MultiHaluDet: Multilingual Hallucination Detection via LLM Hidden State Probing
Pith reviewed 2026-06-30 12:27 UTC · model grok-4.3
The pith
MultiHaluDet detects multilingual hallucinations by probing the full hidden-state trajectories of frozen LLMs without language-specific fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
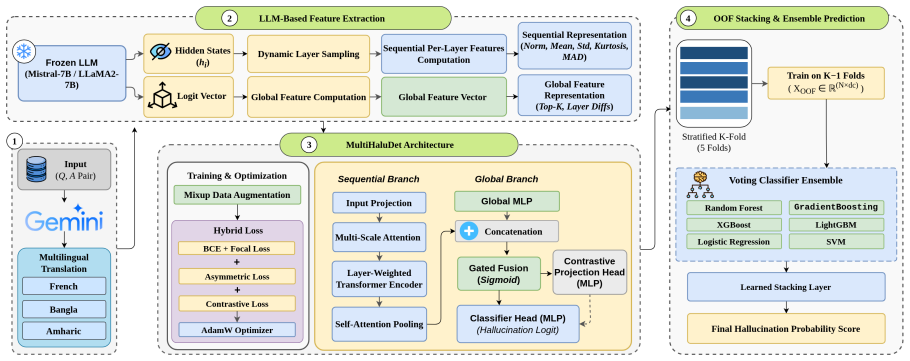
MultiHaluDet is a three-stage stacking framework that detects hallucinations by extracting sequential features from the full hidden-state trajectories of frozen LLMs, processing them with multi-scale attention and self-attention pooling, and feeding the resulting out-of-fold embeddings into a calibrated classical classifier ensemble. The framework achieves up to 98.55 percent AUROC on the English HaluEval and TriviaQA benchmarks with Mistral-7B and LLaMA2-7B and transfers to French, Bangla, and Amharic without language-specific fine-tuning or additional supervision.
What carries the argument
three-stage stacking framework that probes full hidden-state trajectories across multiple layers of a frozen LLM using multi-scale attention and self-attention pooling before feeding out-of-fold embeddings to a classifier ensemble
If this is right
- The same frozen LLM can be monitored for hallucinations in high-, medium-, and low-resource languages using one detector.
- No language-specific labeled data or fine-tuning of the underlying model is required for the detector to operate.
- Both fine-grained layer-wise and coarse-grained sequence-level inconsistency signals are captured by the hybrid attention architecture.
- Classical classifier ensembles calibrated on out-of-fold embeddings improve detection stability over single-layer or logit-based baselines.
Where Pith is reading between the lines
- If hidden-state patterns prove largely language-agnostic, the same detector could be tested on tasks such as bias or toxicity detection that also rely on internal representations.
- The method implies that external retrieval or knowledge-base checks may become less necessary once internal trajectories are read reliably.
- Scaling the approach to larger models would test whether the same layer-wise signatures remain informative as parameter count grows.
Load-bearing premise
Factual inconsistencies produce detectable, consistent patterns in the full hidden-state trajectories of frozen LLMs that transfer across typologically diverse languages without language-specific fine-tuning or additional supervision.
What would settle it
Apply the trained detector to a new low-resource language never seen during any stage of training and measure whether AUROC falls below the strongest baseline; a consistent drop would falsify the cross-lingual transfer claim.
Figures
read the original abstract
Hallucinations in Large Language Models (LLMs) represent a critical barrier to their reliable deployment, a vulnerability heavily exacerbated in non-English and resource-constrained contexts. Existing detection approaches that rely on output confidence heuristics or single-layer internal representations frequently fail to capture deep, complex factual inconsistencies across diverse languages. To address this, we introduce MultiHaluDet, a novel three-stage stacking framework that detects multilingual hallucinations by probing the full hidden state trajectories of frozen LLMs without requiring language-specific fine-tuning. Our method extracts sequential features across multiple layers and processes them via a hybrid architecture using multi-scale attention and self-attention pooling. By generating out-of-fold embeddings that feed into a calibrated classical classifier ensemble, MultiHaluDet captures both fine-grained and coarse-grained patterns of factual inconsistency. Extensive experiments demonstrate that our framework achieves state-of-the-art detection performance, reaching up to 98.55% AUROC on the English HaluEval and TriviaQA benchmarks using Mistral-7B and LLaMA2-7B architectures. Crucially, we rigorously evaluate our framework's cross-lingual generalization across high (French), medium (Bangla), and low-resource (Amharic) languages. MultiHaluDet demonstrates exceptional representational robustness, consistently outperforming baselines and successfully transferring hallucination detection capabilities across typologically diverse linguistic tiers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MultiHaluDet, a three-stage stacking framework for multilingual hallucination detection that probes the full hidden-state trajectories of frozen LLMs (Mistral-7B, LLaMA2-7B). It employs multi-scale attention and self-attention pooling to extract features, generates out-of-fold embeddings, and feeds them into a classical classifier ensemble. The paper claims state-of-the-art performance reaching 98.55% AUROC on English HaluEval and TriviaQA benchmarks, along with exceptional cross-lingual robustness on French (high-resource), Bangla (medium-resource), and Amharic (low-resource) without language-specific fine-tuning.
Significance. If the hidden-state patterns of factual inconsistency prove language-agnostic and the ensemble truly operates in a zero-shot transfer setting, the result would meaningfully advance hallucination detection for non-English and low-resource languages by moving beyond output heuristics or single-layer probes.
major comments (2)
- [Abstract] Abstract: The claim that the framework 'successfully transferring hallucination detection capabilities across typologically diverse linguistic tiers' without language-specific fine-tuning is load-bearing for the central cross-lingual result, yet the abstract provides no information on whether the out-of-fold embeddings and classifier ensemble are trained exclusively on English data or receive any target-language supervision. This detail is required to distinguish true zero-shot transfer from supervised adaptation.
- [Abstract] Abstract: No dataset splits, baseline descriptions, ablation studies, or error analysis are supplied to support the 98.55% AUROC figure or the assertion of outperforming existing methods, rendering the state-of-the-art claim impossible to evaluate on the evidence presented.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback. We address the two major comments on the abstract below. Both points can be resolved through targeted revisions to improve clarity without altering the core claims or results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the framework 'successfully transferring hallucination detection capabilities across typologically diverse linguistic tiers' without language-specific fine-tuning is load-bearing for the central cross-lingual result, yet the abstract provides no information on whether the out-of-fold embeddings and classifier ensemble are trained exclusively on English data or receive any target-language supervision. This detail is required to distinguish true zero-shot transfer from supervised adaptation.
Authors: The out-of-fold embeddings and classifier ensemble are trained exclusively on English data with no target-language supervision at any stage, enabling true zero-shot transfer. This is consistent with the manuscript's description of frozen LLMs and the cross-lingual evaluation protocol. We will revise the abstract to explicitly state that training occurs only on English and that evaluation on French, Bangla, and Amharic is performed in a zero-shot setting. revision: yes
-
Referee: [Abstract] Abstract: No dataset splits, baseline descriptions, ablation studies, or error analysis are supplied to support the 98.55% AUROC figure or the assertion of outperforming existing methods, rendering the state-of-the-art claim impossible to evaluate on the evidence presented.
Authors: Abstracts are concise summaries and do not contain full experimental details; the manuscript body (Sections 4–5) provides dataset splits, baseline comparisons, ablation studies on multi-scale attention and ensemble components, and error analysis. The 98.55% AUROC is supported by these results. To address the concern, we will add a brief clause in the abstract noting that full experimental validation, including ablations, appears in the paper. revision: partial
Circularity Check
No significant circularity; empirical framework with independent experimental claims
full rationale
The paper presents an empirical three-stage stacking framework that extracts features from full hidden-state trajectories of frozen LLMs, applies multi-scale attention and self-attention pooling, generates out-of-fold embeddings, and feeds them to a classical classifier ensemble. No equations, derivations, or self-referential definitions appear in the provided text that would make the reported AUROC values (e.g., 98.55%) equivalent to inputs by construction. Cross-lingual robustness claims rest on experimental evaluation across languages rather than any self-citation load-bearing premise or fitted-parameter renaming. The method is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 967–976
The internal state of an llm knows when it’s lying. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 967–976. Jakub Binkowski, Denis Janiak, Albert Sawczyn, Bog- dan Gabrys, and Tomasz Jan Kajdanowicz
2023
-
[2]
InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing, pages 24365–24396
Hallucination detection in llms using spectral fea- tures of attention maps. InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing, pages 24365–24396. Chao Chen, Kai Liu, Ze Chen, Yi Gu, Yue Wu, Mingyuan Tao, Zhihang Fu, and Jieping Ye
2025
-
[3]
arXiv preprint arXiv:2402.03744 , year=
Inside: Llms’ internal states retain the power of hallu- cination detection.arXiv preprint arXiv:2402.03744. I Chern, Steffi Chern, Shiqi Chen, Weizhe Yuan, Ke- hua Feng, Chunting Zhou, Junxian He, Graham Neu- big, Pengfei Liu, and 1 others
-
[4]
Factool: Fac- tuality detection in generative ai–a tool augmented framework for multi-task and multi-domain scenar- ios.arXiv preprint arXiv:2307.13528. Yung-Sung Chuang, Linlu Qiu, Cheng-Yu Hsieh, Ran- jay Krishna, Yoon Kim, and James Glass
-
[5]
InProceedings of the 2024 Con- ference on Empirical Methods in Natural Language Processing, pages 1419–1436
Lookback lens: Detecting and mitigating contextual hallucinations in large language models using only attention maps. InProceedings of the 2024 Con- ference on Empirical Methods in Natural Language Processing, pages 1419–1436. Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal
2024
-
[6]
A probabilistic framework for llm hal- lucination detection via belief tree propagation. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Compu- tational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 3076–3099. Yuheng Huang, Jiayang Song, Zhijie Wang, Shengming Zhao, Huaming Chen...
2025
-
[7]
Look before you leap: An exploratory study of uncertainty measurement for large language models. arXiv preprint arXiv:2307.10236. Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer
-
[8]
Language Models (Mostly) Know What They Know
Language mod- els (mostly) know what they know.arXiv preprint arXiv:2207.05221. Sahil Kale and Antonio Luca Alfeo
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Lie to me: Knowledge graphs for robust hallucination self-detection in llms, 2025
Lie to me: Knowledge graphs for robust hallucination self- detection in llms.arXiv preprint arXiv:2512.23547. Hazel Kim, Tom A Lamb, Adel Bibi, Philip Torr, and Yarin Gal
-
[10]
InPro- ceedings of the 2025 Conference on Empirical Meth- ods in Natural Language Processing, pages 32298– 32310
Detecting llm hallucination through layer-wise information deficiency: Analysis of am- biguous prompts and unanswerable questions. InPro- ceedings of the 2025 Conference on Empirical Meth- ods in Natural Language Processing, pages 32298– 32310. Jannik Kossen, Jiatong Han, Muhammed Razzak, Lisa Schut, Shreshth Malik, and Yarin Gal
2025
-
[11]
Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs
Seman- tic entropy probes: Robust and cheap hallucination detection in llms.arXiv preprint arXiv:2406.15927. Junyi Li, Xiaoxue Cheng, Wayne Xin Zhao, Jian- Yun Nie, and Ji-Rong Wen
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Halueval: A large-scale hallucination evaluation benchmark for large language models (2023).URL https://arxiv. org/abs/2305.11747,
-
[13]
Neural probe- based hallucination detection for large language mod- els.arXiv preprint arXiv:2512.20949. Abhika Mishra, Akari Asai, Vidhisha Balachandran, Yizhong Wang, Graham Neubig, Yulia Tsvetkov, and Hannaneh Hajishirzi
- [14]
-
[15]
arXiv preprint arXiv:2410.02707 , year=
Llms know more than they show: On the intrinsic representation of llm hallucinations. arXiv preprint arXiv:2410.02707. Ernesto Quevedo, Jorge Yero Salazar, Rachel Koerner, Pablo Rivas, and Tomas Cerny
-
[16]
In Findings of the Association for Computational Lin- guistics: ACL 2024, pages 14379–14391
Un- supervised real-time hallucination detection based on the internal states of large language models. In Findings of the Association for Computational Lin- guistics: ACL 2024, pages 14379–14391. Bhanu Prakash Vangala, Sajid Mahmud, Pawan Neu- pane, Joel Selvaraj, and Jianlin Cheng
2024
-
[17]
Neeraj Varshney, Wenlin Yao, Hongming Zhang, Jian- shu Chen, and Dong Yu
Hal- lumat: Detecting hallucinations in llm-generated ma- terials science content through multi-stage verifica- tion.arXiv preprint arXiv:2512.22396. Neeraj Varshney, Wenlin Yao, Hongming Zhang, Jian- shu Chen, and Dong Yu
-
[18]
A Stitch in Time Saves Nine: Detecting and Mitigating Hallucinations of
A stitch in time saves nine: Detecting and mitigating hallucinations of llms by validating low-confidence generation.arXiv preprint arXiv:2307.03987. Borui Yang, Md Afif Al Mamun, Jie M Zhang, and Gias Uddin. 2025a. Hallucination detection in large language models with metamorphic relations. Proceedings of the ACM on Software Engineering, 2(FSE):425–445. ...
-
[19]
Hallucination Detection and Evaluation of Large Language Model
Hallu- cination detection and evaluation of large language model.arXiv preprint arXiv:2512.22416. Jiawei Zhang, Chejian Xu, Yu Gai, Freddy Lecue, Dawn Song, and Bo Li
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Knowhalu: Hal- lucination detection via multi-form knowledge based factual checking,
Knowhalu: Hallucination detection via multi-form knowledge based factual checking.arXiv preprint arXiv:2404.02935. Luan Zhang, Dandan Song, Zhijing Wu, Yuhang Tian, Changzhi Zhou, Jing Xu, Ziyi Yang, and Shuhao Zhang
-
[21]
Mahogany
is adapted for our evaluation by collecting realistic, model-generated hallucinations. In the original dataset, each entry consists of a question and its ground-truth correct answer. To generate plausible hard negatives, we prompt an early-generation language model known for its propensity to hallucinate, Gemma-2-2B, to answer each question. Responses tha...
1975
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.