Counterfactually Safe Reinforcement Learning
Pith reviewed 2026-06-29 23:46 UTC · model grok-4.3
The pith
A two-stage procedure learns RL policies that maximize return while controlling counterfactual individual harm.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a two-stage procedure allows learning policies that maximize expected return while the harm rate, defined as the probability that the chosen action is worse than a baseline counterfactual, remains well-controlled. Finite-sample properties are established and an upper bound on the sub-optimality gap is derived, with effectiveness shown on simulated and real-world datasets.
What carries the argument
The two-stage procedure that first estimates counterfactual harm relative to a baseline and then optimizes the policy under a harm-rate constraint.
If this is right
- The learned policy achieves high expected return with the harm rate remaining well-controlled.
- Finite-sample properties of the learned policy hold.
- An explicit upper bound on the sub-optimality gap is available.
- The procedure demonstrates effectiveness on both simulated and real-world datasets.
Where Pith is reading between the lines
- The approach may transfer to sequential decision settings outside standard RL where individual-level safety matters.
- Estimation of counterfactual baselines could be strengthened by combining with observational causal methods.
- High-stakes applications such as medical treatment sequences offer natural test beds for the harm control.
- Relaxing the baseline requirement to purely observational data would broaden applicability.
Load-bearing premise
That counterfactual outcomes relative to a baseline alternative can be meaningfully defined, estimated, or bounded in the given RL environment so that harm events are identifiable and controllable.
What would settle it
An experiment applying the two-stage procedure yet finding the realized harm rate above the target control level would falsify the claim that harm remains well-controlled.
Figures

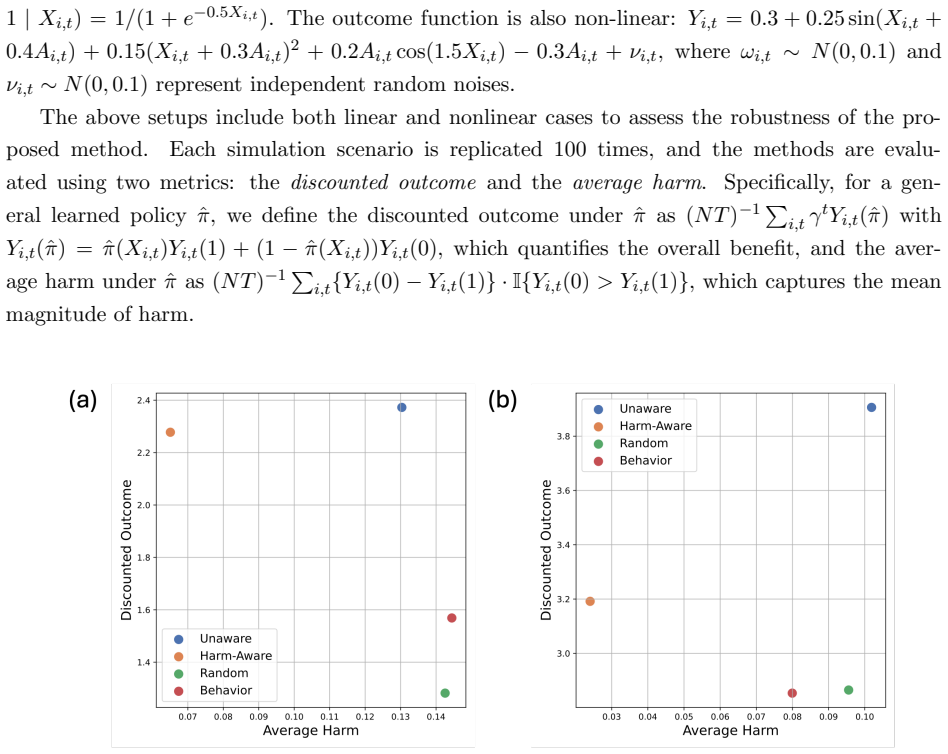
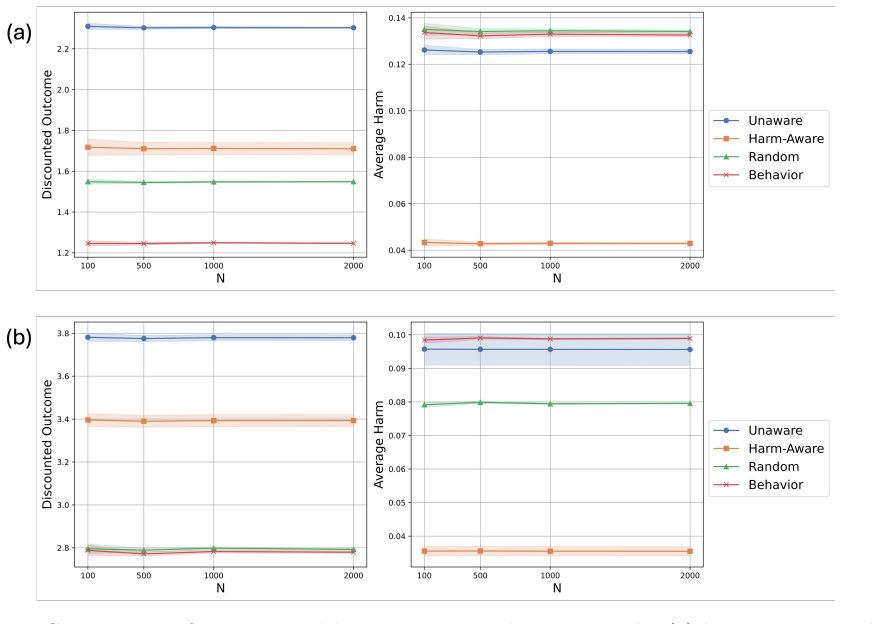
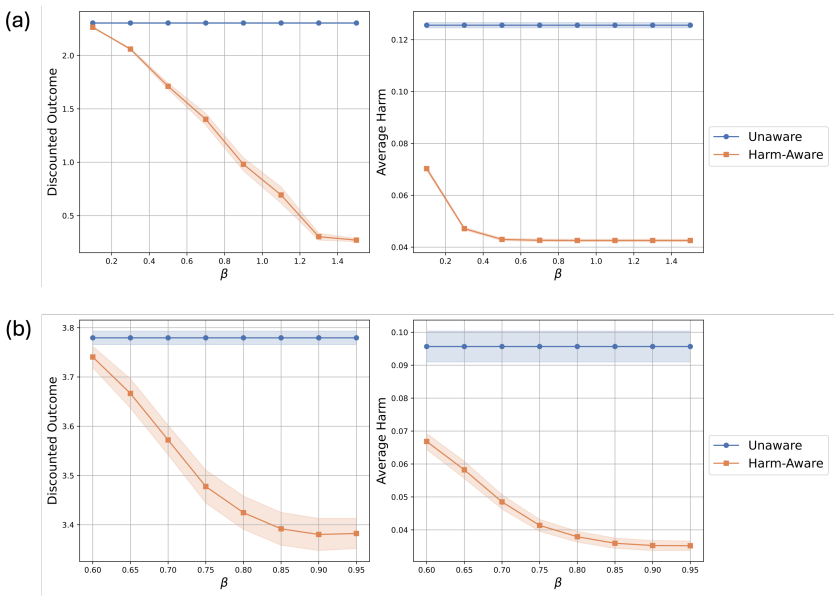
read the original abstract
Reinforcement learning algorithms are generally designed to maximize the expected return across a population. However, a policy that is optimal on average may be suboptimal for certain individuals, leading to potential safety concerns. To address this, we first formalize the notion of individual harm from a counterfactual perspective and define harm as the event in which a chosen action results in a strictly worse outcome than a baseline alternative. We then propose a general two-stage procedure for learning policies that maximize the expected return while accounting for individual harm. We further establish the finite-sample properties of the learned policy, derive an upper bound on its sub-optimality gap, and show that the harm rate remains well-controlled. Numerical experiments on both simulated and real-world datasets demonstrate the effectiveness of the proposed approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes individual harm in RL as a counterfactual event where the chosen action yields a strictly worse outcome than a baseline alternative. It proposes a two-stage procedure to maximize expected return while controlling the harm rate, claims to establish finite-sample properties of the learned policy, derives an upper bound on the sub-optimality gap, and validates the approach via experiments on simulated and real-world datasets.
Significance. If the counterfactual harm definition and associated bounds can be made rigorous under explicit identifiability conditions, the work would offer a useful framework for individual-level safety in RL beyond average-case optimization. The two-stage procedure and finite-sample guarantees would be notable strengths if supported by the derivations.
major comments (1)
- [Abstract] Abstract: The claims of finite-sample properties and an upper bound on the sub-optimality gap rest on the counterfactual harm indicator being well-defined and estimable. However, in an RL setting where outcomes are full trajectories depending on the policy and transition kernel, no conditions are indicated for identifying individual counterfactual outcomes versus the baseline (e.g., no unmeasured confounding or known baseline policy). This renders the harm-rate control and bounds non-operational without additional assumptions, which is load-bearing for all central claims.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claims of finite-sample properties and an upper bound on the sub-optimality gap rest on the counterfactual harm indicator being well-defined and estimable. However, in an RL setting where outcomes are full trajectories depending on the policy and transition kernel, no conditions are indicated for identifying individual counterfactual outcomes versus the baseline (e.g., no unmeasured confounding or known baseline policy). This renders the harm-rate control and bounds non-operational without additional assumptions, which is load-bearing for all central claims.
Authors: We agree that the manuscript does not explicitly state identifiability conditions. Our formalization of counterfactual harm and the subsequent finite-sample analysis assume a known baseline policy together with the standard no-unmeasured-confounding condition that permits identification of individual counterfactual outcomes from observed trajectories. The two-stage procedure and the derived bounds on the sub-optimality gap and harm rate are valid conditional on these assumptions. We will revise the paper to add an explicit subsection stating these conditions (with references to the causal-RL literature) in the problem formulation, thereby making the operational scope of the claims transparent. revision: yes
Circularity Check
No circularity: derivation builds on explicit formalization and standard RL bounds without reduction to fitted inputs or self-citations.
full rationale
The abstract and provided excerpts show the paper first defines individual harm via a counterfactual comparison to a baseline, then introduces a two-stage procedure to maximize return subject to harm control, followed by finite-sample analysis and a sub-optimality bound. No equations or steps are quoted that equate a derived quantity (e.g., the bound or harm rate) to a fitted parameter or prior self-citation by construction. The reader's assessment of score 2.0 aligns with the absence of self-definitional, fitted-prediction, or load-bearing self-citation patterns; the central claims rest on the new harm formalization plus conventional RL theory rather than circular reduction. Identifiability concerns raised by the skeptic pertain to assumption validity, not derivation circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Counterfactual outcomes for baseline alternatives can be defined and compared in the RL setting to identify harm events.
Reference graph
Works this paper leans on
-
[1]
doi: 10.1214/009053606000001217
ISSN 0090-5364. doi: 10.1214/009053606000001217. URL http://dx.doi.org/10.1214/009053606000001217. Jean-Yves Audibert, R´ emi Munos, and Csaba Szepesv´ ari. Tuning bandit algorithms in stochastic environments.Theoretical Computer Science, 410(19):1876–1902,
-
[2]
Marie-Pierre de B´ ethune. Non-nucleoside reverse transcriptase inhibitors (nnrtis), their discovery, development, and use in the treatment of hiv-1 infection: a review of the last 20 years (1989– 2009).Antiviral research, 85(1):75–90,
1989
-
[3]
Off-policy deep reinforcement learning without exploration
Scott Fujimoto, David Meger, and Doina Precup. Off-policy deep reinforcement learning without exploration. InInternational Conference on Machine Learning, pages 2052–2062. PMLR,
2052
-
[4]
Antiretro- viral drugs for treatment and prevention of hiv infection in adults: 2016 recommendations of the international antiviral society–usa panel.Jama, 316(2):191–210,
Huldrych F G¨ unthard, Michael S Saag, Constance A Benson, Carlos Del Rio, Joseph J Eron, Joel E Gallant, Jennifer F Hoy, Michael J Mugavero, Paul E Sax, Melanie A Thompson, et al. Antiretro- viral drugs for treatment and prevention of hiv infection in adults: 2016 recommendations of the international antiviral society–usa panel.Jama, 316(2):191–210,
2016
-
[5]
Deep Reinforcement Learning: An Overview
Yuxi Li. Deep reinforcement learning: An overview.arXiv preprint arXiv:1701.07274,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Fairness-aware contextual dynamic pricing with strategic buyers
21 Pangpang Liu and Will Wei Sun. Fairness-aware contextual dynamic pricing with strategic buyers. arXiv preprint arXiv:2501.15338,
-
[7]
Menlo Park, CA; Cambridge, MA; London; AAAI Press; MIT Press; 1999,
1999
-
[8]
Combin- ing kernel and model based learning for hiv therapy selection.AMIA Summits on Translational Science Proceedings, 2017:239,
Sonali Parbhoo, Jasmina Bogojeska, Maurizio Zazzi, Volker Roth, and Finale Doshi-Velez. Combin- ing kernel and model based learning for hiv therapy selection.AMIA Summits on Translational Science Proceedings, 2017:239,
2017
-
[9]
Statistically efficient advantage learning for offline reinforcement learning in infinite horizons.Journal of the American Statistical Association, 119(545):232–245, 2024a
Chengchun Shi, Shikai Luo, Yuan Le, Hongtu Zhu, and Rui Song. Statistically efficient advantage learning for offline reinforcement learning in infinite horizons.Journal of the American Statistical Association, 119(545):232–245, 2024a. Chengchun Shi, Zhengling Qi, Jianing Wang, and Fan Zhou. Value enhancement of reinforcement learning via efficient and rob...
2011
-
[10]
Ziyu Tang, Qinqing Zhang, and Wen Sun. Worst-case aware policy optimization for robust rein- forcement learning.arXiv preprint arXiv:2002.08033,
- [11]
-
[12]
Jitao Wang, Chengchun Shi, John D Piette, Joshua R Loftus, Donglin Zeng, and Zhenke Wu. Counterfactually fair reinforcement learning via sequential data preprocessing.arXiv preprint arXiv:2501.06366,
-
[13]
Ruosong Wang, Dean P Foster, and Sham M Kakade. What are the statistical limits of offline rl with linear function approximation?arXiv preprint arXiv:2010.11895,
-
[14]
The Promises of Multiple Experiments: Identifying Joint Distribution of Potential Outcomes
Peng Wu and Xiaojie Mao. The promises of multiple experiments: Identifying joint distribution of potential outcomes.arXiv preprint arXiv:2504.20470,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Quantifying Individual Risk for Binary Outcomes
Peng Wu, Peng Ding, Zhi Geng, and Yue Liu. Quantifying individual risk for binary outcome: Bounds and inference.arXiv preprint arXiv:2402.10537,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Mitigating unwanted biases with adversarial learning
Brian Hu Zhang, Bethany Lemoine, and Margaret Mitchell. Mitigating unwanted biases with adversarial learning. InProceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, pages 335–340,
2018
-
[17]
doi: 10.1080/01621459.2022.2138760. 25 Supplementary Material S1. Harm Rate Identifiability under a Gaussian Copula In this section, we derive the identifiability formula for the harm rate presented at the end of Section 2.3 of the manuscript. Under the Gaussian copula assumption with parameterρ, the joint distribution of (Y t(a), Yt(a′)) givenX t =xis a ...
-
[18]
1997; Chernozhukov and Hansen 2005)
Since the noise termϵ t is shared across different actions, it is not hard to verify that the joint distribution of (Y(a), Y(a ′)) conditional onX t is Gaussian with correlation coefficientρ= 1, a property commonly referred to as rank preservation (Heckman et al. 1997; Chernozhukov and Hansen 2005). S3 Table S1: Performance comparison across different sam...
1997
-
[19]
Table S1 and S2 report the detailed numerical values for discounted rewards and average harms over 100 replications, under the linear and nonlinear settings, respectively
Numerical detailsTo complement the experimental results in the main text, we provide a comprehensive breakdown of the performance of our algorithm across different dataset sizes, with the values ofN∈ {100,500,1000,2000}. Table S1 and S2 report the detailed numerical values for discounted rewards and average harms over 100 replications, under the linear an...
2000
-
[20]
Lemma S1.Under the completeness assumption 4(ii) and feature convergence assumption 4(iii) in the manuscript, and assume|ˆrt| ≤M, we have ∥Q∗ − ˆQK∥∞ ≤ K−1X t=0 γt∥ ˆQK−t − T ˆQK−t−1∥∞ + γKM 1−γ .(S6) Proof.This can be shown similarly as Theorem 8 in Hu et al. (2025). 2 Lemma S2.Under the completeness assumption 4(ii) and feature convergence assumption 4(...
2025
-
[21]
Denote ˆwQ as the OLS estimator for anyQ∈ Q
For the ease of presentation, we use lower letters from now on. Denote ˆwQ as the OLS estimator for anyQ∈ Q. Let ˆΣ =Pn i=1 ϕ(xi, ai)ϕ(xi, ai)⊤ be the empirical design matrix, then ˆwQ should be ˆwQ = arg min w∈Rd nX i=1 (wϕ(xi, ai)−r i −γmax a′∈A Q(x′ i, a′))2 = ˆΣ−1 nX i=1 ϕ(xi, ai) ri −γmax a′∈A Q(x′ i, a′) . And let ˜wQ be the parameter using the esti...
1994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.