Deep ZakaiJ: Structured Filtering for Jump-Diffusion Time Series Forecasting
Pith reviewed 2026-06-30 14:28 UTC · model grok-4.3
The pith
Embedding the Zakai equation via Strang splitting in a neural encoder-decoder improves distributional forecasts for jump-diffusion time series with latent states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
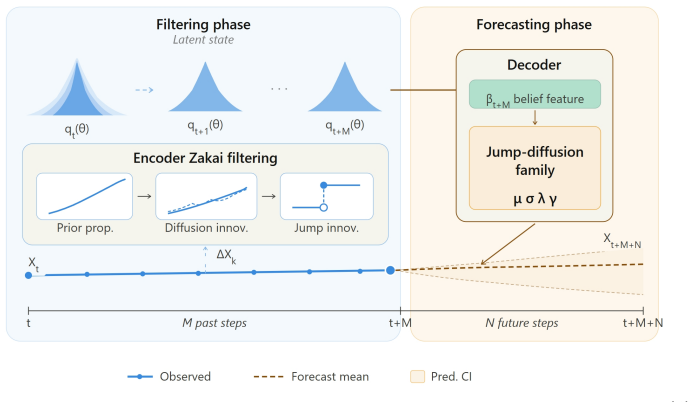
Deep ZakaiJ is a latent-state model for partially observed jump-diffusion systems that embeds the Zakai nonlinear filtering equation into a neural encoder--decoder architecture. The encoder recursively updates a belief over the latent state via Strang splitting into three interpretable substeps: prior propagation, diffusion innovation, and jump innovation, yielding a differentiable, first-order-accurate approximation of the exact filtering evolution. The decoder is a structured jump-diffusion model explicitly conditioned on the filtered belief, preserving the separation between continuous dynamics and discontinuous shocks. On synthetic, financial, and oceanographic datasets, Deep ZakaiJ impr
What carries the argument
Strang splitting of the Zakai nonlinear filtering equation into prior propagation, diffusion innovation, and jump innovation substeps embedded inside the neural encoder.
If this is right
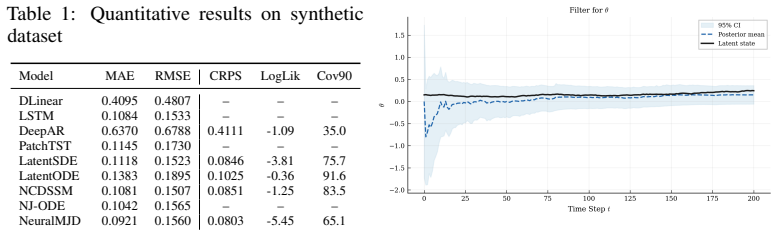
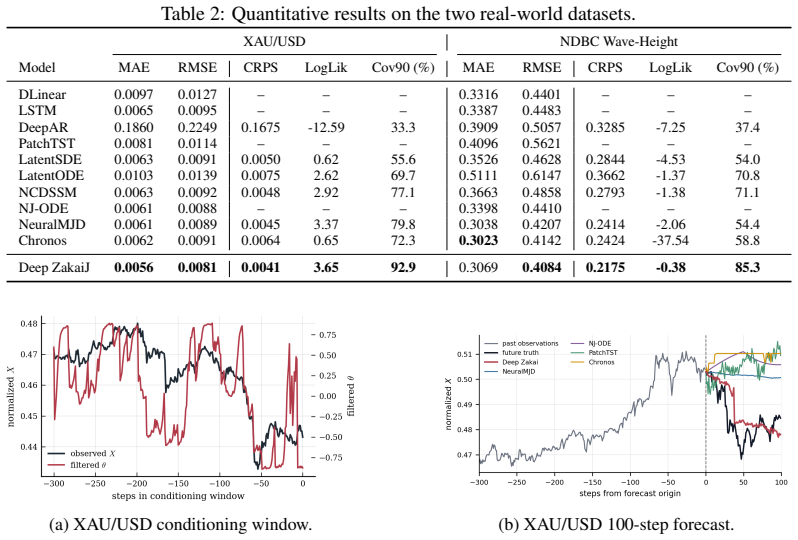
- Distributional forecasts improve on synthetic, financial, and oceanographic data while point accuracy remains competitive.
- Predictive intervals achieve calibration.
- The model recovers interpretable latent structure corresponding to the hidden drivers of jumps.
Where Pith is reading between the lines
- The explicit separation of diffusion and jump updates could support targeted adjustments when only one type of shock matters for a downstream decision.
- Because the encoder maintains a belief state, the same architecture might be applied to control or reinforcement learning problems where actions depend on inferred latent dynamics.
- Replacing the first-order Strang splitting with a higher-order integrator would be a direct next step to test whether forecast sharpness can be increased without losing differentiability.
Load-bearing premise
The Strang splitting produces a differentiable first-order approximation to the Zakai equation that keeps the continuous diffusion and jump components cleanly separated when the whole procedure is placed inside the neural network.
What would settle it
If the model's predictive intervals on a new dataset with recorded jump times show empirical coverage rates that deviate substantially from the nominal levels, the claim of calibrated distributional forecasts would be refuted.
Figures
read the original abstract
Time series driven by unobserved latent states frequently exhibit abrupt jump discontinuities whose timing and magnitude cannot be predicted from observed history alone. Classical jump-diffusion models offer a principled mathematical framework but assume rigid parametric forms, while recent neural jump models operate on fully observed trajectories without inferring the hidden states that govern the dynamics. We propose \textit{Deep ZakaiJ}, a latent-state model for partially observed jump-diffusion systems that embeds the Zakai nonlinear filtering equation into a neural encoder--decoder architecture. The encoder recursively updates a belief over the latent state via Strang splitting into three interpretable substeps: prior propagation, diffusion innovation, and jump innovation, yielding a differentiable, first-order-accurate approximation of the exact filtering evolution. The decoder is a structured jump-diffusion model explicitly conditioned on the filtered belief, preserving the separation between continuous dynamics and discontinuous shocks. On synthetic, financial, and oceanographic datasets, \textit{Deep ZakaiJ} improves distributional forecasts while remaining competitive in point accuracy, achieving calibrated predictive intervals and recovering interpretable latent structure in synthetic and qualitative case studies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Deep ZakaiJ, a latent-state neural model for partially observed jump-diffusion time series. It embeds the Zakai nonlinear filtering equation into an encoder-decoder architecture, where the encoder recursively updates the latent belief via Strang splitting into prior propagation, diffusion innovation, and jump innovation substeps (claimed to be differentiable and first-order accurate). The decoder is a structured jump-diffusion model conditioned on the filtered belief. Experiments on synthetic, financial, and oceanographic datasets report improved distributional forecasts, competitive point accuracy, calibrated predictive intervals, and recovery of interpretable latent structure.
Significance. If the Strang splitting approximation is shown to preserve the required separation and accuracy properties, the work would offer a principled integration of stochastic filtering theory with neural time-series models, enabling better handling of jump discontinuities in latent dynamics and improved uncertainty quantification. The structured separation of continuous and discontinuous components is a potential strength for interpretability if rigorously validated.
major comments (2)
- [Encoder and Strang splitting description] The central claim that Strang splitting produces a differentiable first-order-accurate approximation of the Zakai equation while preserving separation between continuous and jump dynamics (abstract and encoder description) lacks any error bound, consistency proof, Itô-integral justification, or numerical order verification. This is load-bearing for the calibration and interpretability results, as degradation of the splitting order or coupling in the neural parameterization would invalidate the isolation of dynamics fed to the decoder.
- [Method (encoder)] No derivation or reference is given for how the three substeps (prior propagation, diffusion innovation, jump innovation) remain first-order accurate under the stochastic observation semimartingale and the neural parameterization; without this, the downstream claims of calibrated intervals on real datasets rest on an unverified approximation.
minor comments (2)
- [Notation and model definition] Notation for the filtered belief and the decoder conditioning should be introduced with explicit equations rather than descriptive text only.
- [Experiments] The experimental section would benefit from explicit reporting of the number of runs, error bars on all metrics, and the precise data-exclusion rules used for the oceanographic and financial case studies.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments focusing on the theoretical justification of the Strang splitting approximation in the encoder. We respond point by point below.
read point-by-point responses
-
Referee: [Encoder and Strang splitting description] The central claim that Strang splitting produces a differentiable first-order-accurate approximation of the Zakai equation while preserving separation between continuous and jump dynamics (abstract and encoder description) lacks any error bound, consistency proof, Itô-integral justification, or numerical order verification. This is load-bearing for the calibration and interpretability results, as degradation of the splitting order or coupling in the neural parameterization would invalidate the isolation of dynamics fed to the decoder.
Authors: We agree that the current manuscript does not supply a formal error bound, consistency proof, or Itô-integral analysis for the Strang splitting under the neural parameterization and stochastic semimartingale observations. The first-order accuracy statement rests on the classical properties of Strang splitting for deterministic operators, applied heuristically here. In revision we will add citations to the numerical SDE and filtering literature on operator splitting and include numerical order verification experiments in an appendix. A complete rigorous proof lies outside the scope of this work. revision: partial
-
Referee: [Method (encoder)] No derivation or reference is given for how the three substeps (prior propagation, diffusion innovation, jump innovation) remain first-order accurate under the stochastic observation semimartingale and the neural parameterization; without this, the downstream claims of calibrated intervals on real datasets rest on an unverified approximation.
Authors: The substeps follow directly from applying Strang splitting to the Zakai equation to isolate prior propagation from the diffusion and jump components of the innovation. We will revise the method section to include a short derivation outline together with references to established splitting techniques for jump-diffusion filtering. The neural parameterization is constructed to respect the same structural separation. We accept that additional justification is required and will supply it. revision: yes
- A full Itô-integral consistency proof and error bound for the neural-parameterized Strang splitting under stochastic observations.
Circularity Check
No significant circularity; derivation presented as independent construction
full rationale
The paper proposes Deep ZakaiJ as a new neural encoder-decoder architecture that embeds the Zakai equation via Strang splitting into three substeps. No equations, claims, or results in the provided text reduce the central assertions (differentiable first-order approximation, separation of dynamics, calibrated forecasts) to fitted parameters renamed as predictions, self-citations that bear the load of uniqueness or accuracy, or ansatzes smuggled from prior author work. The architecture and its claimed properties are introduced directly as a novel construction without self-referential reduction. This is the common case of a self-contained proposal whose validity rests on external verification rather than internal definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Zakai nonlinear filtering equation governs the evolution of the conditional distribution over latent states in jump-diffusion systems.
Reference graph
Works this paper leans on
-
[1]
A survey of methods for time series change point detection.Knowledge and Information Systems, 51(2):339–367, 2017
Samaneh Aminikhanghahi and Diane J Cook. A survey of methods for time series change point detection.Knowledge and Information Systems, 51(2):339–367, 2017
2017
-
[2]
Improved inequalities for the Poisson and binomial distribution and upper tail quantile functions.International Scholarly Research Notices, 2013(1):412958, 2013
Michael Short. Improved inequalities for the Poisson and binomial distribution and upper tail quantile functions.International Scholarly Research Notices, 2013(1):412958, 2013
2013
-
[3]
Option pricing when underlying stock returns are discontinuous.Journal of Financial Economics, 3(1-2):125–144, 1976
Robert C Merton. Option pricing when underlying stock returns are discontinuous.Journal of Financial Economics, 3(1-2):125–144, 1976
1976
-
[4]
Global trends in wind speed and wave height.Science, 332(6028):451–455, 2011
IR Young, Stefan Zieger, and Alexander V Babanin. Global trends in wind speed and wave height.Science, 332(6028):451–455, 2011
2011
-
[5]
Parametric hurricane wave prediction model.Journal of Waterway, Port, Coastal, and Ocean Engineering, 114(5):637–652, 1988
Ian R Young. Parametric hurricane wave prediction model.Journal of Waterway, Port, Coastal, and Ocean Engineering, 114(5):637–652, 1988
1988
-
[6]
A closed-form solution for options with stochastic volatility with applications to bond and currency options.The Review of Financial Studies, 6(2):327–343, 1993
Steven L Heston. A closed-form solution for options with stochastic volatility with applications to bond and currency options.The Review of Financial Studies, 6(2):327–343, 1993
1993
-
[7]
Cambridge University Press, 1996
Jean Bertoin.Lévy processes, volume 199. Cambridge University Press, 1996
1996
-
[8]
A review of recurrent neural networks: LSTM cells and network architectures.Neural Computation, 31(7):1235–1270, 2019
Yong Yu, Xiaosheng Si, Changhua Hu, and Jianxun Zhang. A review of recurrent neural networks: LSTM cells and network architectures.Neural Computation, 31(7):1235–1270, 2019
2019
-
[9]
Deep learning for time series forecasting: Tutorial and literature survey.ACM Computing Surveys, 55(6):1–36, 2022
Konstantinos Benidis, Syama Sundar Rangapuram, Valentin Flunkert, Yuyang Wang, Danielle Maddix, Caner Turkmen, Jan Gasthaus, Michael Bohlke-Schneider, David Salinas, Lorenzo Stella, et al. Deep learning for time series forecasting: Tutorial and literature survey.ACM Computing Surveys, 55(6):1–36, 2022
2022
-
[10]
Time-series forecasting with deep learning: a survey.Philosoph- ical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 379(2194), 2021
Bryan Lim and Stefan Zohren. Time-series forecasting with deep learning: a survey.Philosoph- ical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 379(2194), 2021
2021
-
[11]
Latent ordinary differential equations for irregularly-sampled time series
Yulia Rubanova, Ricky TQ Chen, and David K Duvenaud. Latent ordinary differential equations for irregularly-sampled time series. InAdvances in Neural Information Processing Systems, volume 32, 2019
2019
-
[12]
Neural controlled differential equations for irregular time series
Patrick Kidger, James Morrill, James Foster, and Terry Lyons. Neural controlled differential equations for irregular time series. InAdvances in Neural Information Processing Systems, volume 33, pages 6696–6707, 2020
2020
-
[13]
Modeling irregular time series with continuous recurrent units
Mona Schirmer, Mazin Eltayeb, Stefan Lessmann, and Maja Rudolph. Modeling irregular time series with continuous recurrent units. InInternational Conference on Machine Learning, pages 19388–19405. PMLR, 2022
2022
-
[14]
Neural continuous-discrete state space models for irregularly-sampled time series
Abdul Fatir Ansari, Alvin Heng, Andre Lim, and Harold Soh. Neural continuous-discrete state space models for irregularly-sampled time series. InInternational Conference on Machine Learning, 2023
2023
-
[15]
Stochastic differential equations
Philip E Protter. Stochastic differential equations. InStochastic integration and differential equations, pages 249–361. Springer, 2012
2012
-
[16]
On filtration enlargements and purely discontinuous martingales.Stochastic Processes and their Applications, 118(9):1662–1678, 2008
Stefan Ankirchner. On filtration enlargements and purely discontinuous martingales.Stochastic Processes and their Applications, 118(9):1662–1678, 2008
2008
-
[17]
The use of ARIMA models for reliability forecasting and analysis
Siu Lau Ho and Min Xie. The use of ARIMA models for reliability forecasting and analysis. Computers & Industrial Engineering, 35(1-2):213–216, 1998. 10
1998
-
[18]
A time series is worth 64 words: Long-term forecasting with Transformers
Yuqi Nie, Nam H Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with Transformers. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum? id=Jbdc0vTOcol
2023
-
[19]
iTransformer: Inverted transformers are effective for time series forecasting
Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, and Mingsheng Long. iTransformer: Inverted transformers are effective for time series forecasting. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview. net/forum?id=JePfAI8fah
2024
-
[20]
DeepAR: Probabilistic forecasting with autoregressive recurrent networks.International Journal of Forecasting, 36(3): 1181–1191, 2020
David Salinas, Valentin Flunkert, Jan Gasthaus, and Tim Januschowski. DeepAR: Probabilistic forecasting with autoregressive recurrent networks.International Journal of Forecasting, 36(3): 1181–1191, 2020
2020
-
[21]
Maddix, Hao Wang, Michael W
Abdul Fatir Ansari, Lorenzo Stella, Ali Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebastian Pineda Arango, Shub- ham Kapoor, Jasper Zschiegner, Danielle C. Maddix, Hao Wang, Michael W. Mahoney, Kari Torkkola, Andrew Gordon Wilson, Michael Bohlke-Schneider, and Bernie Wang. Chronos: Learning the lan...
2024
-
[22]
A decoder-only foundation model for time-series forecasting
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. A decoder-only foundation model for time-series forecasting. InForty-first International Conference on Machine Learning, 2024. URLhttps://openreview.net/forum?id=jn2iTJas6h
2024
-
[23]
Moirai 2.0: When less is more for time series forecasting,
Chenghao Liu, Taha Aksu, Juncheng Liu, Xu Liu, Hanshu Yan, Quang Pham, Silvio Savarese, Doyen Sahoo, Caiming Xiong, and Junnan Li. Moirai 2.0: When less is more for time series forecasting.arXiv preprint arXiv:2511.11698, 2025
-
[24]
Lag-Llama: Towards foundation models for time series forecasting
Kashif Rasul, Arjun Ashok, Andrew Robert Williams, Arian Khorasani, George Adamopoulos, Rishika Bhagwatkar, Marin Biloš, Hena Ghonia, Nadhir Hassen, Anderson Schneider, Sahil Garg, Alexandre Drouin, Nicolas Chapados, Yuriy Nevmyvaka, and Irina Rish. Lag-Llama: Towards foundation models for time series forecasting. InR0-FoMo:Robustness of Few-shot and Zero...
2023
-
[25]
A recurrent latent variable model for sequential data
Junyoung Chung, Kyle Kastner, Laurent Dinh, Kratarth Goel, Aaron C Courville, and Yoshua Bengio. A recurrent latent variable model for sequential data. InAdvances in Neural Information Processing Systems, volume 28, 2015
2015
-
[26]
Rahul G Krishnan, Uri Shalit, and David Sontag. Deep Kalman filters. InarXiv preprint arXiv:1511.05121, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[27]
Deep variational Bayes filters: Unsupervised learning of state space models from raw data
Maximilian Karl, Maximilian Soelch, Justin Bayer, and Patrick van der Smagt. Deep variational Bayes filters: Unsupervised learning of state space models from raw data. InInternational Conference on Learning Representations, 2017. URL https://openreview.net/forum? id=HyTqHL5xg
2017
-
[28]
A disentangled recognition and nonlinear dynamics model for unsupervised learning
Marco Fraccaro, Simon Kamronn, Ulrich Paquet, and Ole Winther. A disentangled recognition and nonlinear dynamics model for unsupervised learning. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[29]
Sequential neural mod- els with stochastic layers
Marco Fraccaro, Søren Kaae Sønderby, Ulrich Paquet, and Ole Winther. Sequential neural mod- els with stochastic layers. InAdvances in Neural Information Processing Systems, volume 29, 2016
2016
-
[30]
Collapsed amortized variational inference for switching nonlinear dynamical systems
Zhe Dong, Bryan Seybold, Kevin Murphy, and Hung Bui. Collapsed amortized variational inference for switching nonlinear dynamical systems. InInternational Conference on Machine Learning, pages 2638–2647. PMLR, 2020
2020
-
[31]
Efficiently modeling long sequences with structured state spaces
Albert Gu, Karan Goel, and Christopher Ré. Efficiently modeling long sequences with structured state spaces. InThe International Conference on Learning Representations (ICLR), 2022. 11
2022
-
[32]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. InFirst Conference on Language Modeling, 2024. URL https://openreview.net/forum? id=tEYskw1VY2
2024
-
[33]
Scalable gradi- ents for stochastic differential equations
Xuechen Li, Ting-Kam Leonard Wong, Ricky TQ Chen, and David Duvenaud. Scalable gradi- ents for stochastic differential equations. InInternational Conference on Artificial Intelligence and Statistics, pages 3870–3882. PMLR, 2020
2020
-
[34]
GRU-ODE-Bayes: Con- tinuous modeling of sporadically-observed time series
Edward De Brouwer, Jaak Simm, Adam Arany, and Yves Moreau. GRU-ODE-Bayes: Con- tinuous modeling of sporadically-observed time series. InAdvances in Neural Information Processing Systems, volume 32, 2019
2019
-
[35]
Filtering variational objectives
Chris J Maddison, John Lawson, George Tucker, Nicolas Heess, Mohammad Norouzi, Andriy Mnih, Arnaud Doucet, and Yee Teh. Filtering variational objectives. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[36]
Variational sequential monte carlo
Christian Naesseth, Scott Linderman, Rajesh Ranganath, and David Blei. Variational sequential monte carlo. InInternational Conference on Artificial Intelligence and Statistics, pages 968–977. PMLR, 2018
2018
-
[37]
SIXO: Smooth- ing inference with twisted objectives
Dieterich Lawson, Allan Raventos, Andrew Warrington, and Scott Linderman. SIXO: Smooth- ing inference with twisted objectives. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=bDyLgfvZ0qJ
2022
-
[38]
Particle filter recurrent neural networks
Xiao Ma, Peter Karkus, David Hsu, and Wee Sun Lee. Particle filter recurrent neural networks. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 5101–5108, 2020
2020
-
[39]
Regime learning for differentiable particle filters
John-Joseph Brady, Yuhui Luo, Wenwu Wang, Víctor Elvira, and Yunpeng Li. Regime learning for differentiable particle filters. In2024 27th International Conference on Information Fusion (FUSION), pages 1–6. IEEE, 2024
2024
-
[40]
Junteng Jia and Austin R. Benson. Neural jump stochastic differential equations. InAdvances in Neural Information Processing Systems, pages 9843–9854, 2019. URL http://papers. nips.cc/paper/9177-neural-jump-stochastic-differential-equations
2019
-
[41]
Neural jump ordinary differential equa- tions: Consistent continuous-time prediction and filtering
Calypso Herrera, Florian Krach, and Josef Teichmann. Neural jump ordinary differential equa- tions: Consistent continuous-time prediction and filtering. InInternational Conference on Learn- ing Representations, 2021. URLhttps://openreview.net/forum?id=JFKR3WqwyXR
2021
-
[42]
Neural ordinary differential equations
Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations. InAdvances in Neural Information Processing Systems, volume 31, 2018
2018
-
[43]
Yuanpei Gao, Qi Yan, Yan Leng, and Renjie Liao. Neural MJD: Neural non-stationary Merton jump diffusion for time series prediction.arXiv preprint arXiv:2506.04542, 2025
-
[44]
Neural jump-diffusion temporal point processes
Shuai Zhang, Chuan Zhou, Yang Aron Liu, Peng Zhang, Xixun Lin, and Zhi-Ming Ma. Neural jump-diffusion temporal point processes. InForty-first International Conference on Machine Learning, 2024. URLhttps://openreview.net/forum?id=d1P6GtRzuV
2024
-
[45]
On the optimal filtering of diffusion processes.Zeitschrift für Wahrscheinlichkeit- stheorie und verwandte Gebiete, 11(3):230–243, 1969
Moshe Zakai. On the optimal filtering of diffusion processes.Zeitschrift für Wahrscheinlichkeit- stheorie und verwandte Gebiete, 11(3):230–243, 1969
1969
-
[46]
Approximation of the Zakai equation by the splitting up method.SIAM Journal on Control and Optimization, 28(6):1420–1431, 1990
Allan Bensoussan, Roland Glowinski, and Aurel Rascanu. Approximation of the Zakai equation by the splitting up method.SIAM Journal on Control and Optimization, 28(6):1420–1431, 1990
1990
-
[47]
Discretization and simulation of the Zakai equation.SIAM Journal on Numerical Analysis, 44(6):2505–2538, 2006
Emmanuel Gobet, Gilles Pages, Huyên Pham, and Jacques Printems. Discretization and simulation of the Zakai equation.SIAM Journal on Numerical Analysis, 44(6):2505–2538, 2006
2006
-
[48]
A Bayesian viewpoint on the price formation process.Market Microstructure and Liquidity, 6(01n04):2050010, 2020
Joffrey Derchu. A Bayesian viewpoint on the price formation process.Market Microstructure and Liquidity, 6(01n04):2050010, 2020. 12
2020
-
[49]
A splitting method for nonlinear filtering problems with diffusive and point process observations.Communications in Computational Physics, 36(4):996–1020, 2024
Fengshan Zhang, Yongkui Zou, Shimin Chai, and Yanzhao Cao. A splitting method for nonlinear filtering problems with diffusive and point process observations.Communications in Computational Physics, 36(4):996–1020, 2024
2024
-
[50]
An energy-based deep splitting method for the nonlinear filtering problem.Partial Differential Equations and Applications, 4(2):14, 2023
Kasper Bågmark, Adam Andersson, and Stig Larsson. An energy-based deep splitting method for the nonlinear filtering problem.Partial Differential Equations and Applications, 4(2):14, 2023
2023
-
[51]
The pricing of options and corporate liabilities.Journal of Political Economy, 81(3):637–654, 1973
Fischer Black and Myron Scholes. The pricing of options and corporate liabilities.Journal of Political Economy, 81(3):637–654, 1973
1973
-
[52]
A jump-diffusion model for option pricing.Management Science, 48(8): 1086–1101, 2002
Steven G Kou. A jump-diffusion model for option pricing.Management Science, 48(8): 1086–1101, 2002
2002
-
[53]
Kurtz and Daniel L
Thomas G. Kurtz and Daniel L. Ocone. Unique characterization of conditional distributions in nonlinear filtering (filtered martingale problem).Annals of Probability, 1988
1988
-
[54]
Backward SDE repre- sentation for partially observed control problems.Annals of Applied Probability, 2018
Elisabetta Bandini, Andrea Cosso, Marco Fuhrman, and Huyên Pham. Backward SDE repre- sentation for partially observed control problems.Annals of Applied Probability, 2018
2018
-
[55]
Nonlinear filtering for jump diffusion observations: Zakai equation, existence and uniqueness.Stochastic Processes and their Applications, 2014
Claudia Ceci and Katia Colaneri. Nonlinear filtering for jump diffusion observations: Zakai equation, existence and uniqueness.Stochastic Processes and their Applications, 2014
2014
-
[56]
Beyond Strang: A practical assessment of some second-order 3-splitting methods.Communications on Applied Mathematics and Computation, 7(1):95–114, 2025
Raymond J Spiteri, Arash Tavassoli, Siqi Wei, and Andrei Smolyakov. Beyond Strang: A practical assessment of some second-order 3-splitting methods.Communications on Applied Mathematics and Computation, 7(1):95–114, 2025
2025
-
[57]
Approximations of small jumps of Lévy processes with a view towards simulation.Journal of Applied Probability, 38(2):482–493, 2001
Søren Asmussen and Jan Rosi´nski. Approximations of small jumps of Lévy processes with a view towards simulation.Journal of Applied Probability, 38(2):482–493, 2001
2001
-
[58]
On the construction and comparison of difference schemes.SIAM Journal on Numerical Analysis, 5(3):506–517, 1968
Gilbert Strang. On the construction and comparison of difference schemes.SIAM Journal on Numerical Analysis, 5(3):506–517, 1968
1968
-
[59]
Are Transformers effective for time series forecasting? InProceedings of the AAAI Conference on Artificial Intelligence, 2023
Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu. Are Transformers effective for time series forecasting? InProceedings of the AAAI Conference on Artificial Intelligence, 2023
2023
-
[60]
Strictly proper scoring rules, prediction, and estimation
Tilmann Gneiting and Adrian E Raftery. Strictly proper scoring rules, prediction, and estimation. Journal of the American Statistical Association, 102(477):359–378, 2007
2007
-
[61]
Titan FX Research Hub: XAUUSD Historical Market Data
Titan FX. Titan FX Research Hub: XAUUSD Historical Market Data. https://research. titanfx.com/instruments/xauusd, 2025. One-minute OHLCV quote data for XAUUSD, Standard series
2025
-
[62]
Approximation Theory of Matrix Rank Minimization and Its Application to Quadratic Equations
NOAA National Data Buoy Center. Station 44027 Historical Standard Meteorological Data. https://www.ndbc.noaa.gov/station_history.php?station=44027, 2025. Signifi- cant wave height (WVHT, meters) from station 44027, Jonesport, ME - 20 NM SE of Jonesport, ME. 13 A Proofs and auxiliary results This appendix contains the proofs and derivations omitted from th...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.