implementing false discovery rate control: increasing your power.Oikos108, 3 (2005), 643–647
2005
- [72]
-
[73]
Ruotong Wang, Ruijia Cheng, Denae Ford, and Thomas Zimmermann. 2024. Investigating and designing for trust in ai-powered code generation tools. InProceedings of the 2024 ACM conference on fairness, accountability, and transparency. 1475–1493
2024
-
[74]
Yue Wang, Weishi Wang, Shafiq Joty, and Steven CH Hoi. 2021. Codet5: Identifier-aware unified pre-trained encoder- decoder models for code understanding and generation. InProceedings of the 2021 conference on Empirical Methods in Natural Language Processing. 8696–8708
2021
-
[75]
David Weintrop and Uri Wilensky. 2019. Transitioning from introductory block-based and text-based environments to professional programming languages in high school computer science classrooms.Computers & Education142 (2019), 103646
2019
-
[76]
Rainer Winkler and Matthias Söllner. 2018. Unleashing the Potential of Chatbots in Education: A State-of-the-Art Analysis. InAcademy of Management Proceedings, Vol. 2018. Academy of Management, Briarcliff Manor, NY, 15903. doi:10.5465/AMBPP.2018.15903abstract
-
[77]
Angela Yang. 2025. Noncoders Are Using AI to Prompt Their Ideas Into Reality. They Call It ‘Vibe Coding’. https: //www.nbcnews.com/tech/tech-news/noncoders-ai-prompt-ideas-vibe-coding-rcna205661. Accessed: 2026-05-07
2025
-
[78]
The AI Tool Can’t Make It Any Worse
Asli Yardim, Raphael Serafini, Nadine Jost, Anna-Marie Ortloff, Joshua Gabriel Speckels, and Alena Naiakshina. 2026. “The AI Tool Can’t Make It Any Worse. ” Investigating Developers’ Security Behavior with AI Assistants in a Password Storage Study. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems. 1–33
2026
- [79]
-
[80]
Beiqi Zhang, Peng Liang, Xiyu Zhou, Aakash Ahmad, and Muhammad Waseem. 2023. Practices and Challenges of Using GitHub Copilot: An Empirical Study. InProceedings of the 35th International Conference on Software Engineering and Knowledge Engineering (SEKE). KSI Research Inc., 124–129. doi:10.18293/SEKE2023-077
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.