VEOcc: Voxel-Centric Online Semantic Occupancy Prediction For Embodied Scene Understanding
Pith reviewed 2026-06-30 12:04 UTC · model grok-4.3
The pith
VEOcc builds 3D semantic occupancy maps online from voxels using a recursive update strategy that skips any initial scene-scale estimate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
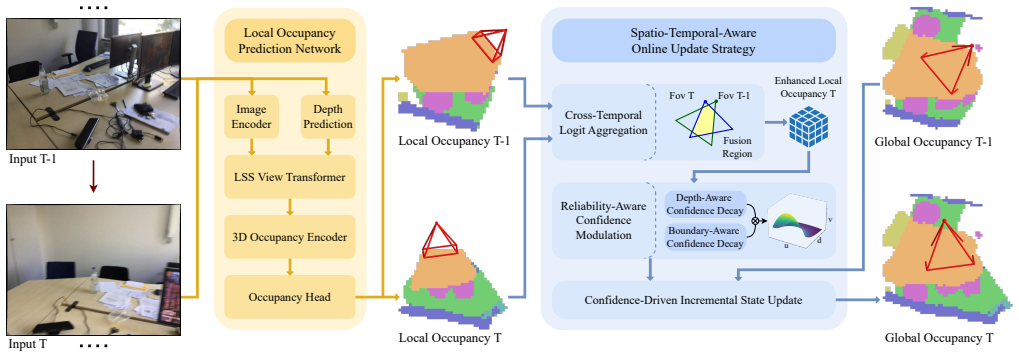
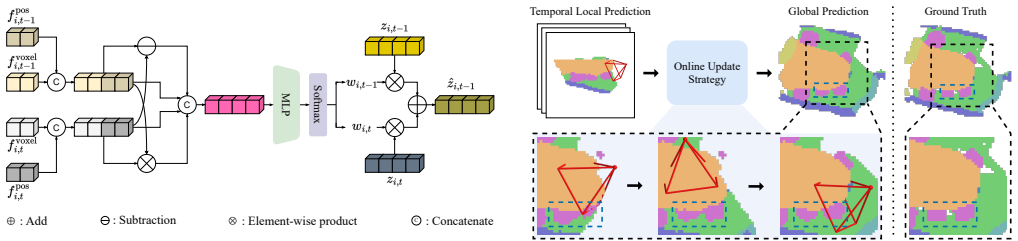
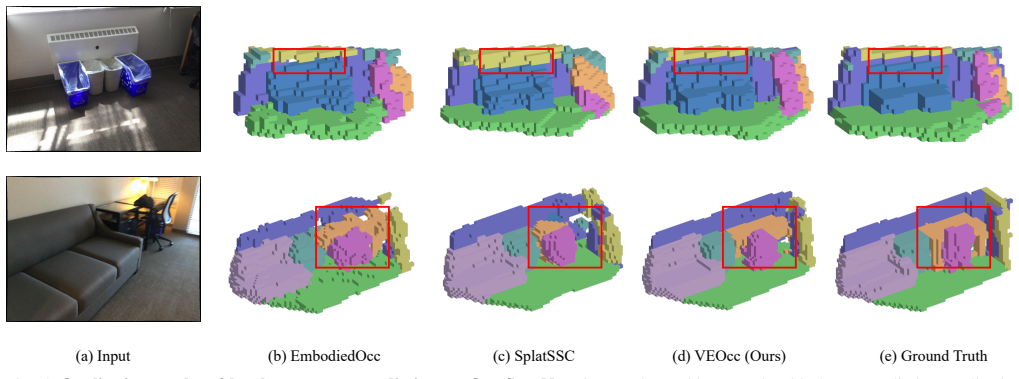
VEOcc formulates online semantic occupancy prediction as a recursive perception-and-assimilation paradigm in voxel space. By replacing Gaussian-centric representations with a discrete voxel grid and introducing the Spatio-Temporal-Aware Online Update Strategy that integrates Cross-Temporal Logit Aggregation for temporal consistency, Reliability-Aware Confidence Modulation for spatial uncertainty calibration, and Confidence-Driven Incremental State Update for global assimilation, the method aggregates noisy temporal observations without any initial scale estimation and produces higher-fidelity boundary predictions.
What carries the argument
The Spatio-Temporal-Aware Online Update Strategy, which aggregates observations inside a discrete voxel grid via logit aggregation across time, confidence-based spatial modulation, and incremental state assimilation.
If this is right
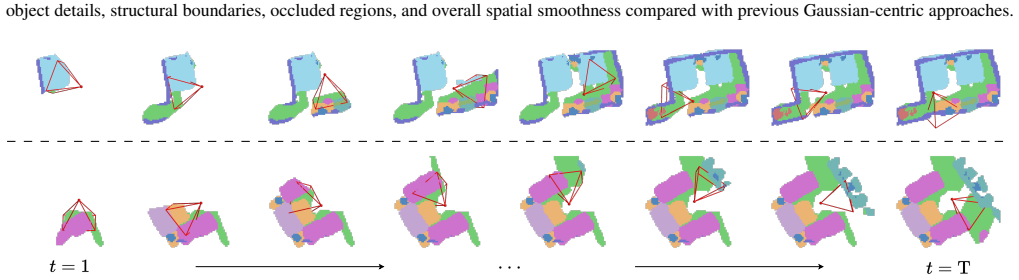
- The map can expand indefinitely without any pre-set scene bounds.
- Structural boundaries are recovered more faithfully than in continuous Gaussian representations.
- State-of-the-art results hold in both local single-view and full embodied multi-view settings.
- Zero-shot transfer succeeds on completely unseen real-world video sequences.
Where Pith is reading between the lines
- The same voxel update logic could be tested on dynamic scenes containing moving objects to check whether temporal consistency still holds.
- Because scale estimation is removed, the method might be combined with loop-closure modules that operate purely on occupancy geometry.
- Long-horizon embodied tasks such as path planning could directly consume the growing voxel map without an extra conversion step.
Load-bearing premise
The three-part update strategy can reliably combine noisy observations inside the voxel grid even when no scene-scale information is supplied at the start.
What would settle it
A long video sequence recorded in an environment whose true extent is unknown and varies over time, where VEOcc either loses map consistency or falls below the accuracy of scale-aware baselines.
Figures


read the original abstract
Crucial for autonomous exploration, online 3D occupancy prediction and mapping incrementally constructs dense spatial representations on the fly. However, recent Gaussian-centric methods struggle with structural boundary fidelity and rely heavily on predefined scene-size priors, fundamentally limiting their operational efficiency. In this work, we present VEOcc, a voxel-centric framework formulated as a recursive perception-and-assimilation paradigm. By eliminating the need for initial scale estimation, VEOcc enables highly streamlined, open-ended map expansion. Furthermore, to robustly aggregate noisy temporal observations within the discrete voxel space, we propose a Spatio-Temporal-Aware Online Update Strategy. It integrates Cross-Temporal Logit Aggregation (TLA) for temporal consistency, Reliability-Aware Confidence Modulation (RCM) for spatial uncertainty calibration, and Confidence-Driven Incremental State Update (CSU) for robust global state assimilation. % Extensive experiments on Occ-ScanNet and EmbodiedOcc-ScanNet demonstrate that VEOcc establishes new state-of-the-art performance in both local and embodied settings, providing an accurate and efficient solution for real-world exploration. Extensive experiments on Occ-ScanNet and EmbodiedOcc-ScanNet demonstrate that VEOcc establishes new state-of-the-art performance in both local and embodied settings. Notably, zero-shot evaluations on self-collected video sequences further confirm its robust out-of-distribution generalization capability in completely unseen real-world environments. Ultimately, our framework provides an accurate and highly efficient solution for autonomous exploration. Code and supplementary visualizations are available on our project page: https://wryzju.github.io/VEOcc/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VEOcc, a voxel-centric framework for online semantic occupancy prediction formulated as a recursive perception-and-assimilation paradigm. It eliminates the need for initial scale estimation to enable open-ended map expansion and proposes a Spatio-Temporal-Aware Online Update Strategy integrating Cross-Temporal Logit Aggregation (TLA), Reliability-Aware Confidence Modulation (RCM), and Confidence-Driven Incremental State Update (CSU) to aggregate noisy temporal observations in discrete voxel space. The work claims new state-of-the-art performance on Occ-ScanNet and EmbodiedOcc-ScanNet in both local and embodied settings, along with robust zero-shot out-of-distribution generalization on self-collected video sequences.
Significance. If the experimental claims hold with rigorous validation, the voxel-centric approach could advance embodied scene understanding by providing a more efficient online mapping solution than Gaussian-centric methods, removing reliance on scene-size priors and improving structural fidelity for autonomous exploration tasks.
major comments (2)
- [Abstract] Abstract: the central SOTA and generalization claims are asserted without any quantitative metrics, ablation results, or experimental protocol details, preventing assessment of whether the performance improvements are load-bearing or supported.
- [Method] Method section on Spatio-Temporal-Aware Online Update Strategy: the claim that TLA/RCM/CSU robustly aggregates noisy observations without requiring initial scale estimation is presented as a key advantage, but lacks explicit derivation, pseudocode, or comparison showing how the discrete voxel update avoids scale priors while maintaining consistency.
minor comments (1)
- [Abstract] Abstract contains a duplicated sentence describing the experiments on Occ-ScanNet and EmbodiedOcc-ScanNet.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central SOTA and generalization claims are asserted without any quantitative metrics, ablation results, or experimental protocol details, preventing assessment of whether the performance improvements are load-bearing or supported.
Authors: Abstracts are space-constrained and conventionally high-level. The manuscript provides the supporting quantitative evidence in Section 4, including mIoU tables on Occ-ScanNet and EmbodiedOcc-ScanNet, ablation results for TLA/RCM/CSU, and the full experimental protocol with dataset splits and evaluation metrics. These sections contain the load-bearing results. revision: no
-
Referee: [Method] Method section on Spatio-Temporal-Aware Online Update Strategy: the claim that TLA/RCM/CSU robustly aggregates noisy observations without requiring initial scale estimation is presented as a key advantage, but lacks explicit derivation, pseudocode, or comparison showing how the discrete voxel update avoids scale priors while maintaining consistency.
Authors: The recursive perception-and-assimilation formulation in the method section derives the scale-free property directly from operating in unbounded discrete voxel space, enabling incremental expansion without a predefined bounding volume (in contrast to Gaussian splatting approaches that require scene-size initialization). The update rules for TLA (temporal logit fusion), RCM (confidence modulation), and CSU (incremental state assimilation) are given with their mathematical definitions; algorithmic consistency follows from the per-voxel recursive update. We can add explicit pseudocode to the supplementary material. revision: partial
Circularity Check
No significant circularity detected
full rationale
The abstract and provided text introduce VEOcc as a new voxel-centric recursive paradigm with three named update strategies (TLA, RCM, CSU) but contain no equations, parameter-fitting steps, or derivations. No self-citations appear, no uniqueness theorems are invoked, and no predictions are shown reducing to fitted inputs by construction. The central claims rest on empirical SOTA results rather than any closed mathematical loop, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A Survey on Learning Motion Planning and Control for Mobile Robots: Toward Embodied Intelligence
M. Wang, Y . Niu, B. Wang, W. Zhang, and C. Wang. “A Survey on Learning Motion Planning and Control for Mobile Robots: Toward Embodied Intelligence”. In:IEEE Transactions on Neural Networks and Learning Systems(2026), pp. 1–21
2026
-
[2]
ASurvey OF EMBODIED ARTIFICIAL INTELLIGENCE DATA ENGINEERING
X. Xia, H. Tong, X. He, B. Yu, N. Ding, X. Liu, and S. Liu. “ASurvey OF EMBODIED ARTIFICIAL INTELLIGENCE DATA ENGINEERING”. In: ()
-
[3]
From machine learning to robotics: Challenges and opportunities for embodied intelligence
N. Roy, I. Posner, T. Barfoot, P. Beaudoin, Y . Bengio, J. Bohg, O. Brock, I. Depatie, D. Fox, D. Koditschek, et al. “From machine learning to robotics: Challenges and opportunities for embodied intelligence”. In:arXiv preprint arXiv:2110.15245(2021)
-
[4]
A comprehensive survey on embodied intelligence: Advancements, challenges, and future perspectives
F. Sun, R. Chen, T. Ji, Y . Luo, H. Zhou, and H. Liu. “A comprehensive survey on embodied intelligence: Advancements, challenges, and future perspectives”. In:CAAI Artificial Intelligence Research3.9150042 (2024), p. 1
2024
-
[5]
Embodied artificial intelligence: Trends and chal- lenges
R. Pfeifer and F. Iida. “Embodied artificial intelligence: Trends and chal- lenges”. In:Lecture notes in computer science(2004), pp. 1–26
2004
-
[6]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei. “V oxposer: Composable 3d value maps for robotic manipulation with language models”. In:arXiv preprint arXiv:2307.05973(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Sayplan: Grounding large language models using 3d scene graphs for scalable robot task planning
K. Rana, J. Haviland, S. Garg, J. Abou-Chakra, I. Reid, and N. Suenderhauf. “Sayplan: Grounding large language models using 3d scene graphs for scalable robot task planning”. In:arXiv preprint arXiv:2307.06135(2023)
-
[8]
Conceptgraphs: Open- vocabulary 3d scene graphs for perception and planning
Q. Gu, A. Kuwajerwala, S. Morin, K. M. Jatavallabhula, B. Sen, A. Agarwal, C. Rivera, W. Paul, K. Ellis, R. Chellappa, et al. “Conceptgraphs: Open- vocabulary 3d scene graphs for perception and planning”. In:2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE. 2024, pp. 5021–5028
2024
-
[9]
Integrated Analysis of Mapping, Path Planning, and Advanced Motion Control for Autonomous Robotic Navigation
K. Bingi, A. P. Singh, R. Ibrahim, A. Rajamallaiah, and N. B. Shaik. “Integrated Analysis of Mapping, Path Planning, and Advanced Motion Control for Autonomous Robotic Navigation”. In:Fractal and Fractional 9.10 (2025), p. 640
2025
-
[10]
Feature Guided Visual SLAM for Floor Cleaning Robot Path Planning
X. Chen, C. Wen, and L. Jiang. “Feature Guided Visual SLAM for Floor Cleaning Robot Path Planning”. In:2025 IEEE 20th Conference on Industrial Electronics and Applications (ICIEA). IEEE. 2025, pp. 1–6
2025
-
[11]
ORB-SLAM: A versatile and accurate monocular SLAM system
R. Mur-Artal, J. M. M. Montiel, and J. D. Tardos. “ORB-SLAM: A versatile and accurate monocular SLAM system”. In:IEEE transactions on robotics 31.5 (2015), pp. 1147–1163
2015
-
[12]
Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam
C. Campos, R. Elvira, J. J. G. Rodr ´ıguez, J. M. Montiel, and J. D. Tard ´os. “Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam”. In:IEEE transactions on robotics37.6 (2021), pp. 1874– 1890
2021
-
[13]
A review on visual-slam: Advancements from geometric modelling to learning-based semantic scene understanding using multi-modal sensor fusion
T. Lai. “A review on visual-slam: Advancements from geometric modelling to learning-based semantic scene understanding using multi-modal sensor fusion”. In:Sensors22.19 (2022), p. 7265
2022
-
[14]
Improved point-line feature based visual SLAM method for complex environments
F. Zhou, L. Zhang, C. Deng, and X. Fan. “Improved point-line feature based visual SLAM method for complex environments”. In:Sensors21.13 (2021), p. 4604
2021
-
[15]
Embodiedocc: Embodied 3d occupancy prediction for vision-based online scene understand- ing
Y . Wu, W. Zheng, S. Zuo, Y . Huang, J. Zhou, and J. Lu. “Embodiedocc: Embodied 3d occupancy prediction for vision-based online scene understand- ing”. In:Proceedings of the IEEE/CVF International Conference on Computer Vision. 2025, pp. 26360–26370
2025
-
[16]
Embodiedocc++: Boosting embodied 3d occupancy prediction with plane regularization and uncertainty sampler
H. Wang, X. Wei, X. Zhang, J. Li, C. Bai, Y . Li, M. Lu, W. Zheng, and S. Zhang. “Embodiedocc++: Boosting embodied 3d occupancy prediction with plane regularization and uncertainty sampler”. In:Proceedings of the 33rd ACM International Conference on Multimedia. 2025, pp. 925–934
2025
-
[17]
Roboocc: Enhancing the geometric and semantic scene understanding for robots
Z. Zhang, Q. Zhang, W. Cui, S. Shi, Y . Guo, G. Han, W. Zhao, H. Ren, R. Xu, and J. Tang. “Roboocc: Enhancing the geometric and semantic scene understanding for robots”. In:arXiv preprint arXiv:2504.14604(2025)
-
[18]
Monocular Occupancy Prediction for Scalable Indoor Scenes
H. Yu, Y . Wang, Y . Chen, and Z. Zhang. “Monocular Occupancy Prediction for Scalable Indoor Scenes”. In:arXiv preprint arXiv:2407.11730(2024)
-
[19]
SplatSSC: Decoupled Depth- Guided Gaussian Splatting for Semantic Scene Completion
R. Qian, H. Cao, T. Deng, S. Yuan, and L. Xie. “SplatSSC: Decoupled Depth- Guided Gaussian Splatting for Semantic Scene Completion”. In:Proceedings of the AAAI Conference on Artificial Intelligence. V ol. 40. 10. 2026, pp. 8520– 8528
2026
-
[20]
Monoscene: Monocular 3d semantic scene completion
A.-Q. Cao and R. De Charette. “Monoscene: Monocular 3d semantic scene completion”. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022, pp. 3991–4001
2022
-
[21]
Occformer: Dual-path transformer for vision- based 3d semantic occupancy prediction
Y . Zhang, Z. Zhu, and D. Du. “Occformer: Dual-path transformer for vision- based 3d semantic occupancy prediction”. In:Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023, pp. 9433–9443
2023
-
[22]
Context and geometry aware voxel transformer for semantic scene completion
Z. Yu, R. Zhang, J. Ying, J. Yu, X. Hu, L. Luo, S.-Y . Cao, and H.-L. Shen. “Context and geometry aware voxel transformer for semantic scene completion”. In:Advances in Neural Information Processing Systems37 (2024), pp. 1531–1555
2024
-
[23]
L2cocc: Lightweight camera-centric semantic scene completion via distillation of lidar model
R. Wang, Y . Ma, Y . Yao, S. Tao, H. Li, Z. Zhu, Y . Liu, and X. Zuo. “L2cocc: Lightweight camera-centric semantic scene completion via distillation of lidar model”. In:2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE. 2025, pp. 716–723
2025
-
[24]
V oxdet: Rethinking 3d semantic occupancy prediction as dense object detection
W. Li, Z. Yu, and A. Alahi. “V oxdet: Rethinking 3d semantic occupancy prediction as dense object detection”. In:Advances in Neural Information Processing Systems38 (2025)
2025
-
[25]
V oxformer: Sparse voxel transformer for camera-based 3d semantic scene completion
Y . Li, Z. Yu, C. Choy, C. Xiao, J. M. Alvarez, S. Fidler, C. Feng, and A. Anandkumar. “V oxformer: Sparse voxel transformer for camera-based 3d semantic scene completion”. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023, pp. 9087–9098
2023
-
[26]
Symphonize 3D Semantic Scene Completion with Contextual Instance Queries
H. Jiang, T. Cheng, N. Gao, H. Zhang, W. Liu, and X. Wang. “Symphonize 3D Semantic Scene Completion with Contextual Instance Queries”. In:arXiv preprint arXiv:2306.15670(2023)
-
[27]
Surroundocc: Multi- camera 3d occupancy prediction for autonomous driving
Y . Wei, L. Zhao, W. Zheng, Z. Zhu, J. Zhou, and J. Lu. “Surroundocc: Multi- camera 3d occupancy prediction for autonomous driving”. In:Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023, pp. 21729–21740
2023
-
[28]
Tri-perspective view for vision-based 3d semantic occupancy prediction
Y . Huang, W. Zheng, Y . Zhang, J. Zhou, and J. Lu. “Tri-perspective view for vision-based 3d semantic occupancy prediction”. In:Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2023, pp. 9223–9232
2023
-
[29]
Gaussianformer: Scene as gaussians for vision-based 3d semantic occupancy prediction
Y . Huang, W. Zheng, Y . Zhang, J. Zhou, and J. Lu. “Gaussianformer: Scene as gaussians for vision-based 3d semantic occupancy prediction”. In:European Conference on Computer Vision. Springer. 2024, pp. 376–393
2024
-
[30]
Odg: Occu- pancy prediction using dual gaussians
Y . Shi, Y . Zhu, S. Han, J. Jeong, A. Ansari, H. Cai, and F. Porikli. “Odg: Occu- pancy prediction using dual gaussians”. In:arXiv preprint arXiv:2506.09417 (2025)
-
[31]
Gaussianflowocc: Sparse and weakly supervised occupancy estimation using gaussian splatting and temporal flow
S. Boeder, F. Gigengack, and B. Risse. “Gaussianflowocc: Sparse and weakly supervised occupancy estimation using gaussian splatting and temporal flow”. In:Proceedings of the IEEE/CVF International Conference on Computer Vision. 2025, pp. 24943–24954
2025
-
[32]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d
J. Philion and S. Fidler. “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d”. In:Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Pro- ceedings, Part XIV 16. Springer. 2020, pp. 194–210
2020
-
[33]
Efficientnet: Rethinking model scaling for convolutional neural networks
M. Tan and Q. Le. “Efficientnet: Rethinking model scaling for convolutional neural networks”. In:International conference on machine learning. PMLR. 2019, pp. 6105–6114
2019
-
[34]
Feature pyramid networks for object detection
T.-Y . Lin, P. Doll ´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie. “Feature pyramid networks for object detection”. In:Proceedings of the IEEE conference on computer vision and pattern recognition. 2017, pp. 2117–2125
2017
-
[35]
Depth anything v2
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao. “Depth anything v2”. In:Advances in Neural Information Processing Systems37 (2024), pp. 21875–21911
2024
-
[36]
Deep residual learning for image recognition
K. He, X. Zhang, S. Ren, and J. Sun. “Deep residual learning for image recognition”. In:Proceedings of the IEEE conference on computer vision and pattern recognition. 2016, pp. 770–778
2016
-
[37]
Structure-from-motion revisited
J. L. Schonberger and J.-M. Frahm. “Structure-from-motion revisited”. In: Proceedings of the IEEE conference on computer vision and pattern recog- nition. 2016, pp. 4104–4113
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.