Multi-view Consistent 3D Gaussian Head Avatars 'without' Multi-view Generation
Pith reviewed 2026-06-30 11:54 UTC · model grok-4.3
The pith
A state space model learns multi-view consistent 3D Gaussian head avatars directly from single 2D images without multi-view data or 3D supervision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
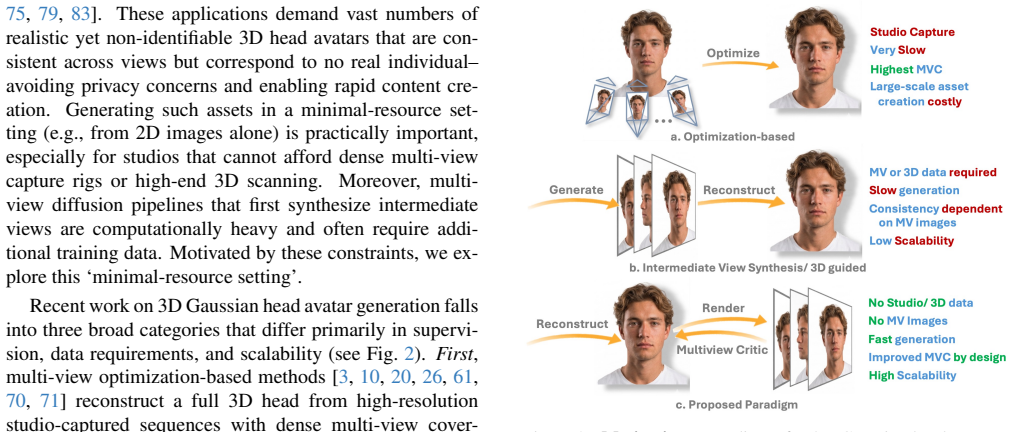
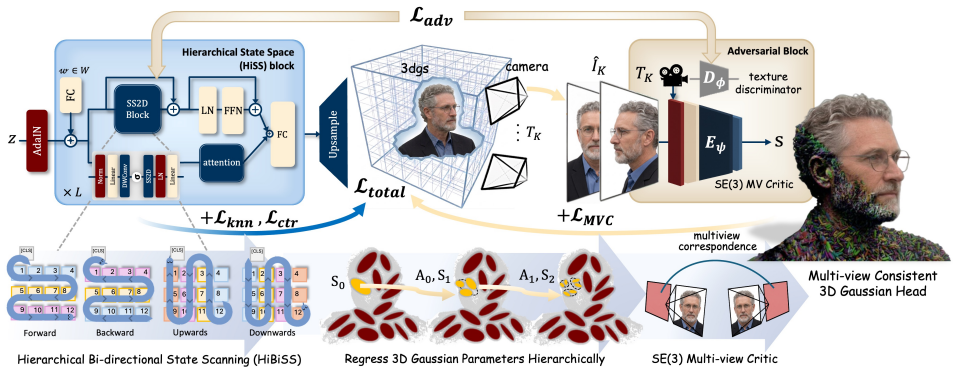
MVCHead is a single-shot model that enforces multi-view consistency directly in the 3D Gaussian representation by regressing Gaussians under the constraints of a Hierarchical State Space block equipped with a Hierarchical Bi-directional State Scan, combined with an SE(3) Multi-view Critic that rewards pixel alignment across self-renders without ever observing real multi-view pairs, yielding state-of-the-art perceptual quality together with improved texture and geometric consistency.
What carries the argument
The SE(3) Multi-view Critic, which judges whether a collection of self-renders arises from a single underlying 3D configuration and thereby supplies the consistency signal during training from 2D images alone.
If this is right
- 3D head avatars become trainable from ordinary single-image photo collections rather than specialized multi-view or 3D datasets.
- No intermediate 2D view synthesis step is required to achieve cross-view consistency.
- Both conditional (image-driven) and unconditional 3D head generation become possible under the same framework.
- A large-scale dataset of ready-to-use 3D Gaussian head assets is provided to support scaled training and evaluation.
Where Pith is reading between the lines
- If the critic generalizes, the same consistency mechanism could be applied to full-body or object-level 3D Gaussian reconstruction from single views.
- Training on web-scale 2D image collections becomes feasible, potentially increasing diversity of head appearances beyond studio-captured datasets.
- The hierarchical bi-directional scan may offer computational advantages over attention-based methods when processing long-range 3D dependencies.
Load-bearing premise
The SE(3) Multi-view Critic can reliably decide whether multiple self-renders come from one consistent 3D head without ever seeing genuine multi-view image pairs.
What would settle it
Train the model, render multiple views of the resulting Gaussians, and check whether the rendered pixels and recovered geometry remain consistent when compared against held-out real multi-view captures of the same subjects.
Figures


read the original abstract
High-fidelity 3D Gaussian head avatar generation is critical for applications such as AR/VR, telepresence, and digital humans. Existing methods depend on multi-view datasets, 3D captures, or intermediate 2D view synthesis. In contrast, we learn both conditional and unconditional 3D head models from randomly sampled 2D images alone, without using multi-view data, 3D supervision, or intermediate view generation. We introduce MVCHead, a single-shot state space model that enforces multi-view consistency (MVC) directly in the 3D representation while regressing 3D Gaussians under these constraints. At its core, we propose a Hierarchical State Space (HiSS) block that progressively refines Gaussians from coarse to fine, while capturing long-range dependencies. Within each HiSS block, we modify Mamba's standard unidirectional scan with the proposed Hierarchical Bi-directional State Scan (HiBiSS) that aligns recurrence with the axes along which multi-view inconsistencies are strongest. Finally, we design an SE(3) Multi-view Critic that judges whether a set of self-renders arises from a single underlying 3D configuration, rewarding cross-view pixel alignment without observing real multi-view pairs. MVCHead achieves state-of-the-art perceptual quality, surpasses prior methods in both texture and geometric consistency, and maintains comparable shape consistency. To demonstrate scalability, we release FaceGS-10K, the first large-scale dataset of ready-to-use 3D Gaussian head assets for training and evaluation of 3D head models. Project Page and code: https://humansensinglab.github.io/MVCHead/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MVCHead, a single-shot state space model for generating 3D Gaussian head avatars. It claims to learn both conditional and unconditional models directly from randomly sampled 2D images without multi-view data, 3D supervision, or intermediate view synthesis. The method uses Hierarchical State Space (HiSS) blocks with Hierarchical Bi-directional State Scan (HiBiSS) to refine Gaussians while capturing long-range dependencies, and an SE(3) Multi-view Critic trained on self-renders to enforce cross-view consistency. The authors also release the FaceGS-10K dataset and assert state-of-the-art perceptual quality along with improved texture and geometric consistency.
Significance. If the central claims hold, the work would represent a meaningful advance by removing the need for costly multi-view captures or 3D supervision in high-fidelity head avatar generation, potentially enabling larger-scale training from 2D image collections alone. The release of FaceGS-10K as a ready-to-use 3D Gaussian head asset dataset is a concrete community contribution that supports reproducibility and future benchmarking.
major comments (2)
- [Abstract] Abstract: The assertion of state-of-the-art perceptual quality and surpassing prior methods in texture and geometric consistency is presented without any quantitative metrics, ablation studies, or validation protocol details. This absence is load-bearing because the central claim of effective multi-view consistency without real multi-view pairs or 3D supervision cannot be assessed without evidence that the SE(3) critic produces measurable gains over baselines.
- [Abstract] SE(3) Multi-view Critic (as described): The mechanism by which the critic, trained exclusively on self-rendered images, distinguishes single underlying 3D configurations from view-inconsistent ones is not evidenced. If the SE(3) judgment reduces to 2D pixel-alignment heuristics rather than true geometric consistency, the no-multi-view training guarantee for both conditional and unconditional models collapses, directly affecting the HiSS/HiBiSS refinement pipeline.
minor comments (1)
- [Title] The title uses quotation marks around 'without'; a brief clarification in the introduction on the precise scope of this qualifier would aid reader expectations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below, drawing on details from the full manuscript while indicating planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion of state-of-the-art perceptual quality and surpassing prior methods in texture and geometric consistency is presented without any quantitative metrics, ablation studies, or validation protocol details. This absence is load-bearing because the central claim of effective multi-view consistency without real multi-view pairs or 3D supervision cannot be assessed without evidence that the SE(3) critic produces measurable gains over baselines.
Authors: The abstract provides a concise summary and omits specific numbers per standard practice. The full manuscript reports quantitative results in Section 4 (Tables 1–2) with perceptual metrics (FID, LPIPS) and consistency scores, plus ablations in Section 4.3 isolating the SE(3) critic’s contribution. We will revise the abstract to include one sentence citing the key measured gains (e.g., consistency improvement margins). revision: yes
-
Referee: [Abstract] SE(3) Multi-view Critic (as described): The mechanism by which the critic, trained exclusively on self-rendered images, distinguishes single underlying 3D configurations from view-inconsistent ones is not evidenced. If the SE(3) judgment reduces to 2D pixel-alignment heuristics rather than true geometric consistency, the no-multi-view training guarantee for both conditional and unconditional models collapses, directly affecting the HiSS/HiBiSS refinement pipeline.
Authors: Section 3.3 specifies that the critic receives self-renders under known SE(3) poses and is trained with a contrastive objective on synthetically generated consistent versus inconsistent Gaussian sets; the SE(3) pose encoding and Gaussian attribute inputs ensure the decision incorporates 3D geometry rather than pure 2D alignment. Ablations and qualitative results in Section 4.3 show inconsistencies that 2D heuristics alone cannot explain. We will expand the method description and add a short formalization of the critic loss if the current exposition is deemed insufficient. revision: partial
Circularity Check
No circularity; derivation relies on newly introduced architectural components.
full rationale
The paper's central derivation introduces independent components (HiSS blocks, HiBiSS scans, and the SE(3) Multi-view Critic) trained on self-renders to enforce consistency from single-view 2D images. No step reduces by construction to fitted inputs, self-citations, or renamed prior results; the critic's judgment mechanism is defined externally to the target consistency metric rather than presupposing it. The chain remains self-contained without load-bearing reductions to the paper's own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gaussian shell maps for efficient 3d human generation
Rameen Abdal, Wang Yifan, Zifan Shi, Yinghao Xu, Ryan Po, Zhengfei Kuang, Qifeng Chen, Dit-Yan Yeung, and Gor- don Wetzstein. Gaussian shell maps for efficient 3d human generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9441– 9451, 2024. 7
2024
-
[2]
Gaus- sianspeech: Audio-driven personalized 3d gaussian avatars
Shivangi Aneja, Artem Sevastopolsky, Tobias Kirschstein, Justus Thies, Angela Dai, and Matthias Nießner. Gaus- sianspeech: Audio-driven personalized 3d gaussian avatars. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13065–13075, 2025. 1
2025
-
[3]
Scaffoldavatar: High-fidelity gaussian avatars with patch expressions
Shivangi Aneja, Sebastian Weiss, Irene Baeza, Prashanth Chandran, Gaspard Zoss, Matthias Niessner, and Derek Bradley. Scaffoldavatar: High-fidelity gaussian avatars with patch expressions. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, pages 1–11, 2025. 2, 3
2025
-
[4]
Met3r: Measuring multi-view consistency in generated images
Mohammad Asim, Christopher Wewer, Thomas Wimmer, Bernt Schiele, and Jan Eric Lenssen. Met3r: Measuring multi-view consistency in generated images. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6034–6044, 2025. 6, 7, 8
2025
-
[5]
Gaussian splatting decoder for 3d-aware generative adversarial networks
Florian Barthel, Arian Beckmann, Wieland Morgenstern, Anna Hilsmann, and Peter Eisert. Gaussian splatting decoder for 3d-aware generative adversarial networks. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7963–7972, 2024. 2
2024
-
[6]
Cgs-gan: 3d consistent gaus- sian splatting gans for high resolution human head synthesis
Florian Barthel, Wieland Morgenstern, Paul Hinzer, Anna Hilsmann, and Peter Eisert. Cgs-gan: 3d consistent gaus- sian splatting gans for high resolution human head synthesis. arXiv preprint arXiv:2505.17590, 2025. 2, 3, 4, 6, 7, 8
-
[7]
Cafca: High-quality novel view synthesis of expressive faces from casual few-shot captures
Marcel C Buehler, Gengyan Li, Erroll Wood, Leonhard Helminger, Xu Chen, Tanmay Shah, Daoye Wang, Stephan Garbin, Sergio Orts-Escolano, Otmar Hilliges, et al. Cafca: High-quality novel view synthesis of expressive faces from casual few-shot captures. InSIGGRAPH Asia 2024 Confer- ence Papers, pages 1–12, 2024. 3
2024
-
[8]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. InPro- ceedings of the International Conference on Computer Vi- sion (ICCV), 2021. 7, 8
2021
-
[9]
Chan, Connor Z
Eric R. Chan, Connor Z. Lin, Matthew A. Chan, Koki Nagano, Boxiao Pan, Shalini de Mello, Orazio Gallo, Leonidas Guibas, Jonathan Tremblay, Sameh Khamis, Tero Karras, and Gordon Wetzstein. Efficient geometry-aware 3d generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16123–16133, 2022. 7
2022
-
[10]
Peng Chen, Xiaobao Wei, Qingpo Wuwu, Xinyi Wang, Xingyu Xiao, and Ming Lu. Mixedgaussianavatar: Realisti- cally and geometrically accurate head avatar via mixed 2d-3d gaussian splatting.arXiv preprint arXiv:2412.04955, 2024. 2, 3
-
[11]
Mimic3d: Thriving 3d-aware gans via 3d-to-2d imitation
Xingyu Chen, Yu Deng, and Baoyuan Wang. Mimic3d: Thriving 3d-aware gans via 3d-to-2d imitation. In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 2338–2348. IEEE Computer Society, 2023. 7
2023
-
[12]
Monogaus- sianavatar: Monocular gaussian point-based head avatar
Yufan Chen, Lizhen Wang, Qijing Li, Hongjiang Xiao, Shengping Zhang, Hongxun Yao, and Yebin Liu. Monogaus- sianavatar: Monocular gaussian point-based head avatar. In ACM SIGGRAPH 2024 Conference Papers, pages 1–9, 2024. 3
2024
-
[13]
Mv-ssm: multi-view state space modeling for 3d human pose estima- tion
Aviral Chharia, Wenbo Gou, and Haoye Dong. Mv-ssm: multi-view state space modeling for 3d human pose estima- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 11590–11599,
-
[14]
Generalizable and ani- matable gaussian head avatar.Advances in Neural Informa- tion Processing Systems, 37:57642–57670, 2024
Xuangeng Chu and Tatsuya Harada. Generalizable and ani- matable gaussian head avatar.Advances in Neural Informa- tion Processing Systems, 37:57642–57670, 2024. 3
2024
-
[15]
Xuangeng Chu, Yu Li, Ailing Zeng, Tianyu Yang, Lijian Lin, Yunfei Liu, and Tatsuya Harada. Gpavatar: Generaliz- able and precise head avatar from image (s).arXiv preprint arXiv:2401.10215, 2024. 3
-
[16]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 3
2009
-
[17]
Arcface: Additive angular margin loss for deep face recognition
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 4690–4699, 2019. 8
2019
-
[18]
Portrait4d: Learning one-shot 4d head avatar synthesis using synthetic data
Yu Deng, Duomin Wang, Xiaohang Ren, Xingyu Chen, and Baoyuan Wang. Portrait4d: Learning one-shot 4d head avatar synthesis using synthetic data. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7119–7130, 2024. 2, 3
2024
-
[19]
Portrait4d-v2: Pseudo multi-view data creates better 4d head synthesizer
Yu Deng, Duomin Wang, and Baoyuan Wang. Portrait4d-v2: Pseudo multi-view data creates better 4d head synthesizer. In European Conference on Computer Vision, pages 316–333. Springer, 2024. 2, 3
2024
-
[20]
Headgas: Real-time animatable head avatars via 3d gaus- sian splatting
Helisa Dhamo, Yinyu Nie, Arthur Moreau, Jifei Song, Richard Shaw, Yiren Zhou, and Eduardo P ´erez-Pellitero. Headgas: Real-time animatable head avatars via 3d gaus- sian splatting. InEuropean Conference on Computer Vision, pages 459–476. Springer, 2024. 2, 3
2024
-
[21]
Hamba: Single-view 3d hand reconstruction with graph-guided bi-scanning mamba
Haoye Dong, Aviral Chharia, Wenbo Gou, Francisco Vicente Carrasco, and Fernando De la Torre. Hamba: Single-view 3d hand reconstruction with graph-guided bi-scanning mamba. arXiv preprint arXiv:2407.09646, 2024. 3
-
[22]
Gpa- vatar: High-fidelity head avatars by learning efficient gaus- sian projections
Wei-Qi Feng, Dong Han, Ze-Kang Zhou, Shunkai Li, Xiao- qiang Liu, Pengfei Wan, Di Zhang, and Miao Wang. Gpa- vatar: High-fidelity head avatars by learning efficient gaus- sian projections. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 250–259, 2025. 3
2025
-
[23]
Brandt, Axel Feld- mann, Zhoutong Zhang, and William T
Stephanie Fu, Mark Hamilton, Laura E. Brandt, Axel Feld- mann, Zhoutong Zhang, and William T. Freeman. Featup: A model-agnostic framework for features at any resolution. InThe Twelfth International Conference on Learning Repre- sentations, 2024. 7, 8 9
2024
-
[24]
Spinmeround: Consistent multi-view identity generation using diffusion models
Stathis Galanakis, Alexandros Lattas, Stylianos Moschoglou, Bernhard Kainz, and Stefanos Zafeiriou. Spinmeround: Consistent multi-view identity generation using diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14346–14356, 2025. 2, 3
2025
-
[25]
Mononphm: Dynamic head reconstruction from monocu- lar videos
Simon Giebenhain, Tobias Kirschstein, Markos Georgopou- los, Martin R ¨unz, Lourdes Agapito, and Matthias Nießner. Mononphm: Dynamic head reconstruction from monocu- lar videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10747– 10758, 2024. 3
2024
-
[26]
Npga: Neural paramet- ric gaussian avatars
Simon Giebenhain, Tobias Kirschstein, Martin R ¨unz, Lour- des Agapito, and Matthias Nießner. Npga: Neural paramet- ric gaussian avatars. InSIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024. 2, 3
2024
-
[27]
Mamba: Linear-time sequence mod- eling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence mod- eling with selective state spaces. InFirst conference on lan- guage modeling, 2024. 3, 4
2024
-
[28]
Efficiently Modeling Long Sequences with Structured State Spaces
Albert Gu, Karan Goel, and Christopher R ´e. Efficiently modeling long sequences with structured state spaces.arXiv preprint arXiv:2111.00396, 2021. 3
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[29]
Combining recurrent, convolutional, and continuous-time models with linear state space layers.Advances in neural information processing sys- tems, 34:572–585, 2021
Albert Gu, Isys Johnson, Karan Goel, Khaled Saab, Tri Dao, Atri Rudra, and Christopher R ´e. Combining recurrent, convolutional, and continuous-time models with linear state space layers.Advances in neural information processing sys- tems, 34:572–585, 2021. 3
2021
-
[30]
Stylenerf: A style-based 3d aware generator for high- resolution image synthesis
Jiatao Gu, Lingjie Liu, Peng Wang, and Christian Theobalt. Stylenerf: A style-based 3d aware generator for high- resolution image synthesis. InInternational Conference on Learning Representations, 2022. 7
2022
-
[31]
Diffportrait3d: Controllable diffusion for zero-shot portrait view synthesis
Yuming Gu, Hongyi Xu, You Xie, Guoxian Song, Yichun Shi, Di Chang, Jing Yang, and Linjie Luo. Diffportrait3d: Controllable diffusion for zero-shot portrait view synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10456–10465, 2024. 2, 3
2024
-
[32]
Diffportrait360: Consis- tent portrait diffusion for 360 view synthesis
Yuming Gu, Phong Tran, Yujian Zheng, Hongyi Xu, Heyuan Li, Adilbek Karmanov, and Hao Li. Diffportrait360: Consis- tent portrait diffusion for 360 view synthesis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26263–26273, 2025. 2, 3
2025
-
[33]
Pct: Point cloud transformer.Computational visual media, 7(2):187–199,
Meng-Hao Guo, Jun-Xiong Cai, Zheng-Ning Liu, Tai-Jiang Mu, Ralph R Martin, and Shi-Min Hu. Pct: Point cloud transformer.Computational visual media, 7(2):187–199,
-
[34]
Mambavision: A hybrid mamba-transformer vision backbone
Ali Hatamizadeh and Jan Kautz. Mambavision: A hybrid mamba-transformer vision backbone. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 25261–25270, 2025. 3
2025
-
[35]
Lam: Large avatar model for one-shot animatable gaus- sian head
Yisheng He, Xiaodong Gu, Xiaodan Ye, Chao Xu, Zhengyi Zhao, Yuan Dong, Weihao Yuan, Zilong Dong, and Liefeng Bo. Lam: Large avatar model for one-shot animatable gaus- sian head. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, pages 1–13, 2025. 3
2025
-
[36]
Ding-Jiun Huang, Yuanhao Wang, Shao-Ji Yuan, Al- bert Mosella-Montoro, Francisco Vicente Carrasco, Cheng Zhang, and Fernando De la Torre. From blurry to believable: Enhancing low-quality talking heads with 3d generative pri- ors.arXiv preprint arXiv:2602.06122, 2026. 1
-
[37]
Arbitrary style transfer in real-time with adaptive instance normalization
Xun Huang and Serge Belongie. Arbitrary style transfer in real-time with adaptive instance normalization. InProceed- ings of the IEEE international conference on computer vi- sion, pages 1501–1510, 2017. 4
2017
-
[38]
Gsgan: Adversarial learning for hierarchical generation of 3d gaussian splats.Advances in Neural Information Processing Systems, 37:67987–68012,
Sangeek Hyun and Jae-Pil Heo. Gsgan: Adversarial learning for hierarchical generation of 3d gaussian splats.Advances in Neural Information Processing Systems, 37:67987–68012,
-
[39]
A new approach to linear filtering and prediction problems
Rudolph Emil Kalman. A new approach to linear filtering and prediction problems. 1960. 3
1960
-
[40]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 4401–4410, 2019. 6, 7, 8
2019
-
[41]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1,
-
[42]
Nersemble: Multi-view radi- ance field reconstruction of human heads.ACM Transactions on Graphics (TOG), 42(4):1–14, 2023
Tobias Kirschstein, Shenhan Qian, Simon Giebenhain, Tim Walter, and Matthias Nießner. Nersemble: Multi-view radi- ance field reconstruction of human heads.ACM Transactions on Graphics (TOG), 42(4):1–14, 2023. 2, 3, 7, 8
2023
-
[43]
Diffusionavatars: Deferred diffusion for high- fidelity 3d head avatars
Tobias Kirschstein, Simon Giebenhain, and Matthias Nießner. Diffusionavatars: Deferred diffusion for high- fidelity 3d head avatars. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5481–5492, 2024. 3
2024
-
[44]
Gghead: Fast and generalizable 3d gaussian heads
Tobias Kirschstein, Simon Giebenhain, Jiapeng Tang, Markos Georgopoulos, and Matthias Nießner. Gghead: Fast and generalizable 3d gaussian heads. InSIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024. 2, 3, 7
2024
-
[45]
Tobias Kirschstein, Javier Romero, Artem Sevastopolsky, Matthias Nießner, and Shunsuke Saito. Avat3r: Large an- imatable gaussian reconstruction model for high-fidelity 3d head avatars.arXiv preprint arXiv:2502.20220, 2025. 1
-
[46]
Ground- ing image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and J´erˆome Revaud. Ground- ing image matching in 3d with mast3r. InEuropean Confer- ence on Computer Vision, pages 71–91. Springer, 2024. 7
2024
-
[47]
Rgbavatar: Reduced gaussian blendshapes for online modeling of head avatars
Linzhou Li, Yumeng Li, Yanlin Weng, Youyi Zheng, and Kun Zhou. Rgbavatar: Reduced gaussian blendshapes for online modeling of head avatars. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10747–10757, 2025. 3
2025
-
[48]
Peng Li, Yisheng He, Yingdong Hu, Yuan Dong, Weihao Yuan, Yuan Liu, Siyu Zhu, Gang Cheng, Zilong Dong, and Yike Guo. Panolam: Large avatar model for gaussian full- head synthesis from one-shot unposed image.arXiv preprint arXiv:2509.07552, 2025. 3
-
[49]
Mamba- nd: Selective state space modeling for multi-dimensional data
Shufan Li, Harkanwar Singh, and Aditya Grover. Mamba- nd: Selective state space modeling for multi-dimensional data. InEuropean Conference on Computer Vision, pages 75–92. Springer, 2024. 3 10
2024
-
[50]
Learning a model of facial shape and expression from 4d scans.ACM Trans
Tianye Li, Timo Bolkart, Michael J Black, Hao Li, and Javier Romero. Learning a model of facial shape and expression from 4d scans.ACM Trans. Graph., 36(6):194–1, 2017. 3, 8
2017
-
[51]
Soap: Style- omniscient animatable portraits
Tingting Liao, Yujian Zheng, Yuliang Xiu, Adilbek Kar- manov, Liwen Hu, Leyang Jin, and Hao Li. Soap: Style- omniscient animatable portraits. InProceedings of the Spe- cial Interest Group on Computer Graphics and Interac- tive Techniques Conference Conference Papers, pages 1–11,
-
[52]
Vmamba: Visual state space model.Advances in neural information processing systems, 37:103031–103063, 2024
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, Jianbin Jiao, and Yunfan Liu. Vmamba: Visual state space model.Advances in neural information processing systems, 37:103031–103063, 2024. 3, 4, 5
2024
-
[53]
Zhibin Liu, Haoye Dong, Aviral Chharia, and Hefeng Wu. Human-vdm: Learning single-image 3d human gaussian splatting from video diffusion models.arXiv preprint arXiv:2409.02851, 2024. 1
-
[54]
Facelift: Learning generalizable single image 3d face re- construction from synthetic heads
Weijie Lyu, Yi Zhou, Ming-Hsuan Yang, and Zhixin Shu. Facelift: Learning generalizable single image 3d face re- construction from synthetic heads. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12691–12701, 2025. 2, 3
2025
-
[55]
Jewett, Simon Ven- shtain, Christopher Heilman, Yueh-Tung Chen, Sidi Fu, Mo- hamed Ezzeldin A
Julieta Martinez, Emily Kim, Javier Romero, Timur Bagaut- dinov, Shunsuke Saito, Shoou-I Yu, Stuart Anderson, Michael Zollh ¨ofer, Te-Li Wang, Shaojie Bai, Chenghui Li, Shih-En Wei, Rohan Joshi, Wyatt Borsos, Tomas Simon, Jason Saragih, Paul Theodosis, Alexander Greene, Anjani Josyula, Silvio Mano Maeta, Andrew I. Jewett, Simon Ven- shtain, Christopher He...
2024
-
[56]
Gta: A geometry-aware attention mechanism for multi-view transformers
Takeru Miyato, Bernhard Jaeger, Max Welling, and Andreas Geiger. Gta: A geometry-aware attention mechanism for multi-view transformers. InInternational Conference on Learning Representations (ICLR), 2024. 5
2024
-
[57]
Point-E: A System for Generating 3D Point Clouds from Complex Prompts
Alex Nichol, Heewoo Jun, Prafulla Dhariwal, Pamela Mishkin, and Mark Chen. Point-e: A system for generat- ing 3d point clouds from complex prompts.arXiv preprint arXiv:2212.08751, 2022. 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[58]
Stylesdf: High-resolution 3d-consistent image and geome- try generation
Roy Or-El, Xuan Luo, Mengyi Shan, Eli Shecht- man, Jeong Joon Park, and Ira Kemelmacher-Shlizerman. Stylesdf: High-resolution 3d-consistent image and geome- try generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13503– 13513, 2022. 7
2022
-
[59]
PercHead: Perceptual Head Model for Single-Image 3D Head Reconstruction & Editing
Antonio Oroz, Matthias Nießner, and Tobias Kirschstein. Perchead: Perceptual head model for single-image 3d head reconstruction & editing.arXiv preprint arXiv:2511.02777,
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Renderme-360: A large dig- ital asset library and benchmarks towards high-fidelity head avatars.Advances in Neural Information Processing Sys- tems, 36:7993–8005, 2023
Dongwei Pan, Long Zhuo, Jingtan Piao, Huiwen Luo, Wei Cheng, Yuxin Wang, Siming Fan, Shengqi Liu, Lei Yang, Bo Dai, Ziwei Liu, Chen Change Loy, Chen Qian, Wayne Wu, Dahua Lin, and Kwan-Yee Lin. Renderme-360: A large dig- ital asset library and benchmarks towards high-fidelity head avatars.Advances in Neural Information Processing Sys- tems, 36:7993–8005, ...
2023
-
[61]
Gaus- sianavatars: Photorealistic head avatars with rigged 3d gaus- sians
Shenhan Qian, Tobias Kirschstein, Liam Schoneveld, Davide Davoli, Simon Giebenhain, and Matthias Nießner. Gaus- sianavatars: Photorealistic head avatars with rigged 3d gaus- sians. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 20299–20309,
-
[62]
V oxgraf: Fast 3d-aware image synthe- sis with sparse voxel grids.Advances in Neural Information Processing Systems, 35:33999–34011, 2022
Katja Schwarz, Axel Sauer, Michael Niemeyer, Yiyi Liao, and Andreas Geiger. V oxgraf: Fast 3d-aware image synthe- sis with sparse voxel grids.Advances in Neural Information Processing Systems, 35:33999–34011, 2022. 7
2022
-
[63]
Splattingavatar: Realistic real-time human avatars with mesh-embedded gaussian splatting
Zhijing Shao, Zhaolong Wang, Zhuang Li, Duotun Wang, Xiangru Lin, Yu Zhang, Mingming Fan, and Zeyu Wang. Splattingavatar: Realistic real-time human avatars with mesh-embedded gaussian splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1606–1616, 2024. 3
2024
-
[64]
Gamba: Marry gaussian splatting with mamba for single-view 3d recon- struction.IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 2025
Qiuhong Shen, Zike Wu, Xuanyu Yi, Pan Zhou, Hanwang Zhang, Shuicheng Yan, and Xinchao Wang. Gamba: Marry gaussian splatting with mamba for single-view 3d recon- struction.IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 2025. 3
2025
-
[65]
Epigraf: Rethinking training of 3d gans.Advances in Neural Information Processing Systems, 35:24487–24501,
Ivan Skorokhodov, Sergey Tulyakov, Yiqun Wang, and Peter Wonka. Epigraf: Rethinking training of 3d gans.Advances in Neural Information Processing Systems, 35:24487–24501,
-
[66]
DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, and Gang Zeng. Dreamgaussian: Generative gaussian splatting for effi- cient 3d content creation.arXiv preprint arXiv:2309.16653,
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
Gaf: Gaussian avatar reconstruction from monocular videos via multi-view diffu- sion
Jiapeng Tang, Davide Davoli, Tobias Kirschstein, Liam Schoneveld, and Matthias Niessner. Gaf: Gaussian avatar reconstruction from monocular videos via multi-view diffu- sion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5546–5558, 2025. 3
2025
-
[68]
Mvp4d: Multi-view portrait video diffusion for animatable 4d avatars
Felix Taubner, Ruihang Zhang, Mathieu Tuli, Sherwin Bah- mani, and David B Lindell. Mvp4d: Multi-view portrait video diffusion for animatable 4d avatars. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–11,
2025
-
[69]
Cap4d: Creating animatable 4d portrait avatars with morphable multi-view diffusion models
Felix Taubner, Ruihang Zhang, Mathieu Tuli, and David B Lindell. Cap4d: Creating animatable 4d portrait avatars with morphable multi-view diffusion models. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5318–5330. IEEE Computer Society, 2025. 2, 3, 7 11
2025
-
[70]
Gaus- sianheads: End-to-end learning of drivable gaussian head avatars from coarse-to-fine representations.ACM Transac- tions on Graphics (TOG), 43(6):1–12, 2024
Kartik Teotia, Hyeongwoo Kim, Pablo Garrido, Marc Haber- mann, Mohamed Elgharib, and Christian Theobalt. Gaus- sianheads: End-to-end learning of drivable gaussian head avatars from coarse-to-fine representations.ACM Transac- tions on Graphics (TOG), 43(6):1–12, 2024. 2, 3
2024
-
[71]
3d gaussian head avatars with expressive dynamic appearances by compact tensorial representations
Yating Wang, Xuan Wang, Ran Yi, Yanbo Fan, Jichen Hu, Jingcheng Zhu, and Lizhuang Ma. 3d gaussian head avatars with expressive dynamic appearances by compact tensorial representations. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21117–21126, 2025. 2, 3
2025
-
[72]
Vfhq: A high-quality dataset and bench- mark for video face super-resolution
Liangbin Xie, Xintao Wang, Honglun Zhang, Chao Dong, and Ying Shan. Vfhq: A high-quality dataset and bench- mark for video face super-resolution. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 657–666, 2022. 3
2022
-
[73]
Mvgbench: Com- prehensive benchmark for multi-view generation models
Xianghui Xie, Chuhang Zou, Meher Gitika Karumuri, Jan Eric Lenssen, and Gerard Pons-Moll. Mvgbench: Com- prehensive benchmark for multi-view generation models. arXiv preprint arXiv:2507.00006, 2025. 6, 7
-
[74]
Gaussian head avatar: Ultra high-fidelity head avatar via dynamic gaussians
Yuelang Xu, Benwang Chen, Zhe Li, Hongwen Zhang, Lizhen Wang, Zerong Zheng, and Yebin Liu. Gaussian head avatar: Ultra high-fidelity head avatar via dynamic gaussians. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 1931–1941, 2024. 3
1931
-
[75]
Peizhi Yan, Rabab Ward, Qiang Tang, and Shan Du. Gaus- sian d´ej`a-vu: Creating controllable 3d gaussian head-avatars with enhanced generalization and personalization abilities. arXiv preprint arXiv:2409.16147, 2024. 2
-
[76]
Facescape: a large-scale high quality 3d face dataset and detailed riggable 3d face pre- diction
Haotian Yang, Hao Zhu, Yanru Wang, Mingkai Huang, Qiu Shen, Ruigang Yang, and Xun Cao. Facescape: a large-scale high quality 3d face dataset and detailed riggable 3d face pre- diction. InProceedings of the ieee/cvf conference on com- puter vision and pattern recognition, pages 601–610, 2020. 8
2020
-
[77]
Mvgamba: Unify 3d content generation as state space sequence modeling.Advances in Neural Infor- mation Processing Systems, 37:7580–7607, 2024
Xuanyu Yi, Zike Wu, Qiuhong Shen, Qingshan Xu, Pan Zhou, Joo-Hwee Lim, Shuicheng Yan, Xinchao Wang, and Hanwang Zhang. Mvgamba: Unify 3d content generation as state space sequence modeling.Advances in Neural Infor- mation Processing Systems, 37:7580–7607, 2024. 3
2024
-
[78]
Facecraft4d: Animated 3d facial avatar generation from a single image
Fei Yin, Chun-Han Yao, Rafal K Mantiuk, Varun Jampani, et al. Facecraft4d: Animated 3d facial avatar generation from a single image. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 11612–11621,
-
[79]
Hravatar: High-quality and relightable gaussian head avatar
Dongbin Zhang, Yunfei Liu, Lijian Lin, Ye Zhu, Kangjie Chen, Minghan Qin, Yu Li, and Haoqian Wang. Hravatar: High-quality and relightable gaussian head avatar. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 26285–26296, 2025. 2
2025
-
[80]
Fate: Full- head gaussian avatar with textural editing from monocular video
Jiawei Zhang, Zijian Wu, Zhiyang Liang, Yicheng Gong, Dongfang Hu, Yao Yao, Xun Cao, and Hao Zhu. Fate: Full- head gaussian avatar with textural editing from monocular video. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5535–5545, 2025. 3
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.