BED-SAM2: Boundary-Enhanced-Depth SAM2 via Monocular Geometric Priors
Pith reviewed 2026-06-30 12:00 UTC · model grok-4.3
The pith
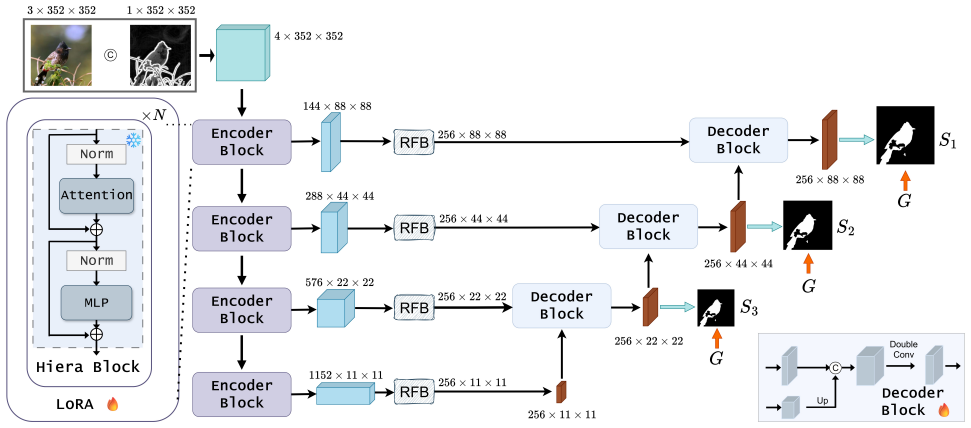
BED-SAM2 modifies the SAM2 Hiera encoder to encode monocular depth from RGB images for sharper object boundaries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BED-SAM2 modifies the SAM2 Hiera encoder architecture so that it directly encodes monocular depth information obtained from RGB images. The added depth channel supplies geometric cues that support more accurate delineation of object boundaries and extraction of camouflaged shapes. This yields competitive state-of-the-art performance on multiple salient and camouflaged object detection tasks while requiring as few as five training epochs.
What carries the argument
The modified SAM2 Hiera encoder that ingests monocular depth maps alongside RGB to inject geometric priors for boundary refinement.
If this is right
- Object boundary accuracy improves in both salient and camouflaged detection settings.
- Performance reaches competitive levels on standard benchmarks after minimal fine-tuning.
- The same encoder change applies across multiple related detection tasks without task-specific redesign.
- Geometric cues from depth reduce reliance on appearance alone for shape extraction.
Where Pith is reading between the lines
- The same depth-injection pattern could be tested on other segmentation foundation models to check transferability.
- If monocular depth proves consistently helpful, training pipelines for boundary-sensitive tasks might incorporate depth estimation as a standard preprocessing step.
- Medical or aerial imagery domains where boundaries are critical could serve as natural next testbeds for the approach.
Load-bearing premise
Monocular depth estimates derived from RGB images supply reliable geometric cues that improve boundary detection without introducing errors or needing large architectural revisions.
What would settle it
A controlled ablation that removes the depth-encoding branch and shows equivalent or higher accuracy on the same detection benchmarks would falsify the claim that the depth channel is the source of the reported gains.
Figures

read the original abstract
Building upon the SAM2 vision foundation model for downstream segmentation, this study introduces Boundary Enhanced Depth (BED)-SAM2. The SAM2 Hiera encoder architecture is modified to directly encode monocular depth information from RGB images, thereby providing geometric cues that enhance object boundary delineation and facilitate the extraction of camouflaged object shapes. BED-SAM2 demonstrates competitive state-of-the-art performance across multiple salient and camouflaged object detection tasks with as few as five training epochs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes BED-SAM2, a modification of the SAM2 vision foundation model in which the Hiera encoder is altered to directly encode monocular depth maps estimated from the input RGB images. This is intended to supply geometric priors that improve object boundary delineation, with particular emphasis on camouflaged object detection. The paper reports that the resulting model achieves competitive state-of-the-art performance on multiple salient and camouflaged object detection benchmarks after only five training epochs.
Significance. If the performance claims are substantiated by rigorous experiments, the work would demonstrate a lightweight way to inject monocular geometric information into a large vision foundation model without major architectural overhaul, potentially benefiting downstream segmentation tasks that rely on boundary accuracy.
major comments (1)
- [Method description] Method description (no section number supplied in available text): the central assumption that directly encoding monocular depth supplies reliable boundary-enhancing cues is not accompanied by any analysis of depth-estimation error rates or their propagation through the Hiera encoder. In camouflaged or low-texture regions—precisely the regimes highlighted in the abstract—monocular depth estimators are known to produce large errors; without explicit mitigation or ablation showing that these errors do not degrade the encoder features, the reported gains could be illusory.
minor comments (1)
- [Abstract] The abstract asserts 'competitive state-of-the-art performance' and 'as few as five training epochs' but supplies no quantitative metrics, baselines, datasets, or statistical significance tests, making the claim impossible to evaluate from the provided text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the method description. We respond to the major comment below.
read point-by-point responses
-
Referee: the central assumption that directly encoding monocular depth supplies reliable boundary-enhancing cues is not accompanied by any analysis of depth-estimation error rates or their propagation through the Hiera encoder. In camouflaged or low-texture regions—precisely the regimes highlighted in the abstract—monocular depth estimators are known to produce large errors; without explicit mitigation or ablation showing that these errors do not degrade the encoder features, the reported gains could be illusory.
Authors: We agree that the manuscript lacks an explicit analysis of depth-estimation error rates and their propagation through the Hiera encoder. In the revised manuscript we will add a dedicated subsection that (i) reports standard depth error metrics (AbsRel, RMSE) of the monocular estimator on the camouflaged-object benchmarks, (ii) presents an ablation that injects controlled noise into the depth maps at levels matching observed error statistics, and (iii) measures the resulting change in boundary F-measure and mIoU. This will directly test whether the reported gains remain robust under realistic depth inaccuracies in low-texture regions. revision: yes
Circularity Check
No circularity: empirical architecture change with no derivation chain
full rationale
The paper describes a direct architectural modification to the SAM2 Hiera encoder to accept monocular depth maps alongside RGB input. No equations, uniqueness theorems, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the provided text. Performance claims rest on reported training results across datasets rather than any closed mathematical reduction to inputs. The monocular-depth integration is an explicit design choice, not a derived quantity that equals its own construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tianrun Chen, Ankang Lu, Lanyun Zhu, Chaotao Ding, Chu- nan Yu, Deyi Ji, Zejian Li, Lingyun Sun, Papa Mao, and Ying Zang. Sam2-adapter: Evaluating & adapting seg- ment anything 2 in downstream tasks: Camouflage, shadow, medical image segmentation, and more.arXiv preprint arXiv:2408.04579, 2024. 2, 5
-
[2]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InCVPR, pages 248–255, 2009. 1
2009
-
[3]
Iako- vidis
George Dimas, Panagiota Gatoula, and Dimitris K. Iako- vidis. MonoSOD: Monocular salient object detection based on predicted depth. InIEEE International Conference on Robotics and Automation (ICRA), pages 4377–4383, 2021. 6
2021
-
[4]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021. 1
2021
-
[5]
Structure-measure: A new way to evaluate foreground maps
Deng-Ping Fan, Ming-Ming Cheng, Yun Liu, Tao Li, and Ali Borji. Structure-measure: A new way to evaluate foreground maps. InICCV, pages 4548–4557, 2017. 4
2017
-
[6]
Enhanced-alignment measure for binary foreground map evaluation
Deng-Ping Fan, Cheng Gong, Yang Cao, Bo Ren, Ming- Ming Cheng, and Ali Borji. Enhanced-alignment measure for binary foreground map evaluation. InIJCAI, pages 698– 704, 2018. 4
2018
-
[7]
Camouflaged object detec- tion
Deng-Ping Fan, Ge-Peng Ji, Guolei Sun, Ming-Ming Cheng, Jianbing Shen, and Ling Shao. Camouflaged object detec- tion. InCVPR, pages 2774–2784, 2020. 4, 5, 7
2020
-
[8]
Pranet: Parallel reverse attention network for polyp segmentation
Deng-Ping Fan, Ge-Peng Ji, Tao Zhou, Geng Chen, Huazhu Fu, Jianbing Shen, and Ling Shao. Pranet: Parallel reverse attention network for polyp segmentation. InMedical Image Computing and Computer Assisted Intervention (MICCAI), pages 263–273, 2020. 3, 4
2020
-
[9]
Rethinking rgb-d salient object detec- tion: Models, data sets, and large-scale benchmarks.IEEE Trans
Deng-Ping Fan, Zheng Lin, Zhao Zhang, Menglong Zhu, and Ming-Ming Cheng. Rethinking rgb-d salient object detec- tion: Models, data sets, and large-scale benchmarks.IEEE Trans. Neural Netw. Learn. Syst., 32(5):2044–2059, 2021. 4, 5, 7
2044
-
[10]
Concealed object detection.IEEE TPAMI, 44(10): 6024–6042, 2022
Deng-Ping Fan, Ge-Peng Ji, Ming-Ming Cheng, and Ling Shao. Concealed object detection.IEEE TPAMI, 44(10): 6024–6042, 2022. 5
2022
-
[11]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InCVPR, pages 770–778, 2016. 1, 2
2016
-
[12]
Xiankang He, Dongyan Guo, Hongji Li, Ruibo Li, Ying Cui, and Chi Zhang. Distill any depth: Distillation cre- ates a stronger monocular depth estimator.arXiv preprint arXiv:2502.19204, 2025. 4
-
[13]
Stereo processing by semiglobal match- ing and mutual information.IEEE TPAMI, 30(2):328–341,
Heiko Hirschmuller. Stereo processing by semiglobal match- ing and mutual information.IEEE TPAMI, 30(2):328–341,
-
[14]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In ICLR, 2022. 3, 5
2022
-
[15]
Depth saliency based on anisotropic center- surround difference
Ran Ju, Ling Ge, Wenjing Geng, Tongwei Ren, and Gang- shan Wu. Depth saliency based on anisotropic center- surround difference. InIEEE Int. Conf. Image Process. (ICIP), pages 1115–1119, 2014. 4, 5
2014
-
[16]
Nick Kanopoulos, Nagesh Vasanthavada, and Robert L. Baker. Design of an image edge detection filter using the sobel operator.IEEE J. Solid-State Circuits, 23(2):358–367,
-
[17]
Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C. Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick. Segment anything. InICCV, pages 3992– 4003, 2023. 1, 2
2023
-
[18]
Nguyen, Zhongliang Nie, Minh- Triet Tran, and Akihiro Sugimoto
Trung-Nghia Le, Tam V . Nguyen, Zhongliang Nie, Minh- Triet Tran, and Akihiro Sugimoto. Anabranch network for camouflaged object segmentation.Comput. Vis. Image Un- derst., 184:45–56, 2019. 4, 5, 7
2019
-
[19]
Visual saliency based on multi- scale deep features
Guanbin Li and Yizhou Yu. Visual saliency based on multi- scale deep features. InCVPR, pages 5455–5463, 2015. 4
2015
-
[20]
Rehg, and Alan L
Yin Li, Xiaodi Hou, Christof Koch, James M. Rehg, and Alan L. Yuille. The secrets of salient object segmentation. InCVPR, pages 280–287, 2014. 4
2014
-
[21]
Lawrence Zitnick
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C. Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, pages 740–755, 2014. 1
2014
-
[22]
Receptive field block net for accurate and fast object detection
Songtao Liu, Di Huang, and Yunhong Wang. Receptive field block net for accurate and fast object detection. InECCV, pages 404–419, 2018. 3
2018
-
[23]
Decoupled weight de- cay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight de- cay regularization. InInternational Conference on Learning Representations (ICLR), 2019. 5
2019
-
[24]
VSCode: General visual salient and camouflaged object de- tection with 2D prompt learning
Ziyang Luo, Nian Liu, Wangbo Zhao, Xuguang Yang, Ding- wen Zhang, Deng-Ping Fan, Fahad Khan, and Junwei Han. VSCode: General visual salient and camouflaged object de- tection with 2D prompt learning. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17169–17180, 2024. 6, 7
2024
-
[25]
Simultaneously lo- calize, segment and rank the camouflaged objects
Yunqiu Lyu, Jing Zhang, Yuchao Dai, Aixuan Li, Bowen Liu, Nick Barnes, and Deng-Ping Fan. Simultaneously lo- calize, segment and rank the camouflaged objects. InCVPR, pages 11591–11601, 2021. 4, 5, 7
2021
-
[26]
How to evaluate foreground maps
Ran Margolin, Lihi Zelnik-Manor, and Ayellet Tal. How to evaluate foreground maps. InIEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 248– 255, 2014. 4
2014
-
[27]
Leveraging stereopsis for saliency analysis
Yuzhen Niu, Yucheng Geng, Xueqing Li, and Feng Liu. Leveraging stereopsis for saliency analysis. InCVPR, pages 454–461, 2012. 4, 5, 7
2012
-
[28]
ZoomNeXt: A unified collaborative pyramid network for camouflaged object detection.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 46(12):9205–9220, 2024
Youwei Pang, Xiaoqi Zhao, Tian-Zhu Xiang, Lihe Zhang, and Huchuan Lu. ZoomNeXt: A unified collaborative pyramid network for camouflaged object detection.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 46(12):9205–9220, 2024. 7
2024
-
[29]
Rgbd salient object detection: A benchmark and algorithms
Houwen Peng, Bing Li, Weihua Xiong, Weiming Hu, and Rongrong Ji. Rgbd salient object detection: A benchmark and algorithms. InECCV, pages 92–109, 2014. 4, 5, 7
2014
-
[30]
Zaiane, and Martin Jagersand
Xuebin Qin, Zichen Zhang, Chenyang Huang, Masood De- hghan, Osmar R. Zaiane, and Martin Jagersand. U2-Net: Going deeper with nested U-Structure for salient object de- tection.Pattern Recognition, 106:107404, 2020. 6
2020
-
[31]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InInt. Conf. Mach. Learn. (ICML), pages 8748–8763, 2021. 1
2021
-
[32]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junt- ing Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao- Yuan Wu, Ross Girshick, Piotr Doll´ar, and Christoph Feicht- enhofer. Sam 2: Segment anything in images and videos. arXiv preprint arXiv:...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer Assisted Inter- vention (MICCAI), pages 234–241, 2015. 2, 3
2015
-
[34]
Hiera: A hier- archical vision transformer without the bells-and-whistles
Chaitanya Ryali, Yuan-Ting Hu, Daniel Bolya, Chen Wei, Haoqi Fan, Po-Yao Huang, Vaibhav Aggarwal, Arkabandhu Chowdhury, Omid Poursaeed, Judy Hoffman, Jitendra Ma- lik, Yanghao Li, and Christoph Feichtenhofer. Hiera: A hier- archical vision transformer without the bells-and-whistles. In Int. Conf. Mach. Learn. (ICML), pages 29441–29454, 2023. 2
2023
-
[35]
A taxonomy and evaluation of dense two-frame stereo correspondence algo- rithms.IJCV, 47:7–42, 2002
Daniel Scharstein and Richard Szeliski. A taxonomy and evaluation of dense two-frame stereo correspondence algo- rithms.IJCV, 47:7–42, 2002. 2
2002
-
[36]
Very deep convo- lutional networks for large-scale image recognition
Karen Simonyan and Andrew Zisserman. Very deep convo- lutional networks for large-scale image recognition. InICLR,
-
[37]
Błaszczyk, Tomasz Depta, Adam Kornacki, and Paweł Kozieł
Przemysław Skurowski, Hassan Abdulameer, J. Błaszczyk, Tomasz Depta, Adam Kornacki, and Paweł Kozieł. Ani- mal camouflage analysis: Chameleon database.Unpublished manuscript, 2018. 4, 5, 7
2018
-
[38]
Learning to de- tect salient objects with image-level supervision
Lijun Wang, Huchuan Lu, Yifan Wang, Mengyang Feng, Dong Wang, Baocai Yin, and Xiang Ruan. Learning to de- tect salient objects with image-level supervision. InCVPR, pages 136–145, 2017. 4, 6
2017
-
[39]
Depth-aided camouflaged object detection
Qingwei Wang, Jinmiao Zheng, Guangyu Qian, Jinghui Dong, Ling Shao, and Ge-Peng Ji. Depth-aided camouflaged object detection. InACM MM, pages 8298–8307, 2023. 2
2023
-
[40]
Pixels, regions, and objects: Multiple enhancement for salient object detection
Yi Wang, Ruili Deng, Qiong Pan, Mingchen Zhuge, Ge-Peng Ji, and Deng-Ping Fan. Pixels, regions, and objects: Multiple enhancement for salient object detection. InCVPR, pages 10031–10040, 2023. 6
2023
-
[41]
F 3Net: Fu- sion, feedback and focus for salient object detection
Jun Wei, Shuhui Wang, and Qingming Huang. F 3Net: Fu- sion, feedback and focus for salient object detection. InAAAI Conference on Artificial Intelligence (AAAI), pages 12321– 12328, 2020. 4
2020
-
[42]
Edn: Salient object detection via extremely- downsampled network.IEEE TIP, 31:3542–3555, 2022
Yu-Huan Wu, Yun Liu, Le Zhang, Ming-Ming Cheng, and Bo Hu. Edn: Salient object detection via extremely- downsampled network.IEEE TIP, 31:3542–3555, 2022. 6
2022
-
[43]
HiDAnet: RGB-D salient ob- ject detection via hierarchical depth awareness.IEEE Trans- actions on Image Processing (TIP), 32:2160–2173, 2023
Zongwei Wu, Guillaume Allibert, Fabrice Meriaudeau, Chao Ma, and C´edric Demonceaux. HiDAnet: RGB-D salient ob- ject detection via hierarchical depth awareness.IEEE Trans- actions on Image Processing (TIP), 32:2160–2173, 2023. 6
2023
-
[44]
Mochu Xiang, Jing Zhang, Yunqiu Lv, Aixuan Li, Yi- ran Zhong, and Yuchao Dai. Exploring depth contri- bution for camouflaged object detection.arXiv preprint arXiv:2106.13217, 2021. 2
-
[45]
Pyramid grafting network for one- stage high resolution saliency detection
Chenxi Xie, Changqun Xia, Mingcan Ma, Zhirui Zhao, Xi- aowu Chen, and Jia Li. Pyramid grafting network for one- stage high resolution saliency detection. InCVPR, pages 11717–11726, 2022. 4, 5, 6
2022
-
[46]
Sam2-unet: Segment anything 2 makes strong encoder for natural and medical image segmentation.Visual Intelligence, 4(1):2, 2026
Xinyu Xiong, Zihuang Wu, Shuangyi Tan, Wenxue Li, Fei- long Tang, Ying Chen, Siying Li, Jie Ma, and Guanbin Li. Sam2-unet: Segment anything 2 makes strong encoder for natural and medical image segmentation.Visual Intelligence, 4(1):2, 2026. 1, 3, 4, 5, 6, 7
2026
-
[47]
Hierarchical saliency detection
Qiong Yan, Li Xu, Jianping Shi, and Jiaya Jia. Hierarchical saliency detection. InCVPR, pages 1155–1162, 2013. 4
2013
-
[48]
Saliency detection via graph-based man- ifold ranking
Chuan Yang, Lihe Zhang, Huchuan Lu, Xiang Ruan, and Ming-Hsuan Yang. Saliency detection via graph-based man- ifold ranking. InCVPR, pages 3166–3173, 2013. 4
2013
-
[49]
Dformerv2: Geometry self- attention for rgbd semantic segmentation
Bo-Wen Yin, Yan-Jie Zhang, Pengyu Zhou, Jifeng Zhao, Luc Van Gool, and Qibin Zhang. Dformerv2: Geometry self- attention for rgbd semantic segmentation. InCVPR, 2025. 6
2025
-
[50]
Towards high-resolution salient object detec- tion
Yi Zeng, Pingping Zhang, Jianming Zhang, Zhe Lin, and Huchuan Lu. Towards high-resolution salient object detec- tion. InICCV, pages 7234–7243, 2019. 4, 5, 6
2019
-
[51]
Rgb-d saliency de- tection via cascaded mutual information minimization
Jing Zhang, Deng-Ping Fan, Yuchao Dai, Xin Yu, Yiran Zhong, Nick Barnes, and Ling Shao. Rgb-d saliency de- tection via cascaded mutual information minimization. In ICCV, pages 4338–4347, 2021. 6
2021
-
[52]
Fastersal: Robust and real-time single-stream ar- chitecture for rgb-d salient object detection.IEEE TMM, 27: 1507–1519, 2025
Jin Zhang, Zhao Liu, Yanliang Ye, Huibing Bi, and Deng- Ping Fan. Fastersal: Robust and real-time single-stream ar- chitecture for rgb-d salient object detection.IEEE TMM, 27: 1507–1519, 2025. 6
2025
-
[53]
Bilateral refer- ence for high-resolution dichotomous image segmentation
Peng Zheng, Dehong Gao, Deng-Ping Fan, Li Liu, Jorma Laaksonen, Wanli Ouyang, and Nicu Sebe. Bilateral refer- ence for high-resolution dichotomous image segmentation. CAAI Artif. Intell. Res., 3:9150038, 2024. 2, 5, 6, 7
2024
-
[54]
Salient object detection via integrity learning.IEEE Transactions on Pattern Anal- ysis and Machine Intelligence (TPAMI), 45(3):3738–3752,
Mingchen Zhuge, Deng-Ping Fan, Nian Liu, Dingwen Zhang, Dong Xu, and Ling Shao. Salient object detection via integrity learning.IEEE Transactions on Pattern Anal- ysis and Machine Intelligence (TPAMI), 45(3):3738–3752,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.