Overview of the PsyDefDetect Shared Task at BioNLP 2026: Detecting Levels of Psychological Defense Mechanisms in Supportive Conversations
Pith reviewed 2026-06-30 12:30 UTC · model grok-4.3
The pith
A shared task on PsyDefConv shows systems classify defense mechanism levels in support dialogues at 0.42 macro F1.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
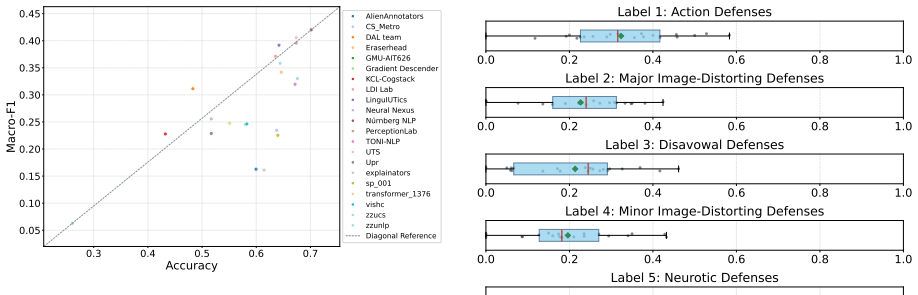
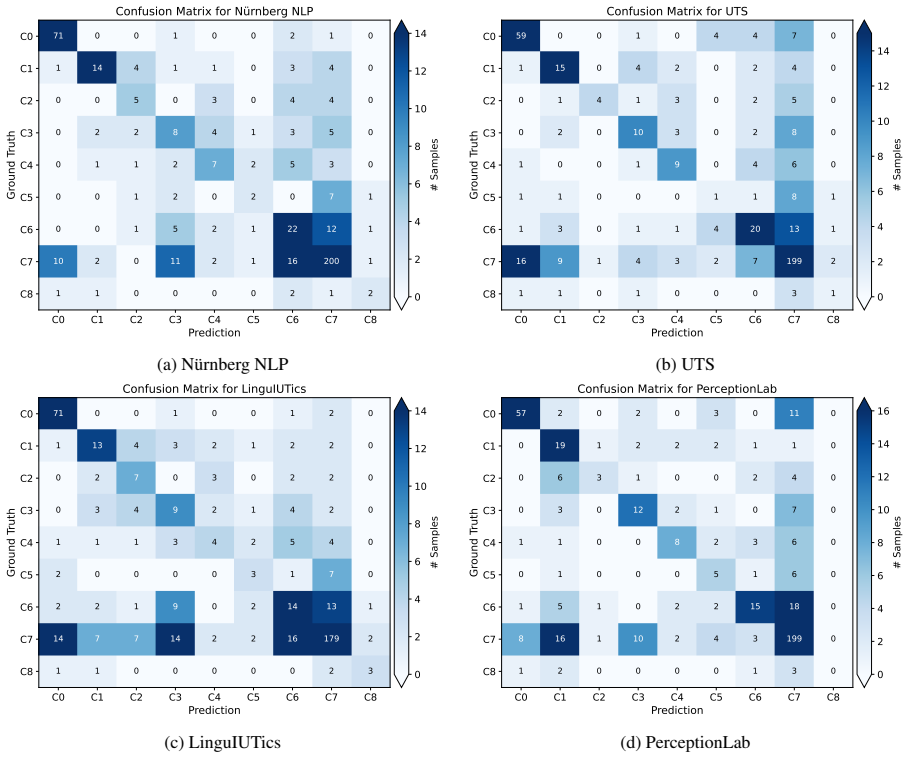
Grounded in the clinically validated DMRS framework, the PsyDefDetect task demonstrates that automated classification of seven hierarchical defense-mechanism levels plus two auxiliary labels is feasible on seeker utterances given preceding context, with the top submitted system attaining 0.420 macro F1 on the 2336-utterance PsyDefConv test set and thereby surpassing the strongest reported baseline.
What carries the argument
The DMRS hierarchical levels (seven main levels plus two auxiliary labels) applied to classify target seeker utterances given dialogue context.
If this is right
- Theory-aware and LLM-based models become preferable for fine-grained defensive-function classification.
- Class-imbalance handling becomes essential for closing the gap between accuracy and macro F1.
- Over-prediction of the High-Adaptive class remains a systematic error that future systems must address.
- Continued community work on this clinical-NLP intersection is invited through released task materials.
Where Pith is reading between the lines
- If DMRS annotations prove stable across languages, the same task design could transfer to non-English support corpora.
- A system that reliably tags defense levels could be inserted into real-time support-chat monitors to flag low-adaptive patterns.
- The observed macro-F1 ceiling of 0.42 suggests the nine-class taxonomy may need coarser or hierarchical evaluation metrics in follow-up work.
Load-bearing premise
Annotators can reliably assign DMRS levels to individual utterances using only the preceding dialogue context.
What would settle it
A fresh annotation round on the same PsyDefConv utterances that yields low or chance-level inter-annotator agreement.
Figures

read the original abstract
We present an overview of PsyDefDetect, the shared task on detecting levels of psychological defense mechanisms in emotional support dialogues, co-located with BioNLP@ACL 2026. Grounded in the clinically validated Defense Mechanism Rating Scales (DMRS) framework, the task asks systems to classify a target seeker utterance, given its preceding dialogue context, into one of nine categories: seven hierarchical DMRS levels plus two auxiliary labels. Participants worked on PsyDefConv, a newly released corpus of 200 dialogues and 2336 help-seeker utterances annotated under DMRS with substantial inter-annotator agreement. The task attracted 172 participants on CodaBench who produced 563 submissions, with 21 teams officially registering their results for the final ranking. The best system achieved a macro F1-score of 0.420, surpassing the strongest fine-tuned baseline reported in the dataset paper by a notable margin, yet leaving clear headroom. Our analysis highlights (i) a persistent tendency to over-predict the majority High-Adaptive class, (ii) a widening gap between accuracy and macro-F1 that reveals class-imbalance sensitivity, and (iii) the value of theory-aware and LLM-based approaches for fine-grained defensive-function classification. We release all task materials and invite the community to continue work on this novel intersection of clinical psychology and NLP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is an overview of the PsyDefDetect shared task (BioNLP@ACL 2026) on classifying nine DMRS-based psychological defense mechanism levels (plus auxiliaries) for seeker utterances in emotional-support dialogues. It introduces the PsyDefConv corpus (200 dialogues, 2336 utterances) annotated under the DMRS framework with reported substantial inter-annotator agreement, describes participation (172 CodaBench users, 21 official teams, 563 submissions), reports that the winning system reached macro F1 of 0.420 (surpassing the dataset-paper baseline), and analyzes persistent issues of majority-class over-prediction and accuracy-vs-macro-F1 divergence.
Significance. If the gold labels prove reliable, the work opens a clinically grounded evaluation setting for fine-grained defensive-function detection in dialogue, supplies a reproducible benchmark with released materials, and demonstrates that theory-aware and LLM-based systems can improve over standard fine-tuning baselines while exposing class-imbalance sensitivities that future work must address.
major comments (1)
- [Abstract / annotation section] Abstract (and the annotation-protocol section): the central performance claim (best macro F1 = 0.420) and the comparison to the dataset-paper baseline presuppose that the 9-class DMRS labels constitute a low-noise gold standard. The only supporting statement supplied is “substantial inter-annotator agreement”; no numerical coefficient (e.g., Fleiss’ κ or Krippendorff’s α), no annotator count per utterance, no resolution procedure for hierarchical-level disagreements, and no per-class agreement breakdown are provided. In a 9-way task already shown to be majority-class biased, this quantitative gap directly affects the interpretability of the reported margin over baseline.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address the single major comment below and will revise the manuscript to improve clarity on annotation reliability.
read point-by-point responses
-
Referee: [Abstract / annotation section] Abstract (and the annotation-protocol section): the central performance claim (best macro F1 = 0.420) and the comparison to the dataset-paper baseline presuppose that the 9-class DMRS labels constitute a low-noise gold standard. The only supporting statement supplied is “substantial inter-annotator agreement”; no numerical coefficient (e.g., Fleiss’ κ or Krippendorff’s α), no annotator count per utterance, no resolution procedure for hierarchical-level disagreements, and no per-class agreement breakdown are provided. In a 9-way task already shown to be majority-class biased, this quantitative gap directly affects the interpretability of the reported margin over baseline.
Authors: We agree that the manuscript currently provides only a qualitative reference to 'substantial inter-annotator agreement' and does not include the requested quantitative details. The full annotation protocol—including numerical coefficients (Fleiss’ κ and Krippendorff’s α), annotator counts, disagreement resolution (majority vote with senior adjudication), and per-class breakdowns—is documented in the referenced PsyDefConv dataset paper. To strengthen self-containment and directly address interpretability concerns for the shared-task overview, we will insert a concise summary of these metrics and procedures into the annotation section of the revised version. This revision will not alter the reported results but will make the gold-standard claims more transparent. revision: yes
Circularity Check
No circularity: shared-task overview reports external results without derivations or self-referential fitting
full rationale
The paper is a competition overview that describes the PsyDefConv corpus, participant submissions (172 participants, 563 submissions), and the winning macro F1 of 0.420 against a baseline from the dataset paper. No equations, predictions, or derivations appear. Claims rest on external team results and reported inter-annotator agreement rather than any fitted parameter renamed as prediction or self-citation chain that reduces the central result to its own inputs. The content is self-contained reporting of empirical outcomes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 2024 Joint International Conference on Computa- tional Linguistics, Language Resources and Eval- uation (LREC-COLING 2024), pages 5734–5746, Torino, Italia
EmpCRL: Controllable empathetic response generation via in-context commonsense reasoning and reinforcement learning. InProceedings of the 2024 Joint International Conference on Computa- tional Linguistics, Language Resources and Eval- uation (LREC-COLING 2024), pages 5734–5746, Torino, Italia. ELRA and ICCL. Tong Chen, Zimu Wang, Yiyi Miao, Haoran Luo, Yu...
2024
-
[2]
InProceedings of the Fifth Workshop on Computational Linguistics and Clinical Psychology: From Keyboard to Clinic, pages 37–46, New Orleans, LA
CLPsych 2018 shared task: Predicting cur- rent and future psychological health from childhood essays. InProceedings of the Fifth Workshop on Computational Linguistics and Clinical Psychology: From Keyboard to Clinic, pages 37–46, New Orleans, LA. Association for Computational Linguistics. Jiayuan Ma, Hongbin Na, Zimu Wang, Yining Hua, Yue Liu, Wei Wang, a...
2018
-
[3]
InProceedings of the 25th Workshop on Biomedical Language Processing (Shared Tasks), San Diego, CA, USA
CS_Metro at PsyDefDetect: Detecting psy- chological defense mechanisms in mental health di- alogues with summarization-enhanced transformer ensembles. InProceedings of the 25th Workshop on Biomedical Language Processing (Shared Tasks), San Diego, CA, USA. Association for Computational Linguistics. Pritha Saha, Shuvodwip Saha, and Anik Mahmud Shanto. 2026....
2026
-
[4]
Philipp Steigerwald, Eric Rudolph, and Jens Albrecht
Large language models and empathy: System- atic review.J Med Internet Res, 26:e52597. Philipp Steigerwald, Eric Rudolph, and Jens Albrecht
-
[5]
InProceedings of the 25th Work- shop on Biomedical Language Processing (Shared Tasks), San Diego, CA, USA
Nürnberg NLP at PsyDefDetect: Multi-axis voter ensembles for psychological defence mecha- nism classification. InProceedings of the 25th Work- shop on Biomedical Language Processing (Shared Tasks), San Diego, CA, USA. Association for Com- putational Linguistics. Duc-Luong Tran, Phuong-Anh Chu, Hoang-Dat Do, Tu-Phuong Mai, Duy-Cat Can, and Hoang-Quynh Le. ...
2026
-
[6]
Do no harm: Exposing hidden vulnera- bilities of LLMs via persona-based client simula- tion attack in psychological counseling.Preprint, arXiv:2604.04842. Zhen Xu, Sergio Escalera, Adrien Pavão, Magali Richard, Wei-Wei Tu, Quanming Yao, Huan Zhao, and Isabelle Guyon. 2022. Codabench: Flexible, easy-to-use, and reproducible meta-benchmark plat- form.Patter...
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.