DarkForest: Less Talk, Higher Accuracy for Multi-Agent LLMs
Pith reviewed 2026-06-30 10:47 UTC · model grok-4.3
The pith
DarkForest improves multi-agent LLM accuracy while cutting communication by keeping agents independent and coordinating only through parsed belief clusters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
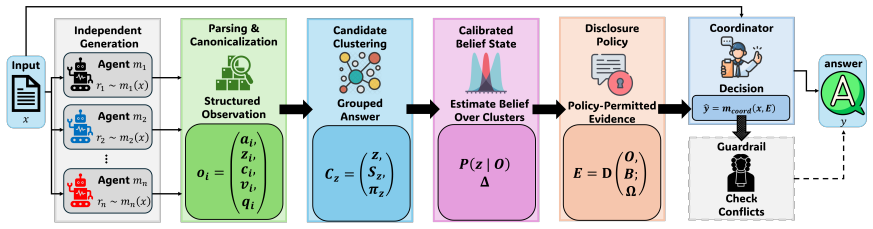
DarkForest keeps agents independent so each produces an answer without seeing others' outputs, parses the raw responses into structured candidate records, groups semantically equivalent candidates into clusters, estimates a calibrated belief distribution over these clusters using agent reliability, confidence, parse quality, support-pattern reliability, and independence corrections, and lets a coordinator receive only policy-permitted evidence from this belief state.
What carries the argument
The calibrated belief distribution over semantically clustered candidate records, built from reliability, confidence, parse quality, support patterns, and independence corrections.
If this is right
- Error propagation from incorrect intermediate reasoning is avoided because agents never see one another's raw outputs.
- Token consumption and latency drop sharply relative to multi-round communication baselines.
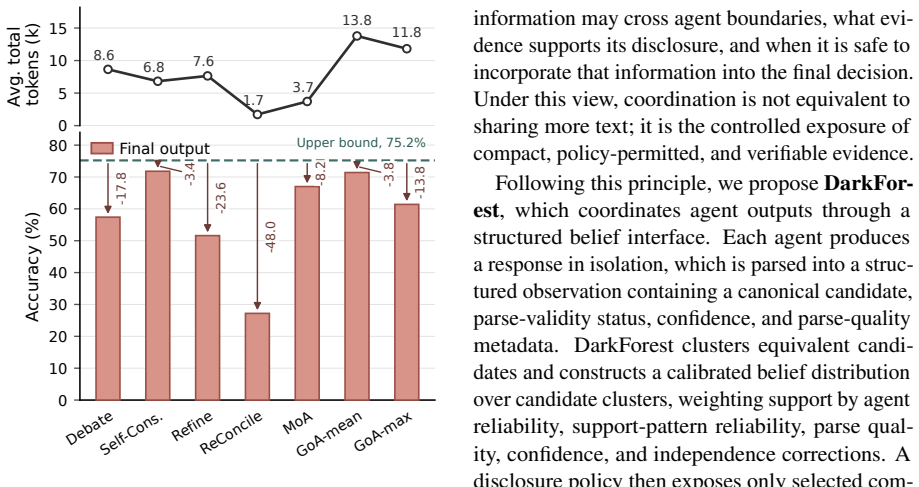
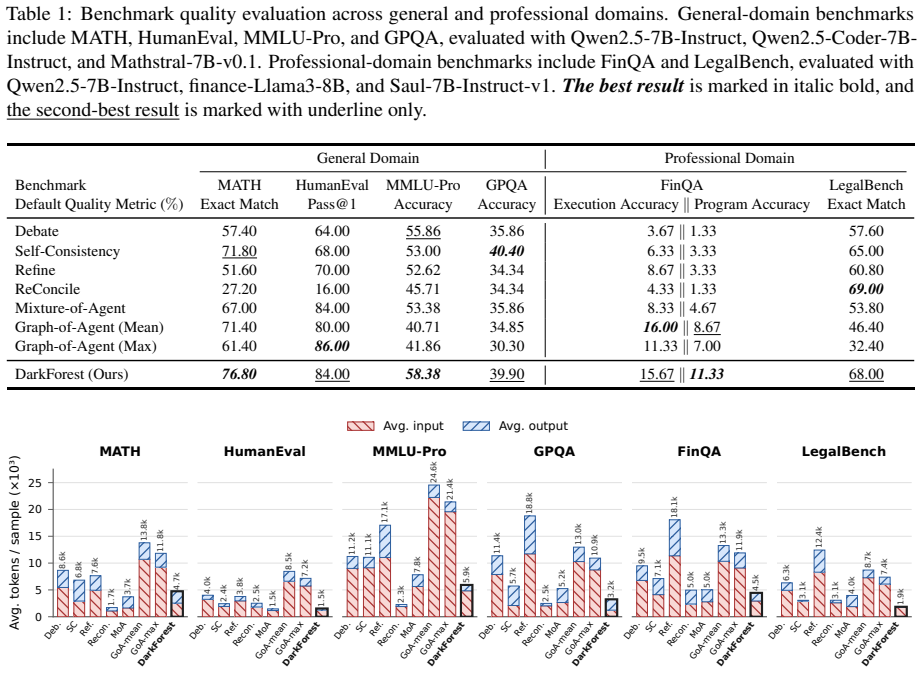
- Overall quality leads on six reasoning benchmarks with measured gains up to 30.7 percent.
- Communication volume can be limited by policy while still using evidence from the belief distribution.
Where Pith is reading between the lines
- The same parse-and-cluster step could be reused with other aggregation rules beyond the current belief estimator.
- Lower communication overhead may make it practical to run larger numbers of agents at fixed cost.
- The method's gains might shrink if the underlying LLMs already produce highly consistent answers without coordination.
Load-bearing premise
Parsing raw responses into structured records and clustering them by semantic equivalence produces accurate groups without injecting new errors that cancel the gains from belief estimation.
What would settle it
An experiment in which the clustering step repeatedly merges distinct answers or the belief weights consistently favor unreliable agents, producing final accuracy below that of simple majority vote on the same independent responses.
Figures
read the original abstract
Multi-agent LLM systems improve reasoning by combining outputs from multiple agents, but interaction-heavy methods can introduce error propagation and high communication overhead. When agents exchange raw responses or reasoning traces, incorrect intermediate reasoning may be adopted and amplified, leading to confident but wrong consensus; multi-round communication also increases token consumption, latency, and inference cost. In this paper, we propose a controlled-communication coordination framework named DarkForest. DarkForest first keeps agents independent, so each agent produces an answer without seeing the others' outputs. It then parses the raw responses into structured candidate records, groups semantically equivalent candidates into clusters, and estimates a calibrated belief distribution over these clusters using agent reliability, confidence, parse quality, support-pattern reliability, and independence corrections. A coordinator receives only policy-permitted evidence from this belief state with controlled communication. Experiments on six reasoning benchmarks show that DarkForest achieves leading overall quality, improves the strongest baseline by up to 30.7\% on benchmark metrics, and reduces token consumption by up to $6.5\times$ compared with communication-heavy baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DarkForest, a controlled-communication framework for multi-agent LLMs. Agents remain independent and produce answers without seeing others' outputs; raw responses are parsed into structured candidate records, grouped into semantically equivalent clusters, and used to estimate a calibrated belief distribution over clusters via agent reliability, confidence, parse quality, support-pattern reliability, and independence corrections. A coordinator then receives only policy-permitted evidence. Experiments on six reasoning benchmarks report leading overall quality, up to 30.7% improvement over the strongest baseline on benchmark metrics, and up to 6.5× reduction in token consumption versus communication-heavy baselines.
Significance. If the parsing, clustering, and belief-calibration steps prove reliable and the gains are robust, the framework could meaningfully advance multi-agent LLM systems by limiting error propagation from raw exchanges while cutting communication overhead. The reported token reductions and benchmark improvements, if reproducible with the missing implementation details, would constitute a practical contribution to efficient coordination.
major comments (3)
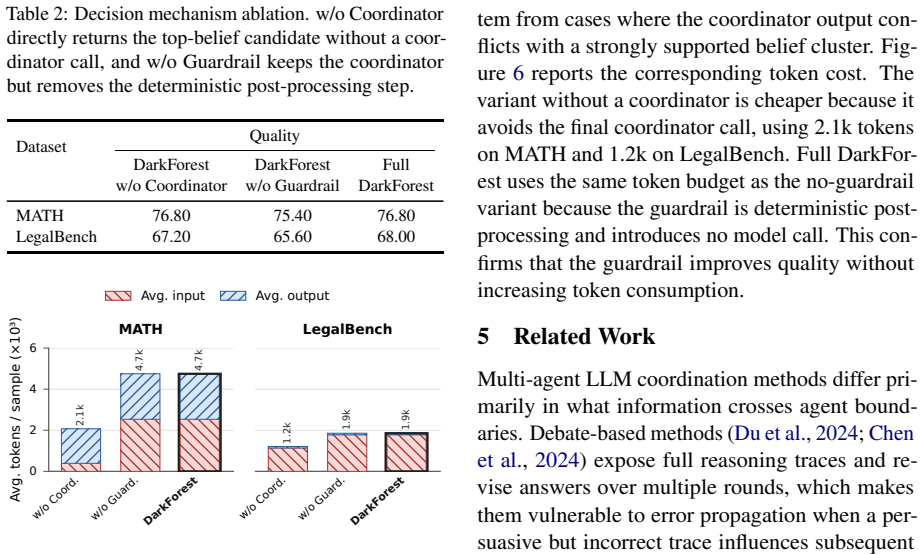
- [Abstract / Method] Abstract and method description: the central claim that the calibrated belief distribution improves final decisions rests on parsing raw responses, semantic clustering, and estimation from agent reliability, confidence, parse quality, support patterns, and independence corrections, yet no exact formulas, pseudocode, or derivation for the belief probabilities are supplied. Without these, it is impossible to determine whether the 30.7% gains arise from accurate probabilities or from unstated factors such as implicit majority voting.
- [Experiments] Experiments section: the reported 30.7% improvement and 6.5× token reduction are end-to-end results, but no separate quantification of semantic-clustering precision/recall, calibration metrics (e.g., Brier score), or ablation isolating the belief-estimation component is provided. This leaves open the possibility that observed gains are driven by other elements of the pipeline or that clustering errors are amplified.
- [Abstract] Abstract: the claims of leading quality and large gains are presented without error bars, statistical significance tests, or explicit data-exclusion rules, making it difficult to assess the reliability of the 30.7% and 6.5× figures across the six benchmarks.
minor comments (1)
- [Method] Notation for the belief-distribution factors (agent reliability, support-pattern reliability, independence corrections) is introduced without a consolidated table or explicit definitions, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and method description: the central claim that the calibrated belief distribution improves final decisions rests on parsing raw responses, semantic clustering, and estimation from agent reliability, confidence, parse quality, support patterns, and independence corrections, yet no exact formulas, pseudocode, or derivation for the belief probabilities are supplied. Without these, it is impossible to determine whether the 30.7% gains arise from accurate probabilities or from unstated factors such as implicit majority voting.
Authors: We agree that the submitted manuscript does not include the explicit formulas or pseudocode for computing the calibrated belief probabilities. This omission limits the ability to verify the precise contribution of the calibration step. In the revised manuscript we will add the full mathematical derivation of the belief distribution, incorporating the weighted contributions from agent reliability, per-agent confidence, parse quality, support-pattern reliability, and the independence correction term. We will also supply pseudocode for the complete estimation procedure. These additions will make clear that the reported gains derive from the calibrated probabilities rather than from implicit majority voting or other unstated mechanisms. revision: yes
-
Referee: [Experiments] Experiments section: the reported 30.7% improvement and 6.5× token reduction are end-to-end results, but no separate quantification of semantic-clustering precision/recall, calibration metrics (e.g., Brier score), or ablation isolating the belief-estimation component is provided. This leaves open the possibility that observed gains are driven by other elements of the pipeline or that clustering errors are amplified.
Authors: We concur that component-level evaluations would increase confidence in the source of the gains. The current experiments report only end-to-end results. In the revision we will add (i) an ablation that removes the belief-estimation module while keeping the rest of the pipeline fixed, (ii) precision and recall figures for the semantic clustering step evaluated on a held-out subset of responses, and (iii) calibration diagnostics including Brier score and expected calibration error for the estimated belief distributions. These new results will be placed in a dedicated subsection of the experiments. revision: yes
-
Referee: [Abstract] Abstract: the claims of leading quality and large gains are presented without error bars, statistical significance tests, or explicit data-exclusion rules, making it difficult to assess the reliability of the 30.7% and 6.5× figures across the six benchmarks.
Authors: The experiments were executed with multiple random seeds, yet the initial submission omitted error bars, significance testing, and explicit statements of data-exclusion criteria. In the revised version we will report mean performance together with standard deviation across seeds, include paired t-test results against the strongest baselines, and add a clear paragraph describing any data filtering or exclusion rules applied to the six benchmarks. These changes will appear both in the abstract (via a concise parenthetical note) and in the experiments section. revision: yes
Circularity Check
No circularity in derivation chain; method is procedural and empirically evaluated
full rationale
The paper describes a coordination procedure (independent agent responses, parsing to records, semantic clustering, calibrated belief estimation from reliability/confidence factors) without any equations, fitted parameters, or self-citations that reduce the claimed benchmark gains or token reductions to quantities defined by construction within the paper. Improvements are presented as measured outcomes on external benchmarks rather than derived tautologically from inputs. No load-bearing steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (3)
- agent reliability
- support-pattern reliability
- independence corrections
Reference graph
Works this paper leans on
-
[1]
Yi Li, Lianjie Cao, Faraz Ahmed, Puneet Sharma, and Bingzhe Li
A survey on llm-based multi-agent sys- tems: workflow, infrastructure, and challenges.Vici- nagearth, 1(1):9. Yi Li, Lianjie Cao, Faraz Ahmed, Puneet Sharma, and Bingzhe Li. 2026a. Hippocampus: An efficient and scalable memory module for agentic ai.arXiv preprint arXiv:2602.13594. Yi Li, Zhichun Guo, Guanpeng Li, and Bingzhe Li. 2026b. You only spectraliz...
-
[2]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harri- son Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe
IEEE. Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harri- son Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe
-
[3]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
Let’s verify step by step. InInternational Conference on Learning Representations, volume 2024, pages 39578–39601. Pan Lu, Baolin Peng, Hao Cheng, Michel Galley, Kai- Wei Chang, Ying Nian Wu, Song-Chun Zhu, and Jianfeng Gao. 2023. Chameleon: Plug-and-play com- positional reasoning with large language models.Ad- vances in Neural Information Processing Syst...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
arXiv preprint arXiv:2306.05443 , year=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Ad- vances in Neural Information Processing Systems, 37:95266–95290. 10 Zhexuan Wang, Yutong Wang, Xuebo Liu, Liang Ding, Miao Zhang, Jie Liu, and Min Zhang. 2025b. Agentdropout: Dynamic agent elimination for token- efficient and high-performance llm-based multi-agent coll...
-
[5]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Jingbo Yang, Kwei-Herng Lai, Xiaowen Wang, Shiyu Chang, Yaar Harari, and Evgeniy Gabrilovich. 2026a. Groupmembench: Benchmarking llm agent mem- ory in multi-party conversations.arXiv preprint arXiv:2605.14498. Qwen An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, D...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
ReAct: Synergizing Reasoning and Acting in Language Models
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629. Sukwon Yun, Jie Peng, Pingzh...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Graph-of-Agents: A Graph-based Framework for Multi-Agent LLM Collaboration
Graph-of-agents: A graph-based framework for multi-agent llm collaboration.arXiv preprint arXiv:2604.17148. Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. 2024. Expel: Llm agents are experiential learners. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19632–19642. Andy Zhou, Kai Yan, M...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.