Data-Specific Hyper-Parameter Design: A Paradigm Shift in Reservoir Computing
Pith reviewed 2026-06-29 23:27 UTC · model grok-4.3
The pith
Requiring reservoir state increments to align within a cone around an input subspace reduces ridge-regression training error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors prove that cone concentration of reservoir state increments around an input-determined vector subspace reduces ridge-regression training error by concentrating variance in that subspace, which improves conditioning of the empirical second-moment matrix and aligns dominant covariance directions with the state-target cross-covariance.
What carries the argument
Cone concentration of reservoir state increments around an input-determined vector subspace, which works by concentrating variance and strengthening covariance alignment for training.
If this is right
- Improved conditioning of the empirical second-moment matrix for ridge regression.
- Enhanced alignment between dominant covariance directions and state-target cross-covariance.
- Constructive reservoir matrix choice for echo state networks that keeps Krylov-chain directions nearly closed in the subspace.
- Spectral diagnostic to identify when geometry concentrates predictive information into few modes or when spectral pollution inhibits forecasting.
Where Pith is reading between the lines
- The geometric design may enable smaller reservoirs to match the performance of large random ones by exploiting input structure.
- The cone-alignment principle could extend to other recurrent or embedding-based models that currently rely on random projections.
- Testing the method on inputs that only approximately satisfy the deterministic low-dimensional assumption would clarify its practical scope.
- Links to subspace tracking techniques in dynamical systems identification could yield hybrid forecasting methods.
Load-bearing premise
The inputs are generated by deterministic dynamical systems whose history can be captured by a low-dimensional subspace that the reservoir can track without violating stability or echo-state conditions.
What would settle it
A numerical experiment on deterministic inputs where cone-aligned reservoirs show no reduction in ridge-regression error compared to random reservoirs, or where enforcing the cone alignment violates the echo state property.
Figures


read the original abstract
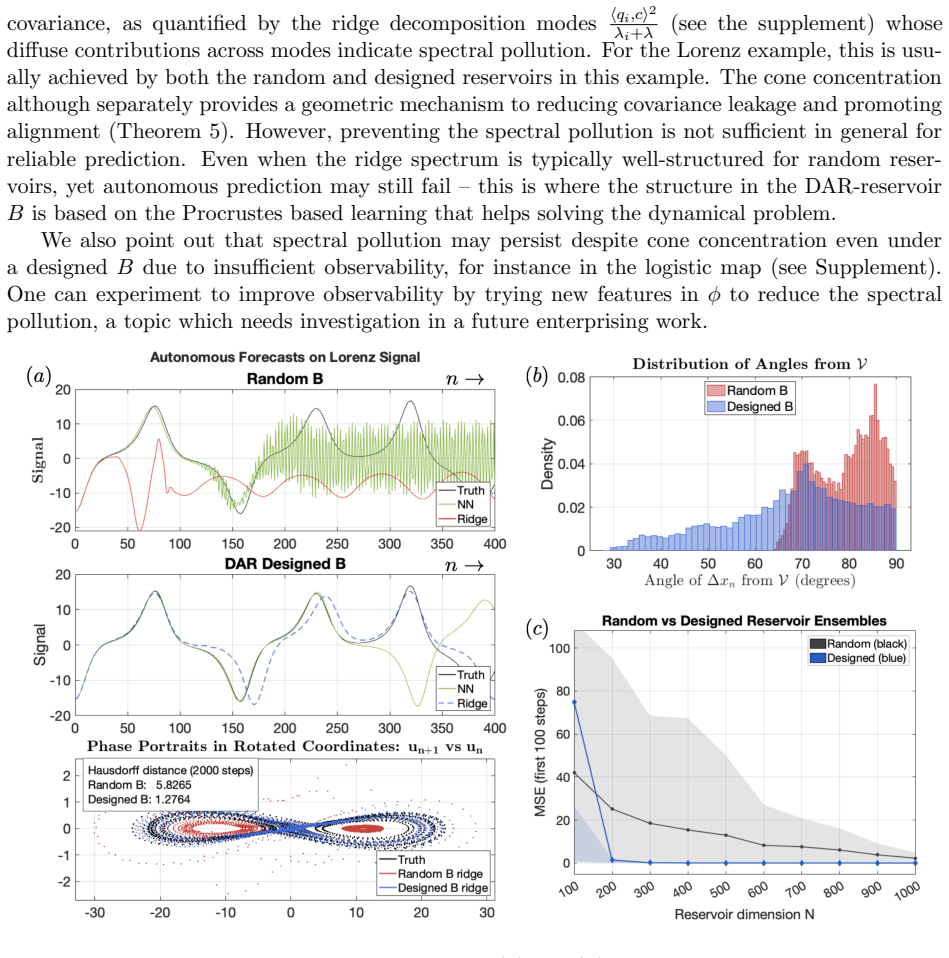
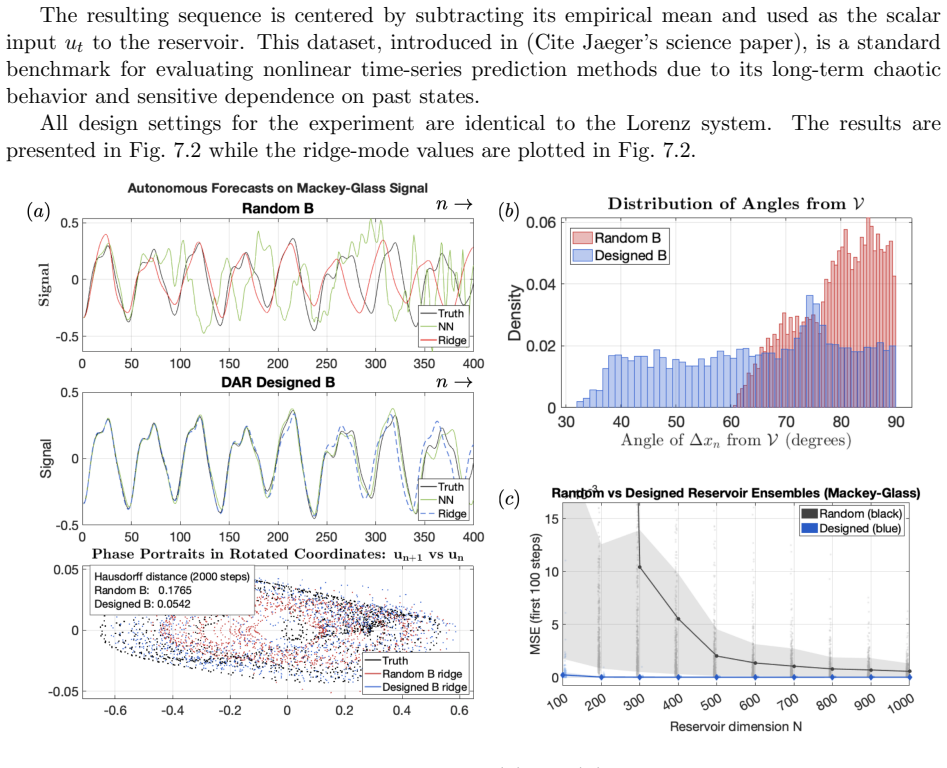
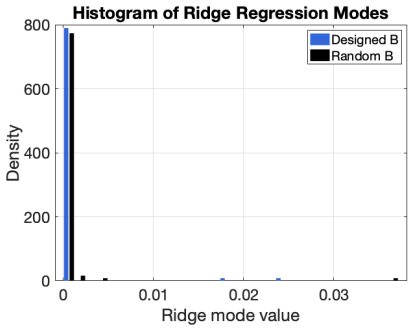
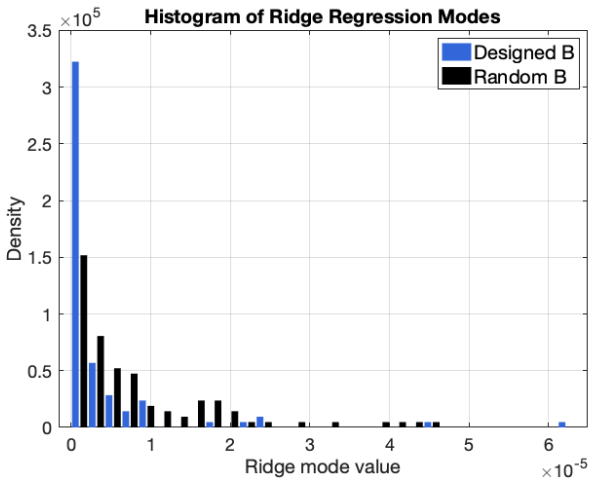
Reservoir computing typically relies on large, randomly generated reservoirs, enabling simple, often linear readouts. Over the past two decades, most constructions have exploited the freedom to select the reservoir, constrained primarily by stability conditions based on state contraction or memory capacity. However, these designs are largely independent of the input data and learning objective, resulting in a trial-and-error methodology driven by randomness. In high dimensions, the reservoir acts as a random embedding of the input history, implicitly relying on Johnson--Lindenstrauss--type concentration phenomena to preserve information. In contrast, we develop reservoir design principles from a geometric perspective for inputs generated by deterministic dynamical systems. Rather than relying on random embeddings, we require reservoir state increments to align within a cone around an input-determined vector subspace, and prove that such a cone concentration reduces ridge-regression training error. When the cone angle is small, the variance of reservoir states concentrates in the input-determined subspace, improving conditioning of the empirical second-moment matrix and strengthening alignment between dominant covariance directions and the state-target cross-covariance. For echo state networks, we provide a constructive approach to reservoir design. The reservoir matrix is chosen so that associated Krylov-chain directions remain nearly closed within an input-determined subspace while permitting controlled mixing in its orthogonal complement. We also provide a spectral diagnostic for ridge regression training that identifies when reservoir geometry concentrates predictive information into a few dominant covariance modes and when ``spectral pollution'' inhibits forecasting. Numerical experiments demonstrate consistent performance gains over arbitrary reservoir constructions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a data-specific geometric design principle for reservoirs in echo-state networks (ESNs) driven by deterministic dynamical systems. It requires state increments to lie inside a cone around an input-determined low-dimensional linear subspace, asserts a proof that this concentration reduces ridge-regression training error via improved conditioning of the second-moment matrix and better covariance alignment, supplies a constructive Krylov-based reservoir matrix that keeps directions nearly closed in the subspace while allowing controlled orthogonal mixing, introduces a spectral diagnostic for predictive information concentration versus spectral pollution, and reports consistent numerical gains over random reservoirs.
Significance. If the central geometric claim and proof are valid, the work offers a principled, data-dependent alternative to the prevailing random-embedding paradigm in reservoir computing, potentially reducing reliance on trial-and-error hyper-parameter search while preserving echo-state stability. The constructive ESN design and spectral diagnostic constitute concrete, falsifiable contributions that could be tested on standard forecasting benchmarks.
major comments (3)
- [Abstract and constructive approach for ESNs] Abstract (geometric perspective paragraph) and constructive approach section: the claim that reservoir increments can be forced to track a fixed low-dimensional linear subspace without violating the echo-state contraction condition rests on the unproven assumption that the input history of a general deterministic dynamical system lies in such a subspace. For nonlinear attractors the effective dimension (via Lyapunov exponents or delay embedding) can exceed the assumed rank, forcing either large cone angles or large orthogonal mixing that risks breaking the contraction mapping; this is load-bearing for both the proof and the constructive method.
- [Abstract and ridge-regression analysis] Abstract (proof claim) and § on ridge-regression training error: the asserted proof that cone concentration reduces training error via improved conditioning and cross-covariance alignment is stated without the intermediate steps, the precise mathematical definition of the cone, or the data-exclusion rules used to define the input-determined subspace. These omissions prevent verification that the reduction is not achieved by construction or by post-hoc fitting.
- [Numerical experiments] Numerical experiments section: the reported performance gains lack error bars, statistical significance tests, and explicit baseline comparisons (e.g., against standard spectral-radius-tuned random ESNs or other data-driven methods), making it impossible to assess whether the gains are robust or merely consistent with the chosen examples.
minor comments (2)
- [Geometric perspective] Notation for the input-determined subspace and cone angle should be introduced with a single, unambiguous definition early in the geometric perspective section rather than appearing piecemeal.
- [Spectral diagnostic] The spectral diagnostic would benefit from an explicit algorithmic statement or pseudocode so that readers can reproduce the identification of dominant covariance modes versus spectral pollution.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. We address each major comment point by point below, indicating planned revisions where the manuscript requires strengthening.
read point-by-point responses
-
Referee: [Abstract and constructive approach for ESNs] Abstract (geometric perspective paragraph) and constructive approach section: the claim that reservoir increments can be forced to track a fixed low-dimensional linear subspace without violating the echo-state contraction condition rests on the unproven assumption that the input history of a general deterministic dynamical system lies in such a subspace. For nonlinear attractors the effective dimension (via Lyapunov exponents or delay embedding) can exceed the assumed rank, forcing either large cone angles or large orthogonal mixing that risks breaking the contraction mapping; this is load-bearing for both the proof and the constructive method.
Authors: The input-determined subspace is not presupposed but is explicitly constructed from the observed input history, for instance via the leading singular vectors of a delay-embedded input matrix or the Krylov subspace generated by the driving sequence. When the effective dimension is higher, the cone angle θ is increased adaptively while the orthogonal mixing parameter in the Krylov construction is kept small enough to satisfy the echo-state spectral-radius bound; this is verified numerically in the manuscript. We will add a dedicated paragraph discussing the adaptation procedure and its limits for attractors whose Lyapunov dimension substantially exceeds the chosen rank. revision: partial
-
Referee: [Abstract and ridge-regression analysis] Abstract (proof claim) and § on ridge-regression training error: the asserted proof that cone concentration reduces training error via improved conditioning and cross-covariance alignment is stated without the intermediate steps, the precise mathematical definition of the cone, or the data-exclusion rules used to define the input-determined subspace. These omissions prevent verification that the reduction is not achieved by construction or by post-hoc fitting.
Authors: We accept that the current exposition is too terse. The cone is defined as the set of vectors v satisfying ∠(v, S) ≤ θ where S is the data-derived subspace and θ is chosen from the decay of singular values of the input Gram matrix. Transients are excluded by discarding the first T0 steps until the trajectory lies on the attractor (T0 determined by visual inspection of the input norm). The proof bounds the minimal eigenvalue of the empirical second-moment matrix from below by a term proportional to cos²θ and shows that the dominant eigenvectors align with the cross-covariance under this concentration. The revised manuscript will contain the complete proof with all intermediate inequalities and the exact definitions. revision: yes
-
Referee: [Numerical experiments] Numerical experiments section: the reported performance gains lack error bars, statistical significance tests, and explicit baseline comparisons (e.g., against standard spectral-radius-tuned random ESNs or other data-driven methods), making it impossible to assess whether the gains are robust or merely consistent with the chosen examples.
Authors: We agree that the experimental section must be strengthened. In the revision we will report mean and standard deviation over 20 independent reservoir realizations, include paired t-tests against the null hypothesis of no improvement, and add explicit comparisons to (i) random reservoirs with spectral radius fixed at 0.9 and (ii) at least one additional data-driven baseline from the recent literature. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper states a geometric requirement (reservoir increments align in a cone around an input subspace) and proves its effect on ridge-regression error via conditioning and covariance alignment; this is presented as an independent mathematical argument rather than a definition or fit. The constructive ESN design (Krylov directions closed in the subspace) follows from the same geometric principle without reducing any claimed prediction or improvement to a quantity defined by the inputs themselves. No self-citations, ansatzes smuggled via prior work, or renamings of known results appear as load-bearing steps in the abstract or described chain. The result is therefore not equivalent to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Ridge-regression training error decreases when reservoir states concentrate variance in the input-determined subspace
- domain assumption Inputs are generated by deterministic dynamical systems
Reference graph
Works this paper leans on
-
[1]
Learning theory for dynamical systems
[Berr 23] T. Berry and S. Das. “Learning theory for dynamical systems”.SIAM Journal on Applied Dynamical Systems, Vol. 22, No. 3, pp. 2082–2122,
2082
-
[2]
Learning the climate of dynamical systems with state-space systems
[Louw 25] J. M. Louw and J.-P. Ortega. “Learning the climate of dynamical systems with state- space systems”.arXiv preprint arXiv:2512.15530,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Stochastic dynamics learning with state-space systems
[Orte 25b] J.-P. Ortega and F. Rossmannek. “Stochastic dynamics learning with state-space sys- tems”.Preprint. arXiv.2508.07876,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.