AOEPT: Breaking the Implicit Modality-Reduction Bottleneck in Modality-Missing Prompt Tuning
Pith reviewed 2026-06-30 12:19 UTC · model grok-4.3
The pith
Modal-Contextualized Prompts restore multimodal transformers' reasoning scope by distilling global modality-wise priors to augment missing-modality information during prompt tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
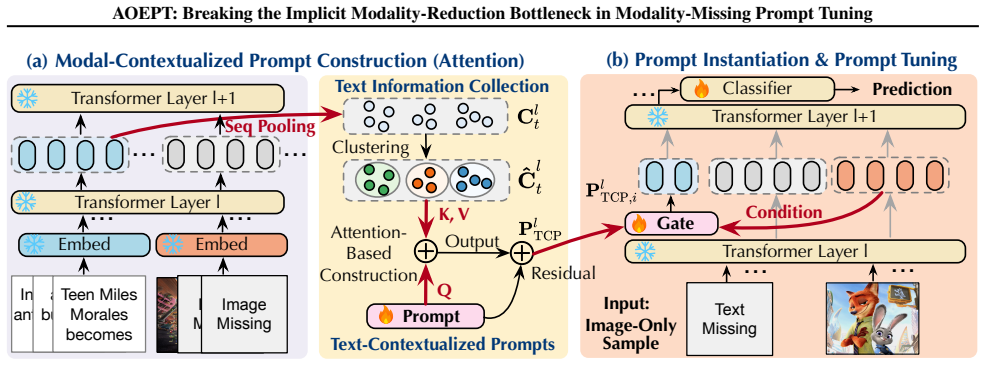
AOEPT pioneers a modal-contextualized prompting approach by introducing Modal-Contextualized Prompts (MCPs) that distill global modality-wise priors from training data, serving as latent repositories of the information sources for missing modalities. Conditioned on the remaining modalities, these MCPs are instantiated into instance-aware prompts that selectively augment missing-modality information for each sample, thereby restoring the reasoning scope of MTs beyond the observed-modality-only subspace.
What carries the argument
Modal-Contextualized Prompts (MCPs) that distill global modality-wise priors from training data and instantiate them into instance-aware prompts conditioned on observed modalities.
If this is right
- Multimodal transformers regain access to full reasoning scope in modality-missing scenarios without restricting to observed modalities.
- The method applies across various multimodal benchmarks and backbones with minimal added computation.
- Instance-aware prompts selectively augment information sources for missing modalities on a per-sample basis.
- Prompts are generated without any access to the missing modality during inference.
Where Pith is reading between the lines
- The same prior-distillation mechanism could be tested on sequential data where modalities drop out over time rather than being absent from the start.
- Extending the approach to cases with multiple simultaneously missing modalities would reveal whether the global priors remain sufficient or require additional structure.
- The technique might transfer to other conditioning-based methods that currently limit model scope to available inputs.
- If the priors prove robust, this could reduce reliance on data imputation techniques that introduce their own artifacts.
Load-bearing premise
Global modality-wise priors distilled from training data can serve as effective latent repositories for missing modalities and can be selectively instantiated without introducing misleading signals or requiring access to the missing modality at inference time.
What would settle it
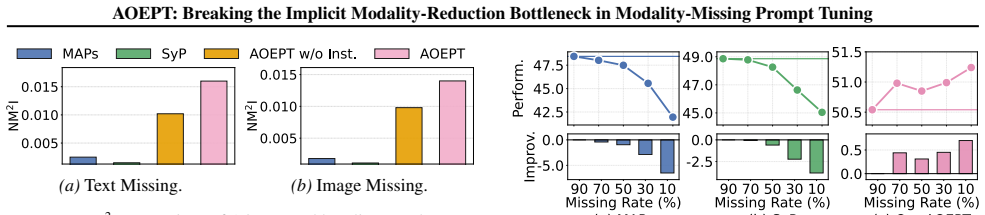
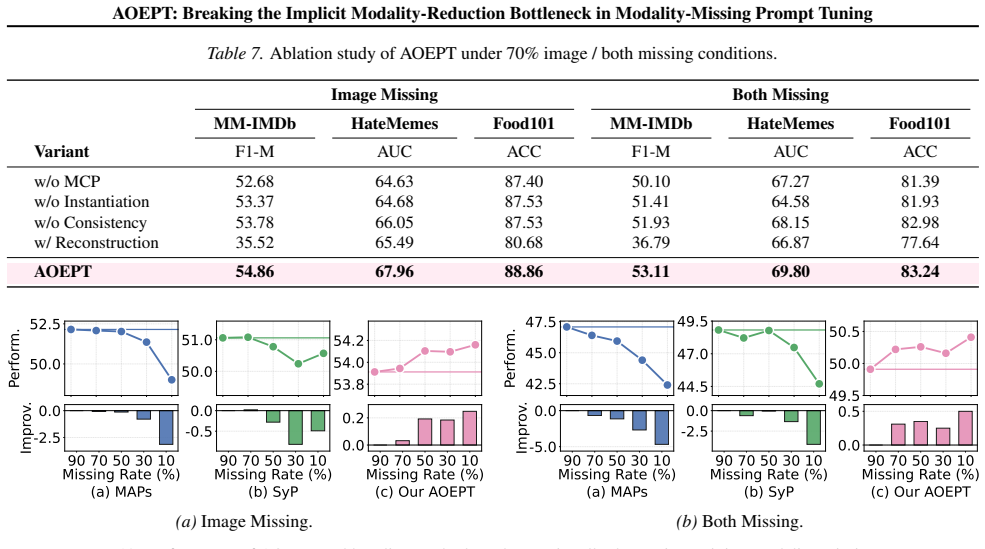
Performance on modality-missing test sets would remain unchanged if the distilled priors were replaced by random vectors or if the MCP instantiation step were removed entirely.
Figures


read the original abstract
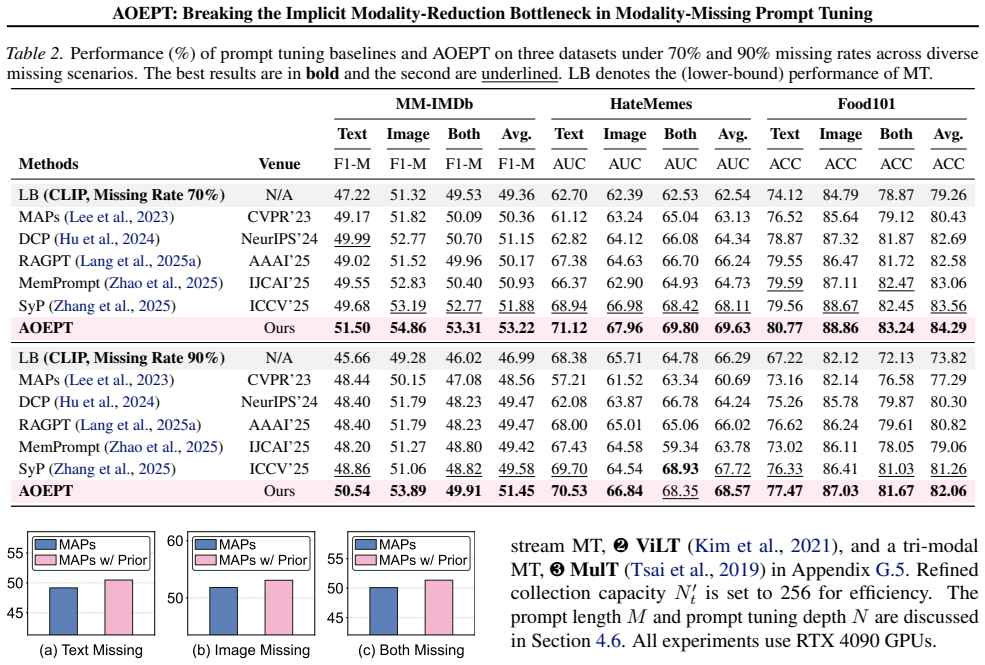
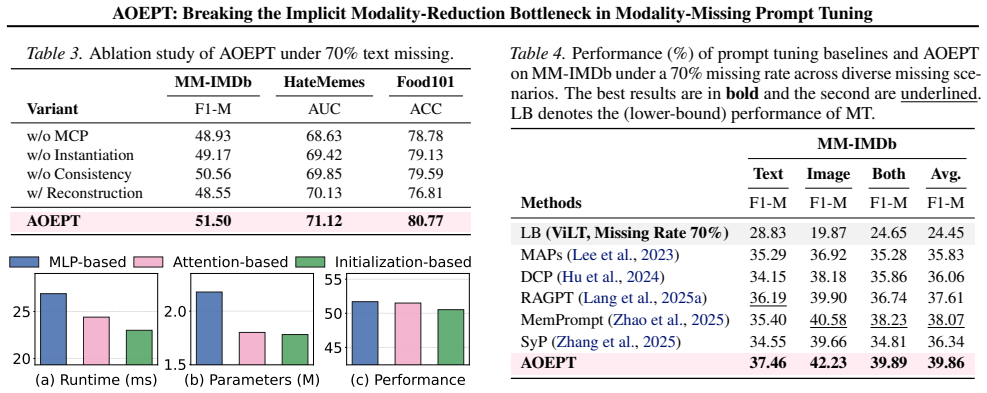
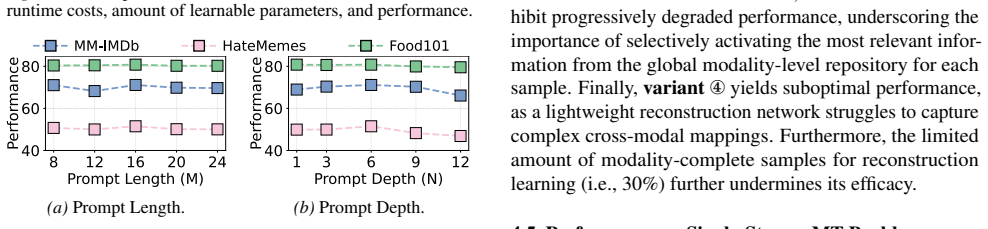
Deploying multimodal systems in real-world environments often entails handling modality-missing scenarios, where one or more modalities are unavailable. While recent studies address this challenge for the general Multimodal Transformer (MT) architecture via prompt tuning, we identify a fundamental limitation in these methods: the Implicit Modality-Reduction bottleneck. By conditioning prompts solely on the observed modalities, they inadvertently restrict the reasoning scope of MTs to the modality-reduced subspace, cutting off access to the latent information sources of the missing modalities. To overcome this limitation, we propose AOEPT, which pioneers a novel modal-contextualized prompting fashion. Specifically, we introduce lightweight Modal-Contextualized Prompts (MCPs) that distill global modality-wise priors from training data, serving as latent repositories of the information sources for missing modalities. Conditioned on the remaining modalities, these MCPs are instantiated into instance-aware prompts that selectively augment missing-modality information for each sample, thereby restoring the reasoning scope of MTs beyond the observed-modality-only subspace. Experiments across various multimodal benchmarks and backbones confirm the strong performance of AOEPT, with minimal computational overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies an Implicit Modality-Reduction bottleneck in existing prompt-tuning approaches for modality-missing scenarios in multimodal transformers, where conditioning solely on observed modalities restricts reasoning to the observed-modality subspace. It proposes AOEPT, which introduces lightweight Modal-Contextualized Prompts (MCPs) distilled from complete training data to act as latent repositories of missing-modality information sources; these are then instantiated into instance-aware prompts conditioned only on observed modalities at inference time. The method is claimed to restore the full reasoning scope of the transformer, with experiments across multimodal benchmarks and backbones showing strong performance and minimal overhead.
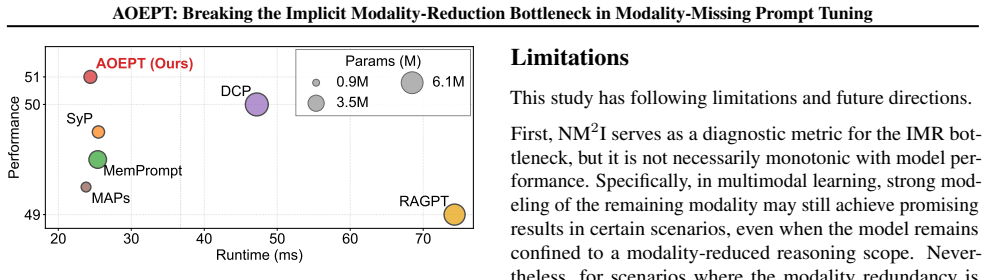
Significance. If the empirical results hold, the work addresses a practically relevant limitation in deploying multimodal models under incomplete inputs. The core idea of distilling global modality-wise priors into MCPs that can be selectively instantiated without access to missing data at test time is a coherent technical contribution that expands the effective input space beyond observed modalities.
minor comments (3)
- The abstract states that MCPs 'distill global modality-wise priors from training data' but does not specify the exact distillation objective or loss used; adding a short description or reference to the relevant section/equation would improve reproducibility.
- The phrase 'pioneers a novel modal-contextualized prompting fashion' is informal; consider replacing with a more precise statement of the technical novelty.
- Figure or algorithm pseudocode illustrating the conditioning and instantiation steps of MCPs would help readers follow the selective augmentation mechanism described in the abstract.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work on the Implicit Modality-Reduction bottleneck and the recommendation for minor revision. The recognition that our Modal-Contextualized Prompts (MCPs) provide a coherent way to expand reasoning scope beyond observed modalities is appreciated.
Circularity Check
No significant circularity detected
full rationale
The manuscript describes a prompting method (MCPs distilled from training data and conditioned on observed modalities) without any equations, derivations, or first-principles claims. No step reduces a result to its inputs by construction, no fitted parameters are relabeled as predictions, and no load-bearing self-citations or uniqueness theorems appear in the provided text. The construction is internally consistent with the stated goal of expanding reasoning scope and does not rely on hidden access to missing modalities. This is the common case of a self-contained empirical method paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Arevalo, J., Solorio, T., Montes-y G´omez, M., and Gonz´alez, F. A. Gated multimodal units for information fusion. arXiv preprint arXiv:1702.01992,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Bai, S., Cai, Y ., Chen, R., Chen, K., Chen, X.-H., and Cheng, Zesen, e. a. Qwen3-VL Technical Report.arXiv.org, abs/2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Retrieval- Augmented Dynamic Prompt Tuning for Incomplete Mul- timodal Learning
Lang, J., Cheng, Z., Zhong, T., and Zhou, F. Retrieval- Augmented Dynamic Prompt Tuning for Incomplete Mul- timodal Learning. InAAAI Conference on Artificial Intel- ligence, volume abs/2501.01120, 2025a. Lang, J., Hong, R., Cheng, Z., Zhong, T., Wang, Y ., and Zhou, F. Redeeming modality information loss: Retrieval- guided conditional generation for sever...
-
[4]
Multi-modal learning with missing modality via shared-specific feature modelling
Wang, H., Chen, Y ., Ma, C., Avery, J., Hull, L., and Carneiro, G. Multi-modal learning with missing modality via shared-specific feature modelling. InIEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), pp. 15878–15887, 2023a. Wang, S., Li, Y ., and Wei, H. Understanding and Mitigating Miscalibration in Prompt Tuning for Vision-Langua...
-
[5]
Deep Multimodal Learning with Missing Modality: A Survey
Wu, R., Wang, H., Chen, H.-T., and Carneiro, G. Deep multimodal learning with missing modality: A survey. arXiv preprint arXiv:2409.07825,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Zhang, Y ., Fei, H., Li, D., Yu, T., and Li, P. Prompting through prototype: A prototype-based prompt learning on pretrained vision-language models.arXiv preprint arXiv:2210.10841,
-
[7]
Implementation of AOEPT on Dual-Stream Multimodal Transformer In the main paper, we present the mathematical formulation of AOEPT on the single-stream MT for clarity
12 AOEPT: Breaking the Implicit Modality-Reduction Bottleneck in Modality-Missing Prompt Tuning A. Implementation of AOEPT on Dual-Stream Multimodal Transformer In the main paper, we present the mathematical formulation of AOEPT on the single-stream MT for clarity. Nevertheless, extending AOEPT to dual-stream MTs is straightforward, as it follows the same...
2024
-
[8]
benign confounders
to showcase its effectiveness in extending to multiple modalities. Below, we present the dataset descriptions. ▷MM-IMDbis a multimodal dataset designed for movie genre classification. It comprises two distinct modalities: visual (movie poster images) and textual (plot summaries). This dataset is primarily used for a multi-label classification, as each mov...
2023
-
[9]
Moreover, we also adopt a tri-modal MT backbone ❸ MulT(Tsai et al.,
and a single-stream MT ❷ ViLT(Kim et al., 2021). Moreover, we also adopt a tri-modal MT backbone ❸ MulT(Tsai et al.,
2021
-
[10]
Below, we provide a detailed implementation the backbones: ▷ CLIP:For CLIP, we adopt the pretrained ViT-B/16 variant following prior studies (Hu et al., 2024)
to showcase the effectiveness of AOEPT in extending to multiple modalities. Below, we provide a detailed implementation the backbones: ▷ CLIP:For CLIP, we adopt the pretrained ViT-B/16 variant following prior studies (Hu et al., 2024). During training, the complete CLIP model remains frozen while the modality-specific projection layer and final layer-norm...
2024
-
[11]
(i.e., the one that we evaluate the modality-missing performance), 17 AOEPT: Breaking the Implicit Modality-Reduction Bottleneck in Modality-Missing Prompt Tuning Table 5.Performance of AOEPT using different down-sampling strategies on three datasets under a 70% missing rate. MM-IMDb HateMemes Food101 Text Image Both Text Image Both Text Image Both Method...
-
[12]
Following prior studies (Hu et al., 2024), we insert all type of MCPs into each sample
with a learning rate of 1×10 −2 and a weight decay of 2×10 −2 for 20 epochs. Following prior studies (Hu et al., 2024), we insert all type of MCPs into each sample. For the missing modalities, we follow prior studies (Lee et al., 2023). Specifically, we set the input text to an empty string for text-missing samples and set all pixel values to ones for ima...
2024
-
[13]
As illustrated in Table 8, AOEPT outperforms all baselines across all missing settings
54.16 53.64 59.81 57.89 57.89 55.35 50.85 50.45 46.27 42.32 55.86 52.44 AOEPT 55.12 54.57 61.73 59.60 58.64 56.81 56.18 55.69 48.08 44.66 59.70 55.63 (e.g., Audio–Video indicates that only the text modality is available), while the remaining samples are complete. As illustrated in Table 8, AOEPT outperforms all baselines across all missing settings. H. Re...
2021
-
[14]
learned a single base prompt and employs a lightweight surrogate feature generator to produce diverse prompted text features from it, bypassing the issue of enormous gradient computation inside the text encoder. With the success of prompt learning in adapting vision–language models to downstream tasks, recent studies (Lee et al., 2023; Hu et al., 2024; Zh...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.