IQA-Spider: Unifying Multi-Granularity Image Quality Assessment with Reasoning, Grounding and Referring
Pith reviewed 2026-06-30 13:25 UTC · model grok-4.3
The pith
IQA-Spider is the first LMM framework to unify reasoning, grounding and referring for multi-granularity image quality assessment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
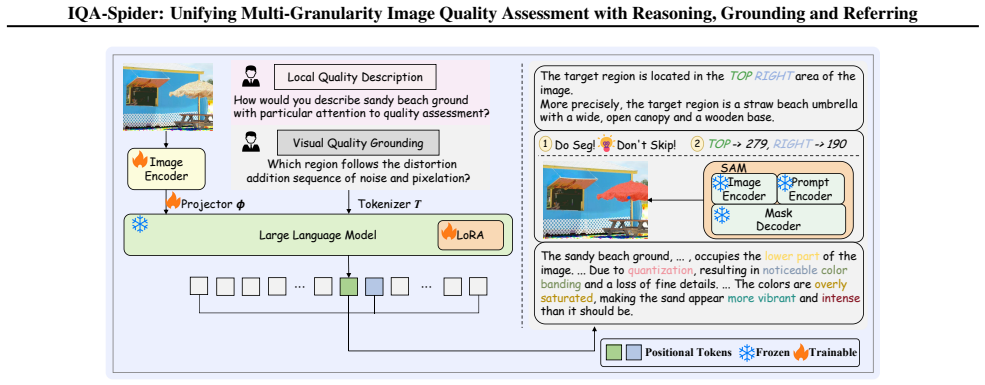
By formulating a rigorous four-task paradigm covering global and local quality description, pixel-level grounding, and region-level referring, and constructing a corresponding IQA dataset, the authors enable a conflict-free two-stage design that progressively extends text-level multi-granularity understanding to pixel-level grounding via a training-free text-to-point grounding paradigm mapping token logits to spatial coordinates, achieving unified multi-granularity explainable image quality assessment.
What carries the argument
The training-free text-to-point grounding paradigm that bridges textual semantics and pixel-level perception by mapping token logits to spatial coordinates.
If this is right
- Supports both global and local quality description alongside pixel-level grounding in a single model.
- Provides a scalable automatic annotation pipeline for building multi-granularity IQA datasets.
- Achieves strong performance across multiple IQA benchmarks through the unified approach.
- Enables explainable quality assessment at multiple granularities without task-specific fine-tuning in the grounding stage.
Where Pith is reading between the lines
- This approach could potentially be applied to other vision-language tasks requiring multi-level perception.
- If the grounding works reliably, it reduces the need for extensive labeled data for pixel-level tasks in IQA.
- Future work might test whether this unification improves downstream applications like image enhancement guided by quality feedback.
Load-bearing premise
The assumption that the training-free text-to-point grounding paradigm can reliably bridge textual semantics to pixel-level perception without introducing conflicts or requiring task-specific fine-tuning.
What would settle it
A test where the second stage is applied and the resulting model shows decreased accuracy on quality description tasks or fails to correctly ground quality-related regions compared to a fine-tuned alternative.
Figures





read the original abstract
We present IQA-Spider, the first image quality assessment (IQA) framework that unifies reasoning, grounding, and referring into a single LMM-based framework for multi-granularity quality understanding. Existing LMM-based IQA methods typically support only partial perception dimensions, such as quality description and question answering~(\textit{i.e.}, reasoning) or pixel-level grounding. This limitation largely stems from the absence of (i) a unified task and data formulation and (ii) effective optimization paradigms for multi-granularity learning. To address these limitations, we formulate a rigorous four-task paradigm covering global and local quality description, pixel-level grounding, and region-level referring. Based on this formulation, we construct a corresponding IQA dataset with a scalable and automatic annotation pipeline, thereby providing a solid foundation for unified multi-granularity learning. To further enable unified perception, we adopt a conflict-free two-stage design that progressively extends text-level multi-granularity understanding to pixel-level grounding: (i) the first stage equips the model with fine-grained text-level reasoning across multiple IQA tasks, and (ii) the second stage introduces a training-free text-to-point grounding paradigm, which bridges textual semantics and pixel-level perception by mapping token logits to spatial coordinates. Based on these efforts, we achieve IQA-Spider with unified multi-granularity explainable image quality assessment. Extensive experiments across multiple benchmarks demonstrate strong performance, validating the effectiveness and versatility of the proposed formulation and framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce IQA-Spider, the first LMM-based IQA framework unifying reasoning, grounding, and referring for multi-granularity quality understanding. It formulates a four-task paradigm (global/local quality description, pixel-level grounding, region-level referring), builds a corresponding dataset via automatic annotation, and uses a conflict-free two-stage design: stage 1 for text-level multi-task reasoning and stage 2 for a training-free text-to-point grounding method that maps token logits directly to spatial coordinates.
Significance. If the two-stage unification holds without conflicts or accuracy loss on subtle IQA degradations, the work would meaningfully extend LMM-based IQA beyond partial-perception methods by enabling joint text-level and pixel-level explainability in a single model, supported by the new multi-task formulation and dataset.
major comments (1)
- [abstract (second training stage description)] The central unification claim rests on the training-free text-to-point grounding paradigm in stage 2 (described in the abstract), which assumes pre-trained token representations already encode precise pixel-level spatial information for quality-relevant regions in a conflict-free manner. For IQA tasks where degradations are often subtle, distributed, or semantically abstract rather than object-centric, this assumption risks inaccurate grounding/referring outputs; the manuscript provides no ablations, error analysis, or quantitative validation of the logit-to-coordinate mapping on IQA-specific cases to confirm reliability without fine-tuning.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the validation of our training-free text-to-point grounding stage. We address this point directly below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [abstract (second training stage description)] The central unification claim rests on the training-free text-to-point grounding paradigm in stage 2 (described in the abstract), which assumes pre-trained token representations already encode precise pixel-level spatial information for quality-relevant regions in a conflict-free manner. For IQA tasks where degradations are often subtle, distributed, or semantically abstract rather than object-centric, this assumption risks inaccurate grounding/referring outputs; the manuscript provides no ablations, error analysis, or quantitative validation of the logit-to-coordinate mapping on IQA-specific cases to confirm reliability without fine-tuning.
Authors: We acknowledge the validity of this concern. The training-free mapping relies on the spatial priors already present in the LMM's token representations after stage-1 multi-task text training, which our design intentionally keeps conflict-free by avoiding any gradient updates in stage 2. While the manuscript reports overall benchmark gains for grounding and referring, we agree that dedicated ablations, error analysis, and quantitative metrics focused on subtle/distributed IQA degradations (rather than object-centric cases) are currently insufficient. In the revision we will add: (i) a new ablation table measuring grounding accuracy versus degradation subtlety, (ii) qualitative failure-case analysis on abstract quality attributes, and (iii) direct comparison of the logit-to-coordinate mapping against a fine-tuned baseline on the same IQA test splits. These additions will be placed in Section 4.3 and the supplementary material. revision: yes
Circularity Check
No significant circularity; derivation is a new construction
full rationale
The paper presents a new four-task formulation, an automatically annotated dataset, and a two-stage training procedure (text-level reasoning followed by a training-free logit-to-coordinate mapping) as original contributions. No equations, fitted parameters, or predictions are described that reduce by construction to prior inputs. No self-citations are invoked as load-bearing uniqueness theorems, and the central unification claim rests on the explicit construction of tasks, data, and the two-stage pipeline rather than on renaming or re-expressing existing results. The framework is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Abdin, M., Aneja, J., Awadalla, H., Awadallah, A., Awan, A. A., Bach, N., Bahree, A., Bakhtiari, A., Bao, J., Behl, H., et al. Phi-3 technical report: A highly capable lan- guage model locally on your phone.arXiv preprint arXiv:2404.14219,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Bai, S., Cai, Y ., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al. Qwen3- vl technical report.arXiv preprint arXiv:2511.21631, 2025a. Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025b. Cao, S., Gui, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Chen, C., Yang, S., Wu, H., Liao, L., Zhang, Z., Wang, A., Sun, W., Yan, Q., and Lin, W. Q-ground: Image quality grounding with large multi-modality models. In Proceedings of the 32nd ACM International Conference on Multimedia, pp. 486–495, 2024a. Chen, J., Yang, Z., and Zhang, L. Semantic segment anything. https://github.com/fudan-zvg/ Semantic-Segment-A...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Text4seg: Reimagining im- age segmentation as text generation.arXiv preprint arXiv:2410.09855,
Lan, M., Chen, C., Zhou, Y ., Xu, J., Ke, Y ., Wang, X., Feng, L., and Zhang, W. Text4seg: Reimagining im- age segmentation as text generation.arXiv preprint arXiv:2410.09855,
-
[5]
Liu, H., Li, C., Li, Y ., and Lee, Y . J. Improved baselines with visual instruction tuning, 2023a. Liu, H., Li, C., Wu, Q., and Lee, Y . J. Visual instruction tun- ing.Advances in neural information processing systems, 36:34892–34916, 2023b. Lu, Y ., Li, X., Wu, H., Li, B., Lin, W., and Chen, Z. Q-adapt: Adapting lmm for visual quality assessment with pr...
-
[6]
Kosmos-2: Grounding Multimodal Large Language Models to the World
URL https: //api.semanticscholar.org/CorpusID: 263218031. Peng, Z., Wang, W., Dong, L., Hao, Y ., Huang, S., Ma, S., and Wei, F. Kosmos-2: Grounding multimodal large language models to the world.arXiv preprint arXiv:2306.14824,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
arXiv preprint arXiv:2404.08506 (2024)
Wei, C., Tan, H., Zhong, Y ., Yang, Y ., and Ma, L. Lasagna: Language-based segmentation assistant for complex queries.arXiv preprint arXiv:2404.08506,
-
[8]
Wu, H., Zhang, Z., Zhang, E., Chen, C., Liao, L., Wang, A., Li, C., Sun, W., Yan, Q., Zhai, G., et al. Q-bench: A benchmark for general-purpose foundation models on low-level vision.arXiv preprint arXiv:2309.14181, 2023a. Wu, H., Zhang, Z., Zhang, W., Chen, C., Liao, L., Li, C., Gao, Y ., Wang, A., Zhang, E., Sun, W., et al. Q-align: Teaching lmms for vis...
-
[9]
Ferret: Refer and Ground Anything Anywhere at Any Granularity
You, H., Zhang, H., Gan, Z., Du, X., Zhang, B., Wang, Z., Cao, L., Chang, S.-F., and Yang, Y . Ferret: Refer and ground anything anywhere at any granularity.arXiv preprint arXiv:2310.07704,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Descriptive image quality assessment in the wild
You, Z., Gu, J., Li, Z., Cai, X., Zhu, K., Dong, C., and Xue, T. Descriptive image quality assessment in the wild. arXiv preprint arXiv:2405.18842,
-
[11]
You, Z., Cai, X., Gu, J., Xue, T., and Dong, C. Teach- ing large language models to regress accurate image quality scores using score distribution.arXiv preprint arXiv:2501.11561, 2025a. You, Z., Gu, J., Cai, X., Li, Z., Zhu, K., Dong, C., and Xue, T. Enhancing descriptive image quality assessment with a large-scale multi-modal dataset.IEEE Transactions o...
-
[12]
Zhang, P., Dong, X., Wang, B., Cao, Y ., Xu, C., Ouyang, L., Zhao, Z., Duan, H., Zhang, S., Ding, S., et al. Internlm-xcomposer: A vision-language large model for advanced text-image comprehension and composition. arXiv preprint arXiv:2309.15112, 2023a. 10 IQA-Spider: Unifying Multi-Granularity Image Quality Assessment with Reasoning, Grounding and Referr...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Zhu, D., Chen, J., Shen, X., Li, X., and Elhoseiny, M
URL https://arxiv.org/ abs/2406.20076. Zhu, D., Chen, J., Shen, X., Li, X., and Elhoseiny, M. Minigpt-4: Enhancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592,
-
[14]
Tasks Global Des
Table 7.Statistics of four tasks in our dataset. Tasks Global Des. Local Des. Grounding Ref short Reflong Train 3251 9742 11669 4506 4222 Test 629 460 586 780 786 Details of Dataset Construction.We construct synthetically distorted images by using the pristine images from Kadis- 700K (Lin et al., 2019), and we leverage human to annotate the authentically ...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.