Multimodality Stacking with Blockwise missing values and application to the PIONeeR biomarkers study for prediction of resistance to immunotherapy
Pith reviewed 2026-06-29 23:44 UTC · model grok-4.3
The pith
A late-fusion stacking method improves survival prediction on multimodal cancer data with entire missing biomarker blocks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
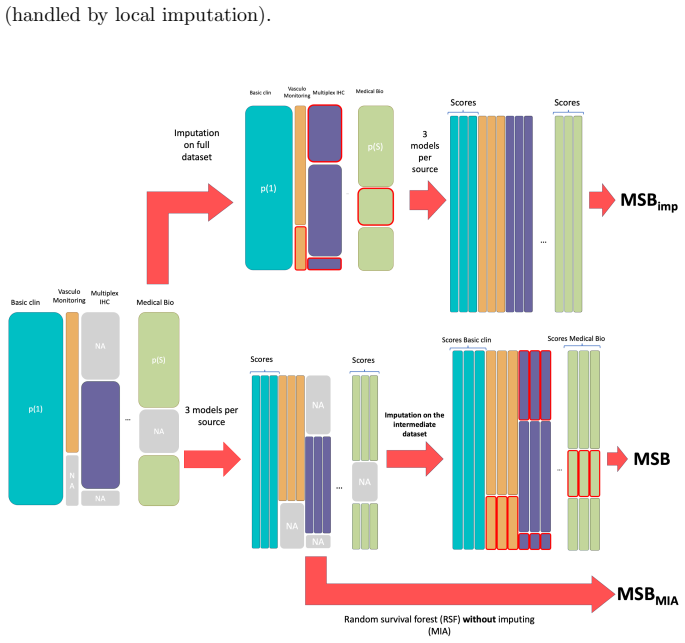
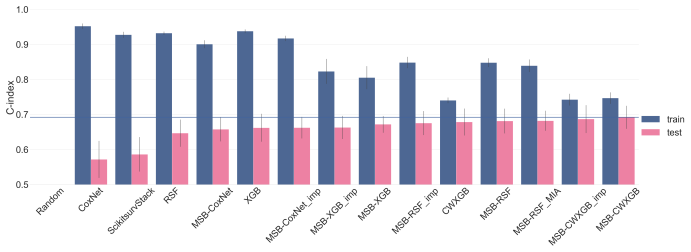
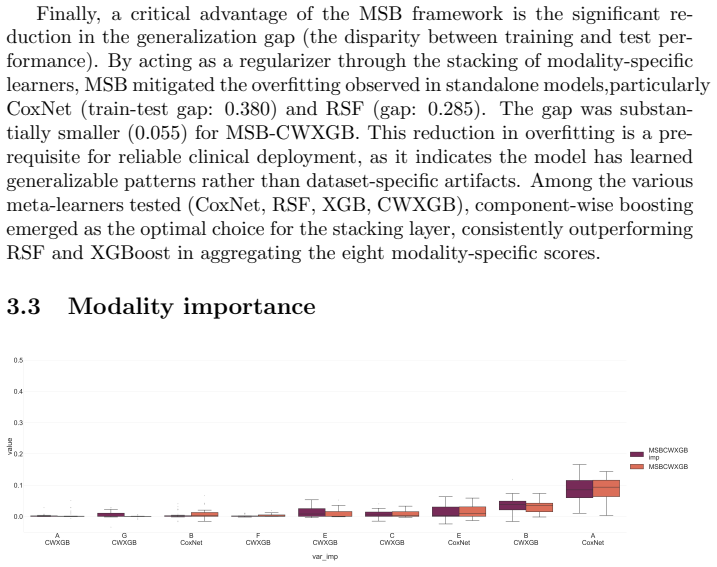
MSB is a late-fusion framework for survival analysis that independently models modality-specific features before aggregating predictions via a cross-validated stacking meta-learner. Applied to the PIONeeR study, it produced higher C-index values than baseline algorithms, with relative gains of 15.9 percent for linear models, 5.4 percent for random survival forests, and 2.1 percent for gradient boosting methods; it also reduced the generalization gap between train and test folds. Permutation importance showed that missing-block indicators carried negligible weight, indicating that predictions were driven by the observed biomarker values themselves.
What carries the argument
The cross-validated stacking meta-learner that aggregates modality-specific survival predictions while tolerating blockwise missingness.
If this is right
- Linear survival models receive larger relative gains from MSB than stronger tree-based or boosting baselines.
- Routine laboratory markers, clinical features, and PD-L1 expression remain the dominant predictors once modalities are stacked.
- The generalization gap between training and held-out performance narrows when stacking is used.
- All patients can be retained for analysis without requiring complete data across every modality.
Where Pith is reading between the lines
- The same late-fusion structure could be applied to other clinical tasks that combine heterogeneous data sources with blockwise missingness.
- External validation on separate patient cohorts would be required to establish whether the observed gains hold outside the PIONeeR study.
- The framework might reduce reliance on imputation techniques that can themselves introduce bias.
- Inclusion of additional modalities would be straightforward provided each modality can be modeled independently first.
Load-bearing premise
The stacking meta-learner combines predictions on the basis of the actual biomarker values rather than on the pattern of which data blocks are missing for each patient.
What would settle it
On an independent cohort, if the permutation importance of missing-block indicators rises above negligible levels or if the reported C-index gains disappear, the claim that the meta-learner learns from values rather than missingness patterns would be refuted.
Figures
read the original abstract
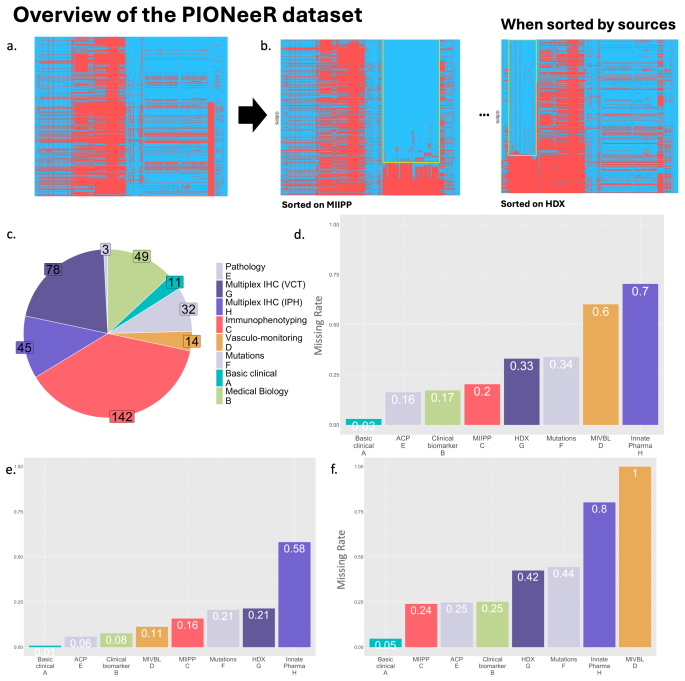
Integrating multimodal datasets in clinical oncology is frequently hindered by high dimensionality and blockwise missingness, where entire data sources are unavailable for specific patient subsets. Standard survival models often struggle with these gaps, leading to biased results or patient exclusion. We introduce Multimodality Stacking with Blockwise missing values (MSB), a late-fusion framework for survival analysis that independently models modality-specific features before aggregating predictions via a cross-validated stacking meta-learner. MSB was validated on the PIONeeR study (n=443 patients, 378 biomarkers across eight heterogeneous sources) to predict progression-free survival in advanced non-small cell lung cancer patients receiving immunotherapy. MSB yielded higher predictive performance (C-index) than baseline algorithms. Improvements varied by baseline strength: linear models showed a 15.9% increase (p<0.001 for the Wilcoxon signed-rank test), random survival forests gained 5.4% (p=0.002), and gradient boosting methods improved by 2.1% (p=0.030). Beyond discrimination, MSB reduced the generalization gap (train-test difference in 5 folds cross-validation repeated 3 times: 0.055 vs 0.380 for linear models). Permutation importance analysis identified routine laboratory markers, clinical features, and PD-L1 expression as primary predictive drivers. Missing block indicators showed negligible importance, suggesting the model learned from biomarker values rather than data availability patterns. MSB provides a statistically validated framework for multimodal survival prediction with blockwise missingness. By enabling systematic biomarker evaluation without requiring complete data, MSB offers a practical tool for predictive modeling in biomedical research, pending external validation. Implementation is available at https://github.com/MohamedBoussena/MSB under Inria license.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Multimodality Stacking with Blockwise missing values (MSB), a late-fusion survival modeling framework that fits modality-specific base learners and aggregates their predictions via a cross-validated stacking meta-learner. Applied to the PIONeeR cohort (n=443 patients, 378 biomarkers from eight sources) for progression-free survival prediction under immunotherapy, MSB is reported to improve C-index over linear, random survival forest, and gradient boosting baselines (gains of 15.9%, 5.4%, and 2.1% respectively, with Wilcoxon p-values), reduce the train-test generalization gap, and identify routine labs, clinical features, and PD-L1 as top predictors while assigning negligible importance to explicit missing-block indicators.
Significance. If the reported gains reflect genuine multimodal signal aggregation rather than artifacts of missingness patterns, MSB would provide a practical, late-fusion tool for survival modeling with blockwise missing multimodal data, a common issue in oncology cohorts. The open-source implementation and explicit comparison of generalization gaps are strengths that could aid adoption. The significance is limited by incomplete demonstration that performance improvements are independent of informative missingness.
major comments (2)
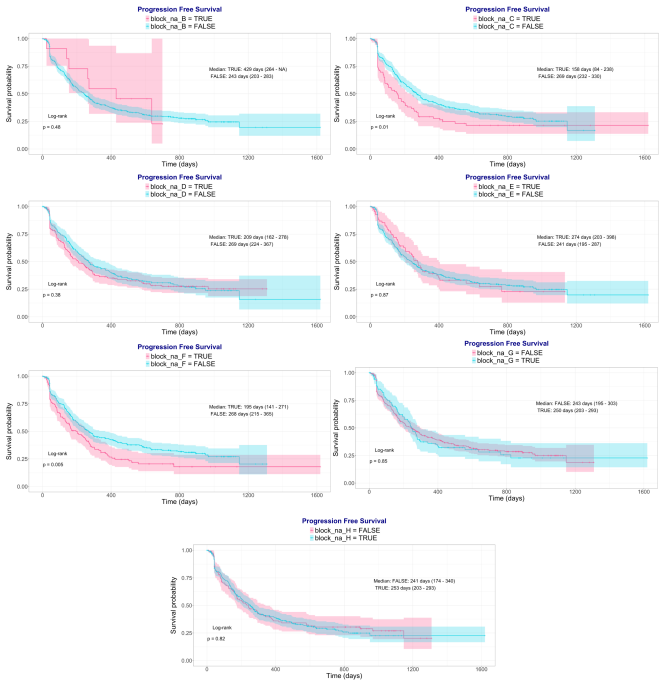
- [Abstract] Abstract: The assertion that the model learned from biomarker values rather than data availability patterns is supported only by the negligible permutation importance of explicit missing-block indicators. This does not address whether the meta-learner indirectly exploits missingness through systematic patterns in the base-model prediction vector (e.g., default outputs, imputations, or dropped models when a modality block is absent), which remains a plausible explanation for both the C-index gains and the reduced generalization gap in the PIONeeR cohort where missingness may be clinically informative.
- [Methods] Methods (cross-validation and base-learner description): The manuscript provides insufficient detail on the specific base learners chosen per modality, hyperparameter tuning, the precise nested cross-validation scheme used for the stacking meta-learner, and the exact mechanism by which blockwise missing values are handled inside each base model. These omissions prevent assessment of data leakage risk and reproducibility of the reported C-index differences and associated p-values.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript on the MSB framework. We have carefully addressed each major comment below. Where the comments identify areas requiring greater clarity or qualification, we agree and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] The assertion that the model learned from biomarker values rather than data availability patterns is supported only by the negligible permutation importance of explicit missing-block indicators. This does not address whether the meta-learner indirectly exploits missingness through systematic patterns in the base-model prediction vector (e.g., default outputs, imputations, or dropped models when a modality block is absent), which remains a plausible explanation for both the C-index gains and the reduced generalization gap in the PIONeeR cohort where missingness may be clinically informative.
Authors: We agree that the permutation importance analysis of explicit missing-block indicators provides only indirect support and does not fully rule out the possibility that the meta-learner could exploit systematic patterns in the base-learner prediction vectors that correlate with missingness. In the revised manuscript we will qualify the relevant sentence in the abstract and add a short paragraph in the Discussion section acknowledging this limitation and noting that dedicated ablation experiments on the prediction vectors would be needed to investigate it further. The core methodological contribution of MSB as a late-fusion approach remains unchanged. revision: yes
-
Referee: [Methods] The manuscript provides insufficient detail on the specific base learners chosen per modality, hyperparameter tuning, the precise nested cross-validation scheme used for the stacking meta-learner, and the exact mechanism by which blockwise missing values are handled inside each base model. These omissions prevent assessment of data leakage risk and reproducibility of the reported C-index differences and associated p-values.
Authors: We acknowledge that the original Methods section lacked the level of detail required for full reproducibility and leakage assessment. In the revised manuscript we will expand the Methods section to explicitly describe: the base learner type and configuration used for each of the eight modalities, the hyperparameter search procedure and ranges, the precise nested cross-validation design (outer folds for performance estimation and inner folds for meta-learner training), and the exact rule applied when a modality block is missing for a given patient (e.g., whether the corresponding base model is omitted from the prediction vector or a default is substituted). These additions will also allow readers to evaluate potential data leakage. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces MSB as a late-fusion stacking method and reports empirical C-index gains plus permutation importance results on the external PIONeeR cohort via repeated cross-validation. No equations, derivations, or self-citations reduce the performance claims to quantities defined by the authors' own fitted parameters or by construction. The central validation rests on standard statistical procedures applied to held-out data rather than any of the enumerated circular patterns (self-definitional, fitted-input-called-prediction, load-bearing self-citation, etc.). The skeptic concern about indirect missingness encoding is a potential correctness or validation gap, not a circularity reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Censoring is non-informative given the observed covariates
Reference graph
Works this paper leans on
-
[1]
P52 - Survival models: Proper scoring rule and stochastic optimization with competing risks
J. Alberge et al. “P52 - Survival models: Proper scoring rule and stochastic optimization with competing risks”. In:Journal of Epidemiology and Pop- ulation Health. EPICLIN 2025, 19` eme Conf´ erence francophone d’´Epid´ emiologie Clinique et 32` emes Journ´ ees des Statisticiens des Centres de Lutte Contre le Cancer, Bordeaux, France, 14-16 mai 2025 73 (...
-
[2]
Permutation importance: a corrected feature im- portance measure
Andr´ e Altmann et al. “Permutation importance: a corrected feature im- portance measure”. In:Bioinformatics26.10 (Apr. 2010), pp. 1340–1347. issn: 1367-4803.doi:10.1093/bioinformatics/btq134. eprint:https: / / academic . oup . com / bioinformatics / article - pdf / 26 / 10 / 1340 / 48851160/bioinformatics_26_10_1340.pdf.url:https://doi.org/ 10.1093/bioin...
-
[3]
Anastasiia Bakhmach et al.ROOFS: RObust biOmarker Feature Selection
- [4]
-
[5]
ISSN: 3067-2007 Pages: 2026.01.09.26343779
Fabrice Barlesi et al.An integrative multimodal machine learning signa- ture of primary resistance to immunotherapy in advanced non-small cell lung cancer: biomarker analysis from the PIONeeR study. ISSN: 3067-2007 Pages: 2026.01.09.26343779. Jan. 11, 2026.doi:10.64898/2026.01.09. 26343779.url:https://www.medrxiv.org/content/10.64898/2026. 01.09.26343779v...
-
[6]
Five-Year Outcomes From the Randomized, Phase III Trials CheckMate 017 and 057: Nivolumab Versus Docetaxel in Previ- ously Treated Non-Small-Cell Lung Cancer
Hossein Borghaei et al. “Five-Year Outcomes From the Randomized, Phase III Trials CheckMate 017 and 057: Nivolumab Versus Docetaxel in Previ- ously Treated Non-Small-Cell Lung Cancer”. In:Journal of Clinical On- cology: Official Journal of the American Society of Clinical Oncology39.7 (Mar. 1, 2021), pp. 723–733.issn: 1527-7755.doi:10 . 1200 / JCO . 20 . 01605
2021
-
[7]
Freddie Bray et al. “Global cancer statistics 2022: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries”. In: CA: a cancer journal for clinicians74.3 (2024), pp. 229–263.issn: 1542- 4863.doi:10.3322/caac.21834
-
[8]
Boosting for high-dimensional linear models
Peter B¨ uhlmann. “Boosting for high-dimensional linear models”. In:The Annals of Statistics34.2 (2006), pp. 559–583.doi:10.1214/009053606000000092. url:https://doi.org/10.1214/009053606000000092
-
[9]
API design for machine learning software: experiences from the scikit-learn project
Lars Buitinck et al. “API design for machine learning software: experiences from the scikit-learn project”. In:ECML PKDD Workshop. 2013, pp. 108– 122
2013
-
[10]
van Buuren.Flexible Imputation of Missing Data
S. van Buuren.Flexible Imputation of Missing Data. Second Edition.Boca Raton, FL.: CRC Press, 2018. S31
2018
-
[11]
Nicolas Captier et al. “Integration of clinical, pathological, radiological, and transcriptomic data improves prediction for first-line immunotherapy outcome in metastatic non-small cell lung cancer”. In:Nature Communica- tions16.1 (Jan. 12, 2025), p. 614.issn: 2041-1723.doi:10.1038/s41467- 025-55847-5.url:https://www.nature.com/articles/s41467-025- 55847-5
-
[12]
New response evaluation criteria in solid tumours: Revised RECIST guideline (version 1.1)
E. A. Eisenhauer et al. “New response evaluation criteria in solid tumours: Revised RECIST guideline (version 1.1)”. In:European Journal of Cancer 45.2 (Jan. 1, 2009). Publisher: Elsevier, pp. 228–247.issn: 0959-8049, 1879-0852.doi:10.1016/j.ejca.2008.10.026.url:https://www. ejcancer.com/article/S0959-8049(08)00873-3/abstract
work page doi:10.1016/j.ejca.2008.10.026.url:https://www 2009
-
[13]
Pembrolizumab plus Chemotherapy in Metastatic Non–Small-Cell Lung Cancer
Leena Gandhi et al. “Pembrolizumab plus Chemotherapy in Metastatic Non–Small-Cell Lung Cancer”. In:New England Journal of Medicine378.22 (May 31, 2018). Publisher: Massachusetts Medical Society, pp. 2078–2092. issn: 0028-4793.doi:10.1056/NEJMoa1801005.url:https://www.nejm. org/doi/full/10.1056/NEJMoa1801005
work page doi:10.1056/nejmoa1801005.url:https://www.nejm 2018
-
[14]
Marina C. Garassino et al. “Pembrolizumab Plus Pemetrexed and Plat- inum in Nonsquamous Non-Small-Cell Lung Cancer: 5-Year Outcomes From the Phase 3 KEYNOTE-189 Study”. In:Journal of Clinical Oncol- ogy: Official Journal of the American Society of Clinical Oncology41.11 (Apr. 10, 2023), pp. 1992–1998.issn: 1527-7755.doi:10.1200/JCO.22. 01989
-
[15]
Multiple Kernel Learning Algo- rithms
Mehmet G¨ onen and Ethem Alpaydin. “Multiple Kernel Learning Algo- rithms”. In:Journal of Machine Learning Research12.64 (2011), pp. 2211– 2268.issn: 1533-7928.url:http://jmlr.org/papers/v12/gonen11a. html
2011
-
[16]
Assessment and comparison of prognostic classifica- tion schemes for survival data
Erika Graf et al. “Assessment and comparison of prognostic classifica- tion schemes for survival data”. In:Statistics in Medicine18.17 (1999), pp. 2529–2545.issn: 1097-0258.doi:10.1002/(SICI)1097-0258(19990915/ 30 ) 18 : 17 / 18<2529 :: AID - SIM274 > 3 . 0 . CO ; 2 - 5.url:https : / / onlinelibrary . wiley . com / doi / abs / 10 . 1002 / %28SICI % 291097...
-
[17]
F. E. Harrell, K. L. Lee, and D. B. Mark. “Multivariable prognostic models: issues in developing models, evaluating assumptions and ade- quacy, and measuring and reducing errors”. In:Statistics in Medicine15.4 (Feb. 28, 1996), pp. 361–387.issn: 0277-6715.doi:10.1002/(SICI)1097- 0258(19960229)15:4<361::AID-SIM168>3.0.CO;2-4
-
[18]
HEALNet: Multimodal Fusion for Heterogeneous Biomedical Data
Konstantin Hemker, Nikola Simidjievski, and Mateja Jamnik. “HEALNet: Multimodal Fusion for Heterogeneous Biomedical Data”. In:Advances in Neural Information Processing Systems37 (Dec. 16, 2024), pp. 64479– 64498.url:https://proceedings.neurips.cc/paper_files/paper/ 2024/hash/765871e77d2ca65126d3d64d31aa6908-Abstract-Conference. html. S32
2024
-
[19]
On the consistency of supervised learning with missing values
Julie Josse et al. “On the consistency of supervised learning with missing values”. In:Statistical Papers65.9 (Dec. 1, 2024), pp. 5447–5479.issn: 1613-9798.doi:10.1007/s00362- 024- 01550- 4.url:https://doi. org/10.1007/s00362-024-01550-4
-
[20]
Multimodal survival prediction in advanced pancreatic cancer using machine learning
J. Keyl et al. “Multimodal survival prediction in advanced pancreatic cancer using machine learning”. In:ESMO Open7.5 (Aug. 18, 2022), p. 100555.issn: 2059-7029.doi:10.1016/j.esmoop.2022.100555.url: https://pmc.ncbi.nlm.nih.gov/articles/PMC9588888/
-
[21]
Review of multimodal machine learning approaches in healthcare
Felix Krones et al. “Review of multimodal machine learning approaches in healthcare”. In:Information Fusion114 (Feb. 1, 2025), p. 102690.issn: 1566-2535.doi:10.1016/j.inffus.2024.102690.url:https://www. sciencedirect.com/science/article/pii/S1566253524004688
work page doi:10.1016/j.inffus.2024.102690.url:https://www 2025
-
[22]
Mark J. van der Laan, Eric C. Polley, and Alan E. Hubbard. “Super learner”. In:Statistical Applications in Genetics and Molecular Biology6 (2007), Article25.issn: 1544-6115.doi:10.2202/1544-6115.1309
-
[23]
Imputation of missing values in multi-view data
Wouter van Loon et al. “Imputation of missing values in multi-view data”. In:Information Fusion111 (Nov. 1, 2024), p. 102524.issn: 1566-2535.doi: 10.1016/j.inffus.2024.102524.url:https://www.sciencedirect. com/science/article/pii/S1566253524003026
work page doi:10.1016/j.inffus.2024.102524.url:https://www.sciencedirect 2024
-
[24]
Evaluation of Adaptive Mixtures of Competing Experts
Steven Nowlan and Geoffrey E Hinton. “Evaluation of Adaptive Mixtures of Competing Experts”. In:Advances in Neural Information Processing Systems. Ed. by R.P. Lippmann, J. Moody, and D. Touretzky. Vol. 3. Morgan-Kaufmann, 1990.url:https : / / proceedings . neurips . cc / paper_files/paper/1990/file/432aca3a1e345e339f35a30c8f65edce- Paper.pdf
1990
-
[25]
Benchmarking missing-values approaches for predictive models on health databases
Alexandre Perez-Lebel et al. “Benchmarking missing-values approaches for predictive models on health databases”. In:GigaScience11 (Apr. 2022), giac013.issn: 2047-217X.doi:10.1093/gigascience/giac013. eprint:https://academic.oup.com/gigascience/article- pdf/doi/ 10.1093/gigascience/giac013/60706597/giac013.pdf.url:https: //doi.org/10.1093/gigascience/giac013
-
[26]
scikit-survival: A Library for Time-to-Event Analysis Built on Top of scikit-learn
Sebastian P¨ olsterl. “scikit-survival: A Library for Time-to-Event Analysis Built on Top of scikit-learn”. In:Journal of Machine Learning Research 21.212 (2020), pp. 1–6.issn: 1533-7928.url:http://jmlr.org/papers/ v21/20-729.html
2020
-
[27]
Naiyer Rizvi et al. “Society for Immunotherapy of Cancer (SITC) con- sensus definitions for resistance to combinations of immune checkpoint in- hibitors with chemotherapy”. In:Journal for ImmunoTherapy of Cancer 11.3 (Mar. 14, 2023).issn: 2051-1426.doi:10.1136/jitc-2022-005920. url:https://jitc.bmj.com/content/11/3/e005920. S33
-
[28]
High-Dimensional Survival Analysis: Meth- ods and Applications
Stephen Salerno and Yi Li. “High-Dimensional Survival Analysis: Meth- ods and Applications”. In:Annual review of statistics and its application 10.1 (Mar. 2023), pp. 25–49.issn: 2326-8298.doi:10.1146/annurev- statistics- 032921- 022127.url:https://www.ncbi.nlm.nih.gov/ pmc/articles/PMC10038209/
-
[29]
MissForest—non-parametric missing value imputation for mixed-type data
Daniel J. Stekhoven and Peter B¨ uhlmann. “MissForest—non-parametric missing value imputation for mixed-type data”. In:Bioinformatics28.1 (Oct. 2011), pp. 112–118.issn: 1367-4803.doi:10.1093/bioinformatics/ btr597. eprint:https://academic.oup.com/bioinformatics/article- pdf/28/1/112/50568519/bioinformatics_28_1_112.pdf.url:https: //doi.org/10.1093/bioinfo...
-
[30]
Multimodal data fusion for cancer biomarker dis- covery with deep learning
Sandra Steyaert et al. “Multimodal data fusion for cancer biomarker dis- covery with deep learning”. In:Nature machine intelligence5.4 (Apr. 2023), pp. 351–362.issn: 2522-5839.doi:10.1038/s42256-023-00633-5. url:https://pmc.ncbi.nlm.nih.gov/articles/PMC10484010/
-
[31]
Hussein A. Tawbi et al. “Society for Immunotherapy of Cancer (SITC) checkpoint inhibitor resistance definitions: efforts to harmonize terminol- ogy and accelerate immuno-oncology drug development”. In:Journal for ImmunoTherapy of Cancer11.7 (July 24, 2023).issn: 2051-1426.doi: 10.1136/jitc- 2023- 007309.url:https://jitc.bmj.com/content/ 11/7/e007309
-
[32]
Missing value estimation methods for DNA microarrays
Olga Troyanskaya et al. “Missing value estimation methods for DNA microarrays”. In:Bioinformatics17.6 (June 2001), pp. 520–525.issn: 1367-4803.doi:10 . 1093 / bioinformatics / 17 . 6 . 520. eprint:https : / / academic . oup . com / bioinformatics / article - pdf / 17 / 6 / 520 / 48837104/bioinformatics_17_6_520.pdf.url:https://doi.org/10. 1093/bioinformat...
2001
-
[33]
Good methods for coping with missing data in decision trees
B.E.T.H. Twala, M.C. Jones, and D.J. Hand. “Good methods for coping with missing data in decision trees”. In:Pattern Recognition Letters29.7 (2008), pp. 950–956.issn: 0167-8655.doi:https://doi.org/10.1016/ j . patrec . 2008 . 01 . 010.url:https : / / www . sciencedirect . com / science/article/pii/S0167865508000305
2008
-
[34]
Improved Mixture Cure Model Using Machine Learning Approaches
Huina Wang, Tian Feng, and Baosheng Liang. “Improved Mixture Cure Model Using Machine Learning Approaches”. In:Mathematics13.4 (Feb. 8, 2025). Company: Multidisciplinary Digital Publishing Institute Distribu- tor: Multidisciplinary Digital Publishing Institute Institution: Multidisci- plinary Digital Publishing Institute Label: Multidisciplinary Digital P...
2025
-
[35]
Stacked generalization
David H. Wolpert. “Stacked generalization”. In:Neural Networks5.2 (Jan. 1, 1992), pp. 241–259.issn: 0893-6080.doi:10 . 1016 / S0893 - 6080(05 ) 80023- 1.url:https://www.sciencedirect.com/science/article/ pii/S0893608005800231. S34
1992
-
[36]
Renjie Wu et al.Deep Multimodal Learning with Missing Modality: A Survey. Oct. 21, 2024.doi:10.48550/arXiv.2409.07825. arXiv:2409. 07825[cs].url:http://arxiv.org/abs/2409.07825
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.07825 2024
-
[37]
Bi-level Multi-Source Learning for Heterogeneous Block- wise Missing Data
Shuo Xiang et al. “Bi-level Multi-Source Learning for Heterogeneous Block- wise Missing Data”. In:NeuroImage102 Pt 1 (Nov. 15, 2014), pp. 192– 206.issn: 1053-8119.doi:10.1016/j.neuroimage.2013.08.015.url: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3937297/
-
[38]
Chang Xu, Dacheng Tao, and Chao Xu.A Survey on Multi-view Learning
-
[39]
arXiv:1304.5634 [cs.LG].url:https://arxiv.org/abs/1304. 5634
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Fei Zhao, Chengcui Zhang, and Baocheng Geng. “Deep Multimodal Data Fusion”. In:ACM Comput. Surv.56.9 (2024), 216:1–216:36.issn: 0360- 0300.doi:10.1145/3649447.url:https://dl.acm.org/doi/10.1145/ 3649447. S35
work page doi:10.1145/3649447.url:https://dl.acm.org/doi/10.1145/ 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.