Where Detectors Fail: Probing Generative Space for Generalizable AI-Generated Image Detection
Pith reviewed 2026-06-30 11:53 UTC · model grok-4.3
The pith
A framework uses the detector itself to steer generators via manifold modifications, creating hard samples that train detectors to generalize to unseen generators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
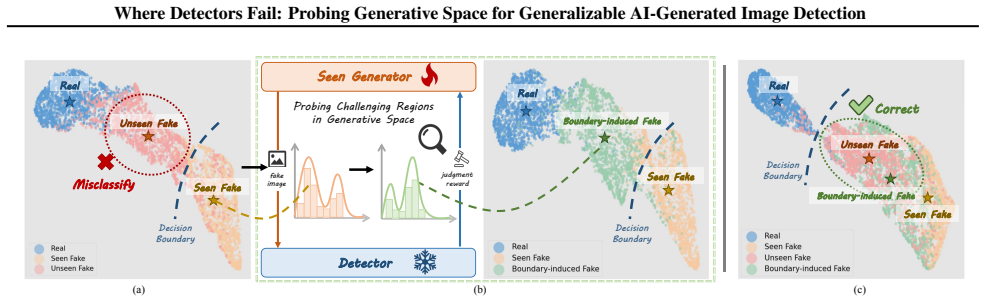
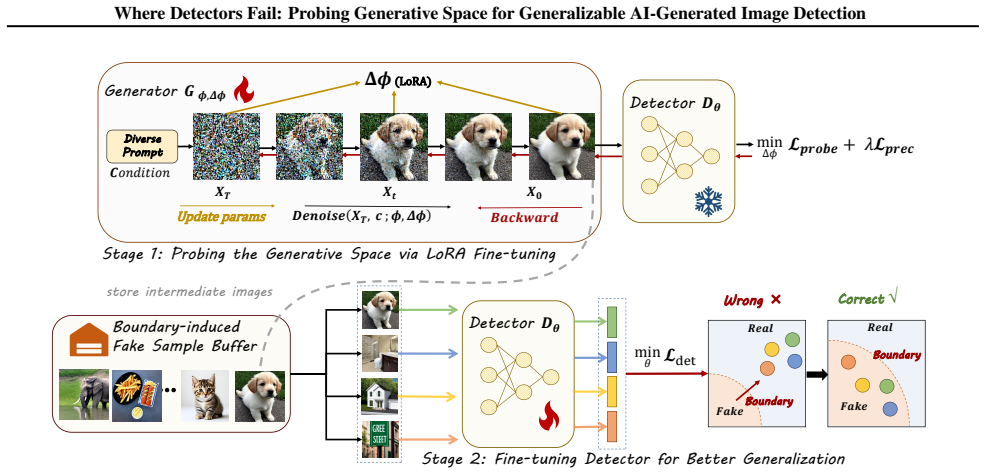
PROBE improves AIGI detector generalization by actively exploring challenging regions of the generative process. Instead of treating the generator as a fixed data source, PROBE uses the detector as a critic to steer the generator through manifold-level modifications, producing realistic samples that are difficult to classify. These samples expose failure cases that are uncommon under standard data sampling strategies and are used to refine the detector.
What carries the argument
PROBE framework that uses the detector as critic to steer the generator through manifold-level modifications and generate challenging training samples.
If this is right
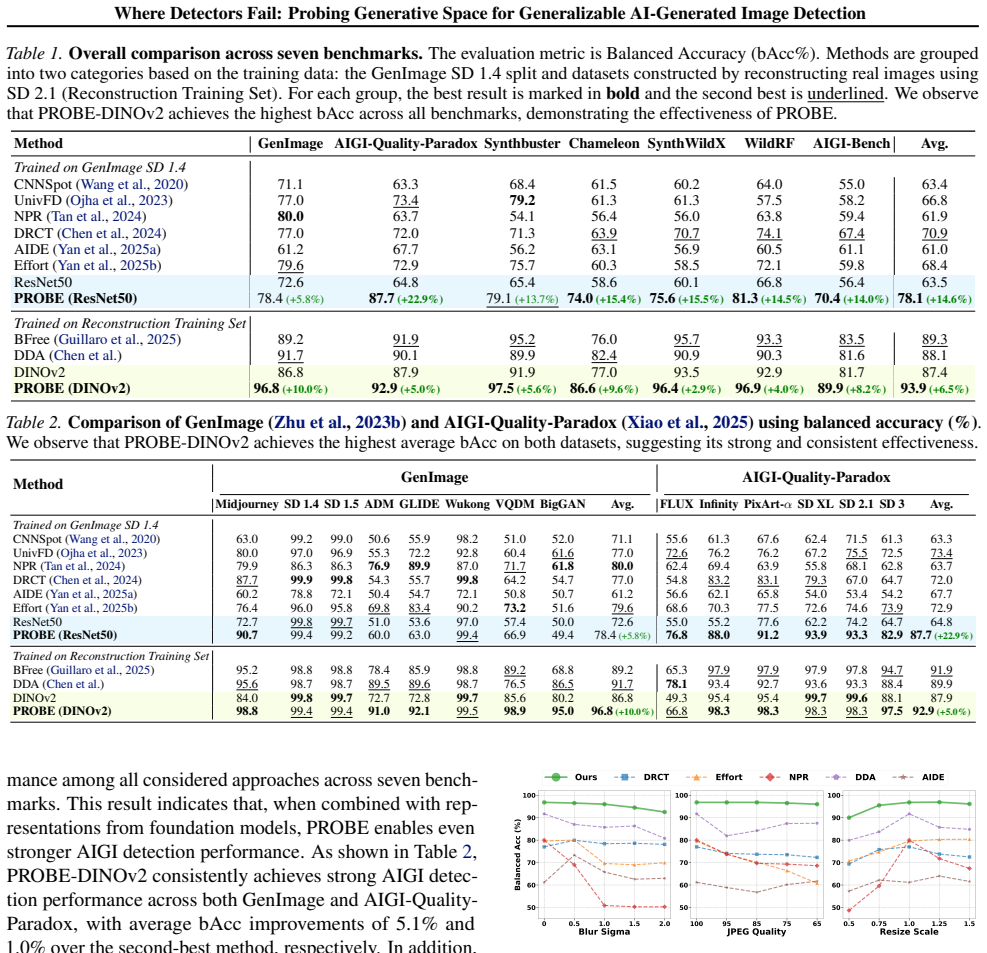
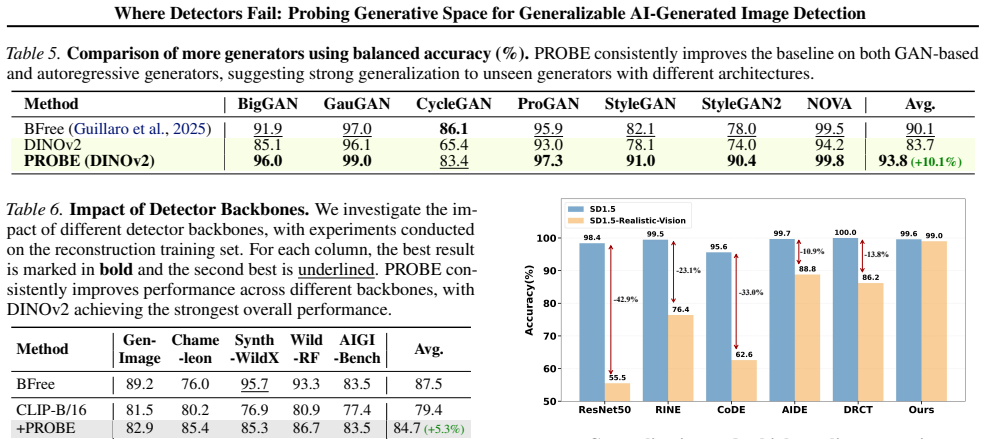
- Detectors refined with PROBE samples achieve better performance on unseen generators across multiple benchmarks.
- Failure cases uncovered by boundary exploration are uncommon under standard sampling and help close coverage gaps.
- Manifold modifications allow creation of diverse realistic variations without relying solely on larger fixed datasets.
- The approach reframes the generator as an editable source rather than a static data provider.
Where Pith is reading between the lines
- Detectors may need ongoing adaptation loops that re-probe generators as new models appear rather than one-time training.
- The same steering idea could apply to other generative domains such as text or video where unseen models also cause detector failure.
- If manifold modifications can be made even more controlled, they might serve as a diagnostic tool to map the exact boundaries of current detectors.
Load-bearing premise
Manifold-level modifications guided by the detector produce realistic images whose failure cases transfer to actual unseen generators.
What would settle it
Train a detector with PROBE samples and test whether its accuracy on images from a new generator (never involved in probing) fails to exceed a baseline trained on standard samples.
Figures






read the original abstract
Detecting AI-generated images (AIGI) remains challenging because detectors often fail to generalize to unseen generators. Although existing methods are trained on large datasets, their performance still degrades when generation settings change, indicating that data scale alone is insufficient and that limited coverage of generative variations during training is a key factor. Studies on generative model editing show that small changes in internal representations can produce diverse and meaningful image variations, many of which are not explored under standard sampling. Leveraging this insight, we propose PROBE (Probing Robustness via Boundary Exploration), a framework that improves detector generalization by actively exploring challenging regions of the generative process. Instead of treating the generator as a fixed data source, PROBE uses the detector as a critic to steer the generator through manifold-level modifications, producing realistic samples that are difficult to classify. These samples expose failure cases that are uncommon under standard data sampling strategies and are used to refine the detector. Experimental results across multiple benchmarks indicate that PROBE enhances generalization to unseen generators, resulting in more generalizable AIGI detection performance. Code and models are available at https://github.com/Amamiya-C/PROBE-AIGI-Detection
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PROBE, a framework that treats the generator as steerable rather than fixed: the detector acts as a critic to perform manifold-level modifications, generating realistic samples that expose uncommon failure cases under standard sampling. These samples are then used to refine the detector, with the central claim being that this process yields improved generalization to unseen generators, as supported by experiments across multiple benchmarks.
Significance. If validated, the result would be significant for AIGI detection because it offers an active, detector-guided way to cover generative variations beyond passive dataset scaling. The public release of code and models is a clear strength that enables reproducibility.
major comments (2)
- [§3] §3 (PROBE framework): the claim that detector-steered manifold modifications produce realistic samples whose failure cases transfer to real unseen generators lacks direct validation via perceptual similarity metrics, human realism ratings, or an ablation showing that non-steered hard negatives are insufficient; this equivalence is load-bearing for the generalization improvement.
- [§4] §4 (Experiments): the reported gains in cross-generator performance are stated without accompanying details on data splits, exact metrics per unseen generator, or controls that isolate the contribution of manifold steering versus standard adversarial augmentation; without these, attribution of the result to the proposed mechanism cannot be verified.
minor comments (1)
- [Abstract] Abstract: the magnitude of improvement and the specific unseen generators tested are not quantified, which would help readers assess practical impact.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will incorporate the suggested additions and clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (PROBE framework): the claim that detector-steered manifold modifications produce realistic samples whose failure cases transfer to real unseen generators lacks direct validation via perceptual similarity metrics, human realism ratings, or an ablation showing that non-steered hard negatives are insufficient; this equivalence is load-bearing for the generalization improvement.
Authors: We agree that direct validation of sample realism and an ablation isolating the steering mechanism would strengthen the central claim. In the revision we will add FID and LPIPS scores comparing steered samples to their unsteered counterparts, include a small-scale human realism rating study, and report an ablation that replaces manifold steering with standard hard-negative mining to quantify the contribution of the proposed mechanism. revision: yes
-
Referee: [§4] §4 (Experiments): the reported gains in cross-generator performance are stated without accompanying details on data splits, exact metrics per unseen generator, or controls that isolate the contribution of manifold steering versus standard adversarial augmentation; without these, attribution of the result to the proposed mechanism cannot be verified.
Authors: We will expand §4 to provide explicit train/validation/test split details, a table of per-generator accuracy and AUC numbers, and additional ablation experiments that directly compare PROBE against standard adversarial augmentation baselines, thereby clarifying the source of the observed generalization gains. revision: yes
Circularity Check
No circularity; empirical refinement via external generators
full rationale
The paper describes an empirical framework (PROBE) that steers generators using a detector to produce challenging samples for detector refinement, with generalization claims resting on experimental results across multiple benchmarks and unseen generators. No equations, derivations, or self-referential definitions are present that would reduce the claimed generalization to a fitted quantity or self-citation chain by construction. The method is presented as data-driven exploration rather than a mathematical derivation, and the approach remains self-contained against external benchmarks without invoking uniqueness theorems or ansatzes from prior self-work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Small changes in internal representations of generative models can produce diverse and meaningful image variations not explored under standard sampling.
Reference graph
Works this paper leans on
-
[1]
Real- time deepfake detection in the real-world.arXiv preprint arXiv:2406.09398,
Cavia, B., Horwitz, E., Reiss, T., and Hoshen, Y . Real- time deepfake detection in the real-world.arXiv preprint arXiv:2406.09398,
-
[2]
Towards Deep Learning Models Resistant to Adversarial Attacks
Madry, A., Makelov, A., Schmidt, L., Tsipras, D., and Vladu, A. Towards deep learning models resistant to adversarial attacks.arXiv preprint arXiv:1706.06083,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Simonyan, K. and Zisserman, A. Very deep convolu- tional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
A sanity check for ai-generated image detection
Yan, S., Li, O., Cai, J., Hao, Y ., Jiang, X., Hu, Y ., and Xie, W. A sanity check for ai-generated image detection. InThe Thirteenth International Conference on Learning Representations, 2025a. Yan, Z., Wang, J., Jin, P., Zhang, K.-Y ., Liu, C., Chen, S., Yao, T., Ding, S., Wu, B., and Yuan, L. Orthogonal subspace decomposition for generalizable ai-gener...
-
[5]
PatchCraft: Exploring texture patch for efficient AI-generated image detection,
Zhong, N., Xu, Y ., Li, S., Qian, Z., and Zhang, X. Patchcraft: Exploring texture patch for efficient ai-generated image detection.arXiv preprint arXiv:2311.12397,
-
[6]
Gendet: Towards good generalizations for ai-generated image detection, 2023
Zhu, M., Chen, H., Huang, M., Li, W., Hu, H., Hu, J., and Wang, Y . Gendet: Towards good generaliza- tions for ai-generated image detection.arXiv preprint arXiv:2312.08880, 2023a. Zhu, M., Chen, H., Yan, Q., Huang, X., Lin, G., Li, W., Tu, Z., Hu, H., Hu, J., and Wang, Y . Genimage: A million-scale benchmark for detecting ai-generated image. InAdvances in...
-
[7]
to fine-tune generator more efficiently. Denoising in the diffusion model is an iterative process, the result xt−1 at the next time step t−1 is obtained by denoising the resultx t at the current stept: xt−1 =a txt +b tϵϕ(xt, t) +c tϵ. (3) where ϵ∼ N(0, I) is random Gaussian noise, and a, b, c are coefficients determined by the sampling algorithm. Therefor...
2023
-
[8]
A linear classifier is attached to each backbone to perform binary classification
and the Transformer-based DINOv2-ViT-L (Oquab et al., 2024). A linear classifier is attached to each backbone to perform binary classification. The input resolutions are set to 224×224 for ResNet50 and 336×336 for DINOV2. For both training and inference, we extract patches of the corresponding resolution via cropping rather than resizing; padding is appli...
2024
-
[9]
We utilize the AdamW optimizer with a weight decay of 1e-5, a learning rate of 1e-5, and a batch size of
• DINOv2: Trained on the Reconstruction Training Set (Guillaro et al., 2025). We utilize the AdamW optimizer with a weight decay of 1e-5, a learning rate of 1e-5, and a batch size of
2025
-
[10]
For image synthesis, we employ the DDIM sampler (Song et al.) with 35 sampling steps
as our target generators for fine-tuning, which align with the seen generators of baseline detectors. For image synthesis, we employ the DDIM sampler (Song et al.) with 35 sampling steps. The classifier-free guidance scale is set to 7.5, and the output resolution is fixed at 512×512. To achieve efficient and controllable fine-tuning, we incorporate lightw...
2022
-
[11]
Finally, the cost of PROBE is a one-time offline process
require 236k and 258k generated samples, respectively, whereas PROBE achieves stronger generalization with only 20k samples. Finally, the cost of PROBE is a one-time offline process. At inference time, the detector architecture remains unchanged and introduces no additional latency. D. Generalization Mechanism of PROBE PROBE performs boundary exploration ...
2008
-
[12]
These datasets encompass a wide array of mainstream generators and exhibit high diversity in terms of both content and format, thereby minimizing evaluation bias. F. Additional Results Following (Wang et al., 2020; Ojha et al., 2023; Tan et al., 2024; Yan et al., 2025b; Guillaro et al., 2025), we additionally report Average Precision (AP) scores in Table
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.