Distributional Conformal Prediction for Markov Processes
Pith reviewed 2026-06-29 23:59 UTC · model grok-4.3
The pith
Markov Distributional Conformal Prediction turns stationary Markov sequences into i.i.d. data for valid conformal intervals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The MDCP method extends distributional conformal prediction to strictly stationary Markov processes by exploiting the probability integral transform based on estimated transition distribution functions to transform the Markov data to an i.i.d. dataset. This yields a non-asymptotic error bound on the unconditional coverage rate under beta-mixing and standard kernel assumptions, asymptotic validity of the conditional prediction interval, and retention of that asymptotic validity when the process is only L^p-m-approximable.
What carries the argument
The probability integral transform applied to kernel-estimated transition distribution functions, which maps the Markov observations to approximately independent uniforms for conformal calibration.
If this is right
- A non-asymptotic error bound holds for the unconditional coverage rate under beta-mixing and standard assumptions on the kernel estimators.
- The conditional prediction interval is asymptotically valid.
- The conditional prediction interval remains asymptotically valid when the Markov process satisfies L^p-m-approximability rather than beta-mixing.
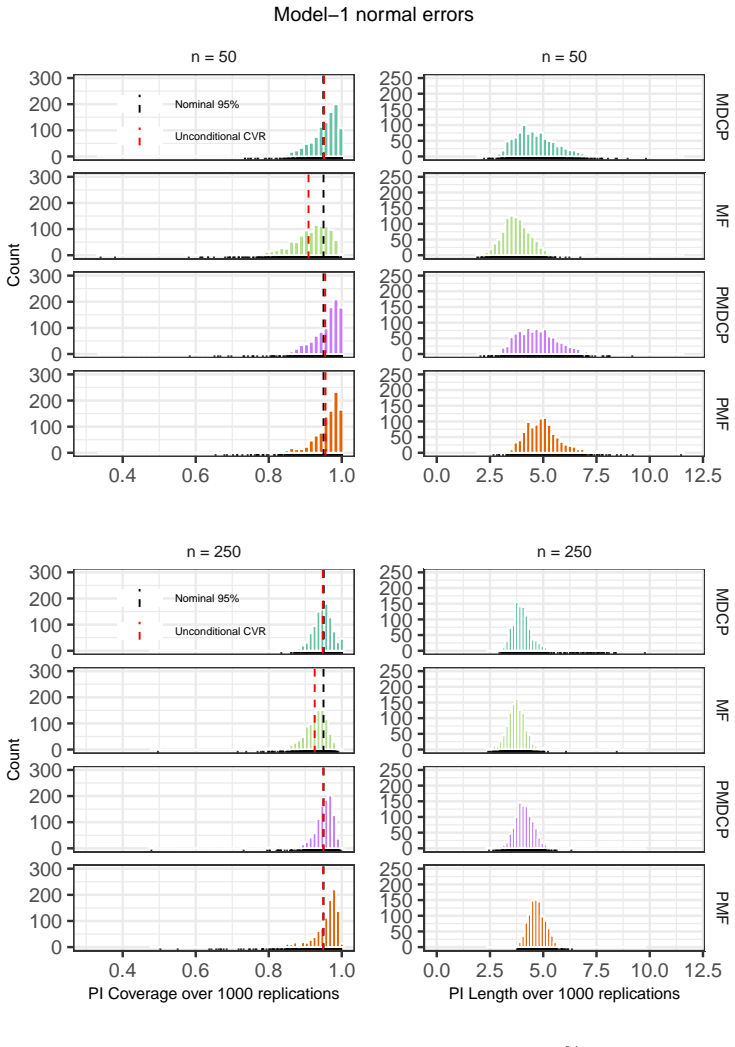
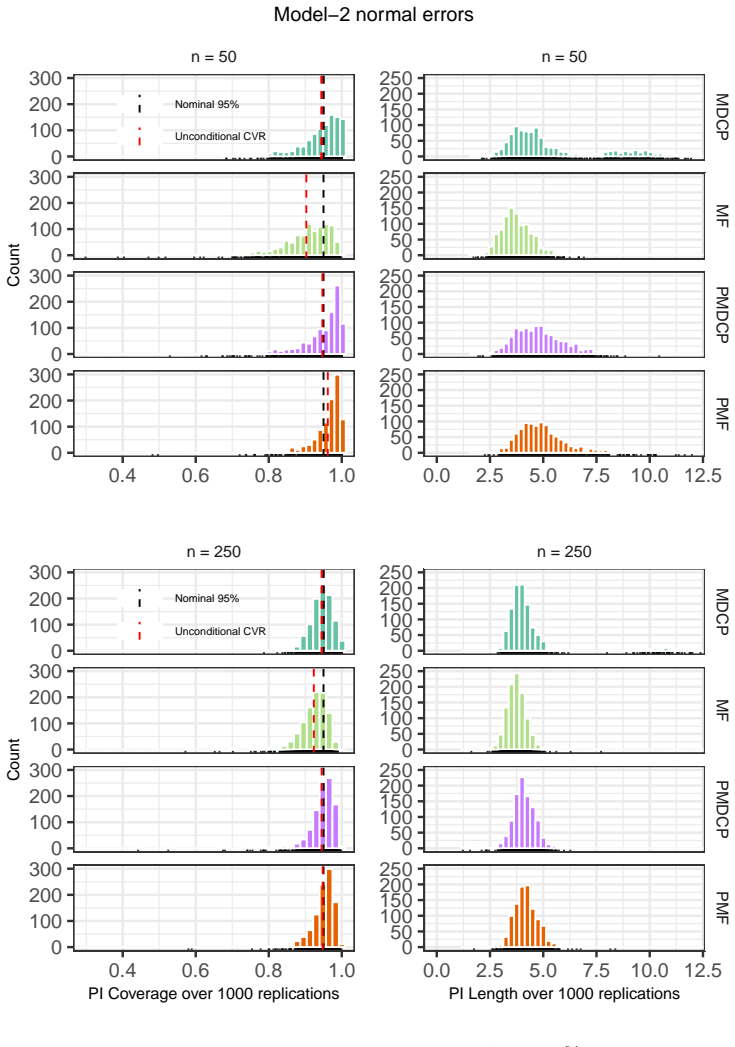
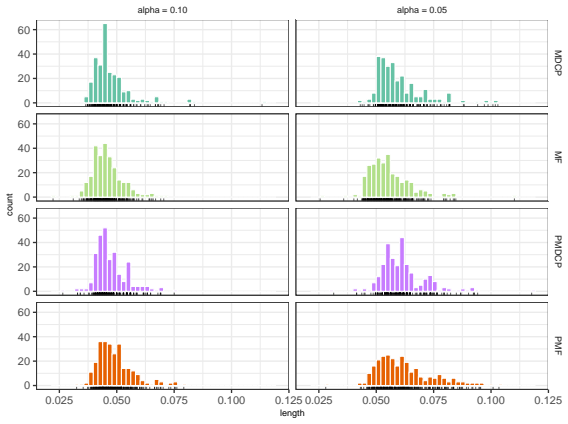
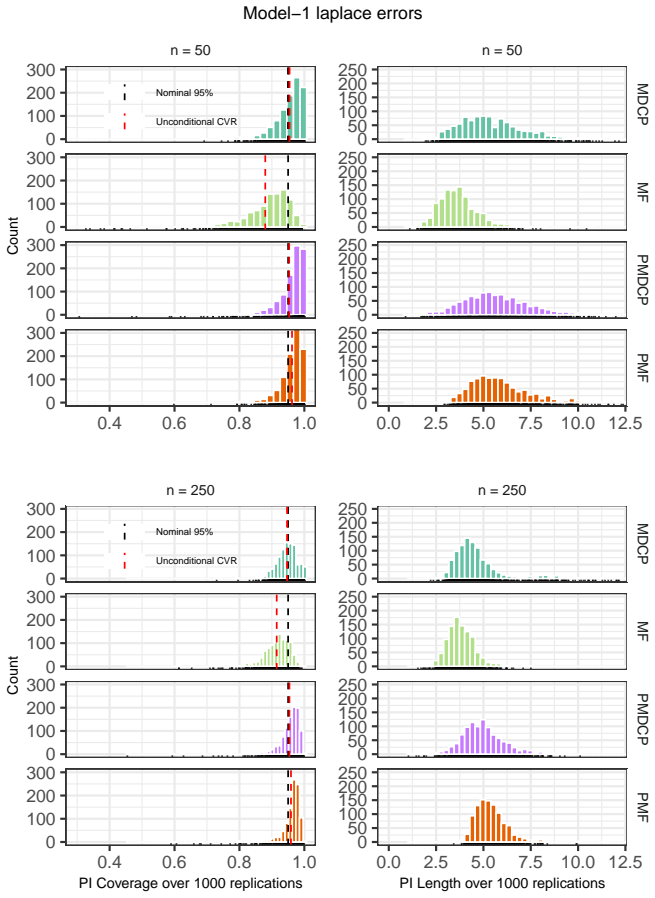
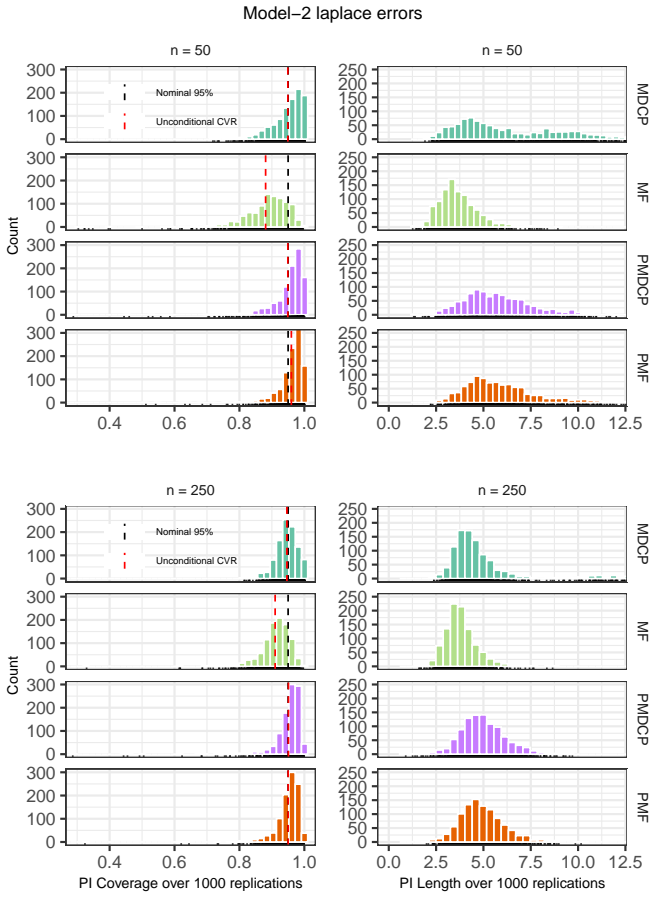
- Numerical experiments compare MDCP performance to the model-free bootstrap prediction method on simulated and real data.
Where Pith is reading between the lines
- The transform-based approach could be tested on non-stationary or higher-order Markovian time series by relaxing the strict stationarity assumption.
- MDCP intervals might be compared directly to other dependence-robust conformal methods on the same Markov data sets to quantify efficiency gains.
- The method suggests a general template for applying conformal inference to other weakly dependent processes by first mapping them toward i.i.d. structure.
Load-bearing premise
The process must be strictly stationary and Markovian with beta-mixing or L^p-m-approximability strong enough that the transformed variables are close enough to i.i.d. for the conformal coverage guarantees to transfer.
What would settle it
Repeated Monte Carlo trials on a beta-mixing Markov chain where the empirical coverage of the MDCP intervals falls materially below the nominal level, for example below 0.90 for a nominal 0.95 interval, would refute the coverage claims.
Figures
read the original abstract
We introduce the Markov Distributional Conformal Prediction (MDCP) method that extends the distributional conformal prediction (previously developed for regression) to the setting of a strictly stationary Markov process. Instead of relying on a specific model structure to do prediction, the idea of distributional conformal prediction interval aligns with the Model-Free (MF) Prediction Principle. In analogy to MF prediction of Markov processes, our method exploits the probability integral transform based on estimated transition distribution functions to transform the Markov data to an i.i.d.~dataset. We show a non-asymptotic error bound of MDCPs unconditional coverage rate under a $\beta$-mixing condition and other standard assumptions on the kernel estimators. The asymptotic validity of the conditional prediction interval is also verified. In addition, we show that our conditional prediction interval is still asymptotically valid with Markov processes being $L^p$-$m$-approximable instead of satisfying the mixing property. Numerical simulations and real data experiments are deployed to empirically illustrate the finite-sample performance of MDCP, and compare it with the MF bootstrap prediction method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Markov Distributional Conformal Prediction (MDCP) extending distributional conformal prediction to strictly stationary Markov processes. It applies kernel estimation of transition distributions followed by the probability integral transform to produce approximately i.i.d. data, then constructs conformal prediction intervals. The central claims are a non-asymptotic error bound on unconditional coverage under a β-mixing condition plus standard kernel assumptions, asymptotic validity of the conditional intervals, and retention of asymptotic validity when the process is L^p-m-approximable rather than β-mixing. Finite-sample performance is illustrated via simulations and real-data experiments, with comparisons to the model-free bootstrap.
Significance. If the non-asymptotic coverage bound can be rigorously established, the method would supply a model-free route to valid prediction intervals for dependent Markov data, extending conformal techniques beyond the i.i.d. setting while preserving the distribution-free flavor of the original distributional conformal prediction framework. The additional L^p-m-approximability result broadens applicability, and the empirical comparisons provide concrete evidence of practical utility.
major comments (2)
- [Abstract] Abstract and the non-asymptotic coverage claim: the stated error bound on unconditional coverage rests on the PIT of the globally estimated transition distribution producing data sufficiently close to i.i.d. for standard conformal arguments to apply with controllable error. Because the kernel estimator is computed once from the entire sample, every transformed observation shares the same random estimation error; this common component induces an extra layer of dependence across conformity scores that is not obviously controlled by β-mixing alone. An explicit accounting for this shared estimation noise (e.g., via a uniform convergence rate that is then propagated into the coverage deviation) is required to support the non-asymptotic guarantee.
- [Theoretical results section] The derivation of the non-asymptotic bound (presumably the main theoretical section following the method definition): the argument must verify that the coverage deviation induced by the fixed (but random) kernel estimator remains of the same order as the usual conformal error term; without an explicit bound on the supremum deviation of the estimated transition function that is uniform over the sample and then folded into the conformal quantile, the claim that β-mixing plus “standard assumptions on the kernel estimators” suffices cannot be confirmed.
minor comments (3)
- Clarify the precise bandwidth and kernel conditions required for the uniform convergence rates invoked in the non-asymptotic argument; these should be stated explicitly rather than left as “standard assumptions.”
- [Numerical experiments] In the simulation section, report the exact sample sizes, mixing coefficients, and bandwidth choices used so that the finite-sample coverage results can be reproduced and compared directly to the theoretical rates.
- The construction of the conditional prediction interval (as opposed to the unconditional one) should be spelled out with an explicit algorithm or pseudocode, including how the estimated conditional distribution is inverted after the conformal step.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive report. The comments correctly identify the need for greater transparency in how the shared estimation error from the global kernel estimator is controlled in the non-asymptotic coverage argument. We address both points below and will revise the manuscript to make the relevant steps explicit.
read point-by-point responses
-
Referee: [Abstract] Abstract and the non-asymptotic coverage claim: the stated error bound on unconditional coverage rests on the PIT of the globally estimated transition distribution producing data sufficiently close to i.i.d. for standard conformal arguments to apply with controllable error. Because the kernel estimator is computed once from the entire sample, every transformed observation shares the same random estimation error; this common component induces an extra layer of dependence across conformity scores that is not obviously controlled by β-mixing alone. An explicit accounting for this shared estimation noise (e.g., via a uniform convergence rate that is then propagated into the coverage deviation) is required to support the non-asymptotic guarantee.
Authors: We agree that the common estimation error must be handled explicitly. The proof of the non-asymptotic bound (Theorem 3.1) uses the uniform convergence rate of the kernel estimator under the stated β-mixing and kernel assumptions to bound the supremum deviation uniformly over the sample. This deviation is then propagated through the probability integral transform and into the conformity scores, showing that its contribution to the coverage error is of strictly smaller order than the usual conformal term. We will revise the abstract and add a short clarifying paragraph immediately after the statement of the theorem to highlight this propagation step. revision: yes
-
Referee: [Theoretical results section] The derivation of the non-asymptotic bound (presumably the main theoretical section following the method definition): the argument must verify that the coverage deviation induced by the fixed (but random) kernel estimator remains of the same order as the usual conformal error term; without an explicit bound on the supremum deviation of the estimated transition function that is uniform over the sample and then folded into the conformal quantile, the claim that β-mixing plus “standard assumptions on the kernel estimators” suffices cannot be confirmed.
Authors: The derivation already contains the required uniform bound on the supremum deviation of the estimated transition distribution (derived from standard results on kernel estimation under β-mixing) and folds this bound into the analysis of the conformal quantile. Nevertheless, the presentation is somewhat compressed. We will expand the relevant subsection to isolate the uniform deviation lemma, state the order explicitly, and show how it enters the final coverage deviation inequality, thereby confirming that the total error remains controlled under the stated assumptions. revision: yes
Circularity Check
No circularity: bounds rest on external mixing/kernel assumptions
full rationale
The paper claims a non-asymptotic error bound on unconditional coverage under β-mixing and standard kernel estimator assumptions, plus asymptotic validity under L^p-m-approximability. These are presented as external conditions that make the PIT-transformed data sufficiently close to i.i.d. for conformal arguments to apply. No equation or claim in the abstract reduces the coverage guarantee to a quantity fitted from the same data or to a self-citation chain; the derivation is therefore self-contained against the stated external benchmarks rather than tautological.
Axiom & Free-Parameter Ledger
free parameters (1)
- kernel smoothing parameter
axioms (3)
- domain assumption The process is strictly stationary and Markovian
- domain assumption β-mixing condition (or L^p-m-approximability)
- domain assumption Standard regularity conditions on the kernel estimators
Reference graph
Works this paper leans on
-
[1]
Andrews, D. W. (1984). Non-strong mixing autoregressive processes.Journal of Applied Probability, 21(4), 930–934. Angelopoulos, A. N., Barber, R. F., & Bates, S. (2024). Theoretical foundations of conformal prediction.arXiv preprint arXiv:2411.11824. Azzalini, A. (1981). A note on the estimation of a distribution function and quantiles by a kernel method....
work page internal anchor Pith review Pith/arXiv arXiv 1984
-
[2]
Springer Science & Business Media. Box, G. E., Jenkins, G. M., Reinsel, G. C., & Ljung, G. M. (2015).Time Series Analysis: Forecasting and Control. John Wiley & Sons. Bradley, R. C. (2005). Basic properties of strong mixing conditions. a survey and some open questions.Probability Surveys, 2(none), 107 –
2015
-
[3]
Trimmed Conformal Prediction for High-Dimensional Models
Chen, B. & Hong, Y. (2012). Testing for the markov property in timeseries.Econometric Theory, 28(1), 130–178. Chen, J. & Politis, D. N. (2019). Optimal Multi-step-ahead Prediction of ARCH/GARCH Models and NoVaS Transformation.Econometrics, 7(3), 1–23. Chen, R., Yang, L., & Hafner, C. (2004). Nonparametric multistep-ahead prediction in time series analysis...
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[4]
Lehmann, E
Springer. Lehmann, E. L. & Romano, J. P. (2005).Testing statistical hypotheses. Springer. 31 Lei, J., G’Sell, M., Rinaldo, A., Tibshirani, R. J., & Wasserman, L. (2018). Distribution- free predictive inference for regression.Journal of the American Statistical Association, 113(523), 1094–1111. Lei, J., Robins, J., & Wasserman, L. (2013). Distribution-free...
2005
-
[5]
P¨ otscher, B. M. & Prucha, I. (1997).Dynamic nonlinear econometric models: Asymptotic theory. Springer Science & Business Media. Romano, Y., Patterson, E., & Candes, E. (2019). Conformalized quantile regression.Ad- vances in neural information processing systems,
1997
-
[6]
Rosenblatt, M. (1952). Remarks on a multivariate transformation.The annals of mathe- matical statistics, 23(3), 470–472. Sesia, M. & Romano, Y. (2021). Conformal prediction using conditional histograms.Ad- vances in neural information processing systems, 34, 6304–6315. Shafer, G. & Vovk, V. (2008). A tutorial on conformal prediction.Journal of Machine Lea...
1952
-
[7]
Wu, K. & Politis, D. N. (2024b). Deep limit model-free prediction in regression.arXiv preprint arXiv:2408.09532. Xu, C. & Xie, Y. (2023). Conformal prediction for time series.IEEE transactions on pattern analysis and machine intelligence, 45(10), 11575–11587. Zaffran, M., F´ eron, O., Goude, Y., Josse, J., & Dieuleveut, A. (2022). Adaptive conformal predi...
-
[8]
Plugging the upper bound back (8), we have |P(Yn+1 ∈ bCMDCP 1−α (Xn))−(1−α)| ≤24C δ + 4 exp(−8N C2 δ ) + 2SN . A.2 Proof of Proposition 3.2 To show Proposition 3.2, we consider theβ-mixing coefficients defined in A.3.1 of Francq & Zakoian (2019): β(F j −∞,F ∞ ℓ ) :=Esup B∈F ∞ ℓ |P(B)−P(B|F j −∞)|, whereF j −∞ andF ∞ ℓ are twoσ-algebras. If we consider the...
2019
-
[9]
measure of dependence
The bandwidth will be selected by cross- validation for the simulation and real-data studies. We consider the consistency between bF (m)(y|x) and bF(y|x) for any (x, y) in the joint domain. Let’s denote: bF(y|x)− bF (m)(y|x) = An −A (m) n W h(x) +A (m) n 1 W h(x) − 1 W (m) h (x) ! ; where An := 1 N n+1X i=p+1 Wh (Xi−1,x)K Yi −y h and A(m) n := 1 N n+1X i=...
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.