ParkingWorld: End-to-End Autonomous Parking Reinforcement Learning from Corrective Experience in 3DGS Simulation
Pith reviewed 2026-06-30 00:23 UTC · model grok-4.3
The pith
A correction-in-the-loop RL framework with multi-level replay buffers, trained in a 3DGS simulator, improves autonomous parking success, efficiency, and safety with direct transfer to physical vehicles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
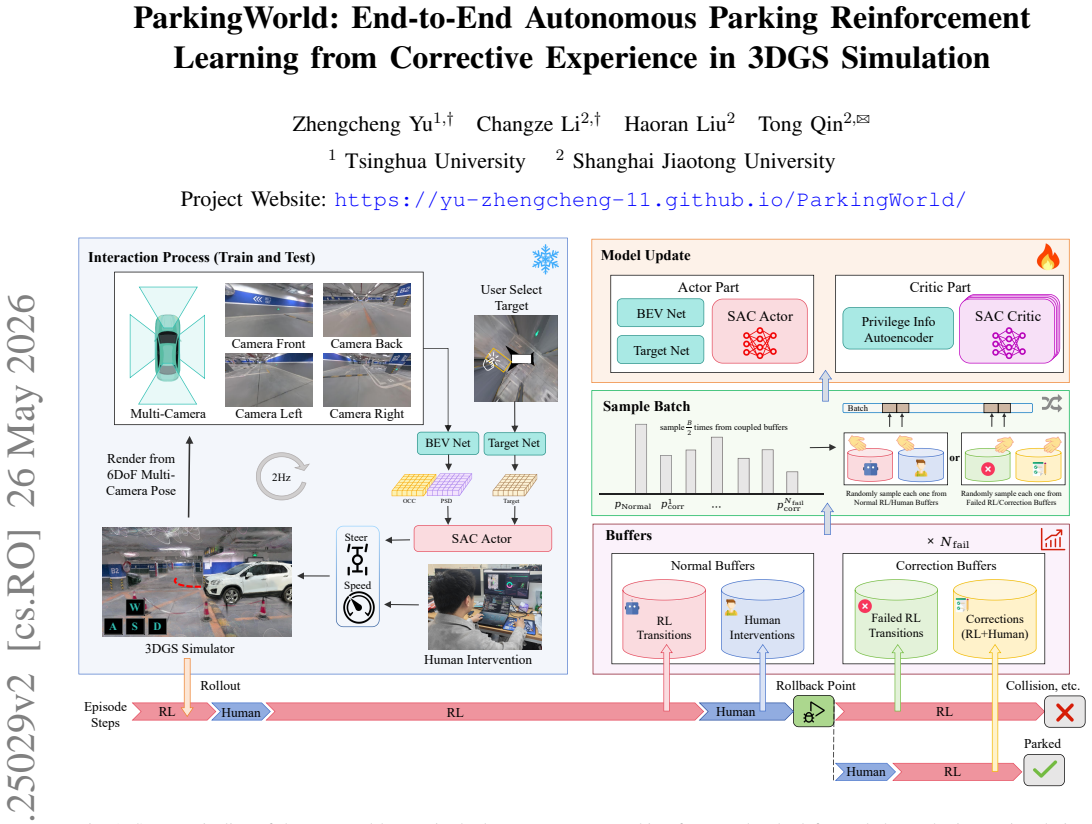
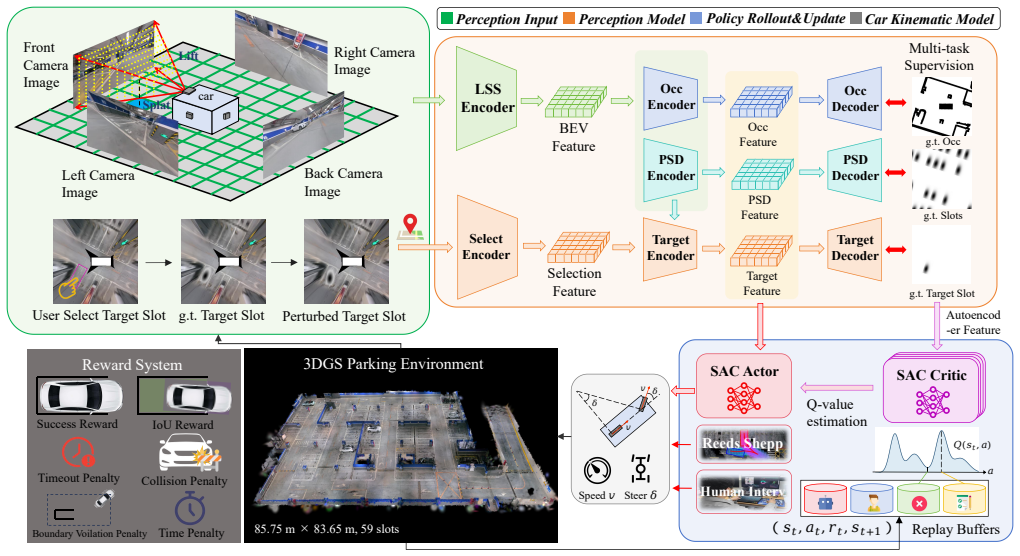
The CIL-SERL framework, built around a multi-level replay buffer that hierarchically organizes standard RL rollouts, human corrective interventions, failed exploration trajectories, and rollback-based correction segments, when trained end-to-end in a 3D Gaussian Splatting parking simulator, produces policies that achieve substantial improvements in parking success rate, operational efficiency, and safety performance across diverse scenarios while supporting direct transfer to a physical vehicle platform.
What carries the argument
The multi-level replay buffer mechanism inside the CIL-SERL framework, which stores and samples from four distinct trajectory types to enable structured, targeted learning from corrective experience.
If this is right
- Parking success rate rises across diverse narrow and cluttered scenarios.
- Operational efficiency improves through reduced time and smoother trajectories.
- Safety performance increases by lowering collision and boundary-violation rates.
- Learned policies transfer directly from the 3DGS simulator to a real vehicle platform.
- The method reduces reliance on massive volumes of expert demonstrations required by imitation learning.
Where Pith is reading between the lines
- The same corrective-experience buffer structure could be applied to other constrained low-speed tasks such as docking or tight navigation.
- Human interventions logged during real-world failures could be fed back into the simulator to further close the sim-to-real gap.
- The framework might lower overall training compute by focusing learning on correction segments rather than uniform random exploration.
- Extending the buffer hierarchy to include sensor-specific failure modes could improve robustness to perception noise.
Load-bearing premise
The photorealistic 3D Gaussian Splatting parking simulator produces reconstructions faithful enough that policies trained inside it transfer directly to a physical vehicle without performance loss.
What would settle it
Deploying the trained policy on the physical vehicle and measuring a large drop in success rate or safety metrics compared with simulation results would falsify the transfer claim.
Figures
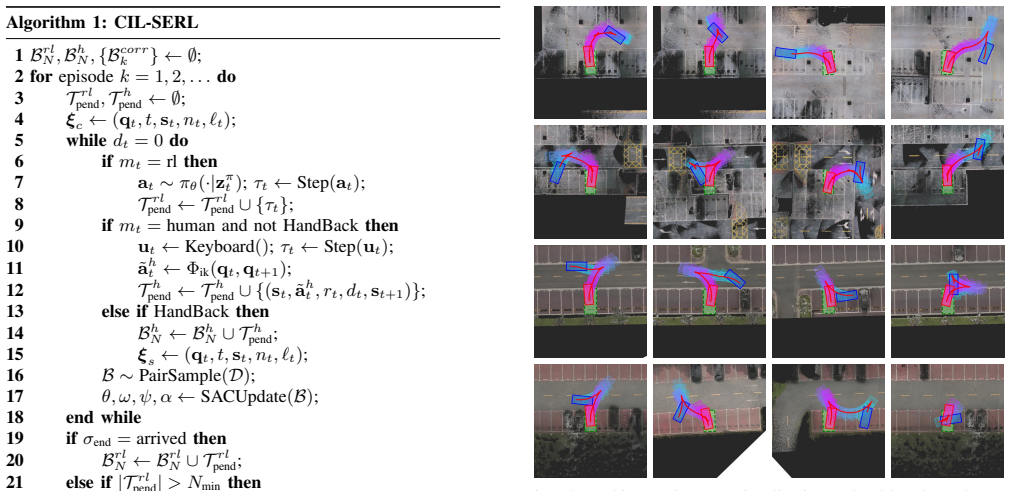
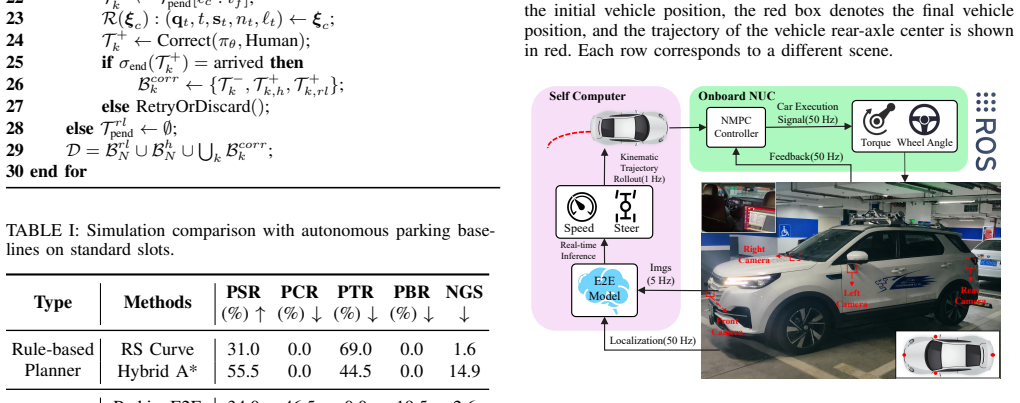
read the original abstract
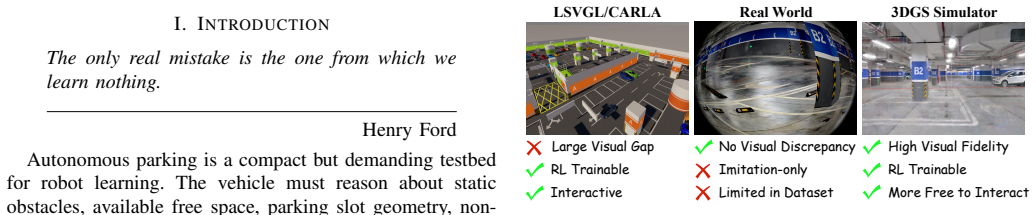
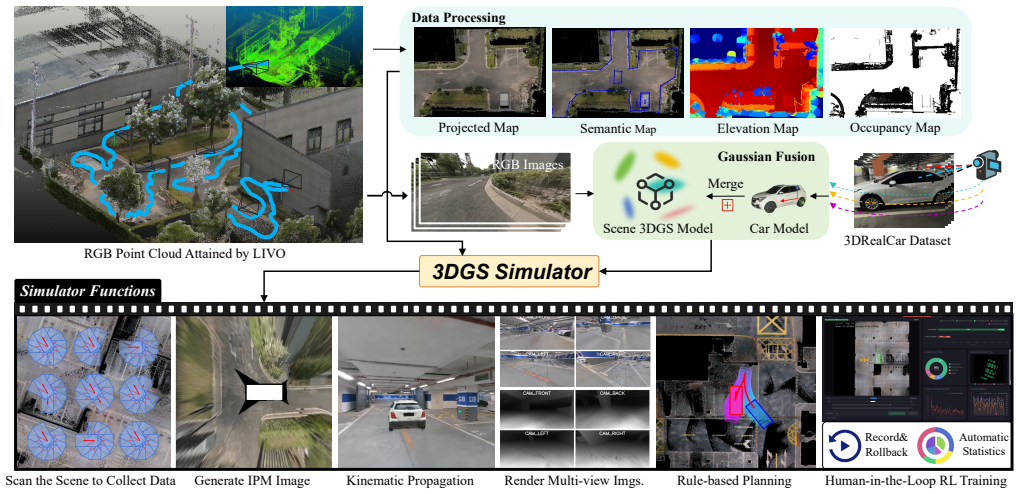
Autonomous parking demands precise low-speed maneuvering within narrow, cluttered, and highly constrained environments, where vehicles must navigate tight spaces while avoiding static obstacles and complex geometric boundaries. Unlike imitation learning, which typically requires massive volumes of high-quality expert demonstrations to converge to a stable policy and often suffers from limited generalization to unseen scenarios, traditional reinforcement learning (RL) methods face persistent challenges including excessive training overhead, inefficient exploration, and even failure to learn viable parking strategies in challenging settings. To address these limitations, this paper presents a correction-in-the-loop sample-efficient reinforcement learning (CIL-SERL) framework for end-to-end autonomous parking, which is entirely trained in a photorealistic 3D Gaussian Splatting (3DGS) parking simulator that enables high-fidelity digital reconstruction of real-world scenes. Inspired by error-correction notebooks used in learning practice, we design a novel multi-level replay buffer mechanism. These buffers hierarchically organize and store standard RL rollouts, human corrective interventions, failed exploration trajectories, and rollback-based correction segments in separate yet interconnected memory regions, facilitating structured sampling and targeted learning during training. The proposed framework is systematically evaluated in both the 3DGS simulation environment and a physical vehicle platform. Extensive experimental results demonstrate that our method achieves substantial improvements in parking success rate, operational efficiency, and safety performance across diverse scenarios, validating the effectiveness and practical applicability of the proposed CIL-SERL-based end-to-end autonomous parking solution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a correction-in-the-loop sample-efficient reinforcement learning (CIL-SERL) framework for end-to-end autonomous parking. It trains policies entirely in a photorealistic 3D Gaussian Splatting (3DGS) simulator using a novel multi-level replay buffer that stores and samples from standard RL rollouts, human corrective interventions, failed trajectories, and rollback corrections. The framework is evaluated in both the simulator and on a physical vehicle platform, with the abstract claiming substantial improvements in parking success rate, operational efficiency, and safety across diverse scenarios.
Significance. If the quantitative results and sim-to-real transfer hold, the work could advance sample-efficient RL for robotics by structuring corrective experience in constrained low-speed maneuvering tasks. The multi-level buffer and 3DGS simulator offer a concrete approach to incorporating human feedback and high-fidelity reconstruction, which may improve generalization over standard imitation or RL baselines in parking scenarios.
major comments (2)
- [Abstract] Abstract: The central claim of 'substantial improvements in parking success rate, operational efficiency, and safety performance' is asserted without any quantitative results, baselines, error bars, trial counts, or statistical tests. This absence prevents assessment of the effectiveness and practical applicability conclusions.
- [Abstract] Abstract: The practical applicability conclusion depends on successful direct transfer from the 3DGS simulator to a physical vehicle with only the multi-level replay buffer. No sim-to-real gap metrics, domain randomization details, real-world trial statistics, or ablations isolating 3DGS fidelity are supplied, which is load-bearing for the claim.
minor comments (1)
- [Abstract] Abstract: The description of how the multi-level replay buffer 'hierarchically organize[s] and store[s]' different trajectory types could be clarified with a diagram or pseudocode to show sampling mechanics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that the abstract should more explicitly support its claims with quantitative details and sim-to-real information. We will revise the abstract accordingly in the next version while preserving its concise nature.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'substantial improvements in parking success rate, operational efficiency, and safety performance' is asserted without any quantitative results, baselines, error bars, trial counts, or statistical tests. This absence prevents assessment of the effectiveness and practical applicability conclusions.
Authors: We agree that the abstract would benefit from quantitative support. The full manuscript reports these metrics (success rates, efficiency, safety) with baselines and trial counts in the experiments section. In revision we will condense the key numbers, baseline comparisons, and trial counts into the abstract to directly substantiate the claims. revision: yes
-
Referee: [Abstract] Abstract: The practical applicability conclusion depends on successful direct transfer from the 3DGS simulator to a physical vehicle with only the multi-level replay buffer. No sim-to-real gap metrics, domain randomization details, real-world trial statistics, or ablations isolating 3DGS fidelity are supplied, which is load-bearing for the claim.
Authors: The manuscript evaluates the policy on the physical vehicle after 3DGS training and reports real-world success. We acknowledge the abstract currently omits explicit sim-to-real gap numbers and trial statistics. In revision we will add a concise statement of real-world trial counts and transfer outcome to the abstract; domain-randomization and 3DGS-specific ablations remain in the main experimental section as they exceed abstract length limits. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The manuscript contains no equations, derivations, fitted parameters, or mathematical claims that reduce to inputs by construction. The central claims rest on experimental results in simulation and on a physical platform, with the 3DGS simulator described as an enabling tool rather than a self-referential fit. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results appear in the provided text. The sim-to-real transfer assertion is an empirical claim whose validity is external to any derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Carla: An open urban driving simulator,
A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V . Koltun, “Carla: An open urban driving simulator,” inConference on robot learning. PMLR, 2017, pp. 1–16
2017
-
[2]
Lgsvl simulator: A high fidelity simulator for autonomous driving,
G. Rong, B. H. Shin, H. Tabatabaee, Q. Lu, S. Lemke, M. Mo ˇzeiko, E. Boise, G. Uhm, M. Gerow, S. Mehta,et al., “Lgsvl simulator: A high fidelity simulator for autonomous driving,” in2020 IEEE 23rd International conference on intelligent transportation systems (ITSC). IEEE, 2020, pp. 1–6
2020
-
[3]
3d gaussian splatting for real-time radiance field rendering
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering.”ACM Trans. Graph., vol. 42, no. 4, pp. 139–1, 2023
2023
-
[4]
C. Li, Z. Chen, S. Chen, L. Mu, Y . Li, Y . Yu, Q. Zhang, Q. Su, M. Yang, and T. Qin, “Reap: Reinforcement-learning end-to-end au- tonomous parking with gaussian splatting simulator for real2sim2real transfer,”arXiv preprint arXiv:2605.08713, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Soft Actor-Critic Algorithms and Applications
T. Haarnoja, A. Zhou, K. Hartikainen, G. Tucker, S. Ha, J. Tan, V . Kumar, H. Zhu, A. Gupta, P. Abbeel,et al., “Soft actor-critic algorithms and applications,”arXiv preprint arXiv:1812.05905, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
E2e parking: Autonomous parking by the end-to-end neural network on the carla simulator,
Y . Yang, D. Chen, T. Qin, X. Mu, C. Xu, and M. Yang, “E2e parking: Autonomous parking by the end-to-end neural network on the carla simulator,” in2024 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2024, pp. 2375–2382
2024
-
[7]
Parkinge2e: Camera- based end-to-end parking network, from images to planning,
C. Li, Z. Ji, Z. Chen, T. Qin, and M. Yang, “Parkinge2e: Camera- based end-to-end parking network, from images to planning,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 13 206–13 212
2024
-
[8]
Reinforcement learning-based autonomous parking with expert demonstrations,
Y . Wu, L. Wang, X. Lu, Y . Wu, and H. Zhang, “Reinforcement learning-based autonomous parking with expert demonstrations,” in 2023 7th CAA International Conference on Vehicular Control and Intelligence (CVCI). IEEE, 2023, pp. 1–6
2023
-
[9]
Hope: A reinforcement learning-based hybrid policy path planner for diverse parking scenarios,
M. Jiang, Y . Li, S. Zhang, S. Chen, C. Wang, and M. Yang, “Hope: A reinforcement learning-based hybrid policy path planner for diverse parking scenarios,”IEEE Transactions on Intelligent Transportation Systems, 2025
2025
-
[10]
Rad: Training an end-to-end driving policy via large-scale 3dgs-based reinforcement learning,
H. Gao, S. Chen, B. Jiang, B. Liao, Y . Shi, X. Guo, Y . Pu, H. Yin, X. Li, X. Zhang,et al., “Rad: Training an end-to-end driving policy via large-scale 3dgs-based reinforcement learning,”arXiv preprint arXiv:2502.13144, 2025
-
[11]
Flying in clutter on monocular rgb by learning in 3d radiance fields with domain adaptation,
X. Huang, J. Li, T. Wu, X. Zhou, Z. Han, and F. Gao, “Flying in clutter on monocular rgb by learning in 3d radiance fields with domain adaptation,”IEEE Robotics and Automation Letters, 2026
2026
-
[12]
Vr- robo: A real-to-sim-to-real framework for visual robot navigation and locomotion,
S. Zhu, L. Mou, D. Li, B. Ye, R. Huang, and H. Zhao, “Vr- robo: A real-to-sim-to-real framework for visual robot navigation and locomotion,”IEEE Robotics and Automation Letters, 2025
2025
-
[13]
Safety-aware human-in- the-loop reinforcement learning with shared control for autonomous driving,
W. Huang, H. Liu, Z. Huang, and C. Lv, “Safety-aware human-in- the-loop reinforcement learning with shared control for autonomous driving,”IEEE Transactions on Intelligent Transportation Systems, vol. 25, no. 11, pp. 16 181–16 192, 2024
2024
-
[14]
From learning to mastery: Achieving safe and efficient real-world autonomous driving with human-in-the-loop reinforcement learning,
Z. Li, Y . Wang, H. Wang, Z. Li, P. Li, W. Liu, and Z. Zuo, “From learning to mastery: Achieving safe and efficient real-world autonomous driving with human-in-the-loop reinforcement learning,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 7925–7932
2025
-
[15]
Precise and dexterous robotic manipulation via human-in-the-loop reinforcement learning,
J. Luo, C. Xu, J. Wu, and S. Levine, “Precise and dexterous robotic manipulation via human-in-the-loop reinforcement learning,”Science Robotics, vol. 10, no. 105, p. eads5033, 2025
2025
-
[16]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
P. Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, et al., “π ∗ 0.6: a vla that learns from experience,”arXiv preprint arXiv:2511.14759, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Fast-livo2: Fast, direct lidar-inertial-visual odometry,
C. Zheng, W. Xu, Z. Zou, T. Hua, C. Yuan, D. He, B. Zhou, Z. Liu, J. Lin, F. Zhu,et al., “Fast-livo2: Fast, direct lidar-inertial-visual odometry,”IEEE Transactions on Robotics, 2024
2024
-
[18]
3drealcar: An in-the-wild rgb-d car dataset with 360-degree views,
X. Du, Y . Wang, H. Sun, Z. Wu, H. Sheng, S. Wang, J. Ying, M. Lu, T. Zhu, K. Zhan,et al., “3drealcar: An in-the-wild rgb-d car dataset with 360-degree views,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 26 488–26 498
2025
-
[19]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,
J. Philion and S. Fidler, “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,” inEuropean conference on computer vision. Springer, 2020, pp. 194–210
2020
-
[20]
Efficient online reinforcement learning with offline data,
P. J. Ball, L. Smith, I. Kostrikov, and S. Levine, “Efficient online reinforcement learning with offline data,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 1577–1594. APPENDIX A. Reward Design The reward function combines sparse terminal feedback with dense stepwise guidance. Sparse terms define the task outcome, including successful p...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.