Interpretability Transfer from Language to Vision via Sparse Autoencoders
Pith reviewed 2026-06-30 11:43 UTC · model grok-4.3
The pith
A visual projector can be regularized to map image tokens into an LLM's existing textual sparse autoencoder space, transferring labeled concepts for interpretation and editing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
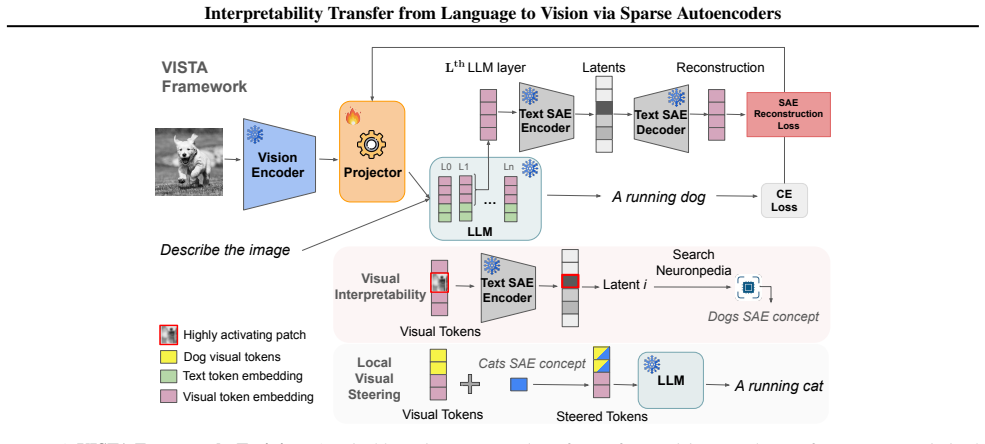
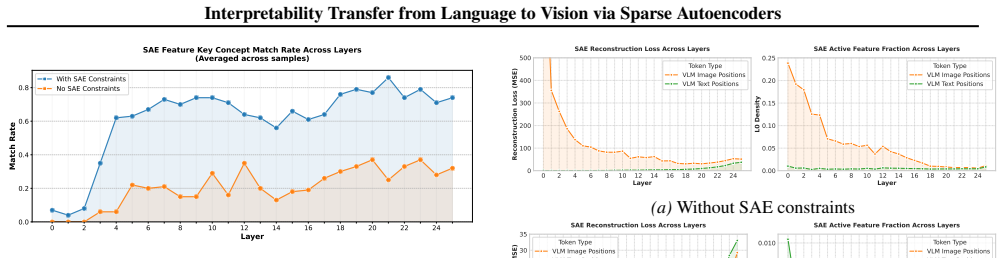
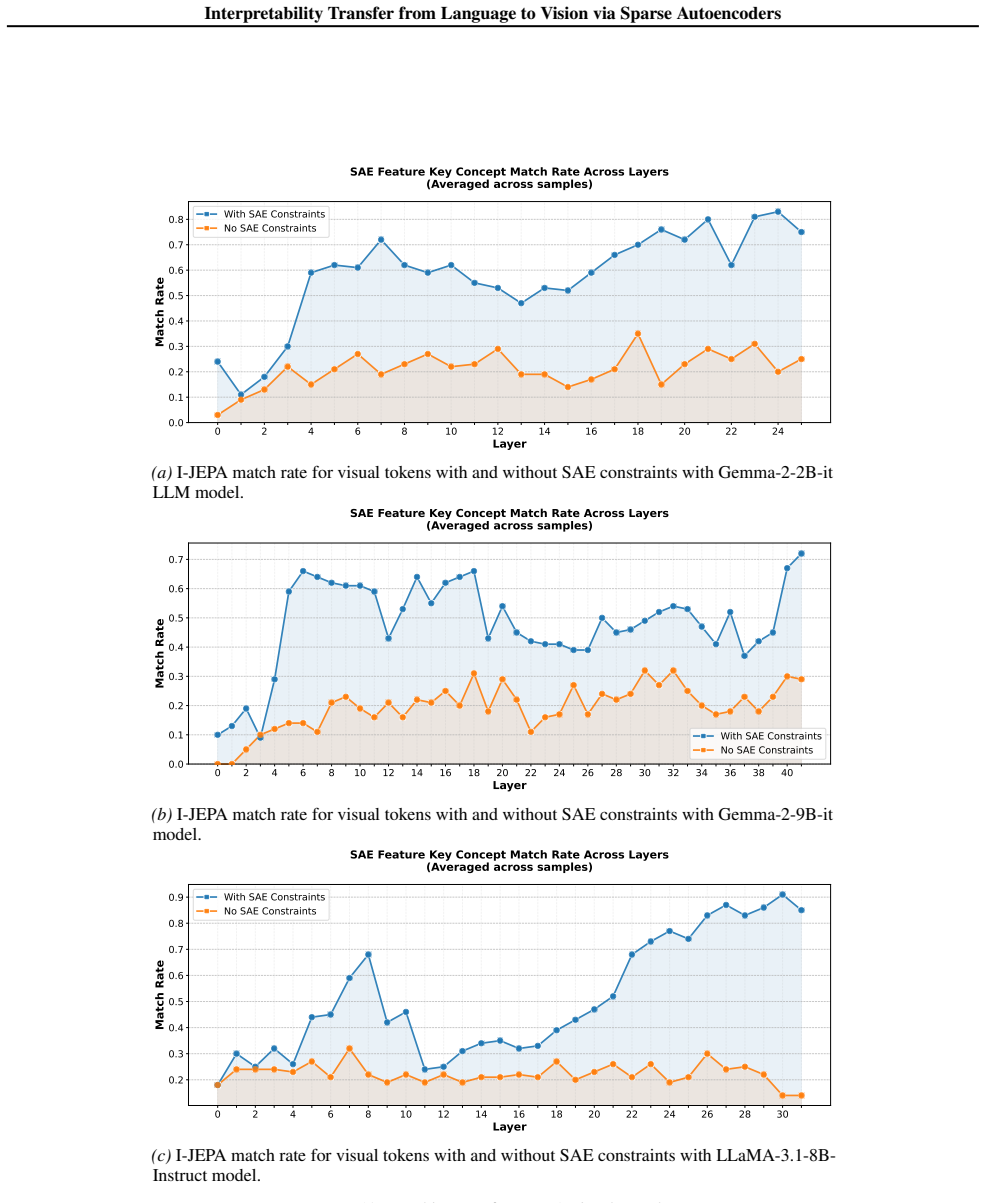
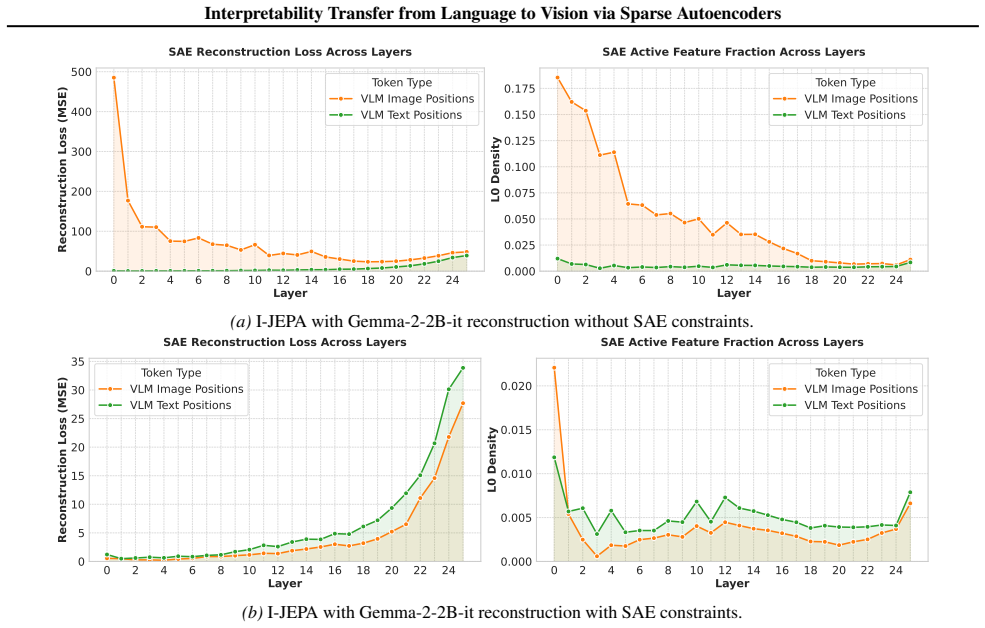
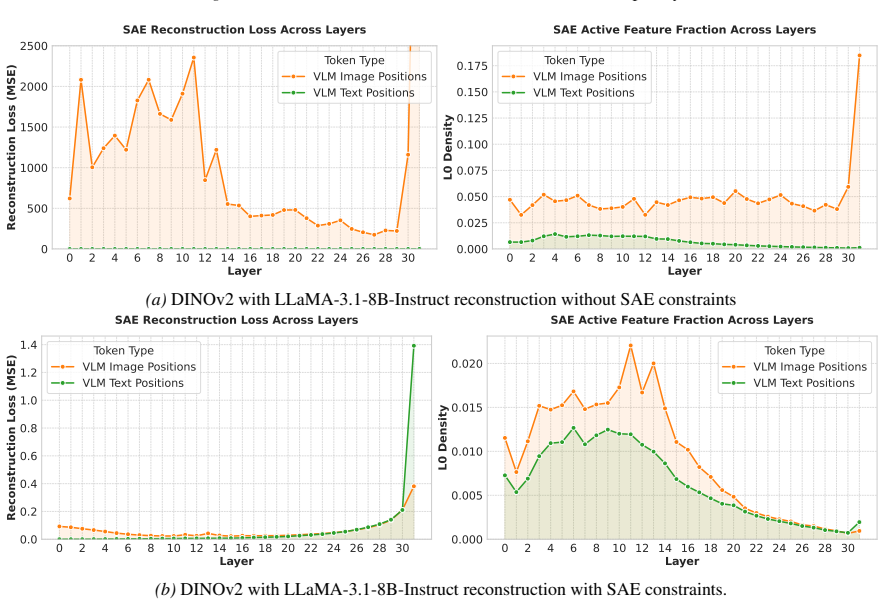
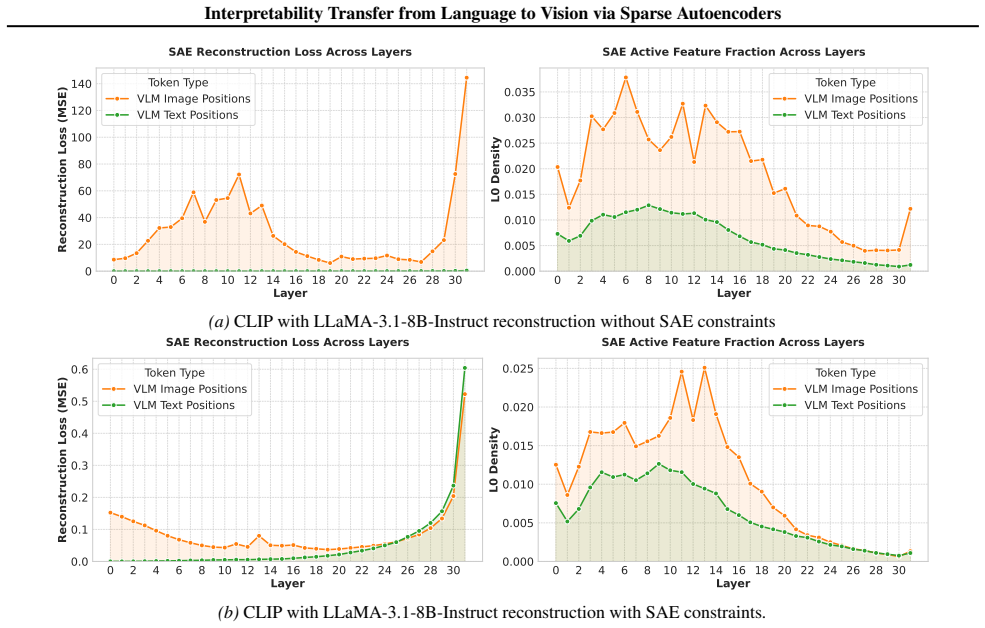
VISTA constrains the visual projector with the LLM's SAE reconstruction loss so that visual tokens inhabit the text SAE manifold. This yields a threefold increase in matching rate between activating textual concepts and image semantics. Localized interventions then remove objects 35 percent more effectively and replace them 47 percent more effectively than vision-only baselines, with the effect holding across multiple LLM architectures.
What carries the argument
The visual projector regularized by textual SAE reconstruction loss to align tokens with labeled language concepts.
If this is right
- Textual SAEs provide interpretability for vision without dedicated vision training.
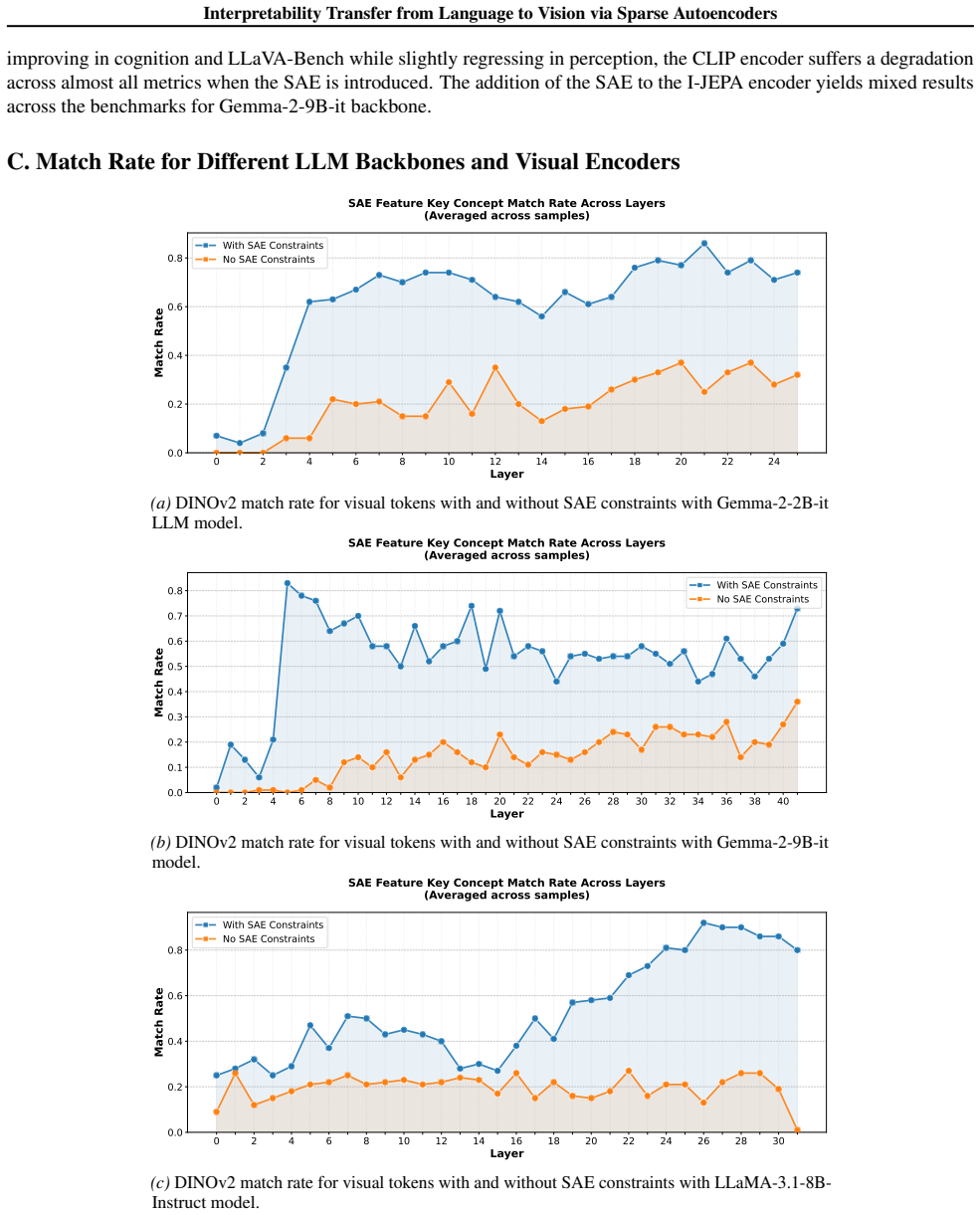
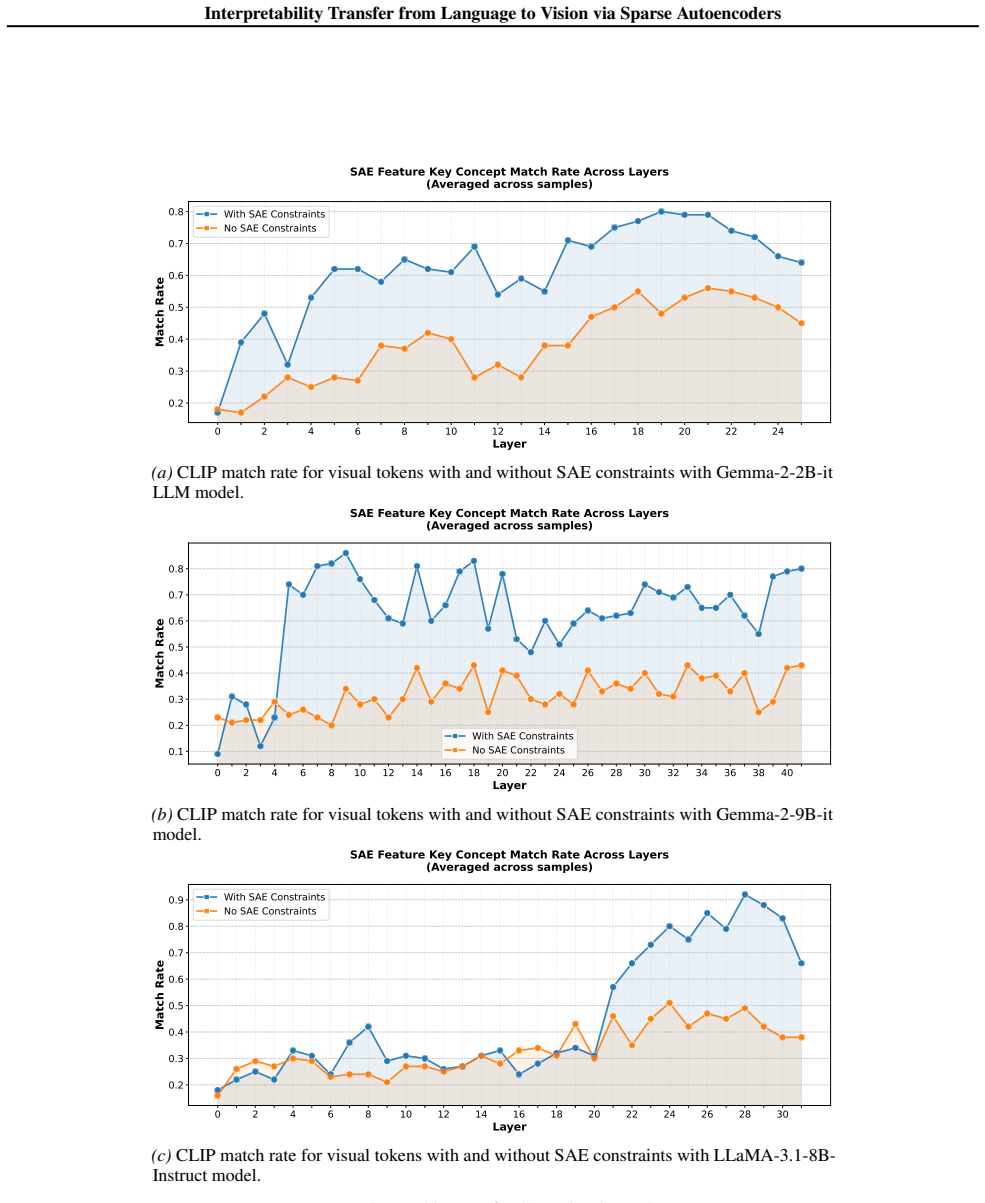
- DINOv2 encoders yield stronger localization than alternatives in the aligned space.
- Concept-level edits can target specific objects while preserving the rest of the scene.
- The method applies to multiple LLM backbones using the same textual SAE.
Where Pith is reading between the lines
- If visual tokens reliably occupy the text SAE manifold, the same alignment could be tested on other input types such as audio.
- Scaling the approach might reveal limits on how well the manifold captures fine visual details.
- Interventions could be combined with other editing techniques to achieve more complex scene changes.
Load-bearing premise
The textual SAE features correspond to distinct semantic visual elements after the projector is regularized, so that altering those features changes only the intended part of the visual output.
What would settle it
A case where deactivating an SAE feature matched to a particular object in the image fails to remove that object from the generated response would falsify the claim that visual tokens inhabit the text SAE manifold.
Figures




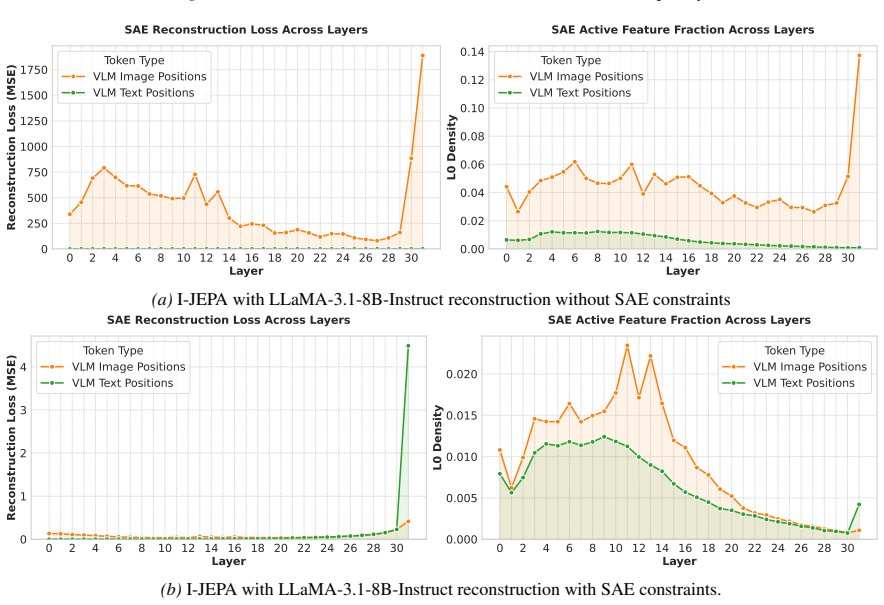
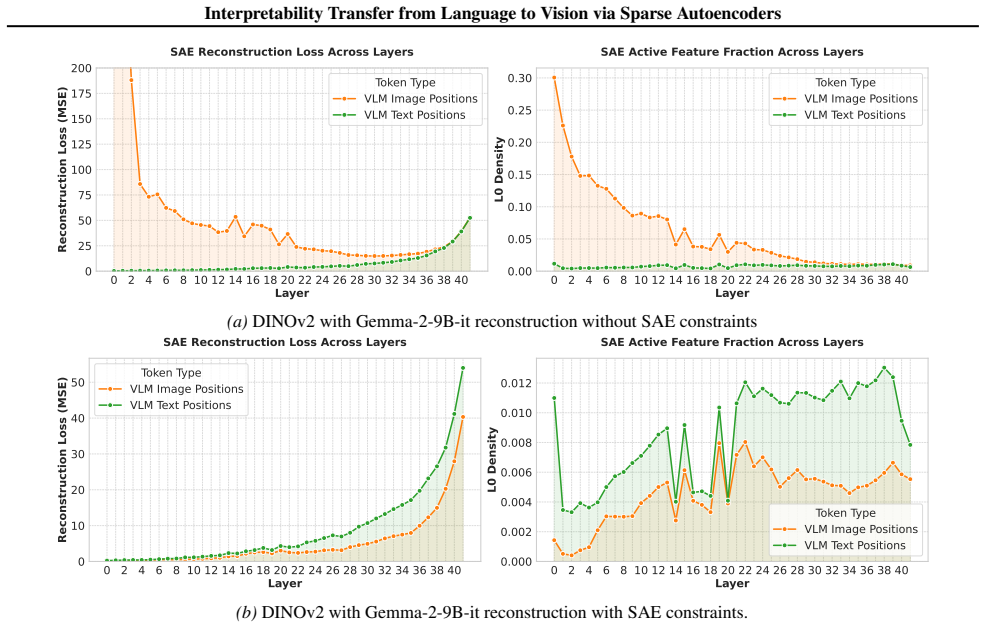
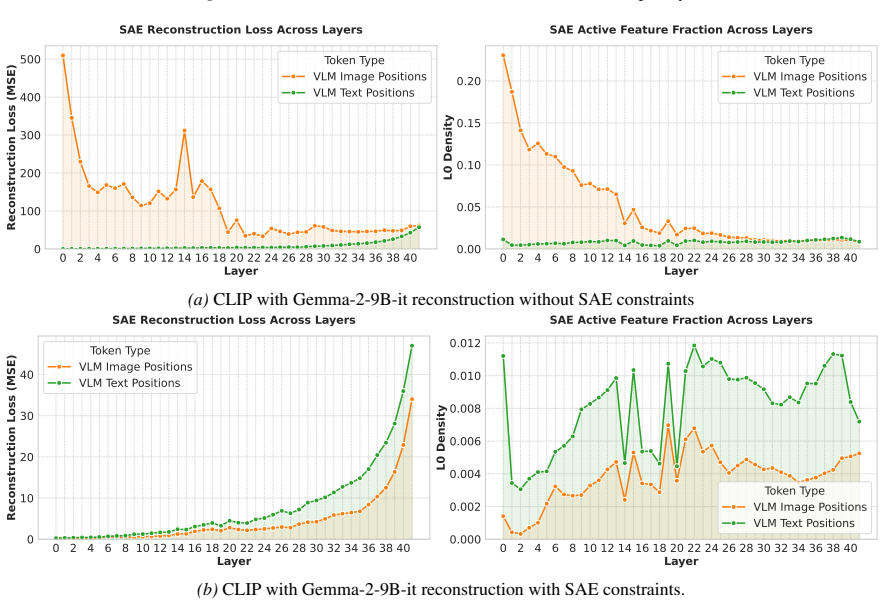
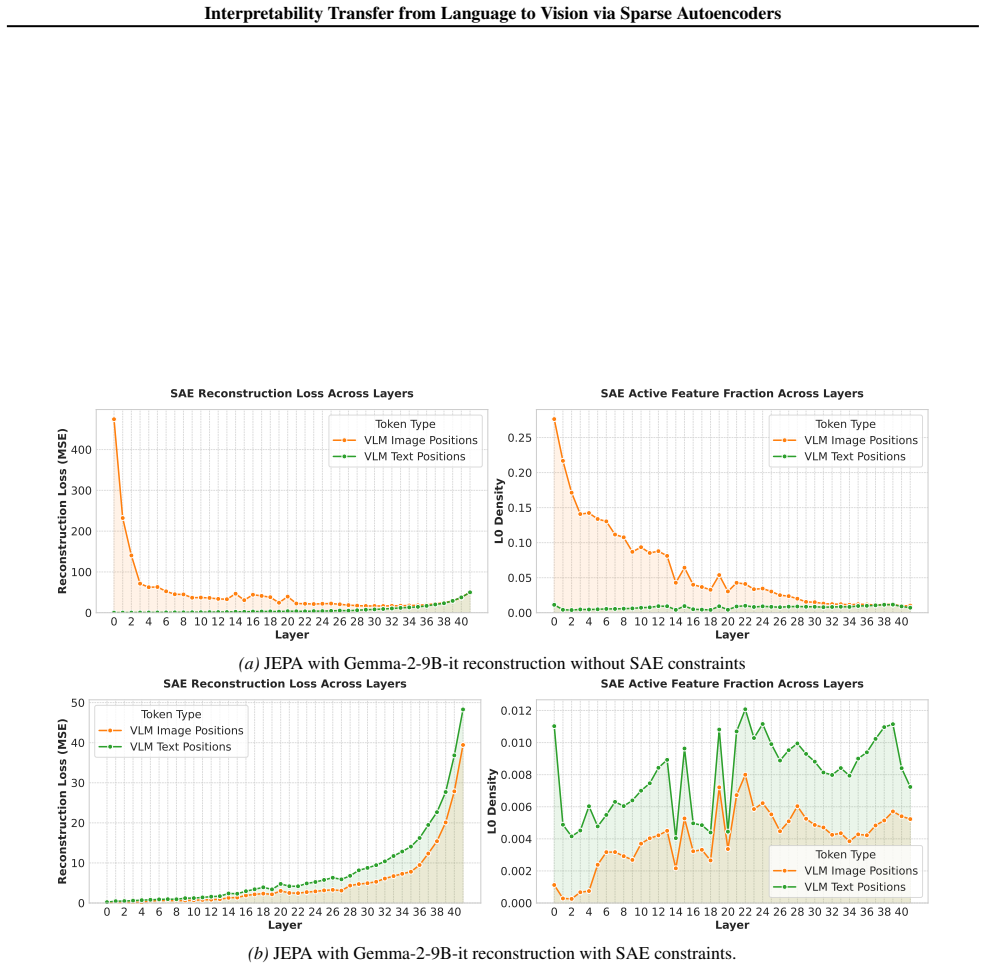


read the original abstract
Recent advances in language model interpretability using sparse autoencoders (SAEs) have yet to effectively translate to the visual domain, mainly due to the difficulty and ambiguity of labeling visual concepts. In this paper, we introduce Visual Interpretability via SAE Transfer Alignment (VISTA), a framework that transfers interpretability from language to vision in a LLaVA-style vision-language model by constraining a visual projector to map visual tokens into an LLM's pre-existing, labeled textual SAE space. This approach enables visual interpretability without training dedicated vision SAEs. By regularizing the projector using the LLM's SAE reconstruction loss, VISTA achieves a threefold increase in the matching rate, which measures how accurately the most activating textual concepts in the SAE space correspond to semantic elements in the image. Using this framework, we further analyze spatial localization properties of different vision encoders and show that DINOv2 features have stronger localization abilities than other encoders. Leveraging this precision, we validate VISTA's cross-modal alignment through fine-grained, localized concept interventions, where specific objects are removed or replaced in the model's perception while preserving the surrounding scene. This results in improvements of 35% in object removal and 47% in object replacement tasks over vision-only baselines, providing causal evidence that visual tokens inhabit the text SAE manifold. These contributions are validated across multiple LLM architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VISTA, a framework that transfers interpretability from pre-trained textual sparse autoencoders (SAEs) to vision in LLaVA-style vision-language models. It does so by regularizing the visual projector with the LLM's SAE reconstruction loss to map visual tokens into the labeled textual SAE space. The work claims a threefold increase in matching rate between top-activating textual SAE concepts and image semantics, stronger spatial localization for DINOv2 encoders, and 35% / 47% gains in object removal and replacement interventions over vision-only baselines, which is presented as causal evidence that visual tokens inhabit the text SAE manifold. Results are reported across multiple LLM architectures.
Significance. If the alignment and causal claims hold after appropriate controls, the approach would provide a practical route to visual interpretability that reuses existing language SAEs rather than training dedicated vision SAEs, while enabling localized concept interventions in multimodal models.
major comments (2)
- [Intervention experiments] Intervention experiments (object removal/replacement tasks): the vision-only baselines omit the SAE reconstruction loss used to train the VISTA projector. Consequently the reported 35% and 47% gains cannot be attributed specifically to visual tokens residing on the pre-trained textual SAE manifold rather than to the presence of the additional regularization term; this directly undermines the causal-evidence claim.
- [Matching-rate evaluation] Matching-rate evaluation: the threefold increase is reported without an explicit definition of the metric, without ablations that isolate manifold habitation from general projector quality, and without controls that apply equivalent regularization without the SAE manifold constraint.
minor comments (2)
- [Abstract] The abstract states that results are validated across multiple LLM architectures but supplies no per-architecture quantitative breakdowns or tables.
- [Method] No equations or pseudocode are shown for the projector regularization term or the matching-rate computation, making it difficult to verify that the method is parameter-free with respect to the SAE labels.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, acknowledging where additional controls are needed to support the causal claims, and outline the revisions we will implement.
read point-by-point responses
-
Referee: [Intervention experiments] Intervention experiments (object removal/replacement tasks): the vision-only baselines omit the SAE reconstruction loss used to train the VISTA projector. Consequently the reported 35% and 47% gains cannot be attributed specifically to visual tokens residing on the pre-trained textual SAE manifold rather than to the presence of the additional regularization term; this directly undermines the causal-evidence claim.
Authors: We agree that the vision-only baselines lack the SAE reconstruction loss, which prevents cleanly attributing the reported gains to manifold alignment rather than the regularization itself. To address this, we will add new control experiments that apply equivalent regularization to the projector using non-SAE objectives (e.g., direct MSE on visual features or a randomly initialized autoencoder). These results, along with updated discussion of the causal evidence, will be included in the revised manuscript. revision: yes
-
Referee: [Matching-rate evaluation] Matching-rate evaluation: the threefold increase is reported without an explicit definition of the metric, without ablations that isolate manifold habitation from general projector quality, and without controls that apply equivalent regularization without the SAE manifold constraint.
Authors: We acknowledge that an explicit mathematical definition of the matching rate was not provided in the main text (though described qualitatively in the abstract). We will insert a precise definition and formula in the methods section. We will also add the requested ablations, including projectors trained with matched regularization strength but without the textual SAE constraint, to isolate the manifold effect from general projector improvements. These changes will be incorporated in the revision. revision: yes
Circularity Check
No circularity: empirical framework with externally defined metrics and no self-referential derivations
full rationale
The manuscript presents VISTA as an empirical method that regularizes a visual projector via an existing textual SAE reconstruction loss and reports comparative performance gains on matching rate, object removal, and replacement tasks. No equations, derivations, or parameter-fitting steps are described that would reduce the central claim (visual tokens inhabiting the SAE manifold) to a tautology or fitted input renamed as prediction. The matching rate and intervention metrics are defined externally rather than by construction from the regularization term. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way. This is the common honest case of a self-contained empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Featured Certification
ISSN 2835-8856. Featured Certification. Pach, M., Karthik, S., Bouniot, Q., Belongie, S., and Akata, Z. Sparse autoencoders learn monosemantic features in vision-language models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. Peng, X., Bai, Q., Xia, X., Huang, Z., Saenko, K., and Wang, B. Moment matching for multi-sou...
2025
-
[2]
Steering llama 2 via contrastive activation addition
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.828. Sharma, P., Ding, N., Goodman, S., and Soricut, R. Con- ceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. InProceedings of ACL, 2018. Turner, A. M., Thiergart, L., Udell, D., Leech, G., Mini, U., and MacDiarmid, M. Activation additi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.