Locality Matters for Training-Free Audio Token Compression in Audio-Language Models
Pith reviewed 2026-06-30 11:36 UTC · model grok-4.3
The pith
Temporal locality in audio token merging benefits captioning more than global merging under compression in audio-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
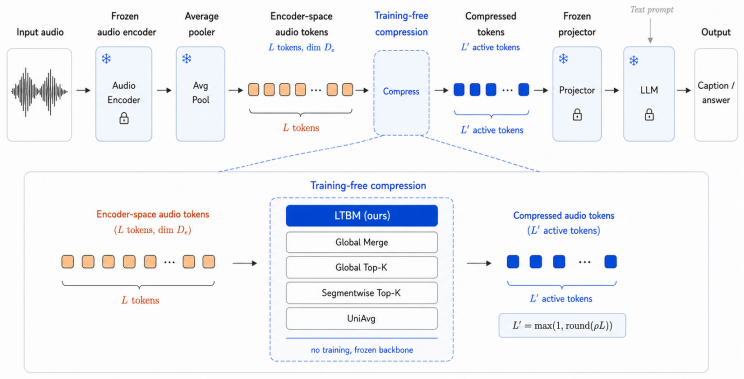
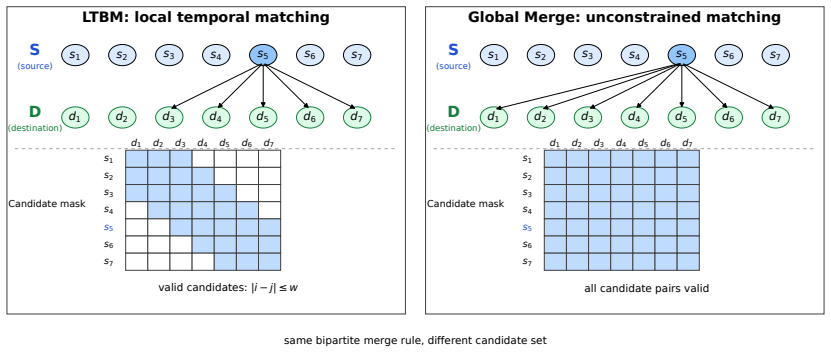
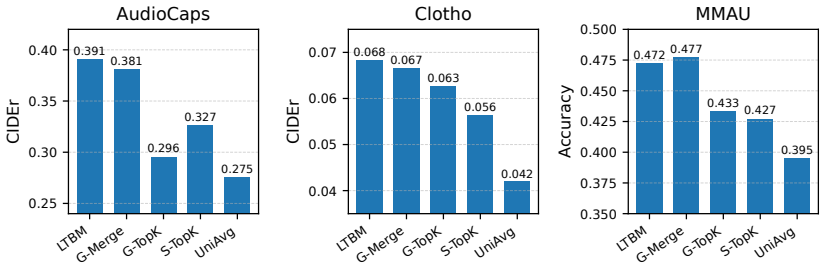
Local Temporal Bipartite Merging merges similar nearby audio tokens under an explicit temporal window constraint. Experiments demonstrate a task-dependent locality effect: locality-aware merging is more favorable for captioning at several compression settings, especially under stronger compression, while global matching is more competitive for multiple-choice audio understanding. A cross-backbone validation on Audio Flamingo 3 further supports the captioning-side advantage of locality-aware merging under moderate and aggressive compression.
What carries the argument
Local Temporal Bipartite Merging (LTBM), which merges similar nearby audio tokens under an explicit temporal window constraint.
Load-bearing premise
The premise that the controlled Global Merge variant isolates the contribution of temporal locality without other confounding differences in how merges are selected or executed.
What would settle it
If an otherwise identical global merge that uses the same similarity computation and execution rules but drops the temporal window produces equivalent captioning scores to LTBM across the tested compression rates, the claimed benefit of locality would be falsified.
Figures
read the original abstract
Audio-language models (ALMs) are increasingly used for audio captioning, question answering, and open-ended audio understanding, but their inference cost remains high when audio inputs are represented as long prefix-token sequences. These audio prefixes consume context budget, increase memory usage, and make deployment harder in resource-constrained or latency-sensitive settings. Existing training-free audio-token reduction methods mainly rely on fixed pooling or score-based pruning. Fixed pooling is content-agnostic, while score-based pruning can preserve isolated salient tokens but discard nearby acoustic context. We propose Local Temporal Bipartite Merging (LTBM), a training-free encoder-space compression method that merges similar nearby audio tokens under an explicit temporal window constraint. Beyond introducing LTBM, we use a controlled Global Merge variant to isolate whether temporal locality itself is a useful inductive bias for audio-token compression. Experiments on AudioCaps, Clotho, and MMAU with Qwen2-Audio show evidence of a task-dependent locality effect: locality-aware merging is more favorable for captioning at several compression settings, especially under stronger compression, while global matching is more competitive for multiple-choice audio understanding. A cross-backbone validation on Audio Flamingo 3 further supports the captioning-side advantage of locality-aware merging under moderate and aggressive compression.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Local Temporal Bipartite Merging (LTBM), a training-free encoder-space method that merges similar nearby audio tokens under an explicit temporal window. It introduces a controlled Global Merge variant to isolate the contribution of temporal locality as an inductive bias. Experiments on AudioCaps, Clotho, and MMAU with Qwen2-Audio, plus cross-backbone validation on Audio Flamingo 3, report a task-dependent effect: locality-aware merging is more favorable for captioning (especially at stronger compression), while global matching is competitive for multiple-choice audio understanding.
Significance. If the empirical isolation of locality holds, the work would be significant for efficient inference in audio-language models by showing that a simple temporal constraint can yield task-specific gains without retraining. The multi-dataset, multi-backbone design and use of a controlled baseline are positive features that could inform compression strategies in resource-constrained settings.
major comments (2)
- [Method (Global Merge variant)] The method description does not supply pseudocode, explicit equations, or an ablation confirming that the Global Merge variant uses identical similarity function, bipartite matching scope, merge count, and post-merge token representation as LTBM outside the window constraint. Without this, performance gaps cannot be attributed solely to the locality bias, which is load-bearing for the central claim in the abstract.
- [§4] §4 (Experiments): the reported results are described only in terms of qualitative trends across compression settings; the absence of tabulated quantitative metrics (e.g., exact captioning scores or accuracy deltas at each ratio) and full implementation details limits assessment of effect sizes and reproducibility.
minor comments (2)
- [Figures] Figure captions could more explicitly state the compression ratios and backbone used in each panel to aid quick comparison with the text.
- [§3] Notation for the temporal window size and merge ratio should be defined once in a dedicated subsection rather than inline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to strengthen the clarity of our method and the presentation of experimental results. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Method (Global Merge variant)] The method description does not supply pseudocode, explicit equations, or an ablation confirming that the Global Merge variant uses identical similarity function, bipartite matching scope, merge count, and post-merge token representation as LTBM outside the window constraint. Without this, performance gaps cannot be attributed solely to the locality bias, which is load-bearing for the central claim in the abstract.
Authors: We agree that additional explicit documentation is needed to rigorously isolate the locality bias. In the revised manuscript we will add pseudocode for both LTBM and the Global Merge variant, together with equations that confirm they employ the identical similarity function, bipartite matching procedure (differing only in the temporal window), merge count, and post-merge representation. We will also include a short ablation verifying these shared components on one dataset. revision: yes
-
Referee: [§4] §4 (Experiments): the reported results are described only in terms of qualitative trends across compression settings; the absence of tabulated quantitative metrics (e.g., exact captioning scores or accuracy deltas at each ratio) and full implementation details limits assessment of effect sizes and reproducibility.
Authors: We acknowledge that quantitative tables and expanded implementation details would improve assessment and reproducibility. The revision will include tables reporting exact captioning scores (CIDEr, SPIDEr) and MMAU accuracies at each compression ratio, together with deltas relative to the no-merge baseline. Full hyper-parameter settings, similarity-function details, and code-release information will be added to the main text or appendix. revision: yes
Circularity Check
No circularity; claims rest on direct empirical comparisons
full rationale
The paper introduces LTBM as a training-free compression method and evaluates it via experiments on AudioCaps, Clotho, and MMAU using Qwen2-Audio (plus cross-backbone validation). The central claim is a task-dependent locality effect observed in performance gaps between LTBM and a controlled Global Merge variant. No derivation chain, equations, or first-principles results are present that reduce to self-definitions, fitted parameters renamed as predictions, or self-citation load-bearing premises. The comparison is presented as an empirical isolation of the temporal window constraint, with no mathematical reduction or ansatz smuggling indicated in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InInter- national Conference on Learning Representations
Token Merging: Your ViT but faster. InInter- national Conference on Learning Representations. Qingqing Cao, Bhargavi Paranjape, and Hannaneh Ha- jishirzi. 2023. PuMer: Pruning and merging tokens for efficient vision language models. InProceed- ings of the Annual Meeting of the Association for Computational Linguistics. Liang Chen, Haozhe Zhao, Tianyu Liu,...
2023
-
[2]
Qwen2-Audio technical report.arXiv preprint arXiv:2407.10759. Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shil- iang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou. 2023. Qwen-Audio: Advancing universal audio understanding via unified large-scale audio- language models.arXiv preprint arXiv:2311.07919. Soham Deshmukh, Benjamin Elizalde, Rita Singh, and ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
InProceedings of the 2024 Conference on Empirical Methods in Natural Language Process- ing
GAMA: A large audio-language model with advanced audio understanding and complex reason- ing abilities. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Process- ing. Marcel Gibier, Raphael Duroselle, Pierre Serrano, Olivier Boeffard, and Jean-François Bonastre. 2025. Segmentwise pruning in audio-language models. arXiv preprin...
-
[4]
InProceedings of the AAAI Conference on Artificial Intelligence
Fit and prune: Fast and training-free visual token pruning for multi-modal large language models. InProceedings of the AAAI Conference on Artificial Intelligence. Qizhe Zhang, Aosong Cheng, Ming Lu, Zhiyong Zhuo, Minqi Wang, Jiajun Cao, Shaobo Guo, Qi She, and Shanghang Zhang. 2024. [CLS] attention is all you need for training-free visual token prun- ing:...
-
[5]
InProceed- ings of the IEEE/CVF International Conference on Computer Vision
AIM: Adaptive inference of multi-modal LLMs via token merging and pruning. InProceed- ings of the IEEE/CVF International Conference on Computer Vision
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.