Evolutionary Enhanced Multi-Agent Reinforcement Learning for Cooperative Air Combat
Pith reviewed 2026-06-30 11:18 UTC · model grok-4.3
The pith
ACE-MAPPO combines evolutionary updates with MAPPO to raise win rates and speed convergence in multi-aircraft cooperative air combat.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
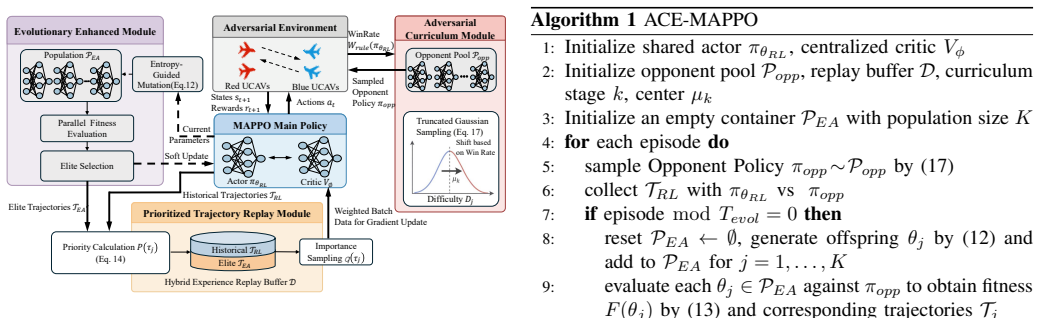
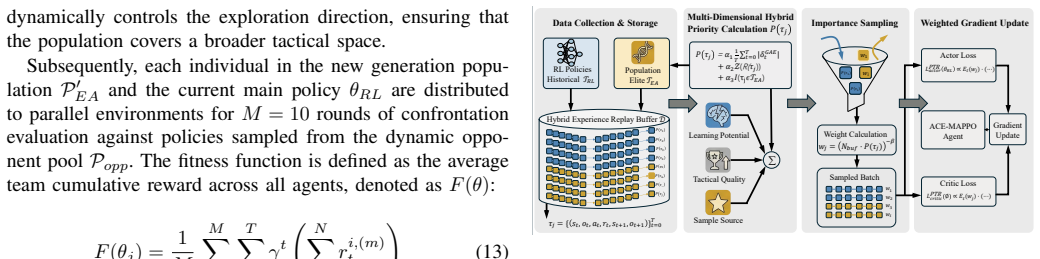
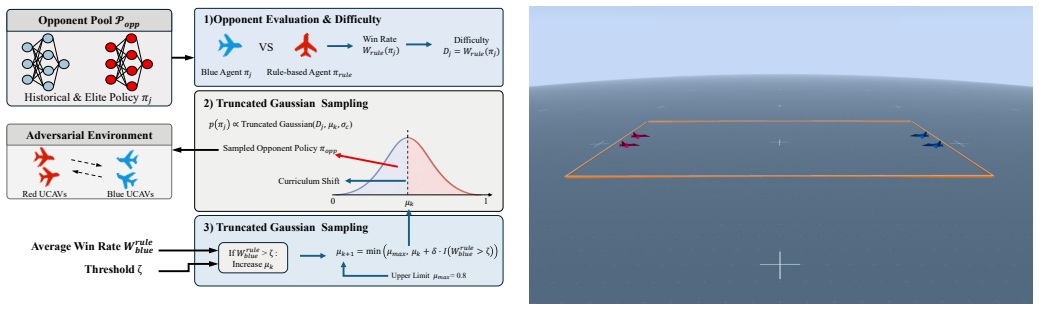
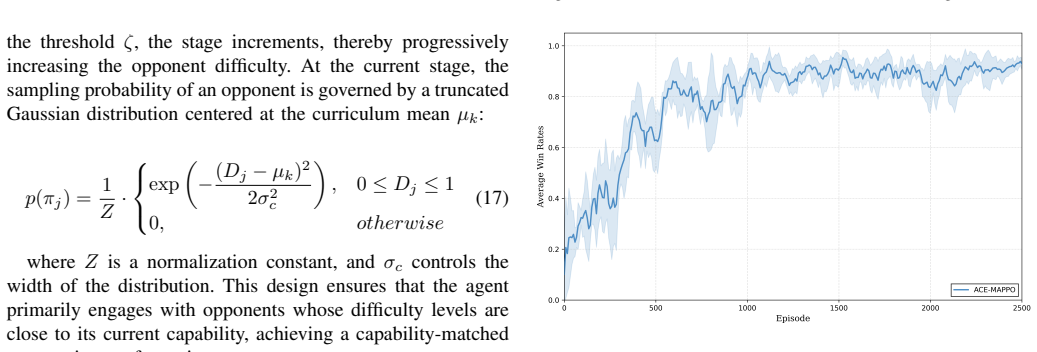
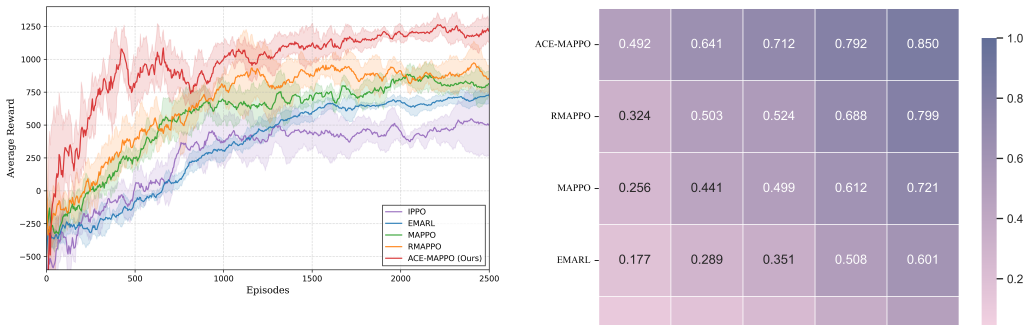
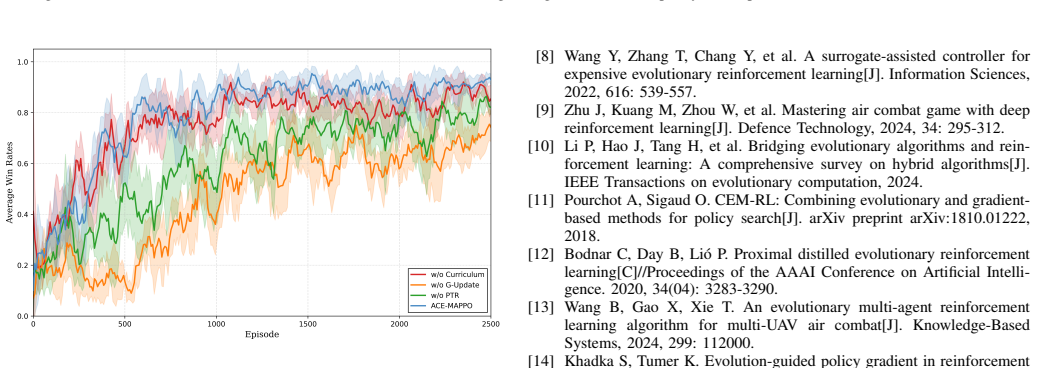
The authors present ACE-MAPPO as a hybrid that augments MAPPO with three evolutionary components: a genetic soft update mechanism that maintains population diversity and avoids local optima, an evolutionary-augmented prioritized trajectory replay that improves use of sparse high-value samples, and an adversarial evolutionary curriculum that adapts training difficulty. In simulated multi-aircraft cooperative engagements, this combination produces more stable training, quicker convergence, and higher win rates than MAPPO and other baselines.
What carries the argument
ACE-MAPPO framework, which augments MAPPO using genetic soft updates for diversity, evolutionary prioritized replay for sample efficiency, and adversarial curriculum learning for progressive difficulty.
If this is right
- Training stability improves in high-dimensional, strongly adversarial state spaces.
- Convergence occurs faster because high-value trajectories receive priority.
- Win rates rise in multi-UCAV cooperative scenarios relative to MAPPO.
- Policies generalize better across progressively harder engagement conditions.
Where Pith is reading between the lines
- The same three components could be tested in other sparse-reward multi-agent settings such as team robotics or fleet coordination.
- Replacing the fixed curriculum schedule with online difficulty estimation might further reduce manual tuning.
- Direct comparison against attention-based or graph MARL variants would clarify whether evolutionary additions provide orthogonal benefits.
Load-bearing premise
Performance gains measured in the chosen simulation will hold when the environment is replaced by real sensor noise, communication limits, or different opponent behaviors.
What would settle it
Re-running the trained policies in a simulator that adds realistic radar uncertainty and intermittent links, then observing whether win-rate advantages disappear against the same baselines.
Figures
read the original abstract
As modern air combat evolves toward beyond-visual-range (BVR) multi-aircraft cooperative engagements, autonomous decision-making for unmanned combat aerial vehicles (UCAVs) faces significant challenges due to high-dimensional state spaces, discrete action commands, and strongly adversarial dynamic environments. To overcome the limitations of existing multi-agent reinforcement learning (MARL) methods in such settings, namely insufficient exploration efficiency, low sample utilization, and poor policy generalization, we propose Adversarial Curriculum and Evolutionary-enhanced Multi-agent Proximal Policy Optimization (ACE-MAPPO), a hybrid learning framework that integrates evolutionary algorithms with MAPPO. Specifically, a genetic soft update mechanism is introduced to enhance population diversity and mitigate convergence to local optima. An evolutionary-augmented prioritized trajectory replay strategy is further employed to improve the utilization of sparse high-value samples. In addition, an adversarial evolutionary curriculum learning mechanism is designed to enable adaptive training with progressively increasing difficulty. Extensive experimental results demonstrate that the proposed method outperforms MAPPO and other baseline algorithms in terms of training stability, convergence speed, and win rate, validating its effectiveness in multi-aircraft cooperative air combat scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ACE-MAPPO, a hybrid MARL framework that augments MAPPO with a genetic soft-update mechanism, an evolutionary-augmented prioritized trajectory replay buffer, and an adversarial evolutionary curriculum. The central claim is that these components improve training stability, convergence speed, and win rate over MAPPO and other baselines in simulated multi-aircraft cooperative BVR air combat.
Significance. If the reported gains are reproducible and the simulator is representative, the work would offer a concrete way to combine evolutionary diversity mechanisms with policy-gradient MARL for sparse-reward, high-dimensional adversarial settings. The explicit integration of curriculum and replay strategies is a strength that could be tested in other domains.
major comments (1)
- [Experimental setup / §4] The simulated environment (described in the experimental setup) omits any mention of sensor noise, communication latency, variable aircraft performance parameters, or realistic BVR geometry and engagement ranges. Because the headline claim of effectiveness in “multi-aircraft cooperative air combat scenarios” rests on measured win-rate improvements, the absence of these fidelity details makes it impossible to determine whether the gains arise from the proposed genetic soft-update, prioritized replay, or curriculum components rather than from simplified dynamics.
minor comments (1)
- [Abstract] The abstract states that “extensive experimental results demonstrate” outperformance but supplies no numerical values, error bars, or statistical tests; moving at least one key metric (e.g., mean win rate ± std) into the abstract would improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the experimental setup. We address it point by point below and will make revisions to improve clarity and transparency.
read point-by-point responses
-
Referee: [Experimental setup / §4] The simulated environment (described in the experimental setup) omits any mention of sensor noise, communication latency, variable aircraft performance parameters, or realistic BVR geometry and engagement ranges. Because the headline claim of effectiveness in “multi-aircraft cooperative air combat scenarios” rests on measured win-rate improvements, the absence of these fidelity details makes it impossible to determine whether the gains arise from the proposed genetic soft-update, prioritized replay, or curriculum components rather than from simplified dynamics.
Authors: We agree that Section 4 should provide a more explicit description of the simulator's modeling assumptions and limitations. The environment is a custom discrete-time multi-agent simulator that abstracts key BVR elements (relative positions, velocities, radar lock states, and missile engagement zones) while using simplified dynamics without sensor noise, latency, or heterogeneous aircraft parameters; all methods including baselines are evaluated under identical conditions to isolate algorithmic effects. This design choice prioritizes computational tractability for extensive ablation studies on the genetic soft-update, evolutionary replay, and adversarial curriculum. We will revise the experimental setup section to (i) detail the exact state/action spaces and transition rules, (ii) explicitly list the omitted fidelity factors, and (iii) add a limitations paragraph discussing how these simplifications may affect direct transfer to real platforms. These changes will allow readers to better assess the source of the observed improvements. revision: yes
Circularity Check
No circularity; empirical validation is independent of self-referential steps
full rationale
The paper proposes ACE-MAPPO by describing three explicit algorithmic components (genetic soft update, evolutionary-augmented prioritized replay, adversarial evolutionary curriculum) and then reports win-rate, stability, and convergence metrics against MAPPO and other baselines inside a simulated environment. No equation or claim reduces by construction to its own inputs, no parameter is fitted on a subset and then relabeled a prediction, and no uniqueness theorem or ansatz is imported via self-citation. The central claim therefore rests on external experimental comparison rather than definitional equivalence.
Axiom & Free-Parameter Ledger
free parameters (1)
- hyperparameters of MAPPO, genetic update, replay, and curriculum components
axioms (1)
- domain assumption The air combat simulation is a sufficient proxy for real BVR cooperative engagements
Reference graph
Works this paper leans on
-
[1]
Deep reinforcement learning-based air- to-air combat maneuver generation in a realistic environment[J]
Bae J H, Jung H, Kim S, et al. Deep reinforcement learning-based air- to-air combat maneuver generation in a realistic environment[J]. IEEE Access, 2023, 11: 26427-26440
2023
-
[2]
Game-theoretic validation and analysis of air combat simulation models[J]
Poropudas J, Virtanen K. Game-theoretic validation and analysis of air combat simulation models[J]. IEEE Transactions on Systems, Man, and Cybernetics-Part A: Systems and Humans, 2010, 40(5): 1057-1070
2010
-
[3]
Autonomous air combat maneuver decision using Bayesian inference and moving horizon optimization[J]
Changqiang H, Kangsheng D, Hanqiao H, et al. Autonomous air combat maneuver decision using Bayesian inference and moving horizon optimization[J]. Journal of Systems Engineering and Electronics, 2018, 29(1): 86-97
2018
-
[4]
Artificial immune system approach for air combat maneuvering[C]//Intelligent Computing: Theory and Appli- cations V
Kaneshige J, Krishnakumar K. Artificial immune system approach for air combat maneuvering[C]//Intelligent Computing: Theory and Appli- cations V . SPIE, 2007, 6560: 68-79
2007
-
[5]
Research on multi-aircraft cooperative combat based on deep reinforcement learning[C]//International Confer- ence on Autonomous Unmanned Systems
Zhu L, Wang J, Wang Y , et al. Research on multi-aircraft cooperative combat based on deep reinforcement learning[C]//International Confer- ence on Autonomous Unmanned Systems. Singapore: Springer Nature Singapore, 2022: 1410-1420
2022
-
[6]
Enhancing Proximal Policy Optimization for UA V Air Combat with Exploration Boosting and Covariance Matrix Adaptation Strategy[J]
Zhou Z, Jiang J, Wang H, et al. Enhancing Proximal Policy Optimization for UA V Air Combat with Exploration Boosting and Covariance Matrix Adaptation Strategy[J]. IEEE Access, 2025
2025
-
[7]
A sample selection mechanism for multi-UCA V air combat policy training using multi- agent reinforcement learning[J]
Zihui Y A N, Liang X, Yueqi H O U, et al. A sample selection mechanism for multi-UCA V air combat policy training using multi- agent reinforcement learning[J]. Chinese Journal of Aeronautics, 2025: 103391
2025
-
[8]
A surrogate-assisted controller for expensive evolutionary reinforcement learning[J]
Wang Y , Zhang T, Chang Y , et al. A surrogate-assisted controller for expensive evolutionary reinforcement learning[J]. Information Sciences, 2022, 616: 539-557
2022
-
[9]
Mastering air combat game with deep reinforcement learning[J]
Zhu J, Kuang M, Zhou W, et al. Mastering air combat game with deep reinforcement learning[J]. Defence Technology, 2024, 34: 295-312
2024
-
[10]
Bridging evolutionary algorithms and rein- forcement learning: A comprehensive survey on hybrid algorithms[J]
Li P, Hao J, Tang H, et al. Bridging evolutionary algorithms and rein- forcement learning: A comprehensive survey on hybrid algorithms[J]. IEEE Transactions on evolutionary computation, 2024
2024
-
[11]
CEM-RL: Combining evolutionary and gradient-based methods for policy search
Pourchot A, Sigaud O. CEM-RL: Combining evolutionary and gradient- based methods for policy search[J]. arXiv preprint arXiv:1810.01222, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
Proximal distilled evolutionary reinforcement learning[C]//Proceedings of the AAAI Conference on Artificial Intelli- gence
Bodnar C, Day B, Li ´o P. Proximal distilled evolutionary reinforcement learning[C]//Proceedings of the AAAI Conference on Artificial Intelli- gence. 2020, 34(04): 3283-3290
2020
-
[13]
An evolutionary multi-agent reinforcement learning algorithm for multi-UA V air combat[J]
Wang B, Gao X, Xie T. An evolutionary multi-agent reinforcement learning algorithm for multi-UA V air combat[J]. Knowledge-Based Systems, 2024, 299: 112000
2024
-
[14]
Evolution-guided policy gradient in reinforcement learning[J]
Khadka S, Tumer K. Evolution-guided policy gradient in reinforcement learning[J]. Advances in Neural Information Processing Systems, 2018, 31
2018
-
[15]
Genetic soft updates for policy evolution in deep reinforcement learning[C]//International Conference on Learning Representations
Marchesini E, Corsi D, Farinelli A. Genetic soft updates for policy evolution in deep reinforcement learning[C]//International Conference on Learning Representations. 2020
2020
-
[16]
(2021).PTR-PPO: Proximal Policy Optimization with Prioritized Trajectory Replay
Liang X, Ma Y , Feng Y , et al. Ptr-ppo: Proximal policy optimization with prioritized trajectory replay[J]. arXiv preprint arXiv:2112.03798, 2021
-
[17]
Enhancing Neural Fictitious Self- Play for Symmetric Team Games: A Two-Stage Training Frame- work[C]//2025 International Joint Conference on Neural Networks (IJCNN)
Zhang B, Liang H, Zhao Z, et al. Enhancing Neural Fictitious Self- Play for Symmetric Team Games: A Two-Stage Training Frame- work[C]//2025 International Joint Conference on Neural Networks (IJCNN). IEEE, 2025: 1-8
2025
-
[18]
The surprising effectiveness of ppo in cooperative multi-agent games[J]
Yu C, Velu A, Vinitsky E, et al. The surprising effectiveness of ppo in cooperative multi-agent games[J]. Advances in neural information processing systems, 2022, 35: 24611-24624
2022
-
[19]
Xu J, Guo Q, Xiao L, et al. Autonomous decision-making method for combat mission of UA V based on deep reinforcement learning[C]//2019 IEEE 4th advanced information technology, electronic and automation control conference (IAEAC). IEEE, 2019, 1: 538-544
2019
-
[20]
UA V air combat autonomous maneuver decision based on DDPG algorithm[C]//2019 IEEE 15th international conference on control and automation (ICCA)
Yang Q, Zhu Y , Zhang J, et al. UA V air combat autonomous maneuver decision based on DDPG algorithm[C]//2019 IEEE 15th international conference on control and automation (ICCA). IEEE, 2019: 37-42
2019
-
[21]
Beyond-visual-range air combat tactics auto-generation by reinforcement learning[C]//2020 international joint conference on neural networks (IJCNN)
Piao H, Sun Z, Meng G, et al. Beyond-visual-range air combat tactics auto-generation by reinforcement learning[C]//2020 international joint conference on neural networks (IJCNN). IEEE, 2020: 1-8
2020
-
[22]
Cooperation and competition: Flocking with evolutionary multi-agent reinforcement learning[C]//International Conference on Neural Information Processing
Guo Y , Xie X, Zhao R, et al. Cooperation and competition: Flocking with evolutionary multi-agent reinforcement learning[C]//International Conference on Neural Information Processing. Cham: Springer Interna- tional Publishing, 2022: 271-283
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.