IV-Net: A neural network for elliptic PDEs with random and highly varying coefficients
Pith reviewed 2026-06-29 23:51 UTC · model grok-4.3
The pith
A neural network structured like a multigrid V-cycle solves linear elliptic PDEs with high-contrast random coefficients by mapping inputs directly to solution fields.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
IV-Net realizes a mapping from spatially varying coefficients and right-hand side to the solution field by implementing an iterated V-cycle whose smoothing, restriction, and prolongation operators are realized as convolutional layers defined on the physical mesh; for coercive elliptic problems with high-contrast coefficients this learned iteration yields lower error than POD-based reduced models and existing neural operators while maintaining comparable performance to Fourier neural operators on smooth-coefficient Helmholtz problems.
What carries the argument
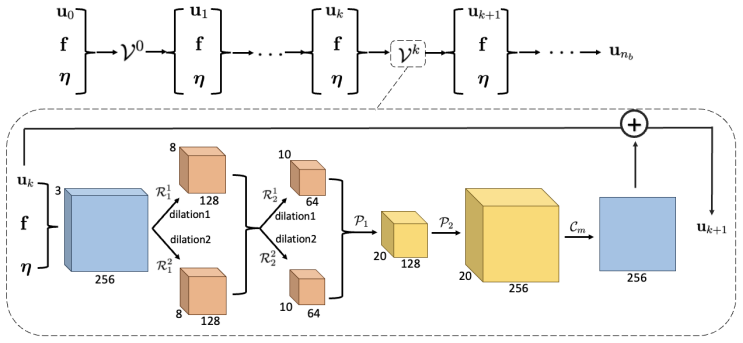
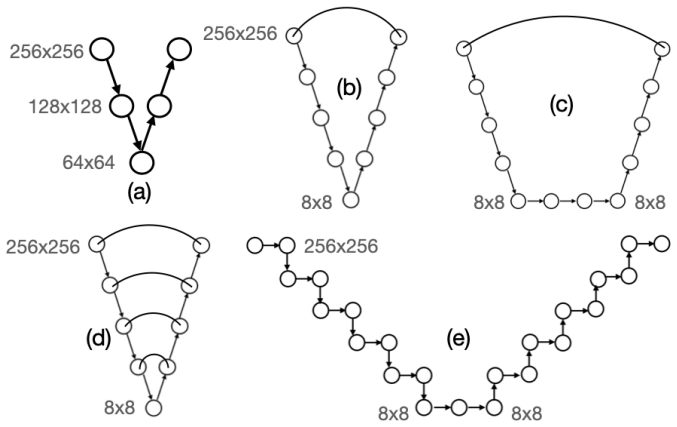
The Iterated V-shaped Net (IV-Net), an architecture that embeds a fixed V-cycle multigrid template inside trainable convolutional layers acting in the physical domain to learn the coefficient-to-solution map.
If this is right
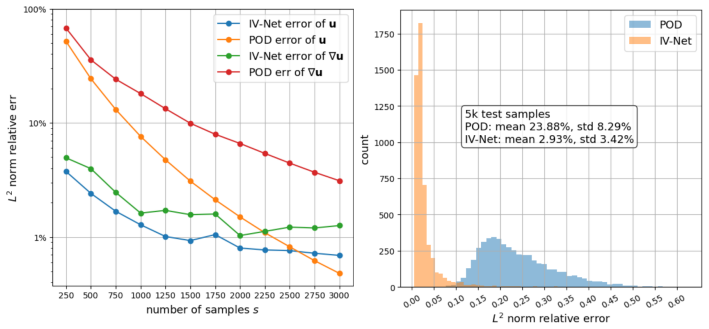
- The learned operator produces lower pointwise and energy-norm errors than POD or other neural operators on coercive high-contrast test problems.
- Error and convergence rates can be bounded in terms of the underlying discretization mesh and the number of training samples.
- The same architecture yields useful predictions for quantities of interest in uncertainty quantification and inverse problems without retraining.
- Performance on low-frequency oscillatory Helmholtz problems with smooth coefficients matches that of a Fourier neural operator.
Where Pith is reading between the lines
- If the convolutional layers truly inherit the contraction properties of multigrid smoothing, the same template could be applied to time-dependent or nonlinear problems whose linearizations admit similar V-cycle structure.
- Because the layers act directly on the physical mesh, the network may transfer across different discretizations more readily than methods that require a fixed spectral basis.
- Data efficiency claims suggest that modest numbers of high-fidelity solves could suffice to train the network for families of coefficients drawn from the same statistical distribution.
Load-bearing premise
A fixed V-cycle multigrid template, once its components are replaced by trainable convolutions, remains stable and accurate for arbitrary high-contrast coefficient fields without any change in iteration count or relaxation parameters.
What would settle it
Numerical experiments on a sequence of coefficient realizations whose contrast ratio exceeds the training range, showing that the network error fails to decrease with additional layers or data while a standard multigrid solver still converges.
Figures

read the original abstract
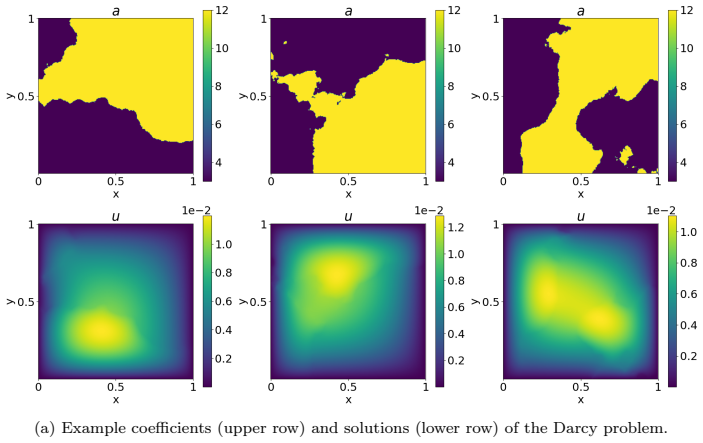
We introduce a novel neural operator architecture designed to approximate solutions of linear elliptic partial differential equations with high-contrast, spatially varying coefficients. The network, termed the Iterated V-shaped Net (IV-Net), realizes a mapping from the input coefficients and righthand side to the corresponding solution field. The architecture of IV-Net is informed by, and closely resembles, a V-cycle multigrid solver. The IV-Net model is parameterized via convolutional layers defined in the physical domain. For coercive problems with highly heterogeneous coefficients, the proposed network exhibits superior performance relative to a proper orthogonal decomposition (POD) approach and several existing neural operator architectures. For low-frequency oscillatory Helmholtz problems with smooth coefficients, its performance is similar to that of a Fourier neural operator. We analyze the approximation error and convergence behavior of IV-Net, its data efficiency, and its dependence on the underlying discretization mesh. Furthermore, we demonstrate the practical effectiveness of the architecture through a series of numerical experiments, including applications to uncertainty quantification, inverse problems, and prediction of quantities of interest.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces IV-Net, a neural operator architecture modeled on the V-cycle multigrid method for approximating solutions of linear elliptic PDEs with high-contrast, spatially varying coefficients. The network maps coefficients and right-hand side to the solution via trainable convolutional layers defined in the physical domain. It claims superior performance relative to POD and existing neural operators on coercive high-contrast problems (with similar performance to FNO on low-frequency Helmholtz), supported by analyses of approximation error, convergence, data efficiency, and mesh dependence, plus numerical experiments on uncertainty quantification, inverse problems, and quantities of interest.
Significance. If the empirical superiority and supporting analyses hold under the stated conditions, the work provides a concrete way to embed classical multigrid structure into neural operators, potentially improving robustness and data efficiency for heterogeneous-coefficient elliptic problems. The explicit study of mesh dependence and the demonstration on downstream tasks (UQ, inversion) are positive features that could influence subsequent operator-learning research.
major comments (2)
- [Analysis of approximation error and convergence behavior] The strongest claim (superior performance on arbitrary high-contrast coercive problems) rests on the assumption that a fixed V-cycle template with trainable convolutional layers remains stable and accurate without per-realization tuning of iteration count or relaxation parameters. The analysis of approximation error does not appear to supply a worst-case bound that survives changes in contrast ratio, correlation length, or spatial arrangement outside the training ensemble; this leaves open whether observed gains are general or ensemble-specific.
- [Numerical experiments section] The manuscript states that numerical experiments support the performance claims, yet the description of data splits, training/validation protocols, and the precise range of contrast ratios tested is not sufficiently detailed to allow independent verification that the superiority versus POD and other operators is not an artifact of the chosen ensemble.
minor comments (2)
- [Architecture description] Notation for the convolutional layers and their relation to the classical multigrid restriction/prolongation operators should be made fully explicit, including any assumptions on the underlying mesh.
- [Numerical experiments] A short table summarizing the contrast ratios, mesh sizes, and number of training samples across all reported experiments would improve readability and allow direct comparison with the cited baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and indicate the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [Analysis of approximation error and convergence behavior] The strongest claim (superior performance on arbitrary high-contrast coercive problems) rests on the assumption that a fixed V-cycle template with trainable convolutional layers remains stable and accurate without per-realization tuning of iteration count or relaxation parameters. The analysis of approximation error does not appear to supply a worst-case bound that survives changes in contrast ratio, correlation length, or spatial arrangement outside the training ensemble; this leaves open whether observed gains are general or ensemble-specific.
Authors: We acknowledge that the approximation error analysis is derived under the distribution of the training ensemble and does not furnish a worst-case bound that is independent of contrast ratio, correlation length, or spatial arrangement outside that ensemble. The performance claims are therefore scoped to problems statistically similar to the training data, with empirical support across the tested range of contrasts. We will revise the manuscript to state this scope explicitly, to clarify that no per-realization tuning is performed, and to discuss the distinction between ensemble-specific gains and fully general guarantees. revision: yes
-
Referee: [Numerical experiments section] The manuscript states that numerical experiments support the performance claims, yet the description of data splits, training/validation protocols, and the precise range of contrast ratios tested is not sufficiently detailed to allow independent verification that the superiority versus POD and other operators is not an artifact of the chosen ensemble.
Authors: We agree that the experimental protocol requires additional detail for independent verification. In the revised version we will expand the numerical experiments section to specify the data-generation procedure, the exact training/validation/test splits, the full training protocol (including optimizer, learning-rate schedule, and stopping criteria), and the precise ranges of contrast ratios and correlation lengths used in all reported comparisons. revision: yes
Circularity Check
No circularity: architecture and empirical validation are self-contained
full rationale
The paper introduces IV-Net as a convolutional parameterization of a V-cycle multigrid template and reports empirical performance against external baselines (POD and published neural operators) plus mesh-dependence and approximation-error analysis. No load-bearing claim reduces by construction to a fitted parameter renamed as prediction, a self-citation chain, or an ansatz smuggled from prior author work; the central mapping is learned from data and the comparisons are to independent methods. The derivation chain therefore remains non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The linear elliptic PDE is coercive for the coefficient fields considered.
Reference graph
Works this paper leans on
- [1]
-
[2]
W.E,B.Yu, TheDeepRitzMethod: ADeepLearning-BasedNumerical Algorithm for Solving Variational Problems, Commun. Math. Stat. 6 (1) (2018) 1–12
2018
-
[3]
Raissi, P
M. Raissi, P. Perdikaris, G. E. Karniadakis, Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations, Journal of Computational Physics 378 (2019) 686–707. 30
2019
-
[4]
V. Sitzmann, J. N. P. Martel, A. W. Bergman, D. B. Lindell, G. Wet- zstein, Implicit Neural Representations with Periodic Activation Func- tions (Jun. 2020).arXiv:2006.09661
-
[5]
Y. Zhu, n. Zabaras, Bayesian deep convolutional encoder–decoder net- works for surrogate modeling and uncertainty quantification, Journal of Computational Physics 366 (2018) 415–447
2018
-
[6]
Y. Khoo, J. Lu, L. Ying, Solving parametric PDE problems with ar- tificial neural networks, Eur. J. Appl. Math 32 (3) (2021) 421–435. arXiv:1707.03351
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Raonic, T
B. Raonic, T. Rohner, CONVOLUTIONAL NEURAL OPERATORS (2023)
2023
- [8]
-
[9]
Winovich, K
N. Winovich, K. Ramani, G. Lin, ConvPDE-UQ: Convolutional neu- ral networks with quantified uncertainty for heterogeneous elliptic par- tial differential equations on varied domains, Journal of Computational Physics 394 (2019) 263–279
2019
-
[10]
T. Chen, H. Chen, Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems, IEEE Trans Neural Netw 6 (4) (1995) 911–917
1995
-
[11]
L. Lu, P. Jin, G. Pang, Z. Zhang, G. E. Karniadakis, Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators, Nat Mach Intell 3 (3) (2021) 218–229
2021
-
[12]
Kontolati, S
K. Kontolati, S. Goswami, G. Em Karniadakis, M. D. Shields, Learning nonlinear operators in latent spaces for real-time predictions of complex dynamics in physical systems, Nat Commun 15 (1) (2024) 5101
2024
-
[13]
Z. Li, N. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. Stu- art, A. Anandkumar, Fourier Neural Operator for Parametric Partial Differential Equations (May 2021).arXiv:2010.08895
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
M. A. Rahman, Z. E. Ross, K. Azizzadenesheli, U-NO: U-shaped Neural Operators, Transactions on Machine Learning Research (Jan. 2023). 31
2023
- [15]
-
[16]
Kovachki, Z
N. Kovachki, Z. Li, B. Liu, K. Azizzadenesheli, K. Bhattacharya, A. Stu- art, Neural Operator: Learning Maps Between Function Spaces With Applications to PDEs
-
[17]
Bhattacharya, B
K. Bhattacharya, B. Hosseini, N. B. Kovachki, A. M. Stuart, Model Re- duction And Neural Networks For Parametric PDEs, The SMAI Journal of computational mathematics 7 (2021) 121–157
2021
-
[18]
L. Lu, X. Meng, S. Cai, Z. Mao, S. Goswami, Z. Zhang, G. E. Karni- adakis, A comprehensive and fair comparison of two neural operators (with practical extensions) based on FAIR data, Computer Methods in Applied Mechanics and Engineering 393 (2022) 114778
2022
-
[19]
O’Leary-Roseberry, P
T. O’Leary-Roseberry, P. Chen, U. Villa, O. Ghattas, Derivative- Informed Neural Operator: An efficient framework for high-dimensional parametric derivative learning, Journal of Computational Physics 496 (2024) 112555
2024
-
[20]
Gupta, X
G. Gupta, X. Xiao, P. Bogdan, Multiwavelet-based Operator Learning for Differential Equations, in: Advances in Neural Information Process- ing Systems, Vol. 34, Curran Associates, Inc., 2021, pp. 24048–24062
2021
-
[21]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. ukasz Kaiser, I. Polosukhin, Attention is All you Need, in: Advances in Neural Information Processing Systems, Vol. 30, Curran Associates, Inc., 2017
2017
-
[22]
Cao, Choose a Transformer: Fourier or Galerkin (Nov
S. Cao, Choose a Transformer: Fourier or Galerkin (Nov. 2021).arXiv: 2105.14995
- [23]
- [24]
-
[25]
Kissas, J
G. Kissas, J. H. Seidman, L. F. Guilhoto, V. M. Preciado, G. J. Pap- pas, P. Perdikaris, Learning operators with coupled attention, J. Mach. Learn. Res. 23 (1) (2022) 215:9636–215:9698
2022
-
[26]
Ronneberger, P
O. Ronneberger, P. Fischer, T. Brox, U-Net: Convolutional Networks for Biomedical Image Segmentation, in: Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2015
2015
-
[27]
F. Yu, V. Koltun, Multi-Scale Context Aggregation by Dilated Convo- lutions (Apr. 2016).arXiv:1511.07122
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[28]
I.M.Babuška, S.A.Sauter, IsthePollutionEffectoftheFEMAvoidable for the Helmholtz Equation Considering High Wave Numbers?, SIAM J. Numer. Anal. 34 (6) (1997) 2392–2423
1997
-
[29]
Azulay, E
Y. Azulay, E. Treister, Multigrid-Augmented Deep Learning Precondi- tioners for the Helmholtz Equation, SIAM J. Sci. Comput. 45 (3) (2023) S127–S151
2023
-
[30]
Benner, S
P. Benner, S. Gugercin, K. Willcox, A Survey of Projection-Based Model Reduction Methods for Parametric Dynamical Systems, SIAM Rev. 57 (4) (2015) 483–531
2015
-
[31]
Quarteroni, A
A. Quarteroni, A. Manzoni, F. Negri, Reduced basis methods for partial differential equations: an introduction, Vol. 92, Springer, 2015
2015
-
[32]
E, A Proposal on Machine Learning via Dynamical Systems, Com- mun
W. E, A Proposal on Machine Learning via Dynamical Systems, Com- mun. Math. Stat. 5 (1) (2017) 1–11
2017
-
[33]
K. He, X. Zhang, S. Ren, J. Sun, Deep Residual Learning for Image Recognition, in: 2016IEEEConferenceonComputerVisionandPattern Recognition (CVPR), IEEE, Las Vegas, NV, USA, 2016, pp. 770–778
2016
-
[34]
Z. Long, Y. Lu, X. Ma, B. Dong, PDE-Net: Learning PDEs from Data, in: Proceedings of the 35th International Conference on Machine Learn- ing, PMLR, 2018, pp. 3208–3216
2018
-
[35]
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
S. Ioffe, C. Szegedy, Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift (Mar. 2015).arXiv: 1502.03167. 33
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[36]
Odena, V
A. Odena, V. Dumoulin, C. Olah, Deconvolution and Checkerboard Ar- tifacts, Distill 1 (10) (2016) e3
2016
-
[37]
S. Lanthaler, R. Molinaro, P. Hadorn, S. Mishra, Nonlinear Reconstruc- tion for Operator Learning of PDEs with Discontinuities (Oct. 2022). arXiv:2210.01074
-
[38]
V. Fanaskov, I. Oseledets, Spectral Neural Operators (Apr. 2024). arXiv:2205.10573
- [39]
-
[40]
S. Lanthaler, S. Mishra, G. E. Karniadakis, Error estimates for Deep- Onets: A deep learning framework in infinite dimensions (Jan. 2022). arXiv:2102.09618
-
[41]
A. Kopaničáková, G. E. Karniadakis, DeepOnet Based Preconditioning Strategies For Solving Parametric Linear Systems of Equations (Jan. 2024).arXiv:2401.02016
- [42]
-
[43]
S. Mao, R. Dong, L. Lu, K. M. Yi, S. Wang, P. Perdikaris, PPDONet: Deep Operator Networks for Fast Prediction of Steady-state Solutions in Disk–Planet Systems, ApJL 950 (2) (2023) L12
2023
-
[44]
C. Lin, Z. Li, L. Lu, S. Cai, M. Maxey, G. E. Karniadakis, Operator learning for predicting multiscale bubble growth dynamics, The Journal of Chemical Physics 154 (10) (2021) 104118
2021
-
[45]
S. Cai, Z. Wang, L. Lu, T. A. Zaki, G. E. Karniadakis, DeepM&Mnet: Inferring the electroconvection multiphysics fields based on operator ap- proximation by neural networks, Journal of Computational Physics 436 (2021) 110296
2021
-
[46]
Zhang, A
E. Zhang, A. Kahana, A. Kopaničáková, E. Turkel, R. Ranade, J. Pathak, G. E. Karniadakis, Blending neural operators and relaxation 34 methods in PDE numerical solvers, Nat Mach Intell 6 (11) (2024) 1303– 1313
2024
-
[47]
J. Hu, P. Jin, A hybrid iterative method based on MIONet for PDEs: Theory and numerical examples, arXiv:2402.07156 [math] (Feb. 2024). doi:10.48550/arXiv.2402.07156. URLhttp://arxiv.org/abs/2402.07156
-
[48]
J. Pathak, S. Subramanian, P. Harrington, S. Raja, A. Chattopadhyay, M. Mardani, T. Kurth, D. Hall, Z. Li, K. Azizzadenesheli, P. Hassan- zadeh, K. Kashinath, A. Anandkumar, FourCastNet: A Global Data- driven High-resolution Weather Model using Adaptive Fourier Neural Operators (Feb. 2022).arXiv:2202.11214
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[49]
V. Gopakumar, S. Pamela, L. Zanisi, Z. Li, A. Anandkumar, MAST. Team, Fourier Neural Operator for Plasma Modelling (Feb. 2023).arXiv:2302.06542
-
[50]
L. Lu, X. Meng, Z. Mao, G. E. Karniadakis, DeepXDE: A Deep Learning LibraryforSolvingDifferentialEquations, SIAMRev.63(1)(2021)208– 228
2021
-
[51]
Z. Long, Y. Lu, B. Dong, PDE-Net 2.0: Learning PDEs from data withanumeric-symbolichybriddeepnetwork, JournalofComputational Physics 399 (2019) 108925
2019
-
[52]
X. Guo, W. Li, F. Iorio, Convolutional Neural Networks for Steady Flow Approximation, in: Proceedings of the 22nd ACM SIGKDD Inter- national Conference on Knowledge Discovery and Data Mining, KDD ’16, Association for Computing Machinery, New York, NY, USA, 2016, pp. 481–490
2016
-
[53]
Deep Learning of Preconditioners for Conjugate Gradient Solvers in Urban Water Related Problems
J. Sappl, L. Seiler, M. Harders, W. Rauch, Deep Learning of Precondi- tioners for Conjugate Gradient Solvers in Urban Water Related Prob- lems (Jun. 2019).arXiv:1906.06925
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[54]
Y. Khoo, L. Ying, SwitchNet: a neural network model for forward and inverse scattering problems, SIAM Journal on Scientific Computing 41 (5) (2019) A3182–A3201. 35
2019
-
[55]
LeCun, Y
Y. LeCun, Y. Bengio, G. Hinton, Deep learning, Nature 521 (7553) (2015) 436–444
2015
-
[56]
Rahaman, A
N. Rahaman, A. Baratin, D. Arpit, F. Draxler, M. Lin, F. Hamprecht, Y. Bengio, A. Courville, On the Spectral Bias of Neural Networks, in: Proceedings of the 36th International Conference on Machine Learning, PMLR, 2019, pp. 5301–5310
2019
-
[57]
Basri, M
R. Basri, M. Galun, A. Geifman, D. Jacobs, Y. Kasten, S. Kritchman, Frequency Bias in Neural Networks for Input of Non-Uniform Density, in: Proceedings of the 37th International Conference on Machine Learn- ing, PMLR, 2020, pp. 685–694
2020
-
[58]
M. Tancik, P. P. Srinivasan, B. Mildenhall, S. Fridovich-Keil, N. Ragha- van, U. Singhal, R. Ramamoorthi, J. T. Barron, R. Ng, Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Do- mains (Jun. 2020).arXiv:2006.10739
-
[59]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J.Uszkoreit, N.Houlsby, AnImageisWorth16x16Words: Transformers for Image Recognition at Scale (Jun. 2021).arXiv:2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [60]
- [61]
-
[62]
Saad, A Flexible Inner-Outer Preconditioned GMRES Algorithm, SIAM J
Y. Saad, A Flexible Inner-Outer Preconditioned GMRES Algorithm, SIAM J. Sci. Comput. 14 (2) (1993) 461–469. 36
1993
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.