StepGap: A Hybrid NLI-LLM Checker for Step-Level Evidence-Gap Detectionin Multi-Hop Question Answering
Pith reviewed 2026-06-30 12:54 UTC · model grok-4.3
The pith
StepGap, a hybrid NLI-LLM decision tree, detects typed evidence gaps at each step of multi-hop QA with accuracy matching LLM-only methods but with a decomposable structure that avoids competing-error cancellation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
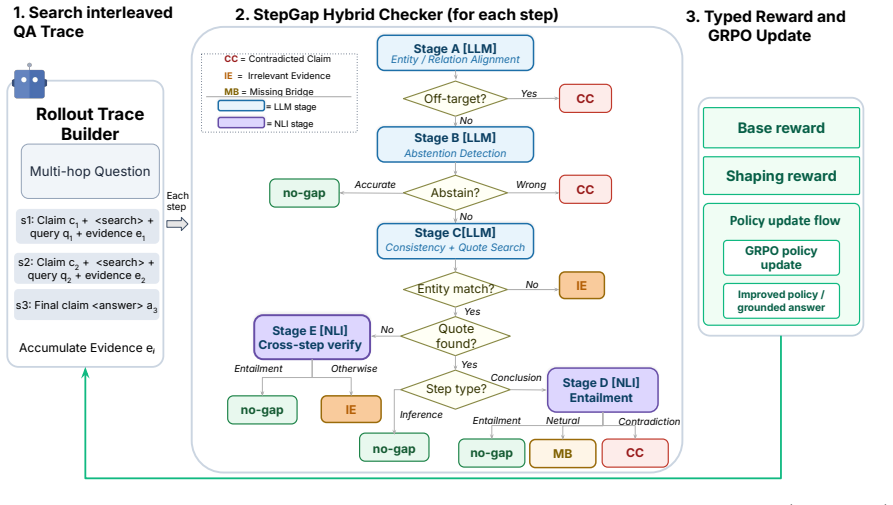
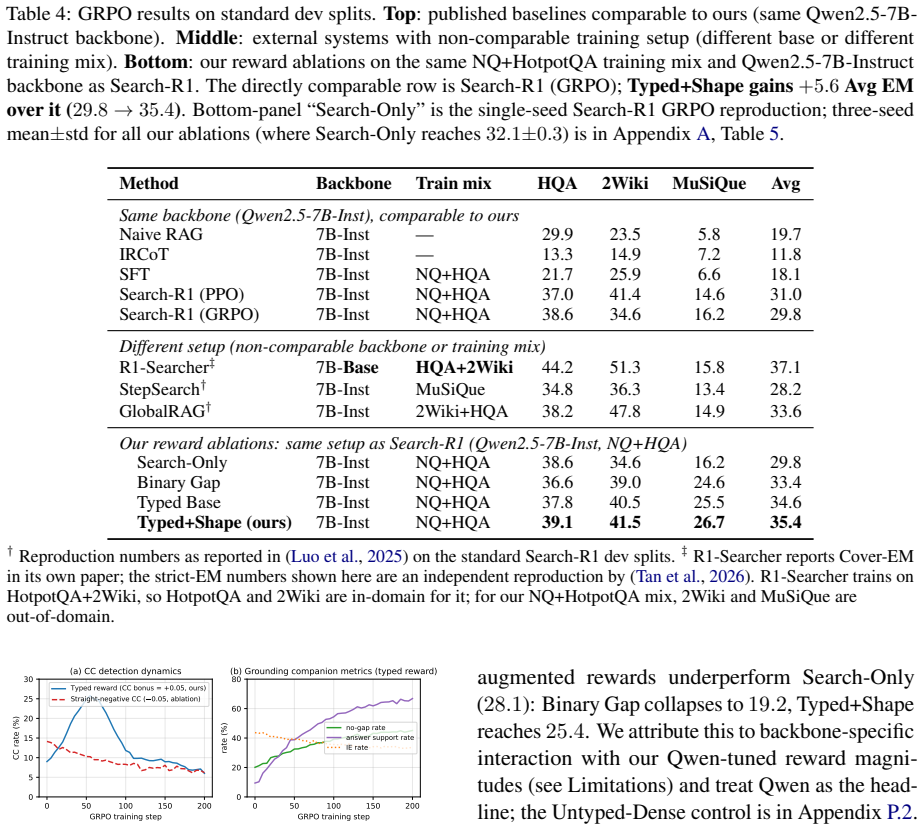
StepGap is a hybrid NLI-LLM decision tree that detects step-level evidence gaps in multi-hop QA and emits one of three typed labels: Contradicted Claim (CC), Irrelevant Evidence (IE), or Missing Bridge (MB), each tied to a concrete repair action. On 82 multi-hop questions with 181 annotated steps, StepGap reaches sF1 of 72.0, within the bootstrap confidence interval of an LLM-only baseline at 70.1, but with a decomposable structure where every stage hurts F1 when removed. It exposes the Q-F1 trap where question-level F1 is inflated by checkers that flag every step and, when used as a typed GRPO process reward, improves Qwen2.5-7B-Instruct Exact Match from 32.1±0.3 to 35.4±0.9 across three se
What carries the argument
Hybrid NLI-LLM decision tree that classifies step-level evidence gaps into Contradicted Claim (CC), Irrelevant Evidence (IE), or Missing Bridge (MB) labels
If this is right
- Step-level F1 is the necessary diagnostic because question-level F1 is mechanically inflated by checkers that flag every step.
- Every StepGap stage contributes positively since removing any stage lowers F1.
- LLM-only baselines exhibit competing-error cancellation where three of four component removals improve F1.
- Using StepGap as a typed GRPO process reward raises Exact Match on the 7B model from 32.1 to 35.4 across seeds.
Where Pith is reading between the lines
- The typed labels could enable targeted repairs in other step-by-step reasoning domains such as mathematical derivations.
- The decomposable design may reduce reliance on post-hoc error analysis when training models on long reasoning chains.
- Future tests on larger models could check whether the performance lift from StepGap rewards scales with model size.
Load-bearing premise
The 181 annotated steps with inter-annotator agreement of 0.704 provide reliable ground truth for evaluating step-level performance and comparing StepGap to LLM-only baselines.
What would settle it
A new annotation set on additional multi-hop questions where StepGap sF1 falls outside the LLM baseline confidence interval or where ablation shows no consistent F1 drop when StepGap stages are removed would falsify the claim of superior decomposability.
Figures

read the original abstract
We present \textbf{StepGap}, a hybrid NLI-LLM decision tree that detects step-level evidence gaps in multi-hop QA and emits one of three typed labels: \textsc{Contradicted Claim} (CC), \textsc{Irrelevant Evidence} (IE), or \textsc{Missing Bridge} (MB), each tied to a concrete repair action. On 82 multi-hop questions (181 annotated steps, $\kappa{=}0.704$), StepGap reaches sF1$=$72.0, within the bootstrap confidence interval of an LLM-only baseline (70.1) but with a more decomposable structure: every StepGap stage \emph{hurts} F1 when removed, while three of four LLM-only removals \emph{improve} F1 -- a sign of \emph{competing-error cancellation}, where internal stages mask each other's errors. We further expose a \emph{Q-F1 trap}: question-level F1 is mechanically inflated by checkers that flag every step, making step-level F1 the necessary diagnostic. Used as a typed GRPO process reward, StepGap improves Qwen2.5-7B-Instruct Exact Match from $32.1{\pm}0.3$ to $35.4{\pm}0.9$ across three seeds, with the single-run comparison showing a $+5.6$ Avg EM gain over the matched Search-R1 GRPO reproduction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents StepGap, a hybrid NLI-LLM decision tree for detecting step-level evidence gaps in multi-hop QA. It assigns one of three typed labels (Contradicted Claim, Irrelevant Evidence, Missing Bridge) tied to repair actions. On 82 questions with 181 annotated steps (κ=0.704), it reports sF1=72.0 (within bootstrap CI of LLM-only baseline at 70.1) but with greater decomposability: every StepGap stage decreases F1 when ablated, unlike the LLM baseline where three of four improve F1, interpreted as competing-error cancellation. It identifies a Q-F1 trap where question-level F1 is inflated by over-flagging, and shows downstream gains when used as a typed GRPO process reward, improving Qwen2.5-7B-Instruct Exact Match from 32.1±0.3 to 35.4±0.9 across three seeds (+5.6 over Search-R1 reproduction).
Significance. If the decomposability claim and downstream gains hold under reliable labels, the work provides a concrete advance in structured process supervision for multi-hop reasoning, with the typed labels enabling targeted repairs and the GRPO experiment offering falsifiable evidence of utility in RL training. The Q-F1 trap diagnosis is a useful methodological contribution for evaluation in this area.
major comments (2)
- [Results section (ablation analysis)] Results section (ablation analysis reporting sF1=72.0 and stage removals): The central claim of superior decomposability and 'competing-error cancellation' (every StepGap stage hurts F1 on removal, while LLM-only stages improve it) is load-bearing on the 181 human-annotated steps as ground truth. With only moderate IAA (κ=0.704) on a 3-class task over short steps, label noise can flip ablation deltas and produce spurious patterns; no sensitivity analysis to label perturbations is reported.
- [Method section] Method section (hybrid decision tree description): The abstract and evaluation report sF1 results and downstream GRPO gains without detailing the exact NLI-LLM integration, decision tree structure, bootstrap CI methodology, or data exclusion rules. This prevents verification that the hybrid structure (rather than implementation artifacts) drives the observed decomposability.
minor comments (2)
- [Evaluation setup] The paper should clarify the exact number of steps per question distribution and any filtering criteria applied to the 181 annotated steps.
- Table or figure reporting per-label precision/recall would help interpret whether the sF1 gain is driven by specific classes (CC/IE/MB).
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Results section (ablation analysis)] Results section (ablation analysis reporting sF1=72.0 and stage removals): The central claim of superior decomposability and 'competing-error cancellation' (every StepGap stage hurts F1 on removal, while LLM-only stages improve it) is load-bearing on the 181 human-annotated steps as ground truth. With only moderate IAA (κ=0.704) on a 3-class task over short steps, label noise can flip ablation deltas and produce spurious patterns; no sensitivity analysis to label perturbations is reported.
Authors: We agree that κ=0.704 indicates moderate agreement and that label noise could in principle affect ablation deltas. The bootstrap CIs provide one robustness check, and the uniform direction of all four StepGap ablations (each decreasing F1) is unlikely to arise solely from noise, but we acknowledge the absence of an explicit sensitivity analysis. In the revision we will add a label-perturbation experiment that samples from the observed confusion matrix and recomputes the ablation deltas; this will be reported alongside the existing bootstrap results. revision: yes
-
Referee: [Method section] Method section (hybrid decision tree description): The abstract and evaluation report sF1 results and downstream GRPO gains without detailing the exact NLI-LLM integration, decision tree structure, bootstrap CI methodology, or data exclusion rules. This prevents verification that the hybrid structure (rather than implementation artifacts) drives the observed decomposability.
Authors: We accept that the current Method section is insufficiently detailed for independent verification. The revised manuscript will expand the description to include: (i) the exact decision-tree topology and the NLI model / LLM prompt used at each node, (ii) the bootstrap procedure (number of replicates, resampling unit, and random seed), and (iii) the precise data-exclusion criteria applied to the 181 steps. These additions will allow readers to confirm that the reported decomposability stems from the hybrid design rather than implementation choices. revision: yes
Circularity Check
No circularity; empirical results rest on independent annotations
full rationale
The paper reports sF1, ablation deltas, and downstream GRPO gains computed directly against 181 human-annotated steps (with stated κ=0.704) and a held-out QA task. No equations, fitted parameters, or self-citations are invoked to derive the performance numbers; the claims are falsifiable measurements on external labels rather than reductions by construction. The evaluation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rag-star: Enhancing deliberative reasoning with retrieval augmented verification and refinement. InProceedings of the 2025 Conference of the Na- tions of the Americas Chapter of the Association for Computational Linguistics: Human Language Tech- nologies (Volume 1: Long Papers), pages 7064–7074. Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Ari...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Let’s verify step by step.arXiv preprint arXiv:2305.20050. Weisi Liu, Guangzeng Han, and Xiaolei Huang. 2025. Examining and adapting time for multilingual clas- sification via mixture of temporal experts. InPro- ceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Compu- tational Linguistics: Human Language Technol...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models
SelfCheckGPT: Zero-resource black-box hal- lucination detection for generative large language models.arXiv preprint arXiv:2303.08896. Mary L McHugh. 2012. Interrater reliability: the kappa statistic.Biochemia medica, 22(3):276–282. Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Haj...
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[4]
MMSearch-R1: Incentivizing LMMs to Search
Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations. InProceed- ings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers), pages 9426–9439, Bangkok, Thailand. Associ- ation for Computational Linguistics. Jinming Wu, Zihao Deng, Wei Li, Yiding Liu, Bo You, Bo Li, Zejun Ma, and Ziw...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Kuhn is a British physicist
“Kuhn is a British physicist” Stage D: NLI=ENTAILMENT(quote found, supported)→no-gap
-
[6]
Per- tramer is a German ac- tress
“Per- tramer is a German ac- tress” Stage D: NLI=ENTAILMENT→no-gap
-
[7]
Britain ̸= Ger- many
“Britain ̸= Ger- many” common-knowledge inference, no quote needed→no-gap
-
[8]
There- fore not from same country
“There- fore not from same country” Stage D: NLI=NEUTRAL; quote found but does not entail (“British physicist” specifies nationality, not country of birth)→MB StepGap correctly identifies the conclusion step as MISSINGBRIDGE: the retrieved evidence supports the sub-claim “Kuhn is British” butnotthe unstated bridging premise “Kuhn was born in Britain.” The...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.