GRAIL: AI translation for scientists application workflow on satellite data
Pith reviewed 2026-06-30 12:47 UTC · model grok-4.3
The pith
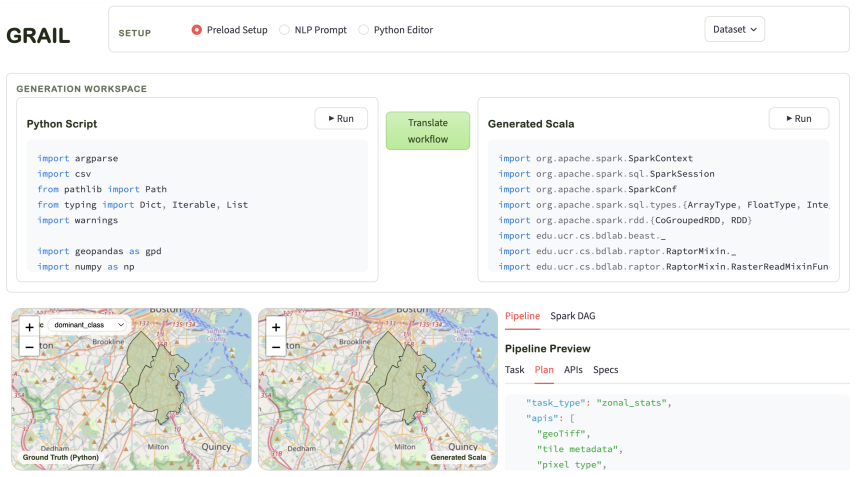
GRAIL automatically translates Python geospatial workflows for satellite data into executable Spark programs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
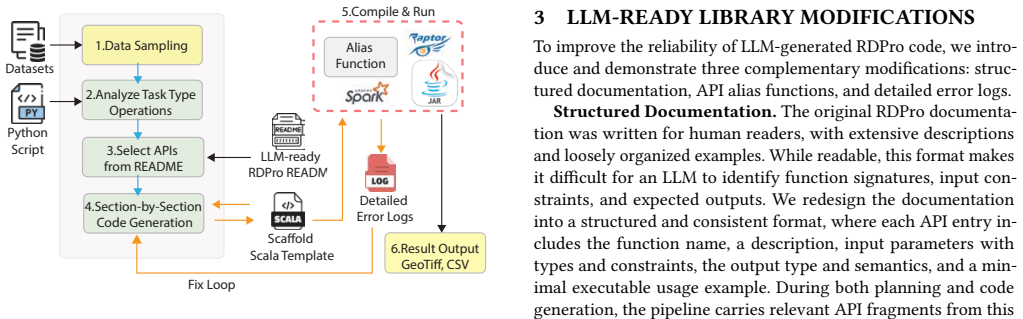
GRAIL is an agentic translation system that converts Python geospatial workflows into executable Spark-based programs without requiring scientists to learn a new framework. Rather than fine-tuning a specialized model, it adapts a Scala library for satellite data analysis to make it LLM-ready using structured documentation, API alias functions, and repair-oriented error logs. Translation is structured as a pipeline that decomposes code generation into explicit sections with guided inputs and outputs, enabling targeted repair without regenerating the full program.
What carries the argument
The pipeline that decomposes code generation into explicit sections with guided inputs and outputs for targeted repair, enabled by adapting the satellite data library with structured documentation, aliases, and repair logs.
If this is right
- Scientists can scale existing Python satellite analysis scripts to large datasets without rewriting them in another language.
- Generated programs maintain correctness on real workflows as shown in the demonstrations.
- Targeted section-by-section repair reduces the need to regenerate entire translations when issues arise.
- The same Python code can run on both small test sets and full-scale satellite data collections.
Where Pith is reading between the lines
- Library authors in other domains could adopt similar documentation practices to support automated translation of their users' scripts.
- The method suggests that AI-assisted translation may lower barriers between quick prototype scripts and production-scale analysis in earth observation.
- Extending the approach to additional satellite data sources or analysis tasks could be tested by measuring translation success rates on held-out workflows.
Load-bearing premise
Preparing the satellite data library with structured documentation, API alias functions, and repair-oriented error logs is sufficient for an LLM to produce correct and scalable translations of complex geospatial workflows.
What would settle it
Apply GRAIL to a new real-world geospatial workflow not used in the paper's demonstrations and check whether the output Spark program matches the original Python results exactly while scaling to larger data without errors or extra fixes.
Figures

read the original abstract
Domain scientists increasingly develop Python scripts to analyze satellite imagery but they lack scalability to large-scale data. This paper demonstrates GRAIL, an agentic translation system that converts Python geospatial workflows into executable Spark-based programs without requiring scientists to learn a new framework. Rather than fine-tuning a specialized LLM model, GRAIL adapts RDPro, a Scala library for satellite data analysis, to make it LLM-ready using structured documentation, API alias functions, and repair-oriented error logs. Translation is structured as a LangGraph pipeline that decomposes code generation into explicit sections with guided inputs and outputs, enabling targeted repair without regenerating the full program. We demonstrate GRAIL on real-world geospatial workflows and showcase the correctness and scalability of the translated code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents GRAIL, an agentic translation system that converts Python geospatial workflows into executable Spark-based programs by adapting the RDPro Scala library (via structured documentation, API alias functions, and repair-oriented error logs) and structuring generation as a LangGraph pipeline with explicit decomposition and targeted repair. It claims to demonstrate the correctness and scalability of the resulting code on real-world satellite data workflows without requiring scientists to learn a new framework.
Significance. If the central claim holds with quantitative support, GRAIL could meaningfully lower the barrier for domain scientists to scale existing Python satellite-imagery scripts to large datasets by leveraging distributed Spark execution, representing a practical engineering contribution at the intersection of LLM agents and geospatial data processing.
major comments (2)
- [Abstract] Abstract: the claim that GRAIL 'demonstrate[s] ... the correctness and scalability of the translated code' on real-world workflows is load-bearing for the paper's contribution, yet the text supplies no quantitative metrics (e.g., correctness rates, runtime scaling curves, memory usage, or error counts), no baselines, and no failure-mode analysis.
- [Demonstration / evaluation section] Demonstration / evaluation section (full text): the assumption that RDPro adaptations (structured docs, API aliases, repair logs) plus LangGraph decomposition suffice to produce correct, scalable translations for domain-specific operations (projections, raster tiling, temporal joins, memory-intensive reductions) is not supported by any reported correctness or scalability measurements, leaving the weakest assumption untested.
minor comments (1)
- [Methods / pipeline description] Notation for LangGraph pipeline stages and RDPro API aliases is introduced without a consolidated table or diagram, making the decomposition hard to follow on first reading.
Simulated Author's Rebuttal
We thank the referee for these focused comments on the evaluation. We agree that the claims of correctness and scalability in the abstract and demonstration section require quantitative backing to be fully substantiated, and we will strengthen the manuscript with explicit metrics, baselines, and analysis in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that GRAIL 'demonstrate[s] ... the correctness and scalability of the translated code' on real-world workflows is load-bearing for the paper's contribution, yet the text supplies no quantitative metrics (e.g., correctness rates, runtime scaling curves, memory usage, or error counts), no baselines, and no failure-mode analysis.
Authors: We accept this observation. The current abstract states a demonstration but does not include supporting numbers. In the revised version we will add concrete metrics (translation success rate across the tested workflows, runtime scaling with dataset size, memory usage, and error counts before/after repair) together with a simple baseline comparison against direct LLM generation without the RDPro adaptations or LangGraph structure. revision: yes
-
Referee: [Demonstration / evaluation section] Demonstration / evaluation section (full text): the assumption that RDPro adaptations (structured docs, API aliases, repair logs) plus LangGraph decomposition suffice to produce correct, scalable translations for domain-specific operations (projections, raster tiling, temporal joins, memory-intensive reductions) is not supported by any reported correctness or scalability measurements, leaving the weakest assumption untested.
Authors: The manuscript currently offers only a qualitative walkthrough on real-world satellite workflows. We will expand the evaluation section to report quantitative results for the listed operations: correctness measured as the fraction of workflows that execute without manual intervention after the repair loop, and scalability shown via runtime and memory curves on progressively larger raster collections. Failure modes (e.g., projection mismatches or memory spikes) will also be tabulated. revision: yes
Circularity Check
No circularity: engineering pipeline with no derivations or self-referential reductions
full rationale
The paper describes GRAIL as an agentic LangGraph-based translation system that adapts RDPro via documentation, aliases, and error logs to enable LLM conversion of Python geospatial scripts to Spark. No equations, fitted parameters, predictions of derived quantities, uniqueness theorems, or self-citation chains appear in the derivation chain. The central claim rests on system implementation and demonstration on real-world workflows, which is self-contained as an engineering artifact without reducing any result to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A demonstration of GeoSpark: A cluster computing framework for processing big spatial data
Jia Yu, Jinxuan Wu, and Mohamed Sarwat. A demonstration of GeoSpark: A cluster computing framework for processing big spatial data. InProceedings of the 32nd IEEE International Conference on Data Engineering (ICDE), 2016
2016
-
[2]
RDPro: Distributed processing of big raster data.Proceedings of the VLDB Endowment, 18(3), 2024
Zhuocheng Shang, Samriddhi Singla, Ahmed Eldawy, and Elia Scudiero. RDPro: Distributed processing of big raster data.Proceedings of the VLDB Endowment, 18(3), 2024
2024
-
[3]
FieldSAT: A scalable query workflow for precision agriculture with large raster datasets
Zhuocheng Shang, Ahmed Eldawy, Elia Scudiero, Ramesh Dhungel, and Ray Anderson. FieldSAT: A scalable query workflow for precision agriculture with large raster datasets. InProceedings of the 33rd ACM International Conference on Advances in Geographic Information Systems, SIGSPATIAL ’25. ACM, 2025
2025
-
[4]
Generating highly customizable python code for data pro- cessing with large language models.The VLDB Journal, 34(2):21, 2025
Immanuel Trummer. Generating highly customizable python code for data pro- cessing with large language models.The VLDB Journal, 34(2):21, 2025
2025
-
[5]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guant- ing Chen, Xiao Bi, Yifan Wu, Y. K. Li, and others. DeepSeek-Coder: When the large language model meets programming—the rise of code intelligence.arXiv preprint arXiv:2401.14196, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Haolin Jin, Linghan Huang, Haipeng Cai, Jun Yan, Bo Li, and Huaming Chen. From LLMs to LLM-based agents for software engineering: A survey of current, challenges and future.arXiv preprint arXiv:2408.02479, 2025
-
[7]
README.LLM: A framework to help LLMs understand your library.arXiv preprint arXiv:2504.09798, 2025
Sandya Wijaya, Jacob Bolano, Alejandro Gomez Soteres, Shriyanshu Kode, Yue Huang, and Anant Sahai. README.LLM: A framework to help LLMs understand your library.arXiv preprint arXiv:2504.09798, 2025. 4
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.