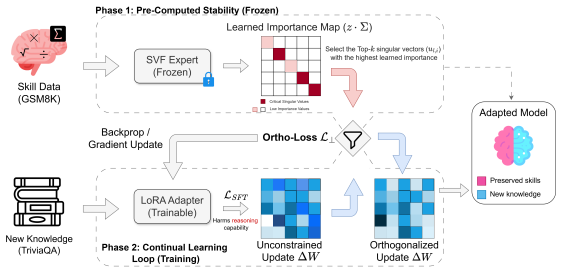
PALoRA: Projection-Adaptive LoRA for Preserving Reasoning in Large Language Models
Pith reviewed 2026-06-30 12:59 UTC · model grok-4.3
The pith
PALoRA shields reasoning subspaces in LLMs during factual updates by using an SVF probe to enforce orthogonal LoRA changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
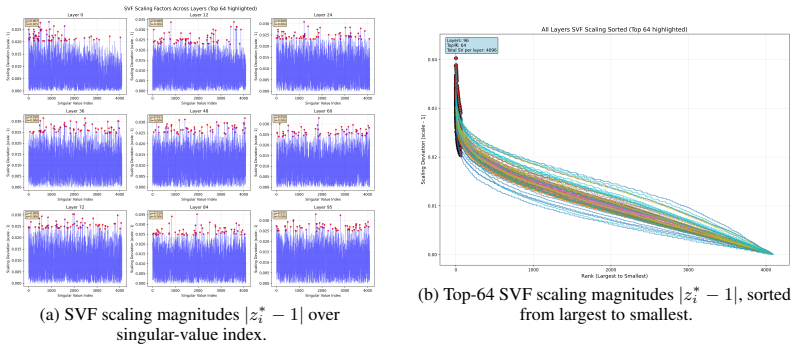
Reasoning-critical information is distributed across the singular spectrum of weight matrices; training an SVF expert on a reasoning set produces a singular scaling vector that serves as a reliable geometric probe; performing subsequent LoRA adaptation under an orthogonality constraint relative to this vector injects facts while preserving the target skill.
What carries the argument
The frozen singular scaling vector from the SVF expert, which identifies the skill-relevant subspace and supplies the structural orthogonality constraint for LoRA updates.
If this is right
- Knowledge injection can be performed with minimal interference to distributed reasoning representations.
- Spectral probes trained on one skill set can guide parameter updates for other capabilities.
- The added overhead remains below 0.006 percent while outperforming prior spectral PEFT baselines on retention.
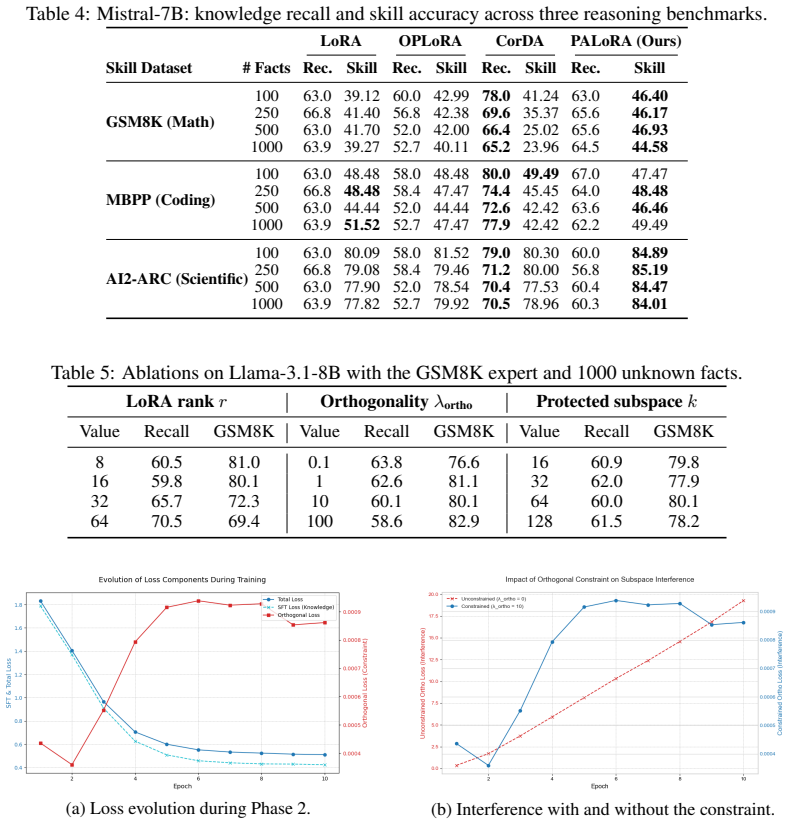
- The same two-stage pattern applies across 7B-8B models on mathematical, coding, and scientific tasks.
Where Pith is reading between the lines
- If the probe generalizes, similar subspace shielding could protect other skills such as safety alignment during capability updates.
- The distributed nature of reasoning suggests that full-rank updates may be needed only inside narrow subspaces rather than everywhere.
- Testing the method on continual learning streams would check whether repeated orthogonal injections accumulate without compounding skill loss.
Load-bearing premise
The singular scaling vector learned from reasoning data correctly marks the directions whose avoidance will protect reasoning performance.
What would settle it
A direct comparison showing that LoRA updates forced into the identified subspace produce substantially larger reasoning drops than the orthogonal updates on the same benchmarks.
Figures
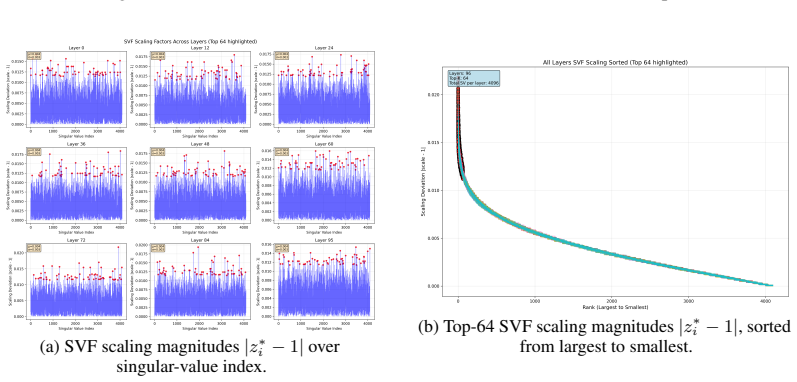
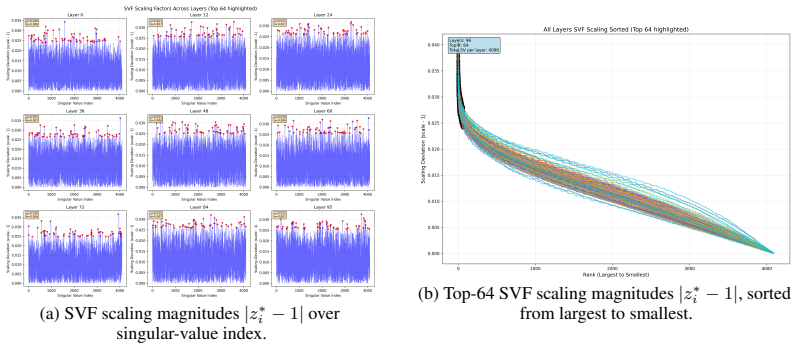
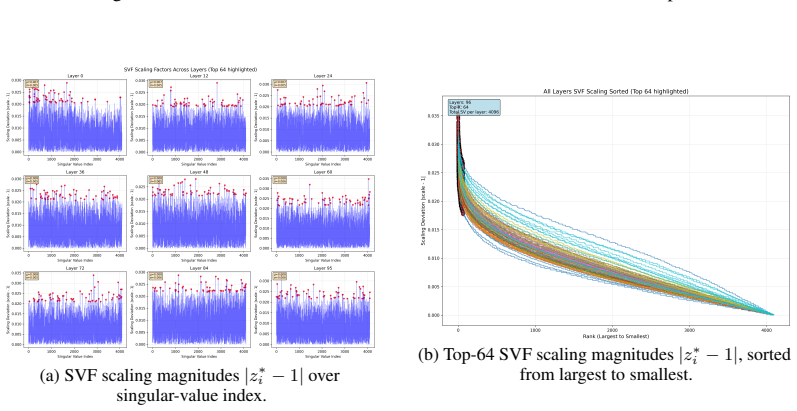
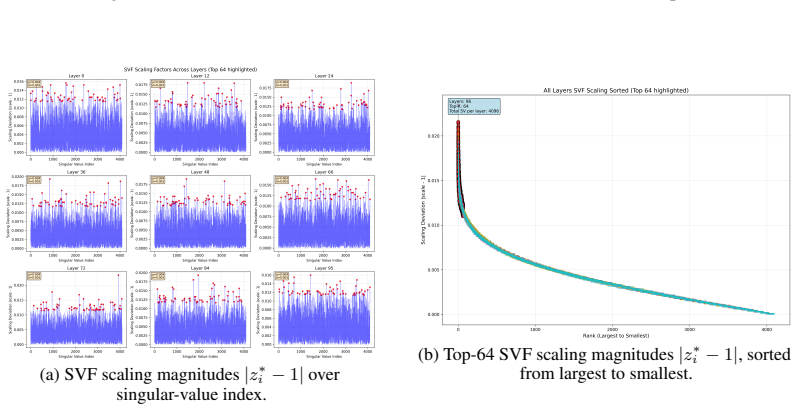
read the original abstract
Efficiently updating Large Language Models (LLMs) with new or evolving factual knowledge remains a central challenge, as even parameter-efficient adaptation can erode previously acquired reasoning abilities. This tension reflects a plasticity-stability dilemma: models must incorporate new knowledge while preserving skill-critical representations. In this work, we study this trade-off through the spectral structure of multilayer perceptron weight matrices. We show, both theoretically and empirically, that information essential for reasoning is not localized only in dominant singular directions, but is instead distributed across the singular spectrum. Motivated by this observation, we introduce PALoRA, a two-stage framework for knowledge injection with reduced interference. PALoRA first trains a Singular Value Fine-Tuning (SVF) expert on a reasoning dataset and uses its learned singular scaling vector as a frozen geometric probe to identify components that are critical for the target skill. It then performs factual knowledge injection with Low-Rank Adaptation (LoRA) under a structural orthogonality constraint, ensuring that updates avoid the identified skill-relevant subspace. Across Llama 3.1 8B and Mistral 7B, and across mathematical, coding, and scientific reasoning benchmarks, PALoRA preserves on average 95% of the SVF expert's reasoning performance while maintaining competitive factual recall. It consistently improves skill retention over prior spectral Parameter-Efficient Fine-Tuning (PEFT) methods while adding less than 0.006% parameter overhead.
Editorial analysis
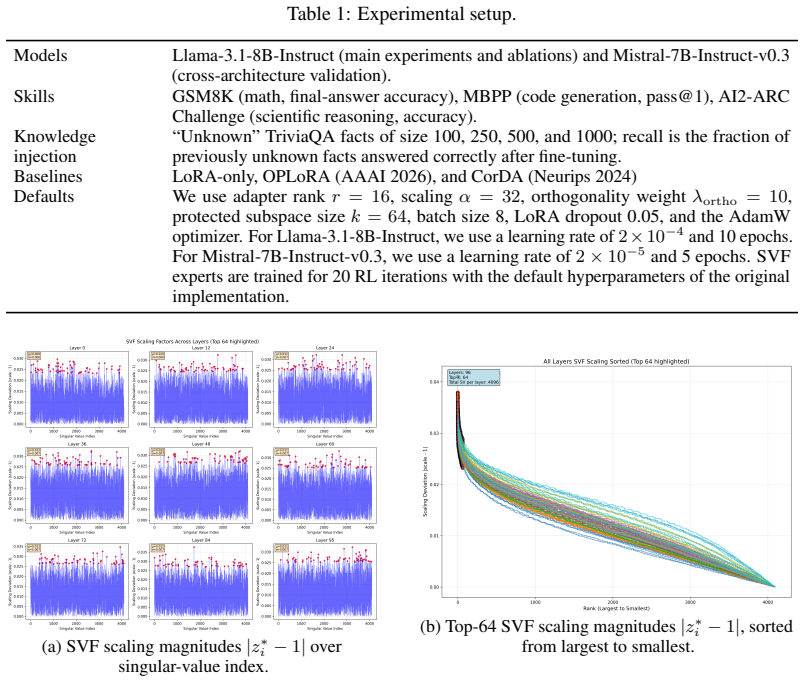
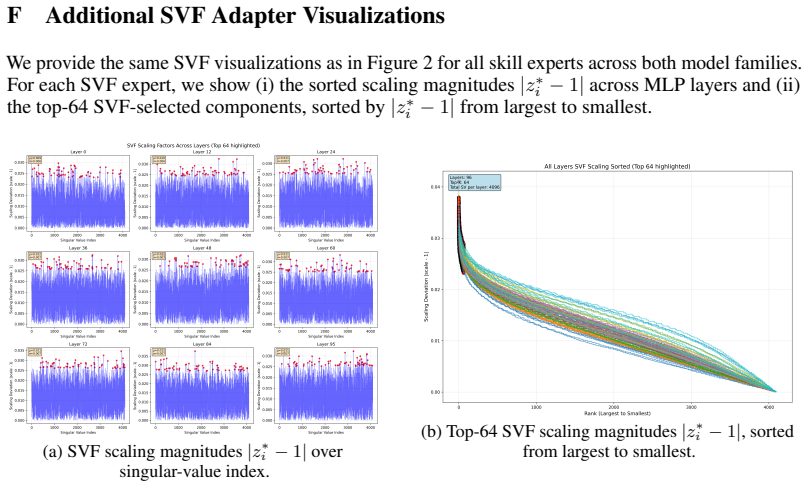
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PALoRA, a two-stage PEFT framework for injecting factual knowledge into LLMs without eroding reasoning skills. It first trains an SVF expert on a reasoning dataset to obtain a singular scaling vector that identifies skill-critical directions distributed across the singular spectrum of MLP weights (rather than only dominant ones). It then applies LoRA updates for factual adaptation subject to a structural orthogonality constraint that avoids the identified subspace. Experiments on Llama 3.1 8B and Mistral 7B across math, coding, and science benchmarks report that PALoRA retains on average 95% of the SVF expert's reasoning performance while achieving competitive factual recall and outperforming prior spectral PEFT baselines with <0.006% added parameters.
Significance. If the empirical results and the underlying subspace-identification claim hold under scrutiny, the work would offer a concrete, low-overhead approach to the plasticity-stability trade-off in LLM adaptation. The spectral-distribution observation and the use of a learned geometric probe to enforce orthogonality could inform future PEFT designs that aim to protect distributed capabilities rather than relying on magnitude-based or random projections.
major comments (2)
- [Abstract, §3] Abstract and §3 (Method): the central 95% preservation claim rests on the SVF-derived singular scaling vector accurately marking a stable reasoning subspace whose orthogonal complement can safely receive factual LoRA updates. No derivation or ablation is supplied showing why a single scaling vector (rather than the full support of non-zero scalings) suffices, nor how the orthogonality constraint remains valid after the base weights are subsequently modified; this directly affects whether the reported performance numbers can be attributed to the proposed mechanism rather than dataset-specific artifacts.
- [§4] §4 (Experiments): the abstract states both theoretical and empirical support for the distributed-spectrum claim and the 95% result, yet provides no dataset descriptions, control conditions (e.g., random vs. learned probe), or statistical tests. Without these, the cross-model, cross-benchmark superiority over prior spectral PEFT methods cannot be verified as load-bearing evidence.
minor comments (2)
- [Abstract] Notation for the singular scaling vector and the orthogonality projection operator should be introduced once with explicit definitions and reused consistently; current usage in the abstract is informal.
- [§4] The parameter-overhead figure (<0.006%) should be broken down by model size and compared directly to the baselines in a table.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to incorporate additional justification and experimental details.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Method): the central 95% preservation claim rests on the SVF-derived singular scaling vector accurately marking a stable reasoning subspace whose orthogonal complement can safely receive factual LoRA updates. No derivation or ablation is supplied showing why a single scaling vector (rather than the full support of non-zero scalings) suffices, nor how the orthogonality constraint remains valid after the base weights are subsequently modified; this directly affects whether the reported performance numbers can be attributed to the proposed mechanism rather than dataset-specific artifacts.
Authors: We agree that the manuscript would benefit from an explicit derivation and targeted ablations. While empirical results across models support the single-vector probe, we will add a derivation in §3 based on the SVD decomposition properties showing why the learned scaling vector captures the distributed subspace, plus ablations comparing it to the full non-zero support. We will also include analysis of the orthogonality constraint's invariance under subsequent base-weight updates. These additions will be made in the revised version. revision: yes
-
Referee: [§4] §4 (Experiments): the abstract states both theoretical and empirical support for the distributed-spectrum claim and the 95% result, yet provides no dataset descriptions, control conditions (e.g., random vs. learned probe), or statistical tests. Without these, the cross-model, cross-benchmark superiority over prior spectral PEFT methods cannot be verified as load-bearing evidence.
Authors: We acknowledge the need for expanded experimental reporting. The manuscript contains dataset descriptions in §4.1 and cross-model comparisons, but we will add explicit control experiments (random probes and full-spectrum baselines), statistical tests (e.g., significance testing on performance deltas), and fuller dataset details in the revised §4 to strengthen verifiability of the results. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's method trains an SVF expert on a separate reasoning dataset to obtain a singular scaling vector, then applies an orthogonality constraint during factual LoRA adaptation; the 95% preservation claim is an empirical measurement on held-out mathematical/coding/scientific benchmarks rather than a quantity that reduces by the paper's own equations to the fitted vector itself. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described framework. The theoretical claim that reasoning information is distributed across the singular spectrum is offered as motivation and is externally falsifiable via the reported benchmark comparisons, leaving the derivation self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- singular scaling vector
axioms (1)
- domain assumption Information essential for reasoning is not localized only in dominant singular directions but is distributed across the singular spectrum of multilayer perceptron weight matrices.
Reference graph
Works this paper leans on
-
[1]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[2]
How much knowledge can you pack into a lora adapter without harming llm? InFindings of the Association for Computational Linguistics: NAACL 2025, pages 4309–4322, 2025
Sergey Pletenev, Maria Marina, Daniil Moskovskiy, Vasily Konovalov, Pavel Braslavski, Alexan- der Panchenko, and Mikhail Salnikov. How much knowledge can you pack into a lora adapter without harming llm? InFindings of the Association for Computational Linguistics: NAACL 2025, pages 4309–4322, 2025
2025
-
[3]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495, 2021
2021
-
[4]
Knowledge neurons in pretrained transformers
Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. Knowledge neurons in pretrained transformers. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8493–8502, 2022
2022
-
[5]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems, 2021.URL https://arxiv. org/abs/2110.14168, 9, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
Pissa: Principal singular values and singular vectors adaptation of large language models.Advances in Neural Information Processing Systems, 37:121038–121072, 2024
Fanxu Meng, Zhaohui Wang, and Muhan Zhang. Pissa: Principal singular values and singular vectors adaptation of large language models.Advances in Neural Information Processing Systems, 37:121038–121072, 2024
2024
-
[9]
Milora: Harnessing minor singular components for parameter-efficient llm finetuning
Hanqing Wang, Yixia Li, Shuo Wang, Guanhua Chen, and Yun Chen. Milora: Harnessing minor singular components for parameter-efficient llm finetuning. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 4823–4836, 2025
2025
-
[10]
Svft: Parameter- efficient fine-tuning with singular vectors.Advances in Neural Information Processing Systems, 37:41425–41446, 2024
Vijay Lingam, Atula Tejaswi, Aditya Vavre, Aneesh Shetty, Gautham K Gudur, Joydeep Ghosh, Alex Dimakis, Eunsol Choi, Aleksandar Bojchevski, and Sujay Sanghavi. Svft: Parameter- efficient fine-tuning with singular vectors.Advances in Neural Information Processing Systems, 37:41425–41446, 2024
2024
-
[11]
Oplora: Orthogonal projection lora prevents catastrophic forgetting during parameter-efficient fine-tuning
Yifeng Xiong and Xiaohui Xie. Oplora: Orthogonal projection lora prevents catastrophic forgetting during parameter-efficient fine-tuning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 34088–34096, 2026
2026
-
[12]
Yibo Yang, Xiaojie Li, Zhongzhu Zhou, Shuaiwen L Song, Jianlong Wu, Liqiang Nie, and Bernard Ghanem. Corda: Context-oriented decomposition adaptation of large language models for task-aware parameter-efficient fine-tuning.Advances in Neural Information Processing Systems, 37:71768–71791, 2024. 10
2024
-
[13]
Transformer-squared: Self-adaptive llms
Qi Sun, Edoardo Cetin, and Yujin Tang. Transformer-squared: Self-adaptive llms. In Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors,International Conference on Learning Representa- tions, volume 2025, pages 13878–13895, 2025
2025
-
[14]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[15]
Catastrophic interference in connectionist networks: The sequential learning problem
Michael McCloskey and Neal J Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. InPsychology of learning and motivation, volume 24, pages 109–165. Elsevier, 1989
1989
-
[16]
The stability-plasticity dilemma: Investigating the continuum from catastrophic forgetting to age-limited learning effects, 2013
Martial Mermillod, Aurélia Bugaiska, and Patrick Bonin. The stability-plasticity dilemma: Investigating the continuum from catastrophic forgetting to age-limited learning effects, 2013
2013
-
[17]
Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
2017
-
[18]
Orthogonal gradient descent for continual learning
Mehrdad Farajtabar, Navid Azizan, Alex Mott, and Ang Li. Orthogonal gradient descent for continual learning. InInternational conference on artificial intelligence and statistics, pages 3762–3773. PMLR, 2020
2020
-
[19]
Gradient projection memory for continual learning
Gobinda Saha, Isha Garg, and Kaushik Roy. Gradient projection memory for continual learning. InInternational Conference on Learning Representations, 2021
2021
-
[20]
Orthogonal subspace learning for language model continual learning
Xiao Wang, Tianze Chen, Qiming Ge, Han Xia, Rong Bao, Rui Zheng, Qi Zhang, Tao Gui, and Xuan-Jing Huang. Orthogonal subspace learning for language model continual learning. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 10658–10671, 2023
2023
-
[21]
Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine learning, 8(3):229–256, 1992
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine learning, 8(3):229–256, 1992
1992
-
[22]
Cambridge university press, 2012
Roger A Horn and Charles R Johnson.Matrix analysis. Cambridge university press, 2012
2012
-
[23]
Matrix perturbation theory.(No Title), 1990
Gilbert W Stewart and Ji-guang Sun. Matrix perturbation theory.(No Title), 1990
1990
-
[24]
JHU press, 2013
Gene H Golub and Charles F Van Loan.Matrix computations. JHU press, 2013
2013
-
[25]
Hermann Weyl. Das asymptotische verteilungsgesetz der eigenwerte linearer partieller differen- tialgleichungen (mit einer anwendung auf die theorie der hohlraumstrahlung).Mathematische Annalen, 71(4):441–479, 1912. 11 Appendix This appendix provides supplementary material supporting the theoretical, methodological, and empirical results of the paper. We f...
1912
-
[26]
The optimization schedule is model-specific: for Llama-3.1-8B-Instruct, we use a learning rate of 2×10 −4 and train for 10 epochs, whereas for Mistral-7B-Instruct-v0.3, we use a learning rate of 2×10 −5 and train for 5 epochs. Evaluation is likewise standardized: knowledge performance is measured with the same Unknown and HighlyKnown splits, and skill pre...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.