CLIP-Guided SAM: Parameter-Efficient Semantic Conditioning for Promptable Segmentation
Pith reviewed 2026-06-30 12:23 UTC · model grok-4.3
The pith
CLIP-Guided SAM injects text, vision, and similarity features from CLIP into SAM's image encoder via lightweight adapters to add semantic conditioning while keeping the original promptable interface intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
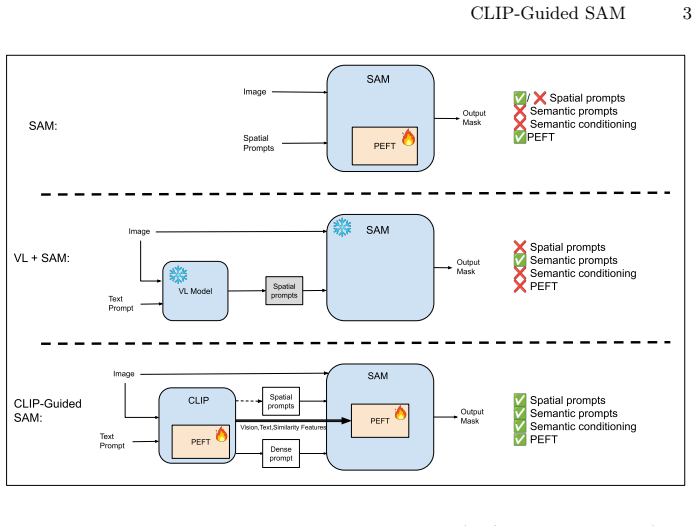
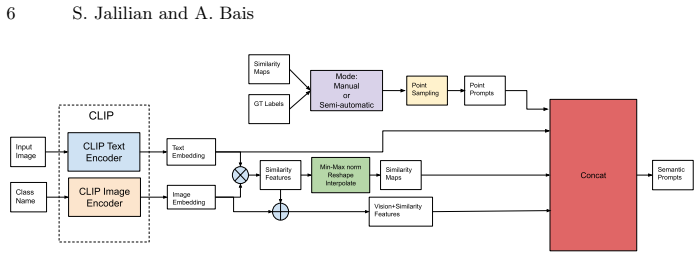
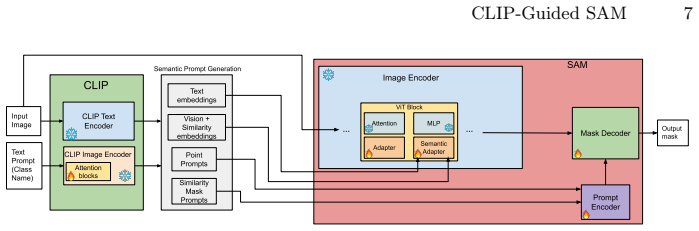
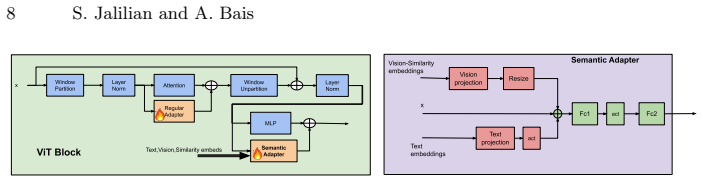
By injecting CLIP-derived text, vision, and similarity features directly into SAM's image encoder through lightweight multi-modal semantic adapters, the framework conditions internal feature representations so that semantic information influences mask prediction while preserving SAM's original promptable interface and supporting both manual and semi-automatic text-only modes.
What carries the argument
Lightweight multi-modal semantic adapters that inject CLIP-derived text, vision, and similarity features directly into SAM's image encoder to condition internal feature representations.
If this is right
- Supports interactive segmentation that combines text and spatial prompts in manual mode.
- Enables concept-specific segmentation from text input alone in semi-automatic mode.
- Remains parameter-efficient during both training and inference across general and specialized tasks.
- Requires consistent prompt types between training and inference to achieve reported robustness.
- Delivers superior or competitive mask quality against SAM+PEFT baselines and vision-language pipelines while using limited labeled data.
Where Pith is reading between the lines
- The internal-conditioning pattern could be tested on other promptable foundation models that currently rely on external vision-language stages.
- Prompt-type alignment during training may prove useful for any system that mixes textual and spatial inputs at inference time.
- The low-labeled-data efficiency suggests direct applicability in domains where annotation is costly, such as specialized imaging tasks.
- Replacing or augmenting the CLIP backbone with other vision-language encoders could be explored to vary the injected semantic signals.
Load-bearing premise
Directly injecting the CLIP features through the adapters will successfully improve semantic awareness without interfering with SAM's prompt-based mask generation or requiring extensive retraining.
What would settle it
On a general-domain benchmark such as COCO or a downstream task, CLIP-Guided SAM produces lower-quality masks or requires substantially more added parameters than a SAM model fine-tuned with standard PEFT methods that lack the semantic adapters.
Figures

read the original abstract
Promptable foundation models such as the Segment Anything Model (SAM) produce high-quality masks but remain semantically blind, relying on external prompts to specify categories. Existing vision-language approaches address this limitation by using external prompt coupling, where a vision-language model generates spatial prompts for SAM as a separate stage. We propose CLIP-Guided SAM, a parameter-efficient segmentation framework built on internal semantic conditioning. Instead of using semantic signals only to generate prompts, we inject CLIP-derived text, vision, and similarity features directly into SAM's image encoder through lightweight multi-modal semantic adapters. These adapters condition SAM's internal feature representations, allowing semantic information to influence mask prediction while preserving SAM's original promptable interface. Our framework is designed for low labeled-data settings and applies to both general-domain benchmarks and specialized downstream tasks. It supports two operating modes: Manual mode, for interactive segmentation with both text and spatial prompts, and Semi-Automatic text-only mode, for applications that require concept-specific segmentation using only textual input. We show that robustness depends on aligning training with the type of prompts used at inference, making train-test prompt consistency an important design principle. Through extensive experiments and ablations, we evaluate our method against SAM+PEFT baselines without semantic conditioning, vision-language + SAM pipelines, SAM 3, and strong semi-supervised segmentation methods that rely on large amounts of unlabeled data. Across these settings, CLIP-Guided SAM consistently achieves superior or competitive performance while remaining parameter-efficient in both training and deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CLIP-Guided SAM, a parameter-efficient framework that injects CLIP-derived text, vision, and similarity features directly into SAM's image encoder via lightweight multi-modal semantic adapters. This internal conditioning enables semantic awareness in promptable segmentation while preserving the original interface. The method supports manual (text+spatial) and semi-automatic (text-only) modes, emphasizes train-test prompt consistency as a design principle, and is evaluated on general benchmarks and specialized tasks against SAM+PEFT, VLM+SAM pipelines, SAM 3, and semi-supervised baselines, claiming superior or competitive results with efficiency in low-labeled-data regimes.
Significance. If the performance and efficiency claims hold under the reported conditions, the work provides a distinct internal-conditioning alternative to external prompt-coupling approaches, potentially improving semantic robustness in foundation models like SAM without full retraining. The explicit focus on prompt-consistency alignment and applicability to downstream tasks with limited labels adds practical value; the parameter-efficient design and dual-mode operation are clear strengths for deployment.
minor comments (3)
- [Abstract] Abstract: the phrase 'SAM 3' is ambiguous (likely a reference to a specific variant or baseline); clarify the exact model or citation in the main text and abstract.
- [§3] The description of adapter architecture and feature-injection points would benefit from an explicit equation or diagram reference early in §3 to make the multi-modal conditioning mechanism immediately reproducible from the text.
- [Experiments] Table captions or result sections should explicitly state the number of parameters updated during training for each compared method to strengthen the 'parameter-efficient' claim.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the method's strengths in internal semantic conditioning, prompt consistency, and efficiency, and the recommendation for minor revision. No major comments were listed in the report.
Circularity Check
No significant circularity; independent architectural proposal
full rationale
The provided abstract and description outline an independent architectural modification: lightweight multi-modal adapters that inject CLIP-derived features directly into SAM's image encoder to condition representations while preserving the original promptable interface. No equations, derivations, or self-referential definitions are supplied that would reduce any claimed result to fitted inputs or prior self-citations by construction. Performance claims rest on external experiments and ablations against baselines, with no indication that results are tautological or forced by the method's own definitions. The design is presented as a novel conditioning strategy rather than a renaming or self-citation-dependent uniqueness claim, making the derivation self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Aleem, S., Wang, F., Maniparambil, M., Arazo, E., Dietlmeier, J., Curran, K., Connor, N.E., Little, S.: Test-time adaptation with SALIP: A cascade of SAM and CLIP for zero-shot medical image segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5184–5193 (2024)
2024
-
[2]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala, K.V., Khedr, H., Huang, A., Lei, J., Ma, T., Guo, B., Kalla, A., Marks, M., Greer, J., Wang, M., Sun, P., Rädle, R., Afouras, T., Mavroudi, E., Xu, K., Wu, T.H., Zhou, Y., Momeni, L., Hazra, R., Ding, S., Vaze, S., Porcher, F., Li, F., Li, S., Kamath, A., Cheng, H.K., ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Cha, J., Mun, J., Roh, B.: Learning to generate text-grounded mask for open- world semantic segmentation from only image-text pairs. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11165– 11174 (2023)
2023
-
[4]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Chen, T., Zhu, L., Deng, C., Cao, R., Wang, Y., Zhang, S., Li, Z., Sun, L., Zang, Y., Mao, P.: Sam-adapter: Adapting segment anything in underperformed scenes. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3367–3375 (2023)
2023
-
[5]
arXiv preprint arXiv:2304.09148 (2023)
Chen, T., Zhu, L., Ding, C., Cao, R., Wang, Y., Li, Z., Sun, L., Mao, P., Zang, Y.: Sam fails to segment anything?–sam-adapter: Adapting sam in underper- formed scenes: Camouflage, shadow, medical image segmentation, and more. arXiv preprint arXiv:2304.09148 (2023)
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Cho,S.,Shin,H.,Hong,S.,Arnab,A.,Seo,P.H.,Kim,S.:Cat-seg:Costaggregation for open-vocabulary semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4113–4123 (2024)
2024
-
[7]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ding, J., Xue, N., Xia, G.S., Dai, D.: Decoupling zero-shot semantic segmenta- tion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11583–11592 (2022)
2022
-
[8]
Fan, D.P., Ji, G.P., Cheng, M.M., Shao, L.: Concealed object detection. IEEE Transactions on Pattern Analysis and Machine Intelligence44(10), 6024–6042 (Oct 2022).https://doi.org/10.1109/tpami.2021.3085766,http://dx.doi.org/10. 1109/TPAMI.2021.3085766
-
[9]
In: European conference on computer vision
Ghiasi,G.,Gu,X.,Cui,Y.,Lin,T.Y.:Scalingopen-vocabularyimagesegmentation with image-level labels. In: European conference on computer vision. pp. 540–557. Springer (2022)
2022
-
[10]
Open-vocabulary Object Detection via Vision and Language Knowledge Distillation
Gu, X., Lin, T.Y., Kuo, W., Cui, Y.: Open-vocabulary object detection via vision and language knowledge distillation. arXiv preprint arXiv:2104.13921 (2021) 16 S. Jalilian and A. Bais
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
In: International conference on machine learning
Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., De Laroussilhe, Q., Ges- mundo, A., Attariyan, M., Gelly, S.: Parameter-efficient transfer learning for nlp. In: International conference on machine learning. pp. 2790–2799. PMLR (2019)
2019
-
[12]
In: European Conference on Computer Vision
Hoyer, L., Tan, D.J., Naeem, M.F., Van Gool, L., Tombari, F.: Semivl: semi- supervised semantic segmentation with vision-language guidance. In: European Conference on Computer Vision. pp. 257–275. Springer (2024)
2024
-
[13]
ICLR1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. ICLR1(2), 3 (2022)
2022
-
[14]
IEEE Access14, 31732–31746 (2026).https:// doi.org/10.1109/ACCESS.2026.3668182
Jalilian, S., Bais, A.: Sam-ptx: Text-guided fine-tuning of sam with parameter- efficient, parallel-text adapters. IEEE Access14, 31732–31746 (2026).https:// doi.org/10.1109/ACCESS.2026.3668182
-
[15]
In: Proceedings of the IEEE/CVF international conference on computer vision
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4015–4026 (2023)
2023
-
[16]
Koleilat, T., Asgariandehkordi, H., Rivaz, H., Xiao, Y.: Medclip-samv2: Towards universal text-driven medical image segmentation. arxiv 2024. arXiv preprint arXiv:2409.19483 (2024)
-
[17]
arXiv preprint arXiv:2407.15728 (2024)
Kollias, D., Arsenos, A., Wingate, J., Kollias, S.: Sam2clip2sam: Vision language model for segmentation of 3d ct scans for covid-19 detection. arXiv preprint arXiv:2407.15728 (2024)
-
[18]
Computer vision and image understanding 184, 45–56 (2019)
Le, T.N., Nguyen, T.V., Nie, Z., Tran, M.T., Sugimoto, A.: Anabranch network for camouflaged object segmentation. Computer vision and image understanding 184, 45–56 (2019)
2019
-
[19]
The Power of Scale for Parameter-Efficient Prompt Tuning
Lester, B., Al-Rfou, R., Constant, N.: The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[20]
Language-driven Semantic Segmentation
Li, B., Weinberger, K.Q., Belongie, S., Koltun, V., Ranftl, R.: Language-driven semantic segmentation. arXiv preprint arXiv:2201.03546 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Neurocomputing618, 129122 (2025)
Li, S., Cao, J., Ye, P., Ding, Y., Tu, C., Chen, T.: ClipSAM: CLIP and SAM collaboration for zero-shot anomaly segmentation. Neurocomputing618, 129122 (2025)
2025
-
[22]
Pattern Recognition162, 111409 (2025)
Li, Y., Wang, H., Duan, Y., Zhang, J., Li, X.: A closer look at the explainability of contrastive language-image pre-training. Pattern Recognition162, 111409 (2025)
2025
-
[23]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Liang, F., Wu, B., Dai, X., Li, K., Zhao, Y., Zhang, H., Zhang, P., Vajda, P., Mar- culescu, D.: Open-vocabulary semantic segmentation with mask-adapted clip. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 7061–7070 (2023)
2023
-
[24]
arXiv preprint arXiv:2503.22237 (2025)
Liu, K., Wang, J., Jin, R., Hwang, W., Chung, T.S.: Schnet: Sam marries clip for human parsing. arXiv preprint arXiv:2503.22237 (2025)
-
[25]
In: European conference on computer vision
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., et al.: Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In: European conference on computer vision. pp. 38–55. Springer (2024)
2024
-
[26]
In: International Conference on Machine Learning
Luo, H., Bao, J., Wu, Y., He, X., Li, T.: Segclip: Patch aggregation with learnable centers for open-vocabulary semantic segmentation. In: International Conference on Machine Learning. pp. 23033–23044. PMLR (2023)
2023
-
[27]
In: 2025 IEEE 22nd International Symposium on Biomedical Imaging (ISBI)
Ma, X., Fu, J., Liao, W., Zhang, S., Wang, G.: Clisc: Bridging clip and sam by enhanced cam for unsupervised brain tumor segmentation. In: 2025 IEEE 22nd International Symposium on Biomedical Imaging (ISBI). pp. 1–5. IEEE (2025)
2025
-
[28]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from CLIP-Guided SAM 17 natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[29]
Ren, T., Liu, S., Zeng, A., Lin, J., Li, K., Cao, H., Chen, J., Huang, X., Chen, Y., Yan, F., Zeng, Z., Zhang, H., Li, F., Yang, J., Li, H., Jiang, Q., Zhang, L.: Grounded sam: Assembling open-world models for diverse visual tasks (2024)
2024
-
[30]
Advances in Neural Information Processing Systems35, 33754–33767 (2022)
Shin,G.,Xie,W.,Albanie,S.:Reco:Retrieveandco-segmentforzero-shottransfer. Advances in Neural Information Processing Systems35, 33754–33767 (2022)
2022
-
[31]
Skurowski, P., Abdulameer, H., Błaszczyk, J., Depta, T., Kornacki, A., Kozieł, P.: Animal camouflage analysis: Chameleon database2(6), 7
-
[32]
arXiv preprint arXiv:2401.17803 (2024)
Song, Y., Zhou, Q., Lu, X., Shao, Z., Ma, L.: Su-sam: A simple unified framework for adapting segment anything model in underperformed scenes. arXiv preprint arXiv:2401.17803 (2024)
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, H., Vasu, P.K.A., Faghri, F., Vemulapalli, R., Farajtabar, M., Mehta, S., Rastegari, M., Tuzel, O., Pouransari, H.: Sam-clip: Merging vision foundation mod- els towards semantic and spatial understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3635–3647 (2024)
2024
-
[34]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xu, J., De Mello, S., Liu, S., Byeon, W., Breuel, T., Kautz, J., Wang, X.: Groupvit: Semantic segmentation emerges from text supervision. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18134– 18144 (2022)
2022
-
[35]
In: European Conference on Computer Vision
Xu, M., Zhang, Z., Wei, F., Lin, Y., Cao, Y., Hu, H., Bai, X.: A simple baseline for open-vocabulary semantic segmentation with pre-trained vision-language model. In: European Conference on Computer Vision. pp. 736–753. Springer (2022)
2022
-
[36]
Yang,L.,Qi,L.,Feng,L.,Zhang,W.,Shi,Y.:Revisitingweak-to-strongconsistency in semi-supervised semantic segmentation (2023),https://arxiv.org/abs/2208. 09910
2023
-
[37]
IEEE Transactions on Pattern Analysis and Machine In- telligence (2025)
Yang, L., Zhao, Z., Zhao, H.: Unimatch v2: Pushing the limit of semi-supervised semantic segmentation. IEEE Transactions on Pattern Analysis and Machine In- telligence (2025)
2025
-
[38]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Yang, X., Gong, X.: Foundation model assisted weakly supervised semantic seg- mentation. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 523–532 (2024)
2024
-
[39]
In: 2024 IEEE International Conference on Bioinformatics and Biomedicine (BIBM)
Yu, X., Elazab, A., Ge, R., Jin, H., Jiang, X., Jia, G., Wu, Q., Shi, Q., Wang, C.: Ich-scnet: Intracerebral hemorrhage segmentation and prognosis classification network using clip-guided sam mechanism. In: 2024 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). pp. 2795–2800. IEEE (2024)
2024
-
[40]
In: 2024 IEEE International Conference on Multimedia and Expo (ICME)
Yu, Y., Xu, C., Wang, K.: Ts-sam: Fine-tuning segment-anything model for down- stream tasks. In: 2024 IEEE International Conference on Multimedia and Expo (ICME). pp. 1–6. IEEE (2024)
2024
-
[41]
In: European Conference on Computer Vision
Yuan, H., Li, X., Zhou, C., Li, Y., Chen, K., Loy, C.C.: Open-vocabulary sam: Seg- ment and recognize twenty-thousand classes interactively. In: European Conference on Computer Vision. pp. 419–437. Springer (2024)
2024
- [42]
-
[43]
In: European conference on computer vision
Zhou, C., Loy, C.C., Dai, B.: Extract free dense labels from clip. In: European conference on computer vision. pp. 696–712. Springer (2022)
2022
-
[44]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhou, Z., Lei, Y., Zhang, B., Liu, L., Liu, Y.: Zegclip: Towards adapting clip for zero-shot semantic segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11175–11185 (2023) 18 S. Jalilian and A. Bais
2023
-
[45]
arXiv preprint arXiv:2010.09713 (2020)
Zou, Y., Zhang, Z., Zhang, H., Li, C.L., Bian, X., Huang, J.B., Pfister, T.: Pseudoseg: Designing pseudo labels for semantic segmentation. arXiv preprint arXiv:2010.09713 (2020)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.