Know You Before You Speak: User-State Modeling for LLM Personalization in Multi-Turn Conversation
Pith reviewed 2026-06-30 13:23 UTC · model grok-4.3
The pith
Explicit modeling of latent user states and their action-conditioned dynamics enables better long-term action selection in personalized dialogue.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
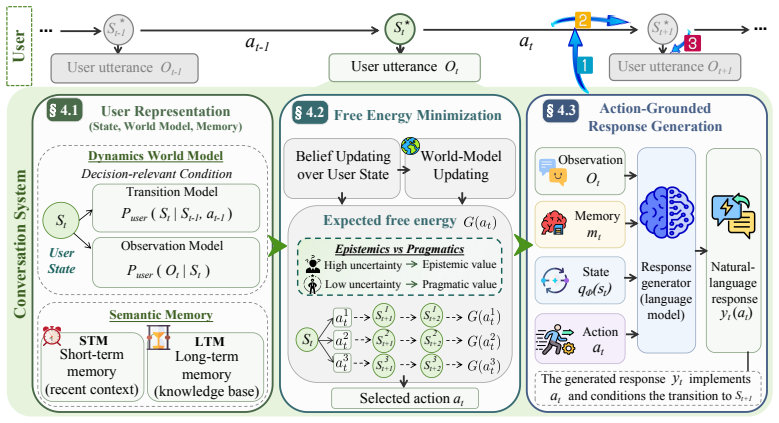
PUMA formulates personalization as decision-making under partial observability centered on an explicit user state model that captures latent user states and their action-conditioned dynamics. At each turn PUMA maintains a belief over the hidden state, refines the model for observation generation and action-conditioned state transition, and selects dialogue actions by minimizing expected free energy, balancing epistemic and pragmatic objectives under a unified criterion. This shifts personalization from passive memory retrieval to model-based decision-making over user evolution, with experiments showing improved long-horizon outcomes on healthcare-oriented counseling benchmarks and more relia
What carries the argument
PUMA, the prospective user-state modeling framework that maintains a belief over hidden states and chooses actions by minimizing expected free energy under the Free Energy Principle.
If this is right
- Long-horizon dialogue outcomes improve on healthcare counseling and motivational interviewing benchmarks while response quality stays high.
- User-state estimation and next-state prediction become more reliable when evaluated across multiple datasets.
- Action selection can be driven by predicted effects on future user states rather than by retrieval of past observations alone.
Where Pith is reading between the lines
- The same belief-update and free-energy minimization loop could be applied to tutoring or customer-service dialogues where user knowledge or intent also evolves.
- If the learned transition model proves stable, it could be reused across sessions to initialize beliefs without starting from scratch each time.
- Combining the explicit state model with larger language models might allow the system to generate both the belief update and the chosen response in a single forward pass.
Load-bearing premise
An explicit latent user-state model with action-conditioned transition dynamics can be learned from data and used to minimize expected free energy in a way that produces measurably better long-horizon outcomes than memory- or profile-based baselines.
What would settle it
A controlled replication on the same counseling benchmarks in which PUMA shows no statistically significant gain on long-horizon outcome metrics or in which its state-estimation accuracy falls to the level of the memory-based baselines.
Figures
read the original abstract
Personalized dialogue requires more than recalling explicit user histories: systems also need to infer hidden user states that evolve through interaction and shape appropriate response strategies. Existing memory- and profile-based methods primarily reuse observable user information, offering limited support for modeling user-state dynamics or selecting actions based on how they shape future user states. We propose PUMA (Prospective User-state Modeling for Action selection), a framework grounded in the Free Energy Principle (FEP) that formulates personalization as decision-making under partial observability, centered on an explicit user state model that captures latent user states and their action-conditioned dynamics. At each turn, PUMA maintains a belief over the user's hidden state, refines the user state model for observation generation and action-conditioned state transition, and selects dialogue actions by minimizing expected free energy, balancing epistemic and pragmatic objectives under a unified criterion. This formulation shifts personalization from passive memory retrieval to model-based decision-making over user evolution. We instantiate PUMA on healthcare-oriented counseling and motivational interviewing benchmarks with latent state annotations for rigorous evaluation. Experiments show that PUMA improves long-horizon dialogue outcomes while maintaining strong response quality, and a cross-dataset study demonstrates more reliable user-state estimation and next-state prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PUMA (Prospective User-state Modeling for Action selection), a framework grounded in the Free Energy Principle that formulates LLM personalization in multi-turn dialogue as decision-making under partial observability. It maintains a belief over latent user states, refines an explicit user-state model with action-conditioned transitions, and selects actions by minimizing expected free energy to balance epistemic and pragmatic objectives. The approach is evaluated on healthcare-oriented counseling and motivational interviewing benchmarks that include latent state annotations; the central claims are improved long-horizon dialogue outcomes relative to memory- and profile-based baselines together with more reliable user-state estimation and next-state prediction in a cross-dataset study.
Significance. If the empirical results hold with appropriate controls, the work would provide a principled, model-based alternative to passive memory retrieval for personalization, potentially improving coherence over extended interactions. The explicit use of expected free energy offers a unified criterion that could be adopted in other interactive settings; the provision of latent-state annotations on the benchmarks is a positive contribution for reproducible evaluation of state-tracking methods.
major comments (2)
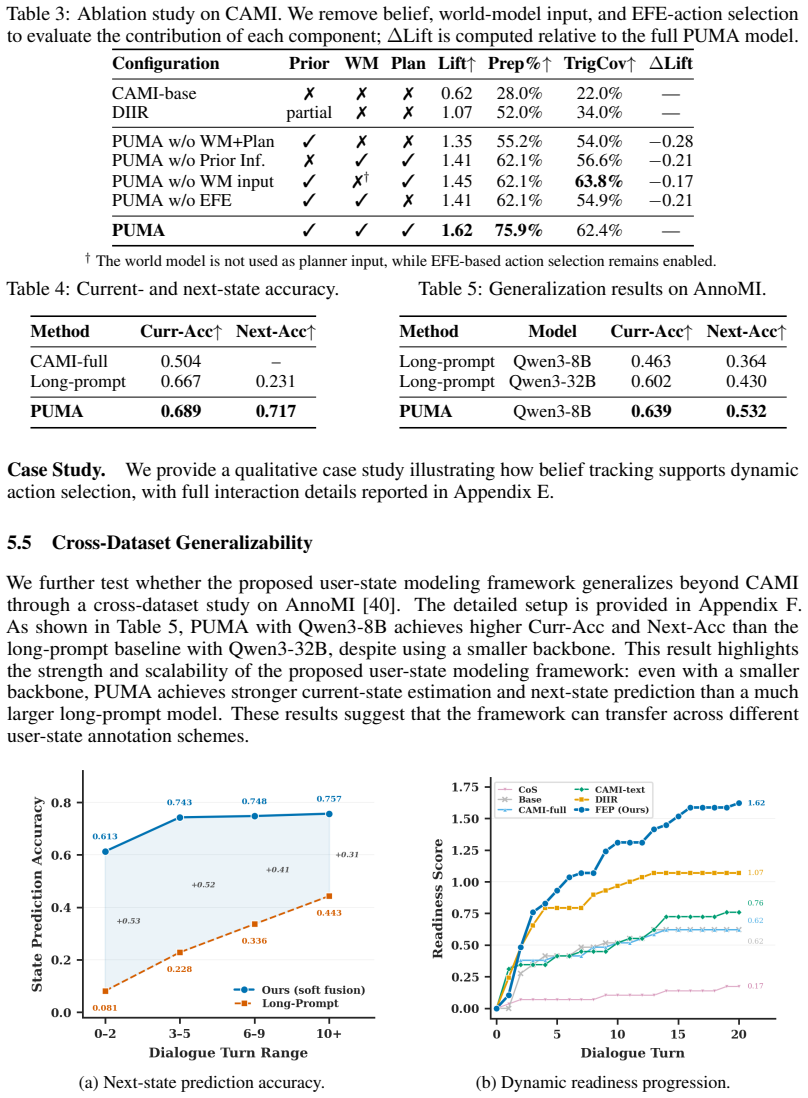
- [Abstract / Experiments] Abstract and Experiments section: the claims of improved long-horizon outcomes and more reliable state estimation are stated without any reported metrics, baselines, effect sizes, or statistical tests, so the central empirical assertion cannot be assessed from the supplied evidence.
- [§3] §3 (PUMA formulation): the action-selection step minimizes expected free energy with respect to the learned user-state model; it is unclear whether the reported gains remain after controlling for the quality of the fitted transition dynamics or whether they are partly circular with the model itself.
minor comments (2)
- Define all acronyms at first use (FEP, PUMA, etc.) and ensure consistent notation for belief states and expected free energy across sections.
- The cross-dataset study would benefit from an explicit description of how the latent-state annotations were obtained and how inter-annotator agreement was measured.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and outline the revisions we will make to improve the clarity and rigor of the empirical claims and formulation.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the claims of improved long-horizon outcomes and more reliable state estimation are stated without any reported metrics, baselines, effect sizes, or statistical tests, so the central empirical assertion cannot be assessed from the supplied evidence.
Authors: We agree that the abstract and Experiments section would benefit from explicit quantitative reporting. The current manuscript summarizes outcomes at a high level. We will revise the abstract to include key metrics (e.g., dialogue success rates, state estimation accuracy) with comparisons to baselines, and expand the Experiments section to report effect sizes and results of statistical tests (paired t-tests or appropriate non-parametric equivalents with p-values) for all central claims. revision: yes
-
Referee: [§3] §3 (PUMA formulation): the action-selection step minimizes expected free energy with respect to the learned user-state model; it is unclear whether the reported gains remain after controlling for the quality of the fitted transition dynamics or whether they are partly circular with the model itself.
Authors: We appreciate this clarification request. The user-state model is fit from data, and action selection proceeds by minimizing expected free energy under that model; the reported improvements are shown relative to memory- and profile-based baselines that lack this prospective modeling. To address potential circularity, we will add an ablation that holds the learned transition dynamics fixed and varies only the action-selection criterion (comparing expected free energy minimization against simpler selection strategies). This will isolate the contribution of the decision-making step. revision: partial
Circularity Check
No significant circularity identified
full rationale
The provided abstract and description present PUMA as an application of the externally established Free Energy Principle to dialogue personalization via standard POMDP-style belief maintenance, action-conditioned transitions, and expected free energy minimization. No equations, fitted parameters renamed as predictions, self-citations, or ansatzes are shown that reduce the central formulation to its own inputs by construction. The empirical claims (long-horizon gains over baselines, reliable state estimation) are framed as testable outcomes rather than definitional or self-referential. This is a normal non-circular case of importing an established framework and evaluating it empirically.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Free Energy Principle provides a suitable normative criterion for action selection under partial observability in dialogue
invented entities (1)
-
PUMA user-state model
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Large language models empowered personalized web agents
Hongru Cai, Yongqi Li, Wenjie Wang, Fengbin Zhu, Xiaoyu Shen, Wenjie Li, and Tat-Seng Chua. Large language models empowered personalized web agents. InProceedings of the ACM on Web Conference 2025, pages 198–215, 2025
2025
-
[2]
A survey on dialogue systems: Recent advances and new frontiers.Acm Sigkdd Explorations Newsletter, 19(2):25–35, 2017
Hongshen Chen, Xiaorui Liu, Dawei Yin, and Jiliang Tang. A survey on dialogue systems: Recent advances and new frontiers.Acm Sigkdd Explorations Newsletter, 19(2):25–35, 2017
2017
-
[3]
Itsugun Cho, Dongyang Wang, Ryota Takahashi, and Hiroaki Saito. A personalized dialogue generator with implicit user persona detection.arXiv preprint arXiv:2204.07372, 2022
-
[4]
Large language models (llms) inference offloading and resource allocation in cloud-edge networks: An active inference approach
Jingcheng Fang, Ying He, F Richard Yu, Jianqiang Li, and Victor C Leung. Large language models (llms) inference offloading and resource allocation in cloud-edge networks: An active inference approach. In2023 IEEE 98th Vehicular Technology Conference (VTC2023-Fall), pages 1–5. IEEE, 2023
2023
-
[5]
The free-energy principle: a unified brain theory?Nature reviews neuroscience, 11(2):127–138, 2010
Karl Friston. The free-energy principle: a unified brain theory?Nature reviews neuroscience, 11(2):127–138, 2010
2010
-
[6]
A free energy principle for the brain.Journal of Physiology-Paris, 100(1–3):70–87, 2006
Karl Friston, James Kilner, and Lee Harrison. A free energy principle for the brain.Journal of Physiology-Paris, 100(1–3):70–87, 2006. doi: 10.1016/j.jphysparis.2006.10.001
-
[7]
Active inference and epistemic value.Cognitive neuroscience, 6(4):187–214, 2015
Karl Friston, Francesco Rigoli, Dimitri Ognibene, Christoph Mathys, Thomas Fitzgerald, and Giovanni Pezzulo. Active inference and epistemic value.Cognitive neuroscience, 6(4):187–214, 2015
2015
-
[8]
Active inference and learning.Neuroscience & Biobehavioral Reviews, 68:862–879, 2016
Karl Friston, Thomas FitzGerald, Francesco Rigoli, Philipp Schwartenbeck, Giovanni Pezzulo, et al. Active inference and learning.Neuroscience & Biobehavioral Reviews, 68:862–879, 2016
2016
-
[9]
Active inference: A process theory.Neural Computation, 29(1):1–49, 2017
Karl Friston, Thomas FitzGerald, Francesco Rigoli, Philipp Schwartenbeck, and Giovanni Pezzulo. Active inference: A process theory.Neural Computation, 29(1):1–49, 2017. doi: 10.1162/NECO_a_00912
-
[10]
Action and behavior: a free-energy formulation.Biological cybernetics, 102(3):227–260, 2010
Karl J Friston, Jean Daunizeau, James Kilner, and Stefan J Kiebel. Action and behavior: a free-energy formulation.Biological cybernetics, 102(3):227–260, 2010
2010
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Ying He, Jingcheng Fang, F Richard Yu, and Victor C Leung. Large language models (llms) inference offloading and resource allocation in cloud-edge computing: An active inference approach.IEEE Transactions on Mobile Computing, 23(12):11253–11264, 2024
2024
-
[13]
Mem-pal: Towards memory-based personalized dialogue assistants for long- term user-agent interaction
Zhaopei Huang, Qifeng Dai, Guozheng Wu, Xiaopeng Wu, Xubin Li, Tiezheng Ge, Wenxuan Wang, and Qin Jin. Mem-pal: Towards memory-based personalized dialogue assistants for long- term user-agent interaction. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 31229–31237, 2026
2026
-
[14]
Dialogue management by estimating user’s internal state using movie recommendation dialogue.Journal of Natural Language Processing, 28(1):104–135, 2021
Takashi Kodama, Ribeka Tanaka, and Sadao Kurohashi. Dialogue management by estimating user’s internal state using movie recommendation dialogue.Journal of Natural Language Processing, 28(1):104–135, 2021. 10
2021
-
[15]
Aligning to thousands of preferences via system message generalization.Advances in Neural Information Processing Systems, 37:73783–73829, 2024
Seongyun Lee, Sue Hyun Park, Seungone Kim, and Minjoon Seo. Aligning to thousands of preferences via system message generalization.Advances in Neural Information Processing Systems, 37:73783–73829, 2024
2024
-
[16]
Hello again! llm-powered personalized agent for long-term dialogue
Hao Li, Chenghao Yang, An Zhang, Yang Deng, Xiang Wang, and Tat-Seng Chua. Hello again! llm-powered personalized agent for long-term dialogue. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 5259–5276, 2025
2025
-
[17]
A persona-aware llm-enhanced framework for multi-session personalized dialogue generation
Dongshuo Liu, Zhijing Wu, Dandan Song, and He-Yan Huang. A persona-aware llm-enhanced framework for multi-session personalized dialogue generation. InFindings of the Association for Computational Linguistics: ACL 2025, pages 103–123, 2025
2025
-
[18]
L-mtp: Leap multi-token prediction beyond adjacent context for large language models.Advances in Neural Information Processing Systems, 38: 102569–102600, 2026
Xiaohao Liu, Xiaobo Xia, Weixiang Zhao, Manyi Zhang, Xianzhi Yu, Xiu Su, Shuo Yang, See-Kiong Ng, and Tat-Seng Chua. L-mtp: Leap multi-token prediction beyond adjacent context for large language models.Advances in Neural Information Processing Systems, 38: 102569–102600, 2026
2026
-
[19]
Zhenyi Lu, Wei Wei, Xiaoye Qu, XianLing Mao, Dangyang Chen, and Jixiong Chen. Miracle: Towards personalized dialogue generation with latent-space multiple personal attribute control. arXiv preprint arXiv:2310.18342, 2023
-
[20]
Siyuan Ma, Bo Gao, Xiaojun Jia, Simeng Qin, Tianlin Li, Ke Ma, Xiaoshuang Jia, Wenqi Ren, and Yang Liu. Odar: Principled adaptive routing for llm reasoning via active inference.arXiv preprint arXiv:2602.23681, 2026
-
[21]
Maple: A framework for active preference learning guided by large language models
Saaduddin Mahmud, Mason Nakamura, and Shlomo Zilberstein. Maple: A framework for active preference learning guided by large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 27518–27528, 2025
2025
-
[22]
UniDetect: LLM-Driven Universal Fraud Detection across Heterogeneous Blockchains
Shuyi Miao, Wangjie Qiu, Shengda Zhuo, Fei Shen, Dan Lin, Xingtong Yu, Chua Tat-Seng, and Zhiming Zheng. Unidetect: Llm-driven universal fraud detection across heterogeneous blockchains.arXiv preprint arXiv:2604.12329, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Active inference and human– computer interaction.ACM Transactions on Computer-Human Interaction, 32(6):1–45, 2025
Roderick Murray-Smith, John H Williamson, and Sebastian Stein. Active inference and human– computer interaction.ACM Transactions on Computer-Human Interaction, 32(6):1–45, 2025
2025
-
[24]
Generating meaning: active inference and the scope and limits of passive ai.Trends in Cognitive Sciences, 28(2): 97–112, 2024
Giovanni Pezzulo, Thomas Parr, Paul Cisek, Andy Clark, and Karl Friston. Generating meaning: active inference and the scope and limits of passive ai.Trends in Cognitive Sciences, 28(2): 97–112, 2024
2024
-
[25]
Active preference inference using language models and probabilistic reasoning
Top Piriyakulkij, V olodymyr Kuleshov, and Kevin Ellis. Active preference inference using language models and probabilistic reasoning. InNeurIPS 2023 Foundation Models for Decision Making Workshop, 2025
2023
-
[26]
Initial efficacy of mi, ttm tailoring and hri’s with multiple behaviors for employee health promotion.Preventive medicine, 46(3):226–231, 2008
James O Prochaska, Susan Butterworth, Colleen A Redding, Verna Burden, Nancy Perrin, Michael Leo, Marna Flaherty-Robb, and Janice M Prochaska. Initial efficacy of mi, ttm tailoring and hri’s with multiple behaviors for employee health promotion.Preventive medicine, 46(3):226–231, 2008
2008
-
[27]
Latent inter-user difference modeling for llm personalization
Yilun Qiu, Tianhao Shi, Xiaoyan Zhao, Fengbin Zhu, Yang Zhang, and Fuli Feng. Latent inter-user difference modeling for llm personalization. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 10610–10628, 2025
2025
-
[28]
Measuring what makes you unique: Difference-aware user modeling for enhancing llm personalization
Yilun Qiu, Xiaoyan Zhao, Yang Zhang, Yimeng Bai, Wenjie Wang, Hong Cheng, Fuli Feng, and Tat-Seng Chua. Measuring what makes you unique: Difference-aware user modeling for enhancing llm personalization. InFindings of the Association for Computational Linguistics: ACL 2025, pages 21258–21277, 2025
2025
-
[29]
Raptor: Recursive abstractive processing for tree-organized retrieval
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D Manning. Raptor: Recursive abstractive processing for tree-organized retrieval. InThe Twelfth International Conference on Learning Representations, 2024. 11
2024
-
[30]
Average user-side counterfactual fairness for collaborative filtering.ACM Transactions on Information Systems, 42(5):1–26, 2024
Pengyang Shao, Le Wu, Kun Zhang, Defu Lian, Richang Hong, Yong Li, and Meng Wang. Average user-side counterfactual fairness for collaborative filtering.ACM Transactions on Information Systems, 42(5):1–26, 2024
2024
-
[31]
Pmg: Personalized multimodal response generation with large language models
Xiaoteng Shen, Rui Zhang, Xiaoyan Zhao, Jieming Zhu, and Xi Xiao. Pmg: Personalized multimodal response generation with large language models. InThe Web Conference 2024
2024
-
[32]
Answering narrative-driven recommendation queries via a retrieve–rank paradigm and the ocg-agent
Yunxiao Shi, Haoning Shang, Xing Zi, Wujiang Xu, Yue Feng, and Min Xu. Answering narrative-driven recommendation queries via a retrieve–rank paradigm and the ocg-agent. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 13192–13213, 2025
2025
-
[33]
An active inference strategy for prompting reliable responses from large language models in medical practice.npj Digital Medicine, 8(1):119, 2025
Roma Shusterman, Allison C Waters, Shannon O’Neill, Marshall Bangs, Phan Luu, and Don M Tucker. An active inference strategy for prompting reliable responses from large language models in medical practice.npj Digital Medicine, 8(1):119, 2025
2025
-
[34]
Xin Sun, Xiao Tang, Abdallah El Ali, Zhuying Li, Xiaoyu Shen, Pengjie Ren, Jan de Wit, Jiahuan Pei, and Jos A Bosch. Chain-of-strategy planning with llms: Aligning the gener- ation of psychotherapy dialogue with strategy in motivational interviewing.arXiv preprint arXiv:2408.06527, 2024
-
[35]
Yihong Tang, Bo Wang, Miao Fang, Dongming Zhao, Kun Huang, Ruifang He, and Yuexian Hou. Enhancing personalized dialogue generation with contrastive latent variables.arXiv preprint arXiv:2305.11482, 2023
-
[36]
Msl: Not all tokens are what you need for tuning llm as a recommender
Bohao Wang, Feng Liu, Jiawei Chen, Xingyu Lou, Changwang Zhang, Jun Wang, Yuegang Sun, Yan Feng, Chun Chen, and Can Wang. Msl: Not all tokens are what you need for tuning llm as a recommender. InProceedings of the 48th international ACM SIGIR conference on research and development in information retrieval, pages 1912–1922, 2025
1912
-
[37]
Chengbing Wang, Yang Zhang, Wenjie Wang, Xiaoyan Zhao, Fuli Feng, Xiangnan He, and Tat-Seng Chua. Think-while-generating: On-the-fly reasoning for personalized long-form generation.arXiv preprint arXiv:2512.06690, 2025
-
[38]
Rlpf: Reinforcement learning from prediction feedback for user summarization with llms
Jiaxing Wu, Lin Ning, Luyang Liu, Harrison Lee, Neo Wu, Chao Wang, Sushant Prakash, Shawn O’Banion, Bradley Green, and Jun Xie. Rlpf: Reinforcement learning from prediction feedback for user summarization with llms. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 25488–25496, 2025
2025
-
[39]
Shirley Wu, Evelyn Choi, Arpandeep Khatua, Zhanghan Wang, Joy He-Yueya, Tharindu Cyril Weerasooriya, Wei Wei, Diyi Yang, Jure Leskovec, and James Zou. Humanlm: Simulating users with state alignment beats response imitation.arXiv preprint arXiv:2603.03303, 2026
-
[40]
Anno-mi: A dataset of expert-annotated counselling dialogues
Zixiu Wu, Simone Balloccu, Vivek Kumar, Rim Helaoui, Ehud Reiter, Diego Reforgiato Recu- pero, and Daniele Riboni. Anno-mi: A dataset of expert-annotated counselling dialogues. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6177–6181. IEEE, 2022
2022
-
[41]
Few-shot dialogue strategy learning for motiva- tional interviewing via inductive reasoning
Zhouhang Xie, Bodhisattwa Prasad Majumder, Mengjie Zhao, Yoshinori Maeda, Keiichi Yamada, Hiromi Wakaki, and Julian McAuley. Few-shot dialogue strategy learning for motiva- tional interviewing via inductive reasoning. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13207–13219, 2024
2024
-
[42]
Gajos, and Dakuo Zhang
Xuhai Xu, Bingsheng Yao, Yuanzhe Dong, Saadia Gabriel, Hong Yu, James Hendler, Krzysztof Z. Gajos, and Dakuo Zhang. Crafting personalized agents through retrieval-augmented generation on editable memory graphs. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024
2024
-
[43]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Reliable and responsible foundation models.Transactions on Machine Learning Research, 2025
Xinyu Yang, Junlin Han, Rishi Bommasani, Jinqi Luo, Wenjie Qu, Wangchunshu Zhou, Adel Bibi, Xiyao Wang, Jaehong Yoon, Elias Stengel-Eskin, et al. Reliable and responsible foundation models.Transactions on Machine Learning Research, 2025
2025
-
[45]
Cami: A counselor agent sup- porting motivational interviewing through state inference and topic exploration
Yizhe Yang, Palakorn Achananuparp, He-Yan Huang, Jing Jiang, Phey Ling Kit, Nicholas Gabriel Lim, Cameron Tan Shi Ern, and Ee-Peng Lim. Cami: A counselor agent sup- porting motivational interviewing through state inference and topic exploration. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Paper...
2025
-
[46]
Consistent client simulation for motivational interviewing-based counseling
Yizhe Yang, Palakorn Achananuparp, He-Yan Huang, Jing Jiang, Nicholas Gabriel Lim, Cameron Tan Shi Ern, Phey Ling Kit, Jenny Giam Xiuhui, John Pinto, and Ee-peng Lim. Consistent client simulation for motivational interviewing-based counseling. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)...
2025
-
[47]
Memweaver: A hierarchical memory from textual interactive behaviors for personalized genera- tion
Shuo Yu, Mingyue Cheng, Daoyu Wang, Qi Liu, Zirui Liu, Ze Guo, and Xiaoyu Tao. Memweaver: A hierarchical memory from textual interactive behaviors for personalized genera- tion. InProceedings of the ACM Web Conference 2026, pages 6920–6931, 2026
2026
-
[48]
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
Haozhen Zhang, Quanyu Long, Jianzhu Bao, Tao Feng, Weizhi Zhang, Haodong Yue, and Wenya Wang. Memskill: Learning and evolving memory skills for self-evolving agents.arXiv preprint arXiv:2602.02474, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
Prime: Large language model personalization with cognitive dual-memory and personalized thought process
Xinliang Frederick Zhang, Nick Beauchamp, and Lu Wang. Prime: Large language model personalization with cognitive dual-memory and personalized thought process. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 33695– 33724, 2025
2025
-
[50]
Reinforced latent reasoning for llm-based recommendation.ICLR, 2026
Yang Zhang, Wenxin Xu, Xiaoyan Zhao, Wenjie Wang, Fuli Feng, Xiangnan He, and Tat-Seng Chua. Reinforced latent reasoning for llm-based recommendation.ICLR, 2026
2026
-
[51]
Nextmem: Towards latent factual memory for llm-based agents.arXiv preprint arXiv:2603.15634, 2026
Zeyu Zhang, Rui Li, Xiaoyan Zhao, Yang Zhang, Wenjie Wang, Xu Chen, and Tat-Seng Chua. Nextmem: Towards latent factual memory for llm-based agents.arXiv preprint arXiv:2603.15634, 2026
-
[52]
Explicit vs implicit memory: Exploring multi-hop complex reasoning over personalized information
Zeyu Zhang, Yang Zhang, Haoran Tan, Rui Li, and Xu Chen. Explicit vs implicit memory: Exploring multi-hop complex reasoning over personalized information. InProceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, pages 1964–1974, 2026
1964
-
[53]
Xiaoyan Zhao, Yang Deng, Wenjie Wang, Hong Cheng, Rui Zhang, See-Kiong Ng, Tat-Seng Chua, et al. Exploring the impact of personality traits on conversational recommender systems: A simulation with large language models.arXiv preprint arXiv:2504.12313, 2025
-
[54]
Steerx: Disentangled steering for llm personalization.arXiv preprint arXiv:2510.22256, 2025
Xiaoyan Zhao, Ming Yan, Yilun Qiu, Haoting Ni, Yang Zhang, Fuli Feng, Hong Cheng, and Tat-Seng Chua. Steerx: Disentangled steering for llm personalization.arXiv preprint arXiv:2510.22256, 2025
-
[55]
Reinforced strategy optimization for conversational recommender systems via network-of-experts.arXiv e-prints, pages arXiv–2509, 2025
Xiaoyan Zhao, Ming Yan, Yang Zhang, Yang Deng, Jian Wang, Fengbin Zhu, Yilun Qiu, Hong Cheng, and Tat-Seng Chua. Reinforced strategy optimization for conversational recommender systems via network-of-experts.arXiv e-prints, pages arXiv–2509, 2025
2025
-
[56]
Nextquill: Causal preference modeling for enhancing llm personalization
Xiaoyan Zhao, Juntao You, Yang Zhang, Wenjie Wang, Hong Cheng, Fuli Feng, See-Kiong Ng, and Tat-Seng Chua. Nextquill: Causal preference modeling for enhancing llm personalization. ICLR, 2026
2026
-
[57]
abstract_cue
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 19724–19731, 2024. 13 A Evaluation Metrics We evaluate the framework from three perspectives: static state inference, dynamic counseling effectiv...
2024
-
[58]
Expectation Generation: from q(s_{t-1}), a_{t-1}, transition prior p, predict the structural regularities of the next move
-
[59]
Observation & Surprise Calculation: assimilate o_t; compute the structural prediction error vs Step 1 expectations as non-semantic regularities
-
[60]
## Strict Rules - Single valid JSON; no markdown fences; escape internal " as \"
State Update: update q to absorb the surprise; q_delta arrays may contain MULTIPLE add/modify/drop entries simultaneously. ## Strict Rules - Single valid JSON; no markdown fences; escape internal " as \". - cue tokens are short snake_case identifiers. - inference_entropy in [0,1]. ## State Boundary Rules - precontemplation: denies/minimizes the problem, e...
-
[61]
Acknowledgment, even reluctant, -> contemplation, not precontemplation
-
[62]
could",
Tentative planning ("could", "should", "I’ll try") -> preparation
-
[63]
yeah", "I don’t know
Brief responses ("yeah", "I don’t know") inherit context; do not regress. ## Update Operations (q_delta) Each operation is factored into: | Component | Definition | Examples | | transition_semantic | abstract latent transition type | resistance_to_engagement | | behavior_pattern | de-semanticized observable pattern | short_response_with_hedging | | state_...
-
[64]
What do you still need to learn about this patient? (exploration)
-
[65]
What action would best advance the patient toward change? (exploitation)
-
[66]
""{current_state}
Avoid repeating the same action -- try different approaches. Return ONLY the action name, nothing else. G.1.4 Counselor Response Generator Counselor Response Generator: System Prompt As a communication expert with outstanding communication habits, you embody the role of {agent_name} throughout the following dialogues. Here are some of your distinctive per...
2002
-
[67]
‘current_state‘: the label of the CURRENT patient utterance
-
[68]
current_state
‘next_state‘: the label the patient is MOST likely to express in their NEXT utterance after the doctor’s latest reply. Output JSON exactly as: {"current_state":"precontemplation|contemplation|preparation", "next_state": "precontemplation|contemplation|preparation", "rationale": "<brief>"} Full history: {history_text} 30
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.