FrontierOR: Benchmarking LLMs' Capacity for Efficient Algorithm Design in Large-Scale Optimization
Pith reviewed 2026-06-30 00:24 UTC · model grok-4.3
The pith
Current LLMs struggle to design efficient algorithms that outperform Gurobi on most large-scale optimization problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
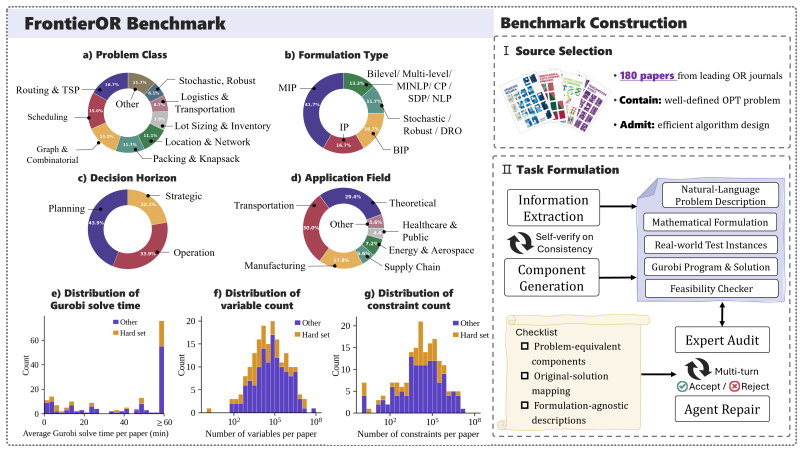
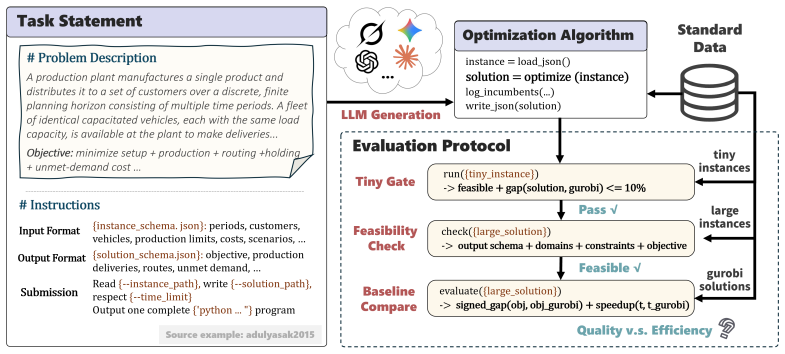
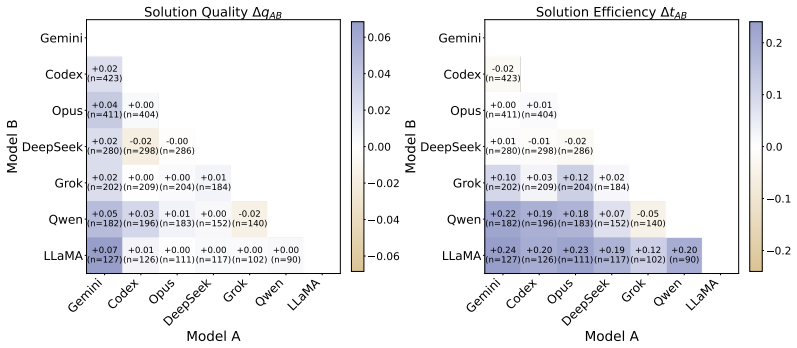
FrontierOR is introduced as a benchmark derived from 180 methodologically diverse papers in top-tier operations research venues. It supplies standardized instances and a hidden expert-verified evaluation suite. Evaluations of seven LLMs in one-shot and test-time evolution modes indicate that frontier models move from formulations to efficient algorithms in a minority of cases, with the strongest one-shot model succeeding in 31% against Gurobi on both metrics and evolution agents at 50% on selected hard tasks.
What carries the argument
The FrontierOR benchmark, which tests the transition from executable formulations to structure-exploiting scalable algorithms on realistic instances.
If this is right
- LLMs currently cannot reliably replace expert algorithm design for large optimization problems.
- Direct use of solvers like Gurobi remains more reliable for most tasks.
- The benchmark provides a standardized way to measure future improvements in LLM algorithm design.
- Test-time evolution improves results but does not close the gap to human-level performance.
Where Pith is reading between the lines
- Models may be limited by training data that emphasizes formulation over algorithmic innovation.
- Adding problem structure hints or domain-specific fine-tuning could be tested as extensions.
- Success here would imply broader capabilities for automated scientific discovery in optimization.
Load-bearing premise
That performance on these 180 tasks accurately reflects the capacity to design efficient algorithms that exploit problem structure at real-world scale.
What would settle it
A model that outperforms Gurobi in both quality and efficiency on more than half of the 180 tasks would indicate that the reported limitations have been overcome.
Figures
read the original abstract
Large language models (LLMs) are increasingly used for optimization modeling and solver-code generation, yet practical operations research and optimization problems often require a harder capability: designing scalable algorithms that exploit problem structure and outperform direct formulation-and-solve baselines. Existing benchmarks are limited to small or simplified examples far below real-world scale and complexity. We introduce FrontierOR, among the first benchmarks to systematically evaluate LLM-based efficient algorithm design for realistic large-scale optimization problems. FrontierOR includes 180 tasks derived from methodologically diverse papers published in top-tier operations research venues, each with standardized instances and a hidden, expert-verified evaluation suite. We evaluate seven LLMs spanning frontier, cost-effective, and open-source models both in one-shot and test-time evolution settings. The results reveal that frontier models still struggle to move from executable formulations to efficient optimization algorithms: the strongest one-shot model outperforms Gurobi in only 31% of cases in both solution quality and computational efficiency, and even strong coding agents with test-time evolution achieve only 50% on selected hard tasks. FrontierOR establishes a practical evaluation platform for LLM-based optimization algorithm design, which enables future LLMs and agents to be systematically tested on whether they can move beyond correct formulation toward a feasible, high-quality, and efficient algorithm. Code and data are publicly released at https://github.com/Minw913/FrontierOR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FrontierOR, a benchmark of 180 tasks derived from methodologically diverse top-tier OR papers, each with standardized instances and a hidden expert-verified evaluation suite. It evaluates seven LLMs (frontier, cost-effective, open-source) in one-shot and test-time evolution settings on their ability to design scalable algorithms that exploit problem structure and outperform Gurobi baselines in solution quality and computational efficiency. Key results: the strongest one-shot model succeeds in only 31% of cases on both metrics, while strong coding agents with evolution reach only 50% on selected hard tasks. The benchmark and public code/data release aim to shift evaluation from formulation correctness to efficient algorithm design at realistic scale.
Significance. If the tasks validly isolate structure-exploiting algorithm design (rather than formulation) and the hidden suite prevents overfitting, the reported performance gaps would establish a clear, scalable testbed for LLM progress in practical large-scale optimization, highlighting current limitations beyond small/simplified examples. The public release of code and data is a positive contribution for reproducibility in this empirical benchmark setting.
major comments (2)
- [Abstract] Abstract: the headline claims that the strongest one-shot model outperforms Gurobi in only 31% of cases (both quality and efficiency) and that agents reach 50% on hard tasks are presented without any information on task selection criteria, statistical testing of the percentages, or how the hidden evaluation suite is constructed to prevent overfitting; these details are load-bearing for interpreting the central empirical results.
- [Abstract] Abstract (and implied § on benchmark construction): the premise that the 180 tasks test the shift to 'efficient optimization algorithms that exploit problem structure' rather than merely correct formulations is invoked to justify relevance, but no concrete mechanism (e.g., instance standardization details or expert verification criteria) is supplied to show how the evaluation distinguishes the two capabilities.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments, which highlight the need for greater transparency in the abstract and benchmark details to support interpretation of the central results. We address each point below and will revise the manuscript to incorporate additional clarifications on task selection, statistical aspects, and evaluation mechanisms.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claims that the strongest one-shot model outperforms Gurobi in only 31% of cases (both quality and efficiency) and that agents reach 50% on hard tasks are presented without any information on task selection criteria, statistical testing of the percentages, or how the hidden evaluation suite is constructed to prevent overfitting; these details are load-bearing for interpreting the central empirical results.
Authors: We agree these details are important for interpreting the headline percentages. Task selection criteria (derivation from 180 methodologically diverse top-tier OR papers) and the hidden expert-verified suite are described in Section 3; statistical computation of the 31% and 50% success rates (across the full set and selected hard tasks) appears in Section 4. To address the concern directly in the abstract, we will add a concise clause noting the tasks are drawn from top-tier venues with a hidden evaluation suite designed to prevent overfitting, and we will include a brief parenthetical on the percentages being computed over the standardized instance set. revision: yes
-
Referee: [Abstract] Abstract (and implied § on benchmark construction): the premise that the 180 tasks test the shift to 'efficient optimization algorithms that exploit problem structure' rather than merely correct formulations is invoked to justify relevance, but no concrete mechanism (e.g., instance standardization details or expert verification criteria) is supplied to show how the evaluation distinguishes the two capabilities.
Authors: The distinction is operationalized by requiring models to produce algorithms that improve both solution quality and runtime over Gurobi on large-scale standardized instances; correct formulations alone are insufficient to meet both criteria at the scales used. Section 3 outlines the standardization process and expert verification, but we acknowledge the need for more explicit criteria. We will expand the benchmark construction section with concrete details on instance scaling, the expert verification rubric (focusing on scalability and structure exploitation), and how the hidden suite enforces evaluation of algorithmic efficiency rather than formulation correctness alone. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
This is an empirical benchmark paper introducing FrontierOR with 180 tasks and reporting LLM performance metrics (e.g., 31% one-shot outperformance of Gurobi) via direct external comparisons. No equations, parameter fits, predictions derived from inputs, or load-bearing self-citations appear in the provided text; the central claims rest on standardized instances and hidden expert-verified evaluation, which are independent of the reported results. The derivation chain is self-contained against external baselines with no reduction to self-definition or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tasks derived from published top-tier OR papers with standardized instances represent realistic large-scale optimization problems that require structure-exploiting algorithms beyond direct formulation.
Reference graph
Works this paper leans on
-
[1]
Ali AhmadiTeshnizi, Wenzhi Gao, and Madeleine Udell. Optimus: Scalable optimization modeling with (mi) lp solvers and large language models.arXiv preprint arXiv:2402.10172, 2024
arXiv 2024
-
[2]
Or-library: distributing test problems by electronic mail.Journal of the operational research society, 41(11):1069–1072, 1990
John E Beasley. Or-library: distributing test problems by electronic mail.Journal of the operational research society, 41(11):1069–1072, 1990
1990
-
[3]
Qaplib–a quadratic assignment problem library.Journal of Global optimization, 10(4):391–403, 1997
Rainer E Burkard, Stefan E Karisch, and Franz Rendl. Qaplib–a quadratic assignment problem library.Journal of Global optimization, 10(4):391–403, 1997
1997
-
[4]
Hongzheng Chen, Yingheng Wang, Yaohui Cai, Hins Hu, Jiajie Li, Shirley Huang, Chenhui Deng, Rongjian Liang, Shufeng Kong, Haoxing Ren, et al. Heurigym: An agentic benchmark for llm-crafted heuristics in combinatorial optimization.arXiv preprint arXiv:2506.07972, 2025
arXiv 2025
-
[5]
Shengyu Feng, Weiwei Sun, Shanda Li, Ameet Talwalkar, and Yiming Yang. A comprehensive evaluation of contemporary ml-based solvers for combinatorial optimization.arXiv preprint arXiv:2505.16952, 2025
arXiv 2025
-
[6]
Miplib 2017: data-driven compilation of the 6th mixed-integer programming library.Mathematical Programming Computation, 13(3):443–490, 2021
Ambros Gleixner, Gregor Hendel, Gerald Gamrath, Tobias Achterberg, Michael Bastubbe, Timo Berthold, Philipp Christophel, Kati Jarck, Thorsten Koch, Jeff Linderoth, et al. Miplib 2017: data-driven compilation of the 6th mixed-integer programming library.Mathematical Programming Computation, 13(3):443–490, 2021. 10
2017
-
[7]
Orlm: A customizable framework in training large models for automated optimization modeling.Operations Research, 73(6):2986–3009, 2025
Chenyu Huang, Zhengyang Tang, Shixi Hu, Ruoqing Jiang, Xin Zheng, Dongdong Ge, Benyou Wang, and Zizhuo Wang. Orlm: A customizable framework in training large models for automated optimization modeling.Operations Research, 73(6):2986–3009, 2025
2025
-
[8]
Llms for mathe- matical modeling: Towards bridging the gap between natural and mathematical languages
Xuhan Huang, Qingning Shen, Yan Hu, Anningzhe Gao, and Benyou Wang. Llms for mathe- matical modeling: Towards bridging the gap between natural and mathematical languages. In Findings of the Association for Computational Linguistics: NAACL 2025, pages 2678–2710, 2025
2025
-
[9]
Caigao Jiang, Xiang Shu, Hong Qian, Xingyu Lu, Jun Zhou, Aimin Zhou, and Yang Yu. Llmopt: Learning to define and solve general optimization problems from scratch.arXiv preprint arXiv:2410.13213, 2024
arXiv 2024
-
[10]
Xia Jiang, Jing Chen, Cong Zhang, Jie Gao, Chengpeng Hu, Chenhao Zhang, Yaoxin Wu, and Yingqian Zhang. Reasoning in a combinatorial and constrained world: Benchmarking llms on natural-language combinatorial optimization.arXiv preprint arXiv:2602.02188, 2026
Pith/arXiv arXiv 2026
-
[11]
Minwei Kong, Ao Qu, Xiaotong Guo, Wenbin Ouyang, Chonghe Jiang, Han Zheng, Yining Ma, Dingyi Zhuang, Yuhan Tang, Junyi Li, et al. Alphaopt: Formulating optimization programs with self-improving llm experience library.arXiv preprint arXiv:2510.18428, 2025
Pith/arXiv arXiv 2025
-
[12]
Kuo Liang, Yuhang Lu, Jianming Mao, Shuyi Sun, Chunwei Yang, Congcong Zeng, Xiao Jin, Hanzhang Qin, Ruihao Zhu, and Chung-Piaw Teo. Large-scale optimization model auto-formulation: Harnessing llm flexibility via structured workflow.arXiv preprint arXiv:2601.09635, 2026
arXiv 2026
-
[13]
Fei Liu, Xialiang Tong, Mingxuan Yuan, Xi Lin, Fu Luo, Zhenkun Wang, Zhichao Lu, and Qingfu Zhang. Evolution of heuristics: Towards efficient automatic algorithm design using large language model.arXiv preprint arXiv:2401.02051, 2024
arXiv 2024
-
[14]
Hongliang Lu, Zhonglin Xie, Yaoyu Wu, Can Ren, Yuxuan Chen, and Zaiwen Wen. Optmath: A scalable bidirectional data synthesis framework for optimization modeling.arXiv preprint arXiv:2502.11102, 2025
arXiv 2025
-
[15]
Kostis Michailidis, Dimos Tsouros, and Tias Guns. Cp-bench: Evaluating large language models for constraint modelling.arXiv preprint arXiv:2506.06052, 2025
arXiv 2025
-
[16]
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131, 2025
Pith/arXiv arXiv 2025
-
[17]
Ao Qu, Han Zheng, Zijian Zhou, Yihao Yan, Yihong Tang, Shao Yong Ong, Fenglu Hong, Kaichen Zhou, Chonghe Jiang, Minwei Kong, et al. Coral: Towards autonomous multi-agent evolution for open-ended discovery.arXiv preprint arXiv:2604.01658, 2026
Pith/arXiv arXiv 2026
-
[18]
Nl4opt competition: Formulating optimization problems based on their natural language descriptions
Rindranirina Ramamonjison, Timothy Yu, Raymond Li, Haley Li, Giuseppe Carenini, Bissan Ghaddar, Shiqi He, Mahdi Mostajabdaveh, Amin Banitalebi-Dehkordi, Zirui Zhou, et al. Nl4opt competition: Formulating optimization problems based on their natural language descriptions. InNeurIPS 2022 competition track, pages 189–203. PMLR, 2023
2022
-
[19]
Tsplib—a traveling salesman problem library.ORSA journal on computing, 3 (4):376–384, 1991
Gerhard Reinelt. Tsplib—a traveling salesman problem library.ORSA journal on computing, 3 (4):376–384, 1991
1991
-
[20]
Openevolve: an open-source evolutionary coding agent.GitHub repository
Asankhaya Sharma. Openevolve: an open-source evolutionary coding agent.GitHub repository. Accessed, pages 08–10, 2025
2025
-
[21]
Co-bench: Benchmarking language model agents in algorithm search for combinatorial optimization
Weiwei Sun, Shengyu Feng, Shanda Li, and Yiming Yang. Co-bench: Benchmarking language model agents in algorithm search for combinatorial optimization. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 33126–33134, 2026
2026
-
[22]
Jianheng Tang, Qifan Zhang, Yuhan Li, Nuo Chen, and Jia Li. Grapharena: Evaluating and exploring large language models on graph computation.arXiv preprint arXiv:2407.00379, 2024. 11
arXiv 2024
-
[23]
New benchmark instances for the capacitated vehicle routing problem.European Journal of Operational Research, 257(3):845–858, 2017
Eduardo Uchoa, Diego Pecin, Artur Pessoa, Marcus Poggi, Thibaut Vidal, and Anand Subrama- nian. New benchmark instances for the capacitated vehicle routing problem.European Journal of Operational Research, 257(3):845–858, 2017
2017
-
[24]
Chain-of-experts: When llms meet complex operations research problems
Ziyang Xiao, Dongxiang Zhang, Yangjun Wu, Lilin Xu, Yuan Jessica Wang, Xiongwei Han, Xiaojin Fu, Tao Zhong, Jia Zeng, Mingli Song, et al. Chain-of-experts: When llms meet complex operations research problems. InThe twelfth international conference on learning representations, 2023
2023
-
[25]
Zhicheng Yang, Yiwei Wang, Yinya Huang, Zhijiang Guo, Wei Shi, Xiongwei Han, Liang Feng, Linqi Song, Xiaodan Liang, and Jing Tang. Optibench meets resocratic: Measure and improve llms for optimization modeling.arXiv preprint arXiv:2407.09887, 2024
arXiv 2024
-
[26]
Chenyu Zhou, Tianyi Xu, Jianghao Lin, and Dongdong Ge. Steporlm: A self-evolving frame- work with generative process supervision for operations research language models.arXiv preprint arXiv:2509.22558, 2025. A Detailed Benchmark Construction Protocol A.1 Source Selection and Reproduction Pipeline For each selected paper, the optimization problem, test dat...
arXiv 2025
-
[27]
When the paper presents multiple alternative formulations, we select the for- mulation that is most central to the computational study
Formulation extraction.The original mathematical formulation of the optimization problem—sets, parameters, variables, objective, and constraints—is identified from the paper and transcribed in LATEX as the single authoritative reference for construction and verification. When the paper presents multiple alternative formulations, we select the for- mulatio...
-
[28]
When instances rely on external and accessible benchmarks, their configurations are retrieved and cross-checked to reproduce the scale and structure used in the source paper
Instance specification extraction.The configurations of all test-instance sets used in the paper’s computational experiments are extracted into a machine-readable JSON specification. When instances rely on external and accessible benchmarks, their configurations are retrieved and cross-checked to reproduce the scale and structure used in the source paper
-
[29]
A Column Generation Algorithm for Choice-Based Network Revenue Management,
Solver implementation.Based on the solver-ready formulation, we implement a Gurobi program that returns solutions expressed in the original decision variables. If the solver uses auxiliary reformulation variables internally, the output is projected back to the variables of the original formulation. When the paper omits a solver-ready formulation, we deriv...
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.