Reasoning to Align: Implicit Reasoning in Diffusion Transformers for Video Editing
Pith reviewed 2026-06-30 13:33 UTC · model grok-4.3
The pith
RVEDiT induces implicit reasoning in diffusion transformers by routing LLM-derived editing tokens to shallow blocks and aligning attention features with a reference branch during training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
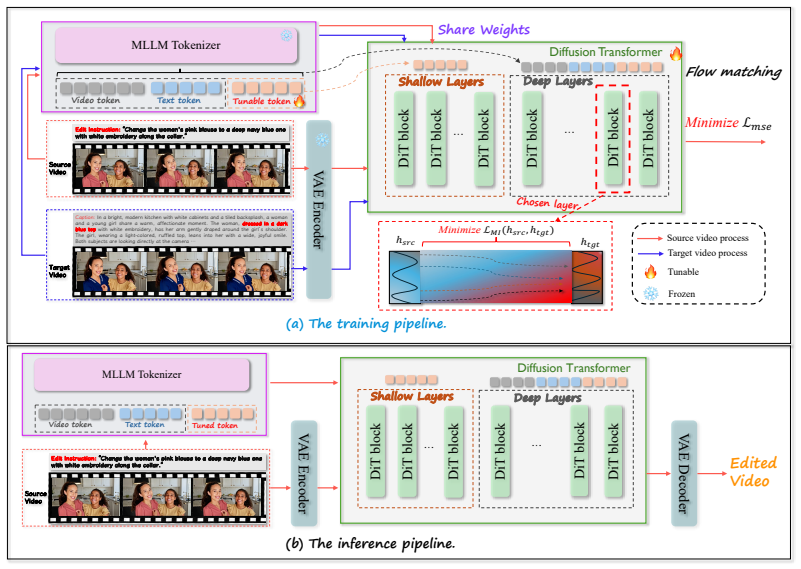
RVEDiT addresses the two structural limits of undifferentiated conditioning and indirect attention supervision by introducing Granularity-Routed Token Conditioning, which sends learnable editing tokens distilled from a multimodal LLM into shallow transformer blocks while holding native visual and text tokens for deeper blocks, together with Reference-Anchored Attention Alignment, which shares parameters with a reference branch at training time and maximizes mutual information between the two branches' attention features so that the editing branch learns a constrained internal reasoning process usable without the reference at inference.
What carries the argument
Granularity-Routed Token Conditioning paired with Reference-Anchored Attention Alignment, which routes coarse editing signals early and regularizes attention via mutual-information maximization against a training-only reference branch.
If this is right
- Localized spatial edits become more accurate because coarse editing intent is processed separately from fine visual detail.
- Compositional instructions are followed more reliably because the coarse-to-fine routing constrains how multiple constraints interact inside the network.
- Temporal coherence improves as the aligned attention patterns enforce consistency without extra post-processing.
- Inference cost remains identical to a standard DiT because the reference branch and mutual-information term are used only at training time.
Where Pith is reading between the lines
- The same separation of token granularity and attention alignment could be tested on image-only or 3D diffusion transformers to check whether the coarse-to-fine benefit is video-specific.
- If the alignment effect holds, future work could replace explicit chain-of-thought modules in other generative models with this cheaper training-time regularizer.
- The approach suggests that many current failures in instruction-conditioned generation stem from insufficient internal constraints rather than insufficient model capacity.
Load-bearing premise
Maximizing mutual information between the attention features of the editing and reference branches during training will cause the editing branch to develop internal reasoning that improves edits when the reference branch is removed at inference.
What would settle it
An ablation that trains identical models with and without the mutual-information alignment term and measures no difference in localized or compositional edit metrics on the same benchmarks.
Figures








read the original abstract
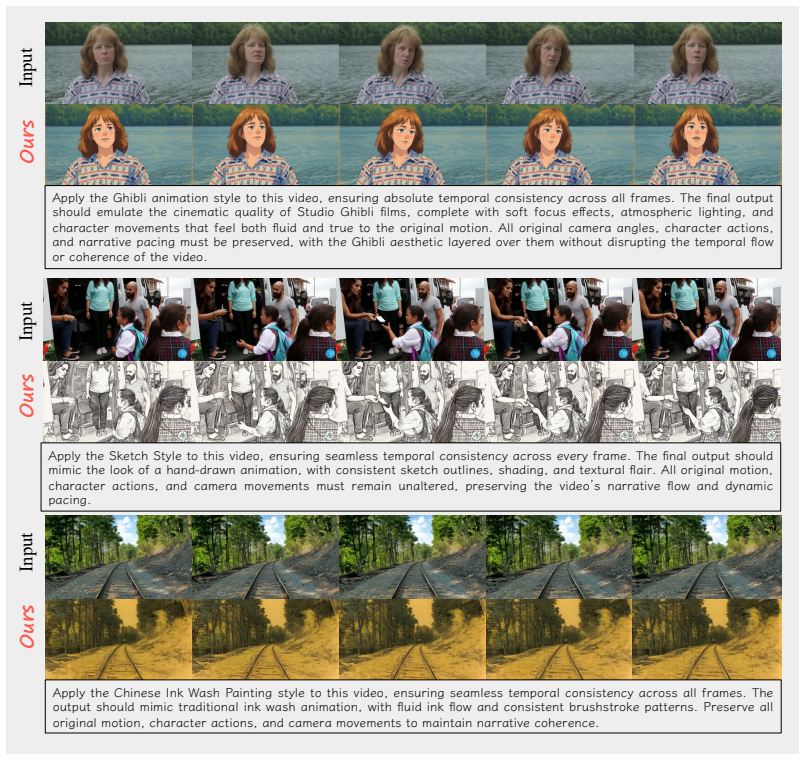
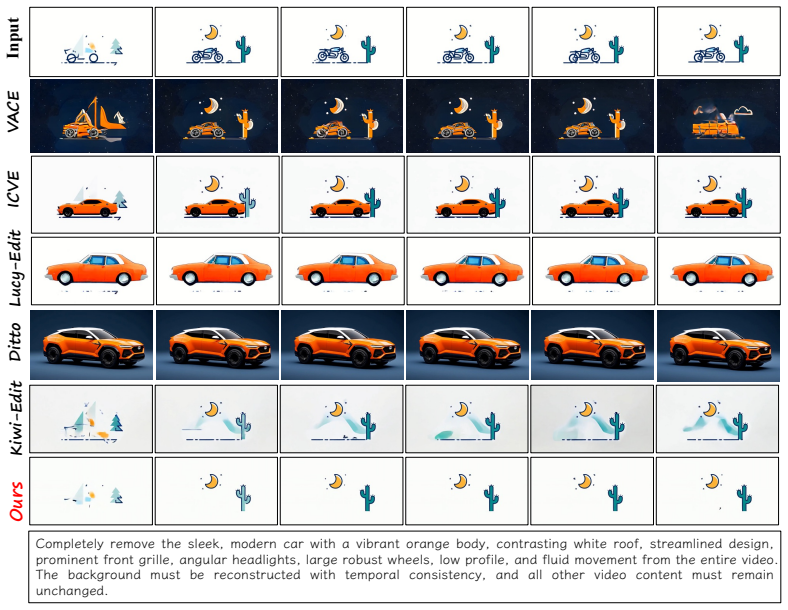
Instruction-based video editing requires transforming a source video according to a natural-language instruction while preserving irrelevant content and remaining temporally coherent. We argue that existing Diffusion Transformer (DiT) editors struggle with this task for two structural reasons. First, conditioning signals are fed undifferentiated into all transformer blocks, forcing a single token stream to encode both global editing intent and fine-grained visual evidence. Second, the cross-attention patterns that govern the edit are supervised only indirectly through pixel-level reconstruction, leaving the model's internal reasoning process under-constrained. To address both limitations, we propose RVEDiT, an implicit Reasoning Video Editing DiT framework built around two complementary components. The first, Granularity-Routed Token Conditioning, introduces learnable editing tokens distilled from a multimodal LLM and routes them to shallow blocks, while reserving native visual and textual tokens for deeper blocks, thereby inducing a coarse-to-fine editing process inside the backbone. The second, Reference-Anchored Attention Alignment, employs a parameter-sharing reference branch during training and maximizes the mutual information between the attention features of the editing and reference branches, regularizing the model's internal reasoning without incurring any additional inference cost. Experiments on standard instruction-based video editing benchmarks show that RVEDiT consistently outperforms state-of-the-art baselines, with particularly strong gains on localized and compositional edits.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RVEDiT, a Diffusion Transformer framework for instruction-based video editing. It introduces two components: Granularity-Routed Token Conditioning, which distills editing tokens from a multimodal LLM and routes them to shallow blocks while reserving visual/textual tokens for deeper blocks, and Reference-Anchored Attention Alignment, which uses a parameter-sharing reference branch during training and maximizes mutual information between attention features of the editing and reference branches. The paper claims these induce implicit coarse-to-fine reasoning that transfers to inference without extra cost, yielding consistent outperformance over state-of-the-art baselines on standard benchmarks, especially for localized and compositional edits.
Significance. If the performance gains are substantiated and attributable to the proposed mechanisms rather than other factors, the work could meaningfully advance instruction-based video editing by offering a training-only regularization strategy that addresses under-constrained internal reasoning in DiTs without inference overhead. The focus on routing and alignment for compositional edits targets a recognized limitation in current conditioning approaches.
major comments (3)
- Abstract: the claim that 'RVEDiT consistently outperforms state-of-the-art baselines' supplies no quantitative metrics, baseline names, dataset details, ablation results, or statistical significance tests, making it impossible to evaluate whether the data support the performance claim or to attribute gains to the proposed components.
- Description of Reference-Anchored Attention Alignment: the central assumption that maximizing mutual information between editing and reference attention features during training produces better internal reasoning that transfers to inference (after dropping the reference branch) is load-bearing for the claimed gains, yet no direct support is provided such as attention map comparisons, probing tasks, or controlled ablations removing the MI term.
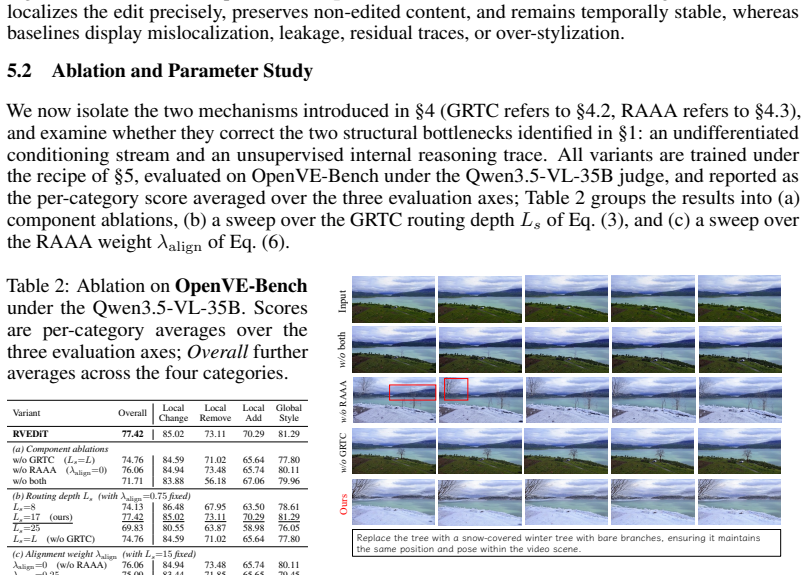
- Description of Granularity-Routed Token Conditioning: the assumption that routing LLM-derived editing tokens to shallow blocks induces an effective coarse-to-fine editing process is also unverified, with no ablations or visualizations demonstrating the routing's contribution to handling localized/compositional edits versus simply using the multimodal tokens.
minor comments (1)
- Abstract: 'standard instruction-based video editing benchmarks' are referenced without naming the specific datasets or protocols used, which should be clarified for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract requires more concrete quantitative support and that additional direct evidence for the two proposed mechanisms would strengthen the claims. We will make revisions accordingly and respond to each major comment below.
read point-by-point responses
-
Referee: Abstract: the claim that 'RVEDiT consistently outperforms state-of-the-art baselines' supplies no quantitative metrics, baseline names, dataset details, ablation results, or statistical significance tests, making it impossible to evaluate whether the data support the performance claim or to attribute gains to the proposed components.
Authors: We agree that the abstract would be more informative with explicit metrics. The experiments section already contains these details (quantitative comparisons on standard benchmarks against named baselines, ablation tables, and dataset descriptions). In the revision we will move key numbers, baseline names, and references to the ablation studies into the abstract itself. revision: yes
-
Referee: Description of Reference-Anchored Attention Alignment: the central assumption that maximizing mutual information between editing and reference attention features during training produces better internal reasoning that transfers to inference (after dropping the reference branch) is load-bearing for the claimed gains, yet no direct support is provided such as attention map comparisons, probing tasks, or controlled ablations removing the MI term.
Authors: The existing ablation that removes the entire alignment module shows measurable drops on localized edits, providing indirect support. To address the request for direct evidence we will add (i) side-by-side attention-map visualizations of the editing versus reference branches and (ii) a controlled ablation that isolates the mutual-information term while keeping the reference branch. revision: yes
-
Referee: Description of Granularity-Routed Token Conditioning: the assumption that routing LLM-derived editing tokens to shallow blocks induces an effective coarse-to-fine editing process is also unverified, with no ablations or visualizations demonstrating the routing's contribution to handling localized/compositional edits versus simply using the multimodal tokens.
Authors: The manuscript already contains an ablation that compares routed versus non-routed placement of the editing tokens and reports gains on compositional edits. To make the coarse-to-fine claim more explicit we will add block-wise activation visualizations that contrast the effect of routing the LLM tokens to shallow layers versus feeding them uniformly. revision: yes
Circularity Check
No circularity: method introduces independent training components with empirical validation
full rationale
The paper's derivation chain consists of proposing two new architectural/training mechanisms (Granularity-Routed Token Conditioning via LLM-distilled tokens routed to shallow blocks, and Reference-Anchored Attention Alignment via parameter-shared reference branch with mutual information maximization on attention features) to address stated limitations in DiT conditioning and supervision. No equations, self-definitional reductions, fitted-input-as-prediction steps, or load-bearing self-citations appear in the provided text that would make any claimed result equivalent to its inputs by construction. The central claims rest on the introduction of these components plus benchmark experiments, rendering the chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Agarwal, S
A. Agarwal, S. Karanam, K. Joseph, A. Saxena, K. Goswami, and B. V . Srinivasan. A-star: Test- time attention segregation and retention for text-to-image synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2283–2293, 2023
2023
-
[3]
Q. Bai, Q. Wang, H. Ouyang, H. Wang, W. Wang, K. L. Cheng, S. Ma, Y . Zeng, Y . Yu, Z. Liu, et al. Ditto: Scaling instruction-based video editing with a high-quality synthetic dataset
- [4]
-
[5]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Brooks, A
T. Brooks, A. Holynski, and A. A. Efros. Instructpix2pix: Learning to follow image editing instructions. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18392–18402, 2023
2023
-
[7]
Brown, B
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[8]
M. Cao, X. Wang, Z. Qi, Y . Shan, X. Qie, and Y . Zheng. Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing. InProceedings of the IEEE/CVF international conference on computer vision, pages 22560–22570, 2023
2023
-
[9]
Chefer, Y
H. Chefer, Y . Alaluf, Y . Vinker, L. Wolf, and D. Cohen-Or. Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models.ACM transactions on Graphics (TOG), 42(4):1–10, 2023
2023
-
[10]
Chefer, S
H. Chefer, S. Zada, R. Paiss, A. Ephrat, O. Tov, M. Rubinstein, L. Wolf, T. Dekel, T. Michaeli, and I. Mosseri. Still-moving: Customized video generation without customized video data.ACM Transactions on Graphics (TOG), 43(6):1–11, 2024
2024
-
[11]
S. Chen, M. Xu, J. Ren, Y . Cong, S. He, Y . Xie, A. Sinha, P. Luo, T. Xiang, and J.-M. Perez-Rua. Gentron: Diffusion transformers for image and video generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6441–6451, 2024
2024
-
[12]
S. X. Chen, M. Sra, and P. Sen. Instruct-clip: Improving instruction-guided image editing with automated data refinement using contrastive learning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 28513–28522, 2025
2025
-
[13]
arXiv preprint arXiv:2311.00213 (2023)
J. Cheng, T. Xiao, and T. He. Consistent video-to-video transfer using synthetic dataset.arXiv preprint arXiv:2311.00213, 2023
-
[14]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [15]
-
[16]
Esser, S
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. Müller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
2024
-
[17]
TokenFlow: Consistent Diffusion Features for Consistent Video Editing
M. Geyer, O. Bar-Tal, S. Bagon, and T. Dekel. Tokenflow: Consistent diffusion features for consistent video editing.arXiv preprint arXiv:2307.10373, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [18]
-
[19]
Prompt-to-Prompt Image Editing with Cross Attention Control
A. Hertz, R. Mokady, J. Tenenbaum, K. Aberman, Y . Pritch, and D. Cohen-Or. Prompt-to-prompt image editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[21]
N. Ho, S. Bae, T. Kim, H. Jo, Y . Kim, T. Schuster, A. Fisch, J. Thorne, and S.-Y . Yun. Block transformer: Global-to-local language modeling for fast inference.Advances in Neural Information Processing Systems, 37:48740–48783, 2024
2024
-
[22]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[23]
Jiang, T
Y . Jiang, T. Wu, S. Yang, C. Si, D. Lin, Y . Qiao, C. C. Loy, and Z. Liu. Videobooth: Diffusion-based video generation with image prompts. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6689–6700, 2024
2024
-
[24]
Jiang, Z
Z. Jiang, Z. Han, C. Mao, J. Zhang, Y . Pan, and Y . Liu. Vace: All-in-one video creation and editing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 17191–17202, 2025
2025
- [25]
- [26]
-
[27]
Y . Lin, G. Liang, Z. Zeng, Z. Bai, Y . Chen, and M. Z. Shou. Kiwi-edit: Versatile video editing via instruction and reference guidance.arXiv preprint arXiv:2603.02175, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
L. Liu, T. Ma, B. Li, Z. Chen, J. Liu, G. Li, S. Zhou, Q. He, and X. Wu. Phantom: Subject-consistent video generation via cross-modal alignment. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14951–14961, 2025
2025
-
[30]
S. Liu, Y . Zhang, W. Li, Z. Lin, and J. Jia. Video-p2p: Video editing with cross-attention control. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8599–8608, 2024
2024
-
[31]
Y . Mao, Z. Qin, X. Shen, J. Zhou, J. Zhang, Y . Zhong, and Y . Dai. Ldt: Efficient scalable video generation using linear diffusion transformer.IEEE Transactions on Multimedia, 2026
2026
-
[32]
A. v. d. Oord, Y . Li, and O. Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
Ouyang, Y
W. Ouyang, Y . Dong, L. Yang, J. Si, and X. Pan. I2vedit: First-frame-guided video editing via image-to- video diffusion models. InSIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024
2024
-
[34]
Patashnik, D
O. Patashnik, D. Garibi, I. Azuri, H. Averbuch-Elor, and D. Cohen-Or. Localizing object-level shape variations with text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 23051–23061, 2023
2023
-
[35]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[36]
Movie Gen: A Cast of Media Foundation Models
A. Polyak, A. Zohar, A. Brown, A. Tjandra, A. Sinha, A. Lee, A. Vyas, B. Shi, C.-Y . Ma, C.-Y . Chuang, et al. Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
C. Qi, X. Cun, Y . Zhang, C. Lei, X. Wang, Y . Shan, and Q. Chen. Fatezero: Fusing attentions for zero-shot text-based video editing. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15932–15942, 2023
2023
-
[38]
B. Qin, J. Li, S. Tang, T.-S. Chua, and Y . Zhuang. Instructvid2vid: Controllable video editing with natural language instructions. In2024 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2024. 11
2024
-
[39]
Rassin, E
R. Rassin, E. Hirsch, D. Glickman, S. Ravfogel, Y . Goldberg, and G. Chechik. Linguistic binding in diffusion models: Enhancing attribute correspondence through attention map alignment.Advances in Neural Information Processing Systems, 36:3536–3559, 2023
2023
- [40]
-
[41]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[42]
Shagidanov, H
A. Shagidanov, H. Poghosyan, X. Gong, Z. Wang, S. Navasardyan, and H. Shi. Grounded-instruct-pix2pix: Improving instruction based image editing with automatic target grounding. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6585–6589. IEEE, 2024
2024
- [43]
- [44]
-
[45]
R. Tang, L. Liu, A. Pandey, Z. Jiang, G. Yang, K. Kumar, P. Stenetorp, J. Lin, and F. Türe. What the daam: Interpreting stable diffusion using cross attention. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5644–5659, 2023
2023
-
[46]
D. Team. Lucy edit: Open-weight text-guided video editing, 2025
2025
-
[47]
S. Tu, Q. Dai, Z. Zhang, S. Xie, Z.-Q. Cheng, C. Luo, X. Han, Z. Wu, and Y .-G. Jiang. Motionfollower: Editing video motion via score-guided diffusion. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12822–12831, 2025
2025
-
[48]
Tumanyan, M
N. Tumanyan, M. Geyer, S. Bagon, and T. Dekel. Plug-and-play diffusion features for text-driven image-to- image translation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1921–1930, 2023
1921
-
[49]
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
J. Z. Wu, Y . Ge, X. Wang, S. W. Lei, Y . Gu, Y . Shi, W. Hsu, Y . Shan, X. Qie, and M. Z. Shou. Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation. InProceedings of the IEEE/CVF international conference on computer vision, pages 7623–7633, 2023
2023
-
[51]
G. Xiao, T. Yin, W. T. Freeman, F. Durand, and S. Han. Fastcomposer: Tuning-free multi-subject image generation with localized attention.International Journal of Computer Vision, 133(3):1175–1194, 2025
2025
- [52]
-
[53]
H. Ye, J. Zhang, S. Liu, X. Han, and W. Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[54]
S. Yu, D. Liu, Z. Ma, Y . Hong, Y . Zhou, H. Tan, J. Chai, and M. Bansal. Veggie: Instructional editing and reasoning video concepts with grounded generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15147–15158, 2025
2025
-
[55]
Zhang, A
L. Zhang, A. Rao, and M. Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023
2023
-
[56]
Meta-CoT: Enhancing Granularity and Generalization in Image Editing
S. Zhang, Y . Cheng, T. Hang, Z. Yin, R. He, Y . Xu, W. Dai, Y . Lin, C. Wang, Q. Lu, et al. Meta-cot: Enhancing granularity and generalization in image editing.arXiv preprint arXiv:2604.24625, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [57]
-
[58]
Region-Constraint In-Context Generation for Instructional Video Editing
Z. Zhang, F. Long, W. Li, Z. Qiu, W. Liu, T. Yao, and T. Mei. Region-constraint in-context generation for instructional video editing.arXiv preprint arXiv:2512.17650, 2025. 12
-
[59]
R. Zhao, Y . Gu, J. Z. Wu, D. J. Zhang, J.-W. Liu, W. Wu, J. Keppo, and M. Z. Shou. Motiondirector: Motion customization of text-to-video diffusion models. InEuropean Conference on Computer Vision, pages 273–290. Springer, 2024
2024
-
[60]
Y . Zhu, H. Wang, S. Ma, W. Zhao, Y . Tang, L. Chen, and J. Zhou. Fade: Frequency-aware diffusion model factorization for video editing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 28426–28435, 2025
2025
-
[61]
B. Zi, P. Ruan, M. Chen, X. Qi, S. Hao, S. Zhao, Y . Huang, B. Liang, R. Xiao, and K.-F. Wong. Se \˜ norita-2m: A high-quality instruction-based dataset for general video editing by video specialists.arXiv preprint arXiv:2502.06734, 2025. 13 A Related Work A.1 Reference-guided Video Generation and Editing A complementary line of work conditions generation...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.