ConFi-GS Confidence-Guided High-Frequency Injection for 3D Gaussian Splatting Super-Resolution
Pith reviewed 2026-06-30 11:33 UTC · model grok-4.3
The pith
A frequency-aware reliability map combined with a geometry-guided prior forms a detail-injection map that selectively adds reliable high-frequency content during 3D Gaussian Splatting optimization from low-resolution images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
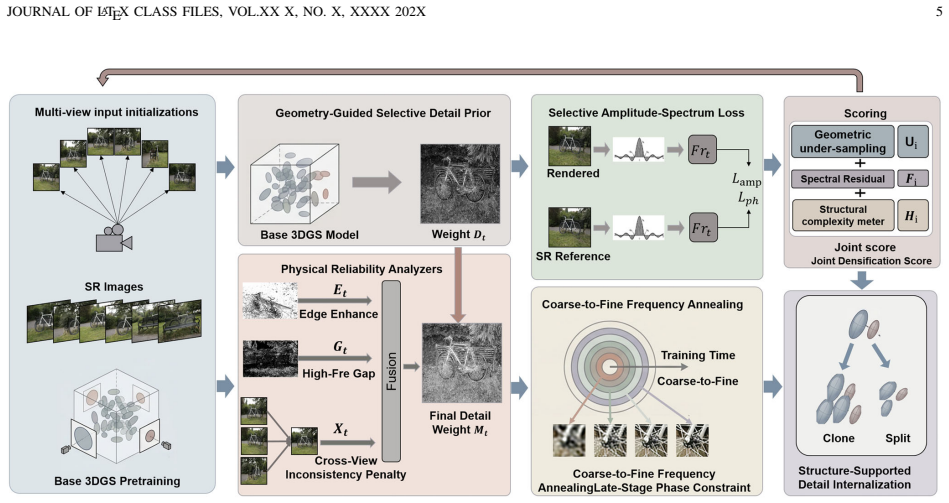
The paper establishes a reliability-aware frequency modeling framework in which a geometry-guided detail-demand prior identifies regions likely to be under-detailed under low-resolution supervision, a frequency-aware reliability map then evaluates whether candidate high-frequency details are structurally supported, spectrally unresolved, and cross-view stable, and their combination produces a detail-injection map that directs spatially selective supervision, coarse-to-fine frequency regularization, and reliability-aware Gaussian densification to internalize only reliable details into the 3D representation.
What carries the argument
The detail-injection map, formed by combining the geometry-guided detail-demand prior and the frequency-aware reliability map, which controls where, when, and how reliable high-frequency details are introduced into the Gaussian representation.
If this is right
- Spatially selective supervision activates high-frequency guidance only where the detail-injection map indicates need.
- Coarse-to-fine frequency regularization progressively incorporates reliable details without destabilizing the representation.
- Reliability-aware Gaussian densification internalizes unresolved yet stable high-frequency content into the 3D model.
- The overall scheme suppresses view-inconsistent artifacts while raising both quantitative fidelity metrics and perceptual quality on standard benchmarks.
Where Pith is reading between the lines
- The same separation of demand from reliability could be tested in other neural rendering pipelines that suffer from low-resolution input.
- If the reliability map proves robust across datasets, it may reduce the need for manual hyperparameter tuning of frequency regularization strength.
- Extending the map to include temporal stability could support video-based 3D reconstruction without additional architectural changes.
Load-bearing premise
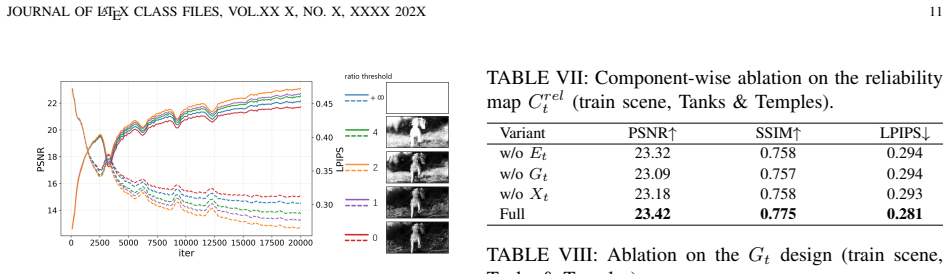
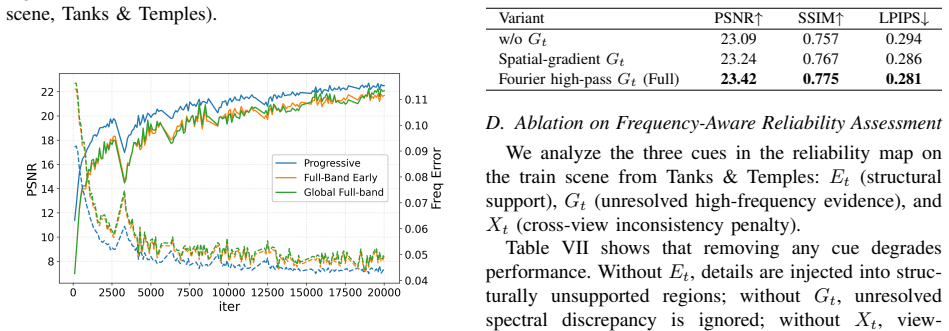
The frequency-aware reliability map can correctly determine whether candidate high-frequency details are structurally supported, spectrally unresolved, and cross-view stable.
What would settle it
A controlled experiment in which the method is applied to a scene with known ground-truth high-frequency structure; if the reliability map labels unstable or inconsistent details as reliable and the optimization incorporates them, producing measurable view inconsistency or reduced fidelity compared to uniform super-resolution baselines, the claim would be falsified.
Figures



read the original abstract
Reconstructing high-quality 3D scenes from low-resolution multi-view images remains challenging for 3D Gaussian Splatting (3DGS), because insufficient high-frequency observations often lead to blurred textures, weak boundaries, and view-inconsistent details. Existing approaches either apply super-resolution guidance uniformly or localize enhancement regions based mainly on geometric sampling. However, they typically do not distinguish between two fundamentally different questions: where additional detail is needed, and whether the corresponding candidate high-frequency content is reliable enough to be internalized into a multi-view consistent 3D representation. In this paper, we propose a reliability-aware frequency modeling framework for low-resolution 3DGS reconstruction. The framework first estimates a geometry-guided detail-demand prior to locate regions that are likely under-detailed under low-resolution supervision. It then computes a frequency-aware reliability map to determine whether candidate high-frequency details are structurally supported, spectrally unresolved, and cross-view stable. Combining these signals yields a detail-injection map that guides where super-resolved details should be introduced during optimization. Based on this map, we design a unified optimization scheme comprising spatially selective supervision, coarse-to-fine frequency regularization, and reliability-aware Gaussian densification. This scheme controls where reliable details are injected, when high-frequency supervision is activated, and how unresolved yet reliable details are internalized into the Gaussian representation. Experiments on multiple benchmarks show improved fidelity and perceptual quality while suppressing unstable or view-inconsistent details.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ConFi-GS, a reliability-aware frequency modeling framework for super-resolving 3D Gaussian Splatting from low-resolution multi-view images. It computes a geometry-guided detail-demand prior to identify under-detailed regions and a frequency-aware reliability map to assess whether candidate high-frequency content is structurally supported, spectrally unresolved, and cross-view stable. These are combined into a detail-injection map that drives a unified optimization scheme consisting of spatially selective supervision, coarse-to-fine frequency regularization, and reliability-aware Gaussian densification. The abstract claims that experiments on multiple benchmarks demonstrate improved fidelity and perceptual quality while suppressing unstable details.
Significance. If the central claims hold with supporting quantitative evidence, the work would offer a principled way to selectively inject reliable high-frequency details into 3DGS, addressing a key limitation of uniform or purely geometry-based super-resolution methods and potentially advancing consistent multi-view 3D reconstruction quality.
major comments (2)
- [Abstract] Abstract: the central claim that the combined detail-demand prior and reliability map produces a detail-injection map yielding improved fidelity rests on experimental validation, yet the abstract supplies no quantitative metrics, error bars, ablation results, or benchmark comparisons; without these the strength of the improvement claim cannot be evaluated.
- [Abstract] Abstract (paragraph on reliability map): the assertion that the frequency-aware reliability map correctly determines structural support, spectral resolution, and cross-view stability is load-bearing for the framework, but no computation details, equations, or validation procedure are provided to allow assessment of whether this determination is reliable or circular.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the combined detail-demand prior and reliability map produces a detail-injection map yielding improved fidelity rests on experimental validation, yet the abstract supplies no quantitative metrics, error bars, ablation results, or benchmark comparisons; without these the strength of the improvement claim cannot be evaluated.
Authors: We agree that the abstract would benefit from explicit quantitative support for the improvement claim. In the revised version we will incorporate key metrics (e.g., average PSNR and perceptual gains on the evaluated benchmarks) together with a concise reference to the supporting ablations, while remaining within abstract length constraints. revision: yes
-
Referee: [Abstract] Abstract (paragraph on reliability map): the assertion that the frequency-aware reliability map correctly determines structural support, spectral resolution, and cross-view stability is load-bearing for the framework, but no computation details, equations, or validation procedure are provided to allow assessment of whether this determination is reliable or circular.
Authors: The abstract is intentionally high-level. The concrete equations defining structural support (geometry-consistency term), spectral resolution (frequency-band analysis), and cross-view stability (multi-view feature consistency), together with the validation procedure, appear in Section 3.2 of the manuscript. We can add a brief parenthetical reference to that section in the abstract if the referee prefers, but we maintain that technical derivations belong in the body text. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper describes a framework that first estimates a geometry-guided detail-demand prior, then computes a frequency-aware reliability map, and combines them into a detail-injection map to guide optimization steps including selective supervision, frequency regularization, and Gaussian densification. No equations, fitted parameters, self-citations, uniqueness theorems, or ansatzes are referenced in the abstract or description. All components are presented as independent computations derived from geometric and frequency analysis rather than reducing to self-defined inputs or prior results by the same authors. The central claims therefore remain self-contained without any load-bearing circular steps.
Axiom & Free-Parameter Ledger
invented entities (1)
-
detail-injection map
no independent evidence
Reference graph
Works this paper leans on
-
[1]
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis,” inProc. Eur. Conf. Comput. Vis. (ECCV), 2020, pp. 405–421. JOURNAL OF LATEX CLASS FILES, VOL.XX X, NO. X, XXXX 202X 14
2020
-
[2]
Instant Neural Graphics Primitives with a Multiresolution Hash Encoding,
T. M ¨uller, A. Evans, C. Schied, and A. Keller, “Instant Neural Graphics Primitives with a Multiresolution Hash Encoding,”ACM Trans. Graph., vol. 41, no. 4, pp. 102:1–102:15, 2022
2022
-
[3]
FoV-NeRF: Foveated Neural Radiance Fields for Virtual Reality,
N. Deng, Z. He, J. Ye, B. Duinkharjav, P. Chakravarthula, X. Yang, and Q. Sun, “FoV-NeRF: Foveated Neural Radiance Fields for Virtual Reality,”IEEE Trans. Vis. Comput. Graph., vol. 28, pp. 3854–3864, 2022, doi: 10.1109/TVCG.2022.3203102
-
[4]
ACM Transactions on Graphics42(4), 1–14 (2023).https://doi.org/10.1145/3592433
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3D Gaussian Splatting for Real-Time Radiance Field Rendering,” ACM Trans. Graph., vol. 42, no. 4, pp. 139:1–139:14, 2023, doi: 10.1145/3592433
-
[5]
Yanqi, D
B. Yanqi, D. Tianyu, H. Jing, L. Yaoli, L. Yuxin, L. Wenbin, G. Yang, L. Jiebo, ”3D Gaussian Splatting: Survey, Technologies, Challenges, and Opportunities,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[6]
3D Gaussian Splatting as a New Era: A Survey,
B. Fei, J. Xu, R. Zhang, Q. Zhou, W. Yang, and Y . He, “3D Gaussian Splatting as a New Era: A Survey,”IEEE Trans. Vis. Comput. Graph., vol. 31, no. 8, pp. 4429–4449, 2025, doi: 10.1109/TVCG.2024.3397828
-
[7]
SVGS: Enhancing Gaus- sian Splatting Using Primitives with Spatially Varying Col- ors,
R. Xu, W. Chen, J. Wang, Y . Liu, P. Wang, C. Lin, S. Xin, X. Li, W. Wang, and T. Komura, “SVGS: Enhancing Gaus- sian Splatting Using Primitives with Spatially Varying Col- ors,”IEEE Trans. Vis. Comput. Graph., pp. 1–14, 2026, doi: 10.1109/TVCG.2026.3690745
-
[8]
SRGS: Super-Resolution 3D Gaussian Splatting,
X. Feng, Y . He, Y . Wang, Y . Yang, W. Li, Y . Chen, Z. Kuang, J. Ding, J. Fan, and J. Yu, “SRGS: Super-Resolution 3D Gaussian Splatting,”arXiv preprint arXiv:2404.10318, 2024, doi: 10.48550/arXiv.2404.10318
-
[9]
S2Gaussian: Sparse-View Super-Resolution 3D Gaussian Splatting,
Y . Wan, M. Shao, Y . Cheng, and W. Zuo, “S2Gaussian: Sparse-View Super-Resolution 3D Gaussian Splatting,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025, pp. 711–721
2025
-
[10]
MPGS: Multi-Plane Gaus- sian Splatting for Compact Scenes Rendering,
D. Li, S.-S. Huang, and H. Huang, “MPGS: Multi-Plane Gaus- sian Splatting for Compact Scenes Rendering,”IEEE Trans. Vis. Comput. Graph., vol. 31, no. 5, pp. 3256–3266, 2025, doi: 10.1109/TVCG.2025.3549551
-
[11]
Fov- GS: Foveated 3D Gaussian Splatting for Dynamic Scenes,
R. Fan, J. Wu, X. Shi, L. Zhao, Q. Ma, and L. Wang, “Fov- GS: Foveated 3D Gaussian Splatting for Dynamic Scenes,”IEEE Trans. Vis. Comput. Graph., vol. 31, no. 5, pp. 2975–2985, 2025, doi: 10.1109/TVCG.2025.3549576
-
[12]
FISN: FInding Spatial Neighborhoods for Generalizable Novel View Synthesis,
Y . Bao, T. Ding, J. Huo, W. Li, and Y . Gao, “FISN: FInding Spatial Neighborhoods for Generalizable Novel View Synthesis,” IEEE Trans. Vis. Comput. Graph., pp. 1–17, 2026
2026
-
[13]
GeoTexDensifier: Geometry-Texture-Aware Densification for High-Quality Photorealistic 3D Gaussian Splatting,
H. Jiang, X. Xiang, H. Sun, H. Li, L. Zhou, X. Zhang, and G. Zhang, “GeoTexDensifier: Geometry-Texture-Aware Densification for High-Quality Photorealistic 3D Gaussian Splatting,”IEEE Trans. Vis. Comput. Graph., vol. 32, no. 3, pp. 2671–2683, 2026
2026
-
[14]
LeOp-GS: Learned Optimizer with Dynamic Gradient Update for Sparse- View 3DGS,
X. Lei, X. Wang, L. Liu, H. Li, and H. Zhang, “LeOp-GS: Learned Optimizer with Dynamic Gradient Update for Sparse- View 3DGS,”IEEE Trans. Vis. Comput. Graph., vol. 31, no. 12, pp. 1–15, 2025
2025
-
[15]
SGGS: Semantic-Guided 3D Gaussian Splatting With Adaptive Render- ing,
A. Zhou, L. Wang, J. Li, J. Huang, L. Li, and J. Yao, “SGGS: Semantic-Guided 3D Gaussian Splatting With Adaptive Render- ing,”IEEE Trans. Vis. Comput. Graph., vol. 32, no. 3, pp. 2628– 2644, 2026
2026
-
[16]
Scaffold-GS: Structured 3D Gaussians for View- Adaptive Rendering,
T. Lu et al., “Scaffold-GS: Structured 3D Gaussians for View- Adaptive Rendering,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 20654–20664
2024
-
[17]
GaussianShader: 3D Gaussian Splatting with Shading Functions for Reflective Sur- faces,
Y . Jiang, Z. Tu, X. Gu, S. Zhao, and W. Wang, “GaussianShader: 3D Gaussian Splatting with Shading Functions for Reflective Sur- faces,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 5322–5332
2024
-
[18]
Frequency-Aware Uncertainty Gaussian Splatting for Dynamic Scene Reconstruc- tion,
M. Shao, Y . Qiao, K. Zhang, and L. Meng, “Frequency-Aware Uncertainty Gaussian Splatting for Dynamic Scene Reconstruc- tion,”IEEE Trans. Vis. Comput. Graph., vol. 31, no. 5, pp. 3558– 3568, 2025, doi: 10.1109/TVCG.2025.3549143
-
[19]
Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Re- construction,
Z. Yang, H. Yang, Z. Pan, X. Zhu, and L. Zhang, “Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Re- construction,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 9453–9462
2024
-
[20]
Mip-NeRF: A Multiscale Rep- resentation for Anti-Aliasing Neural Radiance Fields,
J. T. Barron, B. Mildenhall, M. Tancik, P. Hedman, R. Martin- Brualla, and P. P. Srinivasan, “Mip-NeRF: A Multiscale Rep- resentation for Anti-Aliasing Neural Radiance Fields,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2021, pp. 5855–5864
2021
-
[21]
J. T. Barron, B. Mildenhall, D. Verbin, P. P. Srinivasan, and P. Hedman, “Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022, pp. 5470–5479, doi: 10.1109/CVPR52688.2022.00539
-
[22]
2D Gaussian Splatting for Geometrically Accurate Radiance Fields,
B. Huang, Z. Yu, A. Chen, A. Geiger, and S. Gao, “2D Gaussian Splatting for Geometrically Accurate Radiance Fields,”ACM Trans. Graph., vol. 43, no. 4, pp. 1–11, 2024
2024
-
[23]
Mip- Splatting: Alias-Free 3D Gaussian Splatting,
Z. Yu, A. Chen, B. Huang, T. Sattler, and A. Geiger, “Mip- Splatting: Alias-Free 3D Gaussian Splatting,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 19447– 19456
2024
-
[24]
Learning a Deep Convolutional Network for Image Super-Resolution,
C. Dong, C. C. Loy, K. He, and X. Tang, “Learning a Deep Convolutional Network for Image Super-Resolution,” inProc. Eur. Conf. Comput. Vis. (ECCV), 2014, pp. 184–199
2014
-
[25]
Enhanced Deep Residual Networks for Single Image Super-Resolution,
B. Lim, S. Son, H. Kim, S. Nah, and K. M. Lee, “Enhanced Deep Residual Networks for Single Image Super-Resolution,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), 2017, pp. 1132–1140
2017
-
[26]
Image Super-Resolution Using Very Deep Residual Channel Attention Networks,
Y . Zhang, K. Li, K. Li, L. Wang, B. Zhong, and Y . Fu, “Image Super-Resolution Using Very Deep Residual Channel Attention Networks,” inProc. Eur. Conf. Comput. Vis. (ECCV), 2018, pp. 286–301
2018
-
[27]
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network,
C. Ledig et al., “Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2017, pp. 105–114
2017
-
[28]
Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data,
X. Wang, L. Xie, C. Dong, and Y . Shan, “Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2021, pp. 1905–1914
2021
-
[29]
SwinIR: Image Restoration Using Swin Transformer,
J. Liang, J. Cao, G. Sun, K. Zhang, L. Van Gool, and R. Timofte, “SwinIR: Image Restoration Using Swin Transformer,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2021, pp. 1833–1844
2021
-
[30]
Designing a Practical Degradation Model for Deep Blind Image Super- Resolution,
K. Zhang, J. Liang, L. Van Gool, and R. Timofte, “Designing a Practical Degradation Model for Deep Blind Image Super- Resolution,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2021, pp. 4791–4800
2021
-
[31]
GaussianSR: 3D Gaus- sian Super-Resolution with 2D Diffusion Priors,
X. Yu, H. Zhu, T. He, and Z. Chen, “GaussianSR: 3D Gaus- sian Super-Resolution with 2D Diffusion Priors,”arXiv preprint arXiv:2406.10111, 2024
-
[32]
SuperGaussian: Repurposing Video Models for 3D Super Resolution,
Y . Shen, D. Ceylan, P. Guerrero, Z. Xu, N. J. Mitra, S. Wang, and A. Fr¨uhst¨uck, “SuperGaussian: Repurposing Video Models for 3D Super Resolution,”arXiv preprint arXiv:2406.00609, 2024
-
[33]
Sequence Matters: Harnessing Video Models in 3D Super-Resolution,
H. Ko, D. Park, Y . Park, B. Lee, J. Han, and E. Park, “Sequence Matters: Harnessing Video Models in 3D Super-Resolution,” in Proc. AAAI Conf. Artif. Intell., vol. 39, no. 4, 2025, pp. 3683– 3691, doi: 10.1609/aaai.v39i4.32458
-
[34]
SplatSuRe: Selective Super-Resolution for Multi-view Consistent 3D Gaussian Splatting
P. Asthana, A. Hanson, A. Tu, T. Goldstein, M. Zwicker, and A. Varshney, “SplatSuRe: Selective Super-Resolution for Multi-view Consistent 3D Gaussian Splatting,”arXiv preprint arXiv:2512.02172, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
FreGS: 3D Gaussian Splatting with Progressive Frequency Regularization,
J. Zhang, F. Zhan, M. Xu, S. Lu, and E. Xing, “FreGS: 3D Gaussian Splatting with Progressive Frequency Regularization,” arXiv preprint arXiv:2403.06908, 2024
-
[36]
Frequency-Aware Gaussian Splatting Decomposition,
Y . Lavi, L. Segre, and S. Avidan, “Frequency-Aware Gaussian Splatting Decomposition,”arXiv preprint arXiv:2503.21226, 2025
-
[37]
Tanks and Temples: Benchmarking Large-Scale Scene Reconstruction,
A. Knapitsch, J. Park, Q.Y . Zhou, and V . Koltun, “Tanks and Temples: Benchmarking Large-Scale Scene Reconstruction,” ACM Trans. Graph., vol. 36, no. 4, pp. 78:1–78:13, 2017, doi: 10.1145/3072959.3073599
-
[38]
Deep Blending for Free-Viewpoint Image-Based Rendering,
P. Hedman, J. Philip, T. Price, J. M. Frahm, G. Drettakis, and G. Brostow, “Deep Blending for Free-Viewpoint Image-Based Rendering,”ACM Trans. Graph., vol. 37, no. 6, pp. 257:1–257:15, 2018, doi: 10.1145/3272127.3275084
-
[39]
Structure-from-Motion Revis- ited,
J. L. Sch ¨onberger and J. Frahm, “Structure-from-Motion Revis- ited,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2016, pp. 4104–4113. JOURNAL OF LATEX CLASS FILES, VOL.XX X, NO. X, XXXX 202X 15
2016
-
[40]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018, pp. 586–595
2018
-
[41]
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium,” inAdv. Neural Inf. Process. Syst., vol. 30, 2017, pp. 6629–6640
2017
-
[42]
Rethinking FID: Towards a Better Evaluation Metric for Image Generation,
S. Jayasumana, S. Ramalingam, A. Veit, D. Glasner, A. Chakrabarti, and S. Kumar, “Rethinking FID: Towards a Better Evaluation Metric for Image Generation,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024
2024
-
[43]
DreamSim: Learning New Dimensions of Human Visual Similarity using Synthetic Data,
S. Fu, N. Tamir, S. Sundaram, L. Chai, R. Zhang, T. Dekel, and P. Isola, “DreamSim: Learning New Dimensions of Human Visual Similarity using Synthetic Data,” inAdv. Neural Inf. Process. Syst., 2023
2023
-
[44]
MUSIQ: Multi-scale Image Quality Transformer,
J. Ke, Q. Wang, Y . Wang, P. Milanfar, and F. Yang, “MUSIQ: Multi-scale Image Quality Transformer,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2021, pp. 3575–3585
2021
-
[45]
Making a ‘Com- pletely Blind’ Image Quality Analyzer,
A. Mittal, R. Soundararajan, and A. C. Bovik, “Making a ‘Com- pletely Blind’ Image Quality Analyzer,”IEEE Signal Process. Lett., vol. 20, no. 3, pp. 209–212, Mar. 2013
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.